

本報告由Tiger Research撰寫,大多數人每天都在使用AI,卻從未想過數據流向了何處。Nesa提出的問題是:當你開始正視這個問題時,會發生什麼?
核心要點
- AI已融入日常生活,但用戶往往忽略數據如何通過中央服務器傳輸
- 即便是美國CISA的代理局長,也在不知情中將機密文件洩露給ChatGPT
- Nesa通過傳輸前的數據轉換(EE)和跨節點分割(HSS-EE)重構了這一流程,確保任何單一方都無法查看原始數據
- 學術認證(COLM 2025)和企業實際部署(寶潔)為Nesa奠定了先發優勢
- 更廣泛的市場是否會選擇去中心化隱私AI,而非習慣的中央化API,這仍是關鍵問題
1. 你的數據安全嗎?

來源:CISA
2026年1月,美國網絡安全領導機構CISA的代理局長馬杜·戈圖穆卡拉(Madhu Gottumukkala)將敏感政府文件上傳至ChatGPT,僅僅是為了總結和整理合同相關資料。
這次洩露既未被ChatGPT檢測到,OpenAI也未向政府報告。而是被該機構自身的內部安全系統捕獲,並因違反安全協議引發了調查。
連美國最高網絡安全官員都在日常使用AI,甚至不慎上傳了機密材料。
我們都知道,大多數AI服務會將用戶輸入以加密形式存儲在中央服務器。但這種加密從設計上就是可逆的。在合法授權或緊急情況下,數據可以被解密和披露,而用戶對背後發生的一切毫不知情。
2. 面向日常使用的隱私AI:Nesa
AI已經成為日常生活的一部分——總結文章、編寫代碼、起草郵件。真正值得擔憂的是,正如前述案例所示,即便是機密文件和個人數據,也在人們幾乎沒有風險意識的情況下被交給了AI。
核心問題在於:所有這些數據都要經過服務商的中央服務器。即使進行了加密,解密密鑰也掌握在服務商手中。用戶憑什麼信任這種安排?
用戶輸入的數據可能通過多種途徑暴露給第三方:模型訓練、安全審查、法律請求。企業版中,組織管理員可以訪問聊天記錄;個人版中,數據同樣可能在合法授權下被移交。

既然AI已深度嵌入日常生活,是時候認真審視隱私問題了。
Nesa正是為徹底改變這一結構而生的項目。它構建了去中心化基礎設施,在無需將數據託付給中央服務器的前提下實現AI推理。用戶輸入在加密狀態下處理,任何單一節點都無法查看原始數據。
3. Nesa如何解決問題
設想一家醫院使用Nesa。醫生希望AI分析患者的MRI影像以檢測腫瘤。在現有AI服務中,影像會被直接發送到OpenAI或谷歌的服務器。
而使用Nesa時,影像在離開醫生電腦之前就已完成數學轉換。
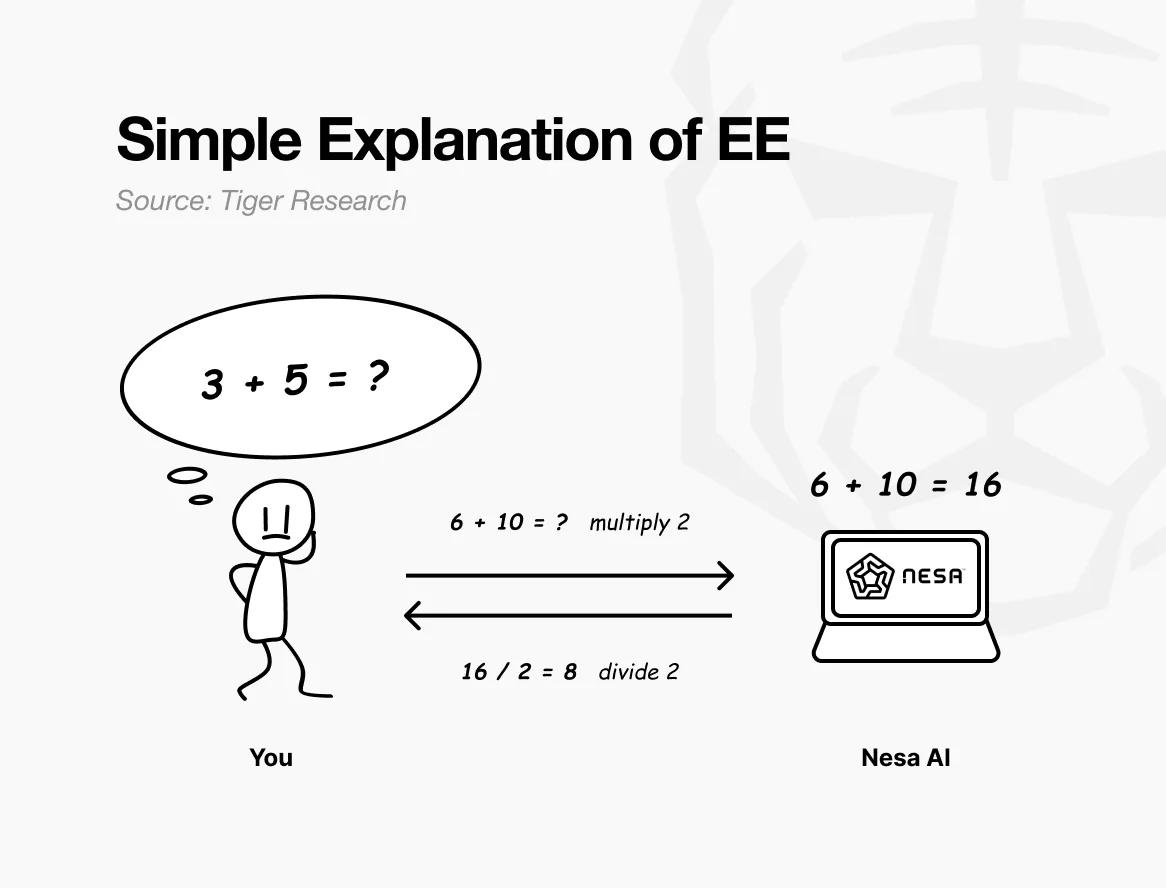
打個簡單的比方:假設原始問題是“3 + 5 = ?”如果直接發送,接收方會清楚知道你在計算什麼。
但如果發送前將每個數字乘以2,接收方看到的就是“6 + 10 = ?”並返回16。你再除以2得到8——與直接計算原問題的答案完全一致。接收方完成了計算,卻始終不知道你的原始數字是3和5。
這正是Nesa的等變加密(EE)所實現的。數據在傳輸前經過數學轉換,AI模型對轉換後的數據進行計算。
用戶再應用逆向轉換,得到的結果與使用原始數據完全相同。在數學上,這種特性叫做等變性:無論先轉換後計算,還是先計算後轉換,最終結果都一致。
實際操作中,轉換遠比簡單乘法複雜得多——它是根據AI模型的內部計算結構專門定製的。正因為轉換與模型的處理流程完美對齊,準確性才不會受到任何影響。
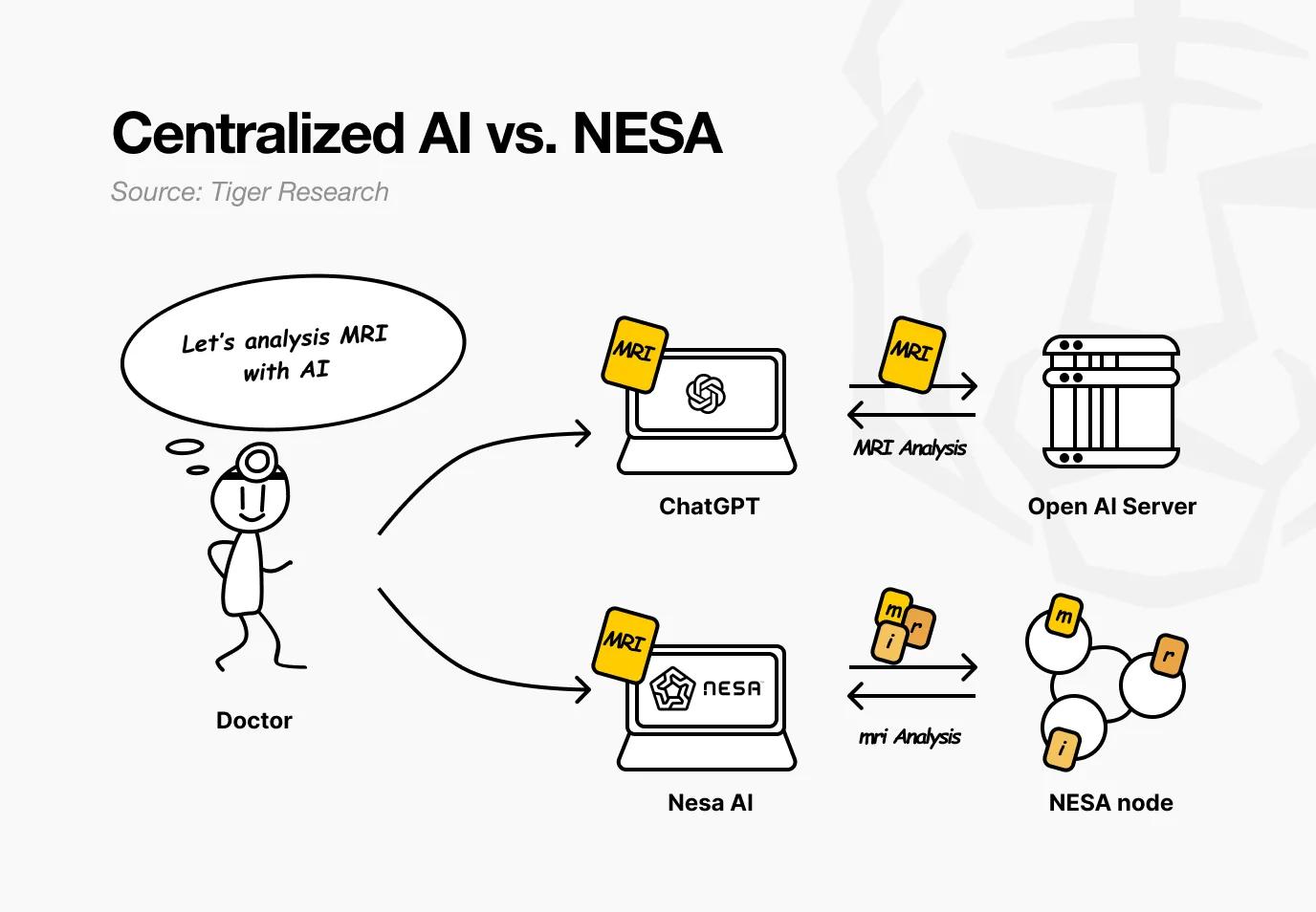
回到醫院場景。對醫生而言,整個流程沒有任何變化——上傳影像、接收結果,一切如常。改變的是:中間環節的任何節點都無法看到患者的原始MRI。
Nesa還更進一步。單憑EE就能防止節點查看原始數據,但轉換後的數據仍完整存在於單個服務器上。
HSS-EE(加密嵌入上的同態秘密共享)則進一步分割了轉換後的數據。
繼續前面的比方。EE相當於在發送試卷前應用乘法規則;HSS-EE則是把轉換後的試卷撕成兩半——第一部分發給節點A,第二部分發給節點B。
每個節點只能解答自己的片段,都看不到完整題目。只有當兩個部分答案合併時,才能得出完整結果——而且只有原始發送者能完成這個合併操作。
簡而言之:EE轉換數據,讓原始內容無法被看見;HSS-EE進一步分割轉換後的數據,使其永遠不會完整出現在任何一處。隱私保護實現了雙重加固。
4. 隱私保護會拖慢性能嗎?
更強的隱私往往意味著更慢的性能——這是密碼學領域長期以來的鐵律。最廣為人知的全同態加密(FHE)比標準計算慢10,000到1,000,000倍,根本無法應用於實時AI服務。
Nesa的等變加密(EE)採用了不同路徑。回到數學類比:發送前乘以2、接收後除以2的成本微乎其微。
與FHE將整個問題轉換為完全不同的數學系統不同,EE只是在現有計算基礎上添加了輕量級轉換層。
性能基準數據:
- EE:在LLaMA-8B上延遲增加不到9%,準確率與原始模型匹配,超過99.99%
- HSS-EE:在LLaMA-2 7B上每次推理耗時700至850毫秒
此外,MetaInf元學習調度器進一步優化了全網效率。它會評估模型大小、GPU規格和輸入特徵,自動選擇最快的推理方法。
MetaInf實現了89.8%的選擇準確率,速度比傳統ML選擇器快1.55倍。該成果已在COLM 2025主會議發表,獲得學術界認可。
以上數據來自受控測試環境。但更重要的是,Nesa的推理基礎設施已在實際企業環境中部署運行,驗證了生產級性能表現。
5. 誰在用?怎麼用?
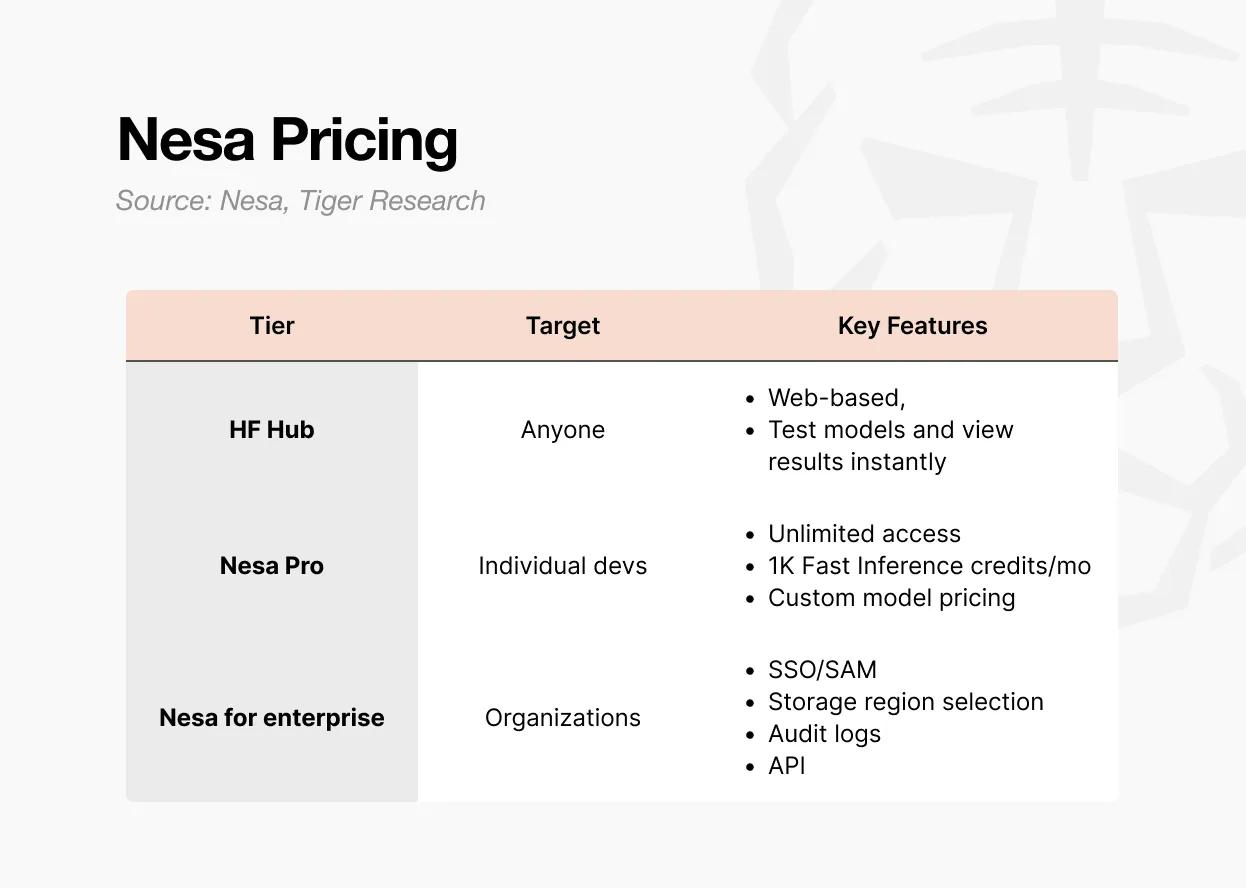
訪問Nesa有三種方式。
第一種是Playground。用戶可以直接在網頁上選擇和測試模型,無需任何開發背景。你可以實際體驗輸入數據、查看各模型輸出結果的完整流程。
這是最快了解去中心化AI推理實際運作方式的途徑。
第二種是Pro訂閱。每月8美元,包含無限訪問、每月1,000個快速推理積分、自定義模型定價控制,以及模型特色頁面展示。
這一檔位專為希望部署和變現自有模型的個人開發者或小團隊設計。
第三種是Enterprise企業版。這不是公開定價方案,而是定製化合同。包含SSO/SAML支持、可選數據存儲區域、審計日誌、細粒度訪問控制和年度合約計費。
起步價為每用戶每月20美元,但實際條款需根據規模協商。它專為將Nesa集成到內部AI流程的組織打造,通過獨立協議提供API訪問和組織級管理功能。
總結:Playground用於探索體驗,Pro適合個人或小團隊開發,Enterprise面向組織級部署。
6. 為什麼需要代幣?
去中心化網絡沒有中央管理者。運行服務器和驗證結果的實體分佈在全球各地。這自然引出一個問題:為什麼有人願意讓自己的GPU持續運轉,為他人處理AI推理?
答案是經濟激勵。在Nesa網絡中,這個激勵就是$NES代幣。
來源:Nesa
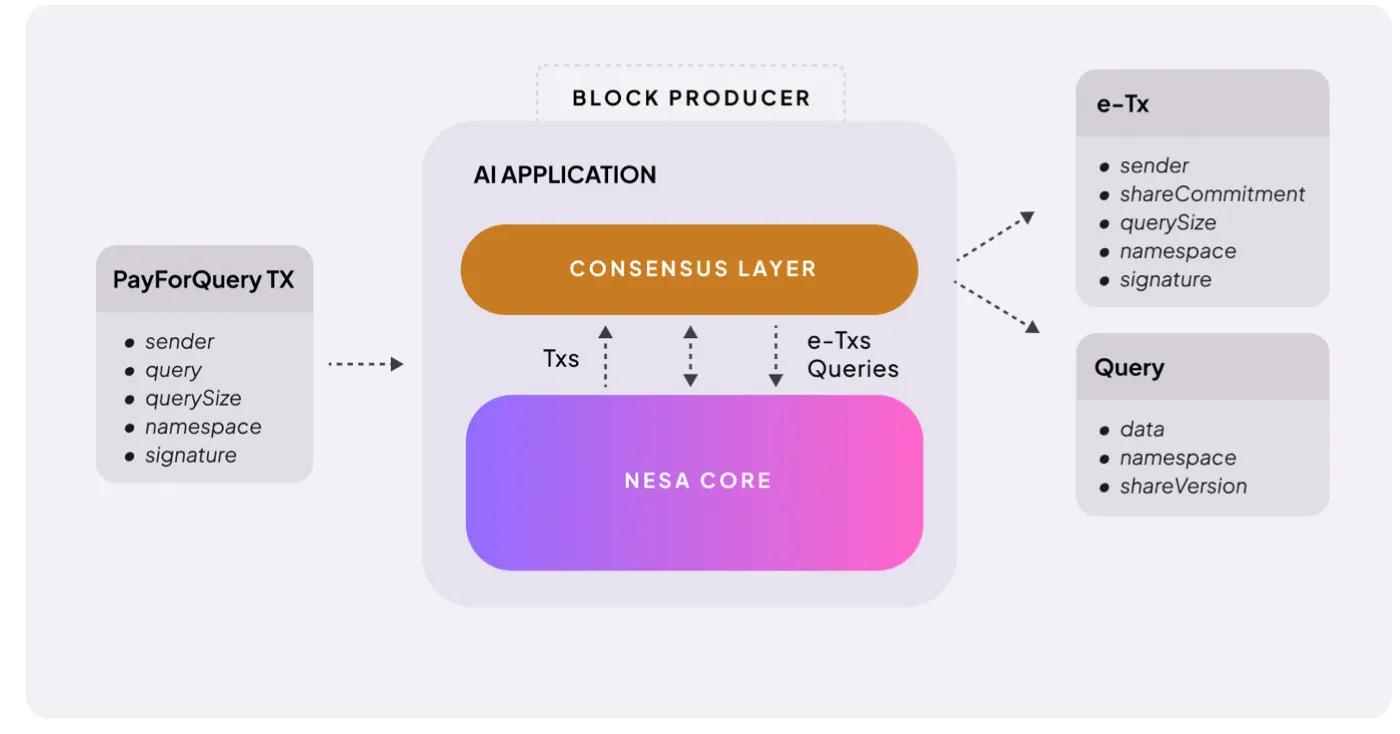
機制非常直接。當用戶發起AI推理請求時,需要支付費用。Nesa稱之為PayForQuery,由每筆交易的固定費用加上與數據量成正比的可變費用構成。
費用越高,處理優先級越高——這與區塊鏈上的gas費原理相同。
這些費用的接收者是礦工。要參與網絡,礦工必須質押一定數量的$NES——在被分配任務前,他們要先將自己的代幣置於風險之中。
如果礦工返回錯誤結果或無法響應,將從質押中扣除罰金;如果處理準確迅速,則獲得更高獎勵。
$NES同時也是治理工具。代幣持有者可以提交提案,對費用結構、獎勵比例等核心網絡參數進行投票。
總而言之,$NES發揮三重作用:推理請求的支付手段、礦工的抵押品和獎勵、網絡治理的參與憑證。沒有代幣,節點不會運行;沒有節點,隱私AI就無從談起。
值得注意的是:代幣經濟的運轉依賴於一定的前提條件。
推理需求必須足夠充分,礦工獎勵才有意義;獎勵有意義,礦工才會留存;礦工數量充足,網絡質量才能維持。
這是一個需求驅動供給、供給維持需求的良性循環——但啟動這個循環恰恰是最困難的階段。
寶潔等企業客戶已經在生產環境中使用該網絡,這是個積極信號。但隨著網絡規模擴張,代幣價值與挖礦獎勵之間的平衡能否維持,仍有待觀察。
7. 隱私AI的必要性
Nesa試圖解決的問題很明確:改變用戶在使用AI時數據暴露給第三方的結構性困境。
技術基礎紮實可靠。其核心加密技術——等變加密(EE)和HSS-EE源自學術研究。推理優化調度器MetaInf已在COLM 2025主會議發表。
這不是簡單引用論文那麼簡單。研究團隊直接設計了協議,並將其實現在了網絡中。
在去中心化AI項目中,能夠在學術層面驗證自有加密原語,並將其部署到實際運行的基礎設施上的項目屈指可數。寶潔等大型企業已經在這套基礎設施上運行推理任務——對於早期項目而言,這是個頗具分量的信號。
話雖如此,侷限性同樣清晰可見:
- 市場範圍:機構客戶優先;普通用戶暫時不太可能為隱私付費
- 產品體驗:Playground更像Web3/投資工具界面,而非日常AI應用
- 規模驗證:受控基準測試≠數千併發節點的生產環境
- 市場時機:隱私AI的需求是真實存在的,但去中心化隱私AI的需求尚未得到驗證;企業仍習慣於中央化API
大多數企業仍習慣使用中央化API,採用基於區塊鏈的基礎設施門檻依然不低。
我們身處這樣一個時代:連美國網絡安全負責人都會將機密文件上傳給AI。對隱私AI的需求已然存在,且只會持續增長。
Nesa擁有經過學術驗證的技術和實際運行的基礎設施來滿足這種需求。儘管存在侷限性,但它的起點已經領先於其他項目。
當隱私AI市場真正打開時,Nesa必將是最先被提及的名字之一。






