


一個尚未盈利的AI公司,連續發佈三個模型後,不到三個月,中國前十大互聯網公司中有九家爭相接入了它。
4月8日,智譜AI在廣州發佈開源大模型GLM-5.1,這是繼2月12日GLM-5、3月16日GLM-5-Turbo之後的第三款模型。三款模型發佈後,一個有趣的現象反覆出現:大量國內企業密集在社交媒體、官網官宣“已接入”,涵蓋互聯網公司、雲服務商、軟件廠商、芯片企業,大中小皆有。
據公開信息可查證,GLM-5系列已獲得至少18家企業的公開接入或適配官宣,覆蓋四個層級:
互聯網頭部廠商中,字節跳動(TRAE編程助手)、阿里巴巴(Qoder)、騰訊(CodeBuddy/WorkBuddy全系)、百度(智能雲千帆平臺)、美團(CatPaw)、快手(萬擎)均已集成。智譜在上市後首份財報(3月31日)中明確表示,“GLM-5發佈後24小時內即獲得字節跳動TRAE/釦子Coze、阿里巴巴Qoder、騰訊CodeBuddy、美團CatPaw、快手萬擎、百度智能雲及WPS Office等頭部平臺產品的官方接入”,並稱“中國前10大互聯網公司中已有9家深度集成GLM”。GLM-5.1發佈當天,騰訊將CodeBuddy與WorkBuddy全線產品升級至GLM-5.1,百度宣佈完成“Day0全棧適配”,字節跳動TRAE實現Day0同步首發。
雲服務商方面,華為雲在發佈日當天即上線碼道(CodeArts)代碼智能體,用戶激增引發排隊;金山雲於4月10日上線星流平臺;優刻得早在GLM-5階段即完成接入。
軟件與硬件廠商中,金山辦公(WPS靈犀)、字節跳動旗下釦子Coze、模型路由平臺OpenRouter、軟通動力(機械革命“龍蝦盒子”終端首發搭載GLM-5-Turbo)分別以深度集成、API接入、硬件搭載等方式接入。值得注意的是,WPS靈犀實際接入時間(2月12日)早於其官方公告時間(2月14日),說明部分企業在正式官宣前已完成技術對接。
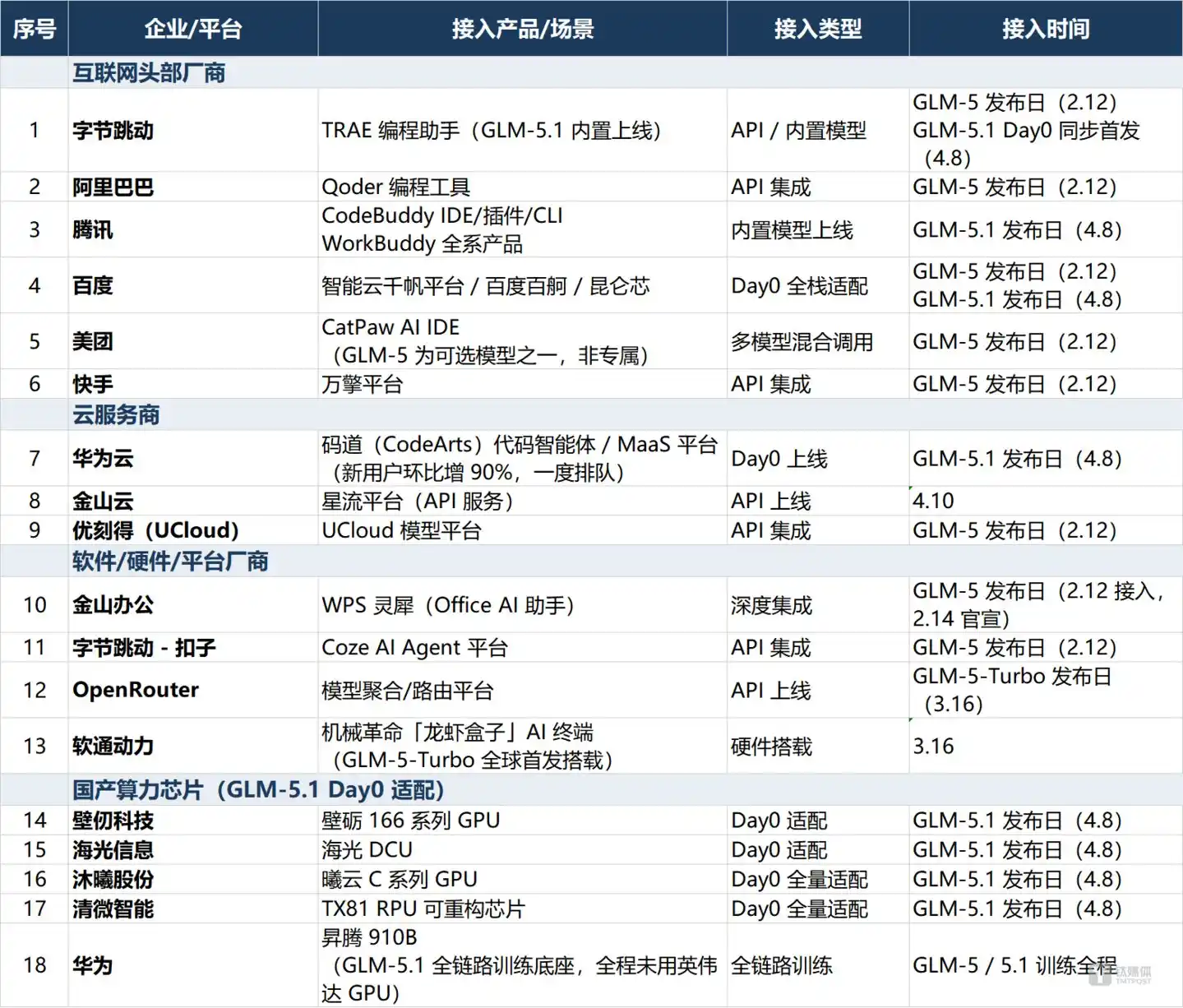
最值得關注的是國產算力芯片的集體“Day0適配”——壁仞科技(壁礪166系列)、海光信息(DCU)、沐曦股份(曦雲C系列)、清微智能(TX81 RPU)均在GLM-5.1發佈當日宣佈完成全量適配,加上全鏈路訓練底座華為升騰910B,構成了一條完整的國產算力適配鏈條。
這種景象並不陌生——每當國內頭部大模型發佈,接入官宣便如約而至。但這一次,官宣的密度和速度明顯高於以往,值得追問:這是模型真的足夠好,還是一場集體營銷?
答案可能兩者都有,但背後折射的是更深層的行業現實。GLM-5系列模型的接入潮,恰好是理解“中國大模型走到哪兒了”的一個切口。
為什麼這麼多企業選擇“官宣”接入?
有三條邏輯可以解釋這一現象。
第一,MIT開源協議大幅降低了接入成本和風險。 從GLM-4.5到GLM-5再到GLM-5.1,智譜的旗艦模型全部採用MIT協議開源——可商用、可私有化部署、無使用限制。對大量中小企業和政務機構來說,這是商業閉源API不可替代的門檻優勢:數據不必出內網,合規風險可控,採購審批更容易過。官宣接入的成本極低,理由卻足夠充分。
第二,編程能力的真實突破,給了部分企業接入的產品價值支撐。 GLM-5.1在SWE-Bench Pro編程測試中拿到58.4分,超過Claude Opus 4.6(57.3分)和GPT-5.4(57.7分),並首次在該基準上以國產開源模型身份實現對頂級閉源產品的超越。對軟件開發類企業而言,編程場景的能力提升是看得見的。接入不只是噱頭,至少在編程這一條線上有實際使用場景。
第三,“接入國產旗艦模型”本身具有營銷價值。 在政企採購、融資路演、媒體曝光的語境下,官宣接入頭部大模型是一張門檻不高但信號價值明顯的牌。這與模型本身厲不厲害關係不大——而是中國AI生態中特有的宣發慣例。
這三條邏輯,分別對應著技術、商業和生態三個層面的現實。要真正理解它們,需要從三個維度拆開來看:GLM-5.1的技術到底走到了哪裡,開源與閉源的路線之爭走到了哪裡,智譜的商業化走到了哪裡。
突破是真實的,但“偏科”代價不小
先說真實的進展。
GLM-5.1延續了GLM-5的MoE架構:744B總參數、256專家混合、約44B激活參數,在全鏈路華為升騰910B上完成訓練。嚴格來說,這不是一次架構迭代,而是後訓練階段的定向優化——在編程和Agent場景加大了強化學習權重。從GLM-5到GLM-5.1,間隔不到八週,迭代速度本身值得肯定。
核心突破集中在兩個方向。
其一,編程基準的數字躍升。 SWE-Bench Pro 58.4分,超越Claude Opus 4.6(57.3分)和GPT-5.4(57.7分),是國產開源模型在這一基準上的歷史最高分。在Terminal-Bench和NL2Repo兩項代碼評測的綜合平均中,GLM-5.1取得全球第三、國產第一、開源第一的排名。
其二,“長程任務”能力的首次量化驗證。 智譜將其定義為模型接收一項任務後持續工作數小時乃至更久的能力,官方展示了若干案例:模型在無監督下完成655輪迭代、超過6000次工具調用,將向量數據庫QPS從3,547提升至21,500;14小時內將GPU計算內核加速35.7倍;8小時內自主搭建出包含窗口管理器、終端模擬器、文件瀏覽器的完整Linux桌面環境。這種行為模式更接近一個初級工程師,而非高級搜索引擎。
但這裡有兩個必須標註的折扣。
折扣一:評測體系本身的可信度存疑。 今年3月,AI安全研究機構METR發佈研究指出,SWE-bench系列中被自動判定為“通過”的AI代碼方案,約有一半會被真實項目維護者拒絕,自動評測可能將AI編程能力高估達7倍。幾乎同期,OpenAI宣佈棄用SWE-bench Verified作為評估標準,理由是自動評測與實際開發效能的偏差已不可忽視。GLM-5.1與Claude Opus 4.6之間不到1分的差距,在METR揭示的誤差範圍內,“全球最強開源模型”的標籤需要審慎看待。
折扣二:能力分佈極不均勻。 Text Arena第三方競技場的細分排名清楚呈現了代價:編程較前代躍升28名,但醫療掉24名,法律掉6名,數學掉2名。NL2Repo(從零構建代碼倉庫)上落後Claude Opus 4.6達7分(42.7對49.8)。知乎開發者“晴天”用閱讀理解、SVG代碼生成等場景做橫向測試,結論是GLM-5.1連基本閱讀理解都未達標;另一位通過Ollama本地部署的開發者評價“整體不如Qwen3.6-Plus”。這些個體測試不代表全貌,但共同指向一個事實:GLM-5.1是一個在編程和Agent方向刻意訓練、其他領域有所犧牲的“偏科生”。
偏科並不是貶義詞,關鍵在於“偏的那個科”值不值得偏。
編程和自主執行,目前確實是AI行業競爭最密集的賽道。但需要清醒認識到,就在GLM-5.1發佈的同一天,Anthropic推出了Mythos Preview——SWE-Bench Pro拿到77.8分,領先GLM-5.1近20分。Mythos暫不公開,但它標定了行業能力的當前天花板,也說明競爭對手的儲備遠比已發佈的產品更深厚。
開源換信任,閉源換安全
GLM-5.1發佈當天,發生了一個對比鮮明的時間巧合。
太平洋彼岸,Anthropic官宣了新一代模型Claude Mythos Preview——但沒有向公眾開放,而是定向提供給蘋果、微軟、谷歌、英偉達等12家合作伙伴和40餘家基礎設施組織,用於一個名為“Project Glasswing”的網絡安全計劃。
同一天,兩家公司各出一手牌,方向截然相反:一家將模型權重全量上傳Hugging Face任人下載,另一家主動把最強模型鎖進了圍牆。
這個巧合,是當前AI行業最核心路線分歧的縮影。
智譜的開源邏輯,已經形成了清晰的商業飛輪設計:以MIT協議開源建立開發者信任→信任轉化為企業採購時的優先考量→通過API調用和Agent執行收費實現變現。這條路在中國政企市場有結構性優勢,數據合規要求高的行業(金融、政務、醫療)對“數據不出內網”有剛性需求,閉源API天然無法滿足。
Anthropic的閉源邏輯,則是另一套完全不同的證明路徑:以安全為品牌核心,以能力背書商業化,通過已驗證的企業服務口碑拉高定價。2025年,Anthropic ARR突破300億美元,首次超越OpenAI同期的250億美元——市場在用真金白銀認可這套邏輯的合理性。
兩條路哪條更對?這個問題可能本身就問錯了。更準確的表述是:兩條路在各自的目標市場裡,目前都找到了需求錨點。
但兩條路也各有各的真實風險。
智譜開源路線的隱患在於:開源能贏口碑,未必能贏市場定價權。 MIT協議意味著任何人可以免費使用模型權重,智譜的商業回報只能來自服務層的API和Agent——在一個主要競爭對手把Token定價壓到國際競品十分之一的市場裡,提價的空間天然受限。另外,GLM-5.1的全鏈路訓練深度綁定華為升騰910B,供應鏈集中化風險真實存在,壁仞科技、海光DCU等廠商雖已完成Day-0適配,但“適配完成”與“好用”之間的距離,仍待真實業務驗證。
Anthropic閉源路線的隱患在於:安全約束與實用能力之間的張力正在顯現。 近期Claude Code陷入“思考深度驟降67%”的爭議——AMD AI總監Stella Laurenzo基於6852條會話日誌公開指控其思考深度驟降,暴露了安全護欄對模型能力的實質性壓制。閉源路線的代價是:你為安全交的每一分學費,都會被用戶感知到。
提價是信號,但盈利拐點仍在遠處
3月31日,智譜披露上市後首份年報,數字非常矛盾。
好的一面:2025年收入7.24億元,同比增長132%,在國內獨立大模型廠商中排名第一。API收入暴增292.6%,Agent收入增長248.8%,MaaS平臺年度經常性收入達17億元,同比飆升60倍。平臺化轉型方向清晰。
難看的一面:淨虧損擴大至47.18億元,毛利率從56.3%下滑至41.0%,研發開支31.80億元是收入的4.4倍,四年累計虧損約85億元。以約4100億港元市值計算,市銷率接近500倍——市場幾乎完全在為未來定價,而非為當下定價。對比參考:騰訊當前市銷率約為5倍。
這份年報發佈後第二天,CEO張鵬在業績會上明確將Anthropic列為對標方向,原話是“當模型足夠強,API本身就是最好的商業模式”。當天股價大漲31.94%。市場接受了這個新敘事。
但“中國版Anthropic”的標籤,有一道繞不過去的數字鴻溝需要正視。
Anthropic的ARR是智譜全年總收入的約285倍。千餘家年消費超百萬美元的企業客戶,構成了Anthropic營收的基本盤——每一家背後是真實的合同、真實的工程師使用量和真實的續簽率。智譜目前的MaaS ARR 17億元摺合約2.3億美元,與Anthropic的體量不在同一量級,這說明“對標”和“追趕到”之間,還有相當長的路程。
更值得關注的是GLM-5.1發佈當天的一個定價動作:智譜逆勢將API價格上調10%,這是年內第三次提價——2026年一季度Token價格累計上調83%,但調用量反而增長了400%。這組數字是目前最有力的商業信號:價格敏感度不如想象中高,用戶對能力溢價有一定接受度。
但提價的持續性依賴三個假設,每個都有不確定性:
- 能力溢價是否可持續? 領先優勢高度集中在編程方向,對非編程場景並無顯著溢價支撐。
- 成本能否壓下來? 41%的毛利率意味著盈利拐點仍然很遠。
- 增速能否維持? 7.24億的基數放大後,維持130%以上增速的難度將顯著上升。
調價後,GLM-5.1在Coding場景緩存命中Token價格已接近Claude Sonnet 4.6水平——注意,是Sonnet,不是Opus。Claude Opus 4.6的API定價仍顯著高於智譜。對企業用戶而言,同樣的價格,面臨的是“生態更成熟的Claude”與“性能接近但確定性存疑的GLM-5.1”之間的權衡。
從“追趕”進入“攻堅”階段
回到最初的問題:為什麼這麼多企業爭著官宣接入GLM-5.1?
部分原因是這個模型真的值得評估,特別是在編程自動化場景;部分原因是MIT開源協議提供了接入的低成本理由;還有一部分,坦率說,是慣例使然。
但從企業接入潮這個切口望進去,能看到的比一款模型發佈更多:中國大模型行業正在從粗放的“追趕期”進入精細的“攻堅期”。
追趕期的標誌是,國產模型在關鍵基準上與全球頂尖水平的差距從“代際差”縮小到“個位數差”——這一步,GLM-5.1在編程方向上已經走到了。
攻堅期的難題是,技術領先能否轉化成商業壁壘、開源信任能否轉化成定價能力、鉅額研發投入何時能在利潤表上留下正向的印記。這三個問題,智譜沒有回答,整個國產大模型行業都還沒有回答。
GLM-5.1的發佈,證明了中國大模型在特定領域已經能和全球最頂尖的產品同臺競技。但“同臺競技”和“贏下市場”之間,仍然是一段沒有路標的旅程。(本文首發鈦媒體APP,作者 | 硅谷Tech_news,編輯 | 焦燕)






