

AI時代核心資產是記憶和抽象思維
折騰了一段時間,終於把"本地記憶 + 雲端 LLM"的架構跑通了
核心思路:
記憶是核心資產,不能全給雲端。
輸入 → 本地記憶(完整) → 過濾層 → 雲端 LLM → 審計 → 輸出
我的做法分幾層:
1. 本地存完整記憶* — Markdown 文件 + 本地向量數據庫
- 什麼都記,不做過濾
- 這是"真實的我"
2. 雲端只拿過濾後的上下文
- 敏感信息單獨存,不進 LLM 上下文
-輸出審計 — 發送前過一遍檢查
👌
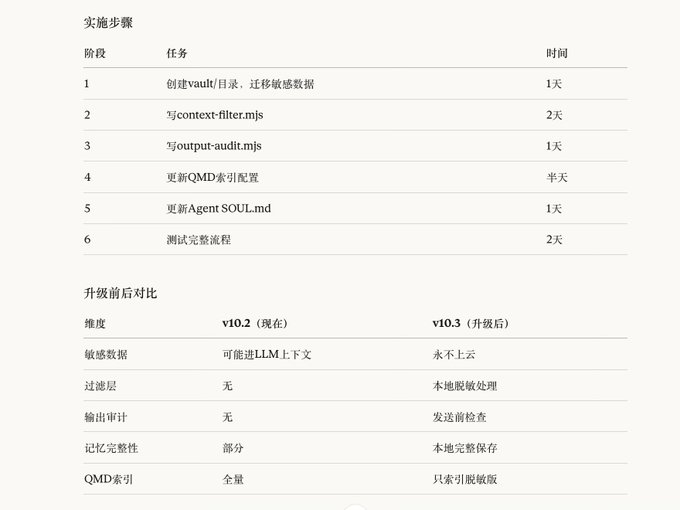
把這段提示詞丟給ai。
執行升級:本地記憶 + 過濾層架構
核心原則:記憶是核心資產,敏感信息永不上雲。
== 安全規則(最高優先級) ==
1. 每一步改完都要測試,確認系統正常再進行下一步
2. 不要同時改多個東西
3. 改配置前先備份:cp openclaw.json openclaw.json.bak
4. x.com/bitfish/status…
感覺未來蘋果這類終端廠商,會把本地LLM邊緣計算模式 也跑通。。
來自推特
免責聲明:以上內容僅為作者觀點,不代表Followin的任何立場,不構成與Followin相關的任何投資建議。
喜歡
收藏
評論
分享




