

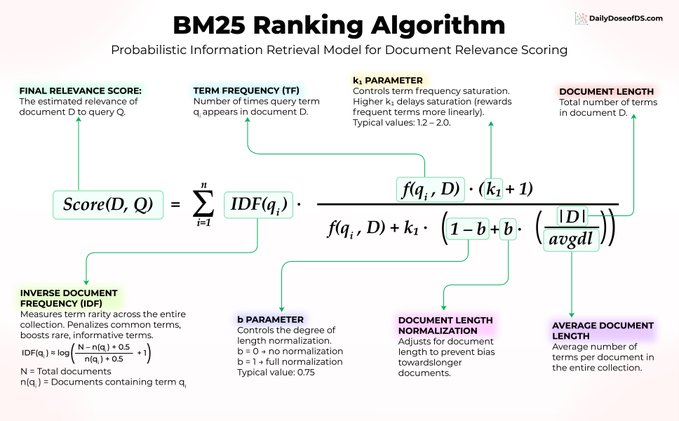
向量搜索並非萬能。 一個已有 30 年曆史、無需訓練、無需嵌入、無需微調的算法,至今仍在為 Elasticsearch、OpenSearch 以及大多數生產級搜索系統提供動力。 它就是 BM25,值得我們探究它為何經久不衰。 假設你在一個機器學習論文庫中搜索“transformer attention mechanism”(transformer 注意力機制)。 BM25 使用三個核心思想對文檔進行評分: 1) 詞語稀有度比詞頻更重要 每篇論文都包含“the”和“is”,因此這些詞本身並不具有任何信號意義。 但“transformer”一詞具體且信息豐富,因此 BM25 會賦予它更高的權重。在公式中,這體現在 IDF(qᵢ) 上。 2) 重複出現會有幫助,但收益遞減 如果“attention”(注意力)一詞在一篇論文中出現 10 次,這是一個很強的相關性信號。但從 10 次到 100 次的出現,對得分的影響微乎其微。 BM25 應用了由 f(qᵢ, D) 和參數 k₁ 控制的飽和曲線,從而防止關鍵詞堆砌操縱搜索結果。 3) 文檔長度歸一化 一篇 50 頁的論文自然比一篇 5 頁的論文包含更多的關鍵詞命中。 BM25 使用 |D|/avgdl 進行調整,該值由參數 b 控制,因此較長的文檔不會僅僅因為文本量更多而佔據排名優勢。 三個核心理念。無需神經網絡。無需訓練數據。僅需經受時間考驗的優雅數學。 這裡是大多數人忽略的部分:BM25 擅長精確關鍵詞匹配,而這正是嵌入算法的弱項。 當用戶搜索“錯誤代碼 5012”時,向量搜索可能會返回語義相似的錯誤代碼。而 BM25 每次都能找到完全匹配項。 這正是混合搜索成為頂級 RAG 系統默認設置的原因。 將 BM25 與向量搜索相結合,即可在單一流程中實現語義理解和精確的關鍵詞匹配。 因此,在您動輒就用 GPU 解決所有搜索問題之前,請考慮一下 BM25 是否已經能夠解決問題,或者至少,兩者結合後,語義搜索的性能將顯著提升。
本文為機器翻譯
展示原文
來自推特
免責聲明:以上內容僅為作者觀點,不代表Followin的任何立場,不構成與Followin相關的任何投資建議。
喜歡
收藏
評論
分享




