
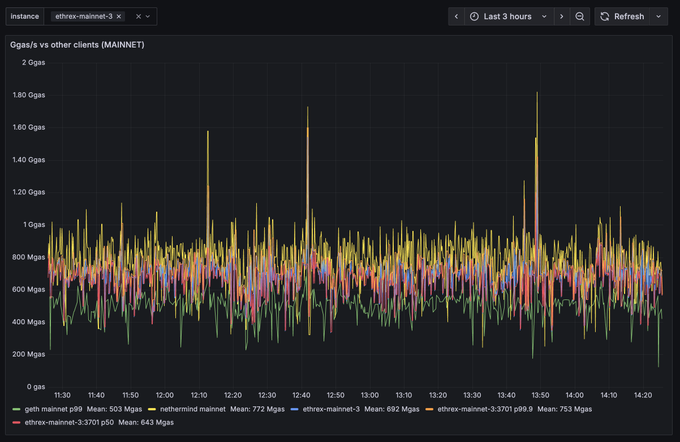
正如我們今天在社區電話會議上提到的,我們實現了性能提升,區塊執行吞吐量提高了 20-25%。在我們的一臺服務器上,@ethrex_client 的吞吐量從 514 mgas/s 提升至 637 mgas/s,延遲也從 64 毫秒降至 57 毫秒。 這個想法源於 Reth 的最新版本,他們添加了一個緩存,使得證明工作線程可以共享已獲取的數據庫值,而不是每個工作線程都獨立訪問數據庫。我們沒有使用覆蓋層或證明工作線程,而是使用 trie 層進行默克爾化,但我們在其他地方也遇到過同樣的問題:在預熱狀態時,各個工作線程會多次獲取相同的狀態,最好的情況是訪問 trie 層,最壞的情況是訪問數據庫。添加一個用於存儲已獲取值的共享緩存帶來了上述性能提升。 過去幾周,我們在未使用 Claude Code 的情況下,性能提升了 50%。使用 Claude Code 後,預計很快會有更多收益。作為參考,我們服務器上的 Nethermind主網平均吞吐量為 772 mgas/s,而 ethrex 的平均吞吐量為 692 mgas/s。 恭喜 @class_lambda。
本文為機器翻譯
展示原文
來自推特
免責聲明:以上內容僅為作者觀點,不代表Followin的任何立場,不構成與Followin相關的任何投資建議。
喜歡
收藏
評論
分享





