

Google 今(13)日發布了 Gemini 3 Deep Think 的重大升級。在 ARC-AGI-2(一個專門防止 AI 背題庫的推理測試,不考你知道多少,考你能不能從幾個範例中自己歸納出規則)測試中,Gemini 3 Deep Think 拿下了 84.6%。
作為參照,Claude Opus 4.6(Thinking Max 模式)拿到 68.8%,GPT-5.2(Thinking xhigh 模式)是 52.9%,而人類平均約 60%。
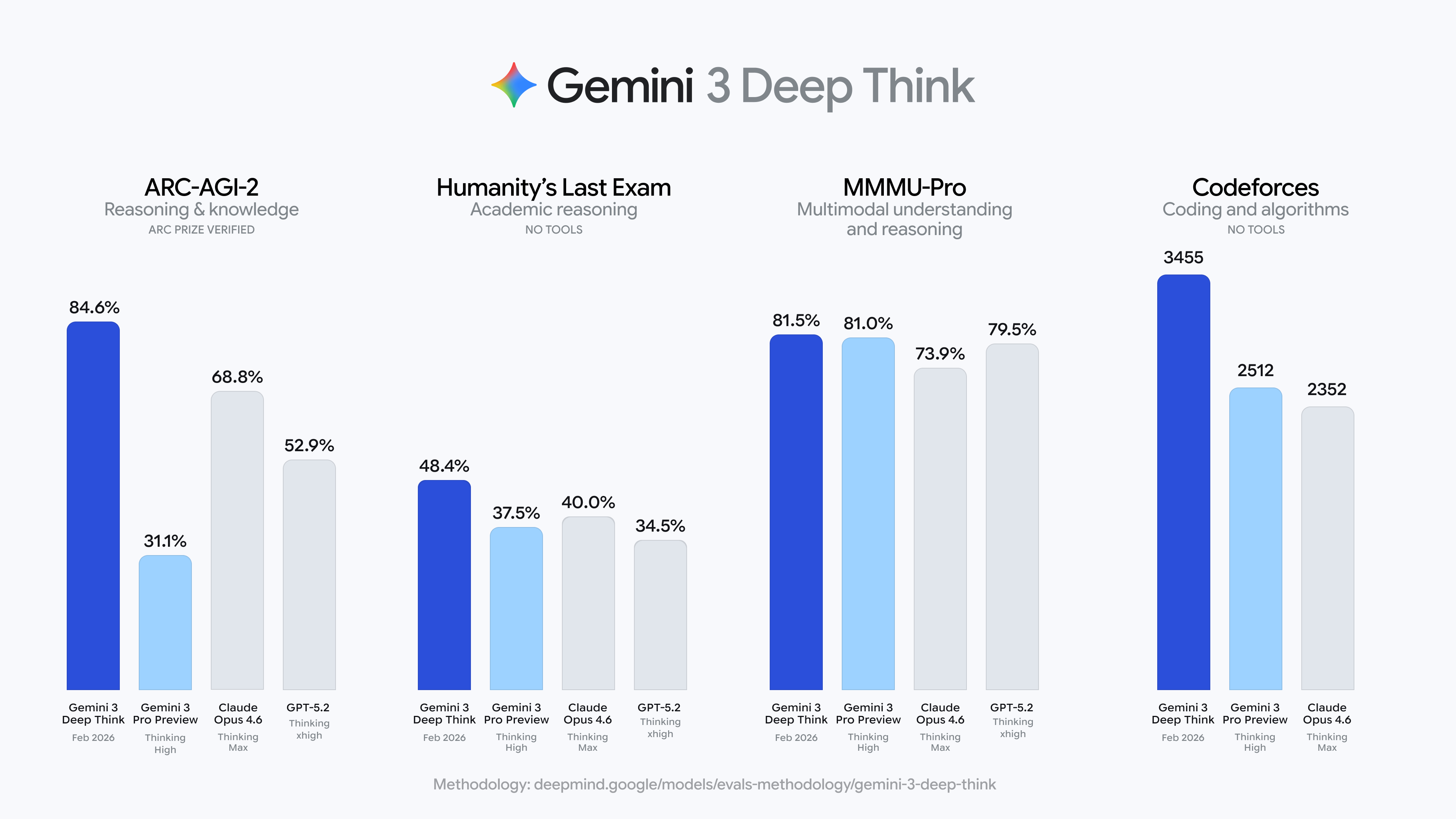
更驚人的是,在原版 ARC-AGI-1 上,Deep Think 拿到 96%,基本上把這個曾被視為「AI 最難考試之一」的基準測試考到了天花板。
不只會考試,還會抓人類的錯
跑分之外,Google 在公告中提到了一個細節:Deep Think 在審閱一篇經過人類同行評審的數學論文時,成功找出了一個之前所有審稿人都沒發現的邏輯漏洞。這篇論文由羅格斯大學(Rutgers University)的數學家確認。
這個案例的重要性在於,它不是模型在標準化測試中的表現,而是在真實的、開放式的科學場景中展現的能力。同行評審是學術界最核心的品質控制機制,如果 AI 能穩定地在這個環節提供有價值的輔助,它對科學研究的加速效應將遠超任何跑分所能衡量。
Deep Think 同時在 2025 年國際物理奧林匹克和化學奧林匹克的筆試部分達到金牌水準,在 Codeforces 上的 Elo 評分為 3,455,對應「傳奇宗師」等級,全球僅極少數人類程式設計師能達到這個層級。
而在「人類最後的考試」(Humanity’s Last Exam)這個由各領域專家設計、刻意讓 AI 難以作答的基準上,Deep Think 拿到 48.4%(不使用工具),也創下新紀錄。
市場份額的地殼變動
AI 三巨頭的技術競賽正在改變市場版圖。ChatGPT 的市佔率已從巔峰時期的 87% 降至約 68%,而 Gemini 從不到 5% 飆升至超過 18%、Anthropic 的 Claude 則穩步蠶食企業級市場。
Google 在這場競賽中的獨特優勢是分發能力。Gemini 內建在 Android 系統、Chrome 瀏覽器、Google Workspace 和搜尋引擎中,這意味著即使在模型能力上與對手打平,Google 也能透過渠道優勢贏得用戶。
但分發優勢是雙面刃。如果 Gemini 的體驗不夠好,它可能會比任何競品更快地失去用戶信任,因為用戶是「被動接觸」而非「主動選擇」。OpenAI 的用戶是主動付費的,天然有更高的容忍度和黏性。
對加密產業的漣漪效應
AI 軍備競賽的每一次升級,都在推高對運算基礎設施的需求。訓練一個前沿模型所需的 GPU 叢集成本已經從 2024 年的數億美元級別,膨脹到 2026 年的數十億美元級別。這也直接影響了兩件事。
第一,比特幣礦工的轉型路徑。當挖礦利潤被壓縮(摩根大通本週估算 BTC 生產成本降至 7.7 萬美元,而幣價在 6.6 萬附近),擁有大規模算力基礎設施的礦工正加速轉向 AI 運算服務。
高成本礦企不是「退出」,而是「轉業」,從挖比特幣變成提供 AI 算力的合約收入。
第二,AI 代幣的敘事。每當 Google、OpenAI 或 Anthropic 發布重大升級,鏈上 AI 相關代幣(如去中心化運算協議)通常會出現短期炒作。
但這些代幣的基本面問題始終沒變:去中心化運算在延遲和吞吐量上,距離企業級 AI 訓練的需求還有很長的路要走。敘事可以跑得很快,但基礎設施還追不上敘事的速度。
科學決勝局才剛開始
Deep Think 的升級把 Google 又推回了 AI 競賽的領跑位置,至少在推理和科學領域是如此。但如果你仔細看 Google 的公告措辭,會發現一個微妙的定位轉變:它不再強調「最聰明的通用 AI」,而是反覆提及「為科學而生」。
當通用 AI 的基準測試越來越擁擠、差異化越來越難,「我的 AI 能幫你做科學研究」是一個比「我的 AI 跑分最高」更有說服力的價值主張。如果 Deep Think 真的能穩定地輔助同行評審、加速藥物發現、或在物理模擬中找到人類遺漏的解,這比任何跑分榜單都更有意義。
問題是,從「能在基準測試上拿高分」到「能在真實科學場景中可靠地輔助人類」,中間的距離可能比 Google 暗示的更遠,畢竟基準測試有標準答案,科學沒有。





