【Sentient 新基礎設施 ROMA 評測】
大家好,我是 Nyangburger。
Sentient 最近舉辦了一場精彩的活動,所以我決定第一時間參與。
我將撰寫一篇關於 Sentient 新基礎設施項目 ROMA(遞歸開放元代理)的深度評測。
我將深入探討細節,並在構建虛擬測試環境的過程中分享我的想法。
簡而言之,ROMA 不僅僅是一個簡單的代理;它有潛力成為解決 AI 推理“信任”問題的關鍵基礎設施。
讓我們分析一下 ROMA 在此時此刻為何如此重要,以及它與現有模型有何不同。
黑盒 AI 的終結與“遞歸推理”的開端
常用的 LLM 和代理最大的問題是什麼?它們在“長週期任務”中表現不佳。雖然它擅長總結以太坊白皮書,但如果你讓它“分析過去三年排名前十的 DeFi 協議的表現,並將其與宏觀經濟指標進行比較”,它就會迷失方向,甚至出現幻覺。這是因為在人工智能的運行過程中,錯誤會逐步累積。
然而,由 Sentient 開發的 ROMA 憑藉其“遞歸結構”和“透明性”正面解決了這個問題。
{1. ROMA 的核心架構:像 CEO 一樣工作的 AI}
為了便於理解 ROMA,可以想象一個“高效的組織架構圖”。
傳統的智能體就像一個獨自敲鼓的自由職業者,而 ROMA 則是一個“元智能體”,它會不斷地將任務分解成子任務並進行分配。
ROMA 通過以下四階段無限循環來解決複雜問題:
第一階段:原子化器:評估傳入的任務。您可以獨立判斷一項任務是否能夠獨立完成,或者是否需要將其分解成更小的部分。
步驟 2:規劃器:如果需要分解,它會將任務分解成子任務,就像項目經理將任務分解成開發、設計和規劃階段一樣。
步驟 3:執行器:利用搜索工具、數據分析工具或其他專用 AI 模型執行分解後的任務。
步驟 4:聚合器:收集並驗證每次執行的結果,並將它們彙總成最終報告。
ROMA 的遞歸特性就體現在這個過程中。如果子任務很複雜,則會重複這四個步驟,深入挖掘樹狀結構。
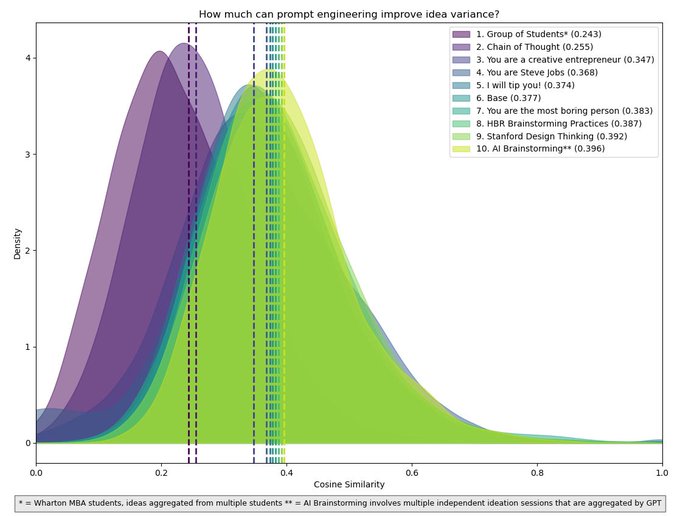
{2. 超強性能:數據說話}
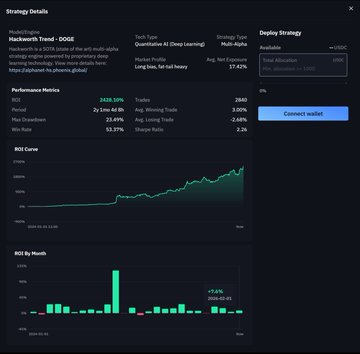
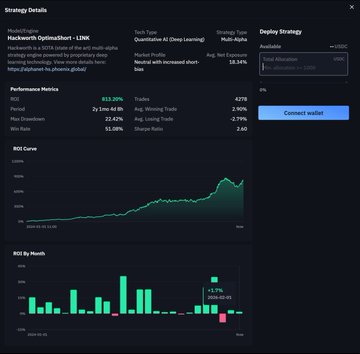
在 Web3 領域,規則是“不要輕信,要驗證”。ROMA 的性能已通過基準測試數據得到驗證。Seal-0 基準測試結果令人震驚,該測試旨在檢驗其複雜的搜索和推理能力。
ROMA 搜索:45.6%(遙遙領先,位居榜首)
Kimi Researcher:36%
Gemini 2.5 Pro:19.8%
Open Deep Search:8.9%
ROMA 的準確率是 Google Gemini 的兩倍以上。這有力地證明了 ROMA 並非簡單地抓取信息,而是在保持上下文的情況下進行邏輯推理。
{3. 為什麼 Web3 和開發者需要 ROMA?(實用性和清晰度)}
我被這個框架吸引,不僅是因為它的性能,還因為 ROMA 的理念基於開源和透明。
打破黑箱(階段追蹤):
現有的商業代理程序只是提供結果,卻無法解釋結果背後的原因。然而,ROMA 提供了“階段追蹤”功能。從輸入到輸出的整個推理過程,都通過 Pydantic 架構透明地呈現。調試是可能的,並且可以通過人為干預(人機交互)來識別錯誤。
這在信任至關重要的領域(例如鏈上數據分析和財務報告)尤為重要。
模塊化:
ROMA 就像樂高積木。您可以自由地將所需的 LLM(GPT-4、Claude、Llama 等)或工具插入到每個節點(階段)中。
利用模塊化的一個策略示例是成本效益策略:將規劃階段外包給智能的 GPT-4 模型,將簡單的搜索外包給輕量級的 Llama 模型。
並行性:
獨立的子任務並行運行。這極大地加速了需要處理海量數據的研究任務。
{4. 結語:Sentient 的宏偉願景
Sentient 相信,ROMA 開啟了一個“任何人都可以使用最佳技術構建自己的代理”的世界。
這不僅僅是一個工具;它更像是一個完整的協議。
儘管當前的人工智能領域以封閉模型為主導,但 ROMA 提供了一個堅實的基礎,開源社區可以在此基礎上構建針對金融、法律和創意寫作等領域的專用“專家代理”。
基於此基礎,我相信 Sentient 將進一步鞏固其在人工智能領域的地位。
twitter.com/CalligramReboot/st...