

정리 : 새로운

6월 2일 저녁, NVIDIA CEO Jen-Hsun Huang은 타이베이에서 열린 ComputeX 2024 컨퍼런스에서 가속 컴퓨팅 및 생성 AI 분야에서 NVIDIA의 최신 성과를 시연했으며, 미래 컴퓨팅 및 로봇 기술을 위한 개발 청사진도 제시했습니다.

이번 연설에서는 기초 AI 기술부터 다양한 산업 분야의 미래 로봇 공학, 생성 AI 애플리케이션까지 모든 내용을 다루며, 컴퓨팅 기술 변화를 촉진하는 데 있어 NVIDIA의 뛰어난 성과를 종합적으로 보여주었습니다.

Huang Renxun은 NVIDIA가 NVIDIA의 영혼인 컴퓨터 그래픽, 시뮬레이션 및 AI의 교차점에 위치하고 있다고 말했습니다. 오늘날 우리에게 보여진 모든 것은 아날로그이며, 수학, 과학, 컴퓨터 과학, 놀라운 컴퓨터 아키텍처의 조합입니다. 이것은 애니메이션이 아니라 직접 만든 애니메이션이며 Nvidia는 이를 모두 Omniverse 가상 세계에 통합했습니다.
가속 컴퓨팅 및 AI
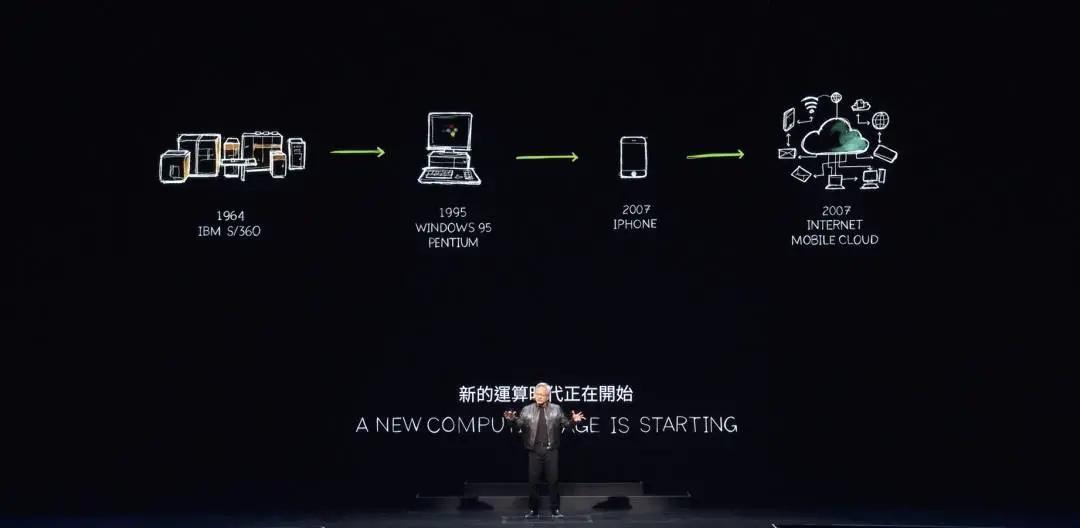
Huang Renxun은 우리가 보는 모든 것의 기초는 Omniverse 내에서 실행되는 가속 컴퓨팅과 AI라는 두 가지 기본 기술이라고 말했습니다. 이 두 가지 컴퓨팅 기본 힘은 컴퓨터 산업을 재편할 것입니다. 컴퓨터 산업은 60년의 역사를 가지고 있습니다. 여러 면에서 오늘날 우리가 하는 모든 일은 Jensen Huang이 1964년에 태어난 지 1년 후에 발명되었습니다.
IBM System 360은 중앙 처리 장치, 범용 컴퓨팅, 운영 체제를 통한 하드웨어와 소프트웨어 분리, 멀티태스킹, IO 하위 시스템, DMA 및 오늘날 사용되는 다양한 기술을 도입했습니다. 아키텍처 호환성, 이전 버전과의 호환성, 제품군 호환성 등 오늘날 우리가 컴퓨터에 대해 알고 있는 모든 것은 대부분 1964년에 설명되었습니다. 물론 PC 혁명은 컴퓨팅을 민주화하여 모든 사람의 손과 집에 제공했습니다.
2007년 iPhone은 모바일 컴퓨팅을 도입하여 컴퓨터를 주머니에 넣었습니다. 그 시점부터 모든 것이 모바일 클라우드를 통해 항상 연결되어 실행됩니다. 지난 60년 동안 우리는 많지는 않지만 두세 번 정도의 주요 기술 변화와 컴퓨팅 분야의 구조적 변화를 두세 번 목격했으며, 곧 이 모든 일이 다시 일어나는 것을 보게 될 것입니다.

두 가지 기본적인 일이 일어나고 있습니다. 첫 번째는 컴퓨터 산업을 운영하는 중앙 처리 장치인 프로세서의 성능 향상이 크게 둔화되었다는 것입니다. 그러나 우리가 수행해야 하는 계산의 양은 여전히 기하급수적으로 빠르게 증가하고 있습니다. 처리 수요, 처리해야 할 데이터의 양이 기하급수적으로 계속 증가하지만 성능이 향상되지 않으면 계산 인플레이션이 발생합니다. 사실 우리는 지금 이것을 보고 있습니다. 전 세계 데이터 센터에서 사용되는 전기의 양은 대폭상승 있습니다. 컴퓨팅 비용도 증가하고 있습니다. 우리는 계산된 인플레이션을 경험하고 있습니다.
물론 이것은 계속될 수 없습니다. 데이터 볼륨은 계속해서 기하급수적으로 증가할 것이며 CPU 성능 향상은 결코 회복되지 않을 것입니다. 더 나은 방법이 있습니다. Nvidia는 거의 20년 동안 가속 컴퓨팅을 연구해 왔습니다. CUDA는 CPU를 강화하여 특수 프로세서가 더 잘 수행할 수 있는 작업을 오프로드하고 가속화합니다. 실제로 성능이 너무 좋아서 CPU 성능 향상이 느려지고 결국 크게 중단됨에 따라 모든 작업의 속도를 높여야 한다는 것이 이제 분명해졌습니다.

Huang은 처리 대량 모든 애플리케이션이 가속화될 것이며 가까운 미래에는 확실히 모든 데이터 센터가 가속화될 것이라고 예측합니다. 이제 계산 속도를 높이는 것이 합리적입니다. 애플리케이션을 보면 여기서 100t는 100시간 단위를 나타내며 100초가 될 수도 있고 100시간이 될 수도 있습니다. 아시다시피 많은 경우 AI 애플리케이션은 이제 100일 동안 실행되는 것으로 검토되고 있습니다.
1T 코드는 단일 스레드 CPU가 매우 중요한 순차 처리가 필요한 코드를 나타냅니다. 운영 체제 제어 논리는 매우 중요하며 한 명령씩 실행해야 합니다. 그러나 컴퓨터 그래픽 처리와 같이 완전히 병렬로 작동할 수 있는 알고리즘은 많이 있습니다. 컴퓨터 그래픽 처리, 이미지 처리, 물리적 시뮬레이션, 조합 최적화, 그래프 처리, 데이터베이스 처리는 물론 딥러닝에서 잘 알려진 선형 대수학까지 이러한 알고리즘은 모두 병렬 처리를 통한 가속에 매우 적합합니다.
그래서 CPU에 GPU를 추가하여 아키텍처를 발명했습니다. 전용 프로세서는 장기 실행 작업을 매우 빠른 속도로 가속화할 수 있습니다. 이 두 프로세서는 나란히 작동할 수 있기 때문에 자율적이고 독립적이며 원래 100시간 단위가 걸리던 작업을 1시간 단위로 가속화할 수 있으며 속도 증가 효과는 100배 이상으로 매우 큽니다. , 그러나 전력 소비는 약 3배 정도 증가하고 비용은 약 50%만 증가합니다. 이는 PC 업계에서 이루어졌습니다. NVIDIA는 1,000달러짜리 PC에 500달러짜리 GeForce GPU를 추가하면 성능이 크게 향상됩니다. NVIDIA는 데이터 센터에서도 이 일을 합니다. 10억 달러 규모의 데이터 센터에 5억 달러 규모의 GPU를 추가하면 갑자기 AI 공장이 되고, 이런 일이 전 세계에서 일어나고 있습니다.
비용 절감 효과는 엄청납니다. 1달러를 소비할 때마다 성능은 60배, 속도는 100배 증가하는 동시에 전력 소비는 3배, 비용은 1.5배만 증가합니다. 절약 효과는 엄청납니다. 비용 절감은 달러로 측정할 수 있습니다.
많은 기업이 클라우드에서 데이터를 처리하는 데 수억 달러를 지출하고 있다는 것은 분명합니다. 이러한 프로세스가 가속화된다면 수억 달러의 비용 절감을 상상하는 것은 어렵지 않습니다. 이는 일반 컴퓨팅이 오랫동안 인플레이션을 겪었기 때문이다.

이제 최종적으로 계산 속도를 높이기로 결정되었으므로 현재 복구할 수 있는 포집된 손실이 대량 시스템에서 배출할 수 있는 잔류 폐기물도 많습니다. 이는 돈 절약과 에너지 절약으로 이어질 것입니다. 이것이 바로 Jen-Hsun Huang이 종종 "더 많이 구매할수록 더 많이 절약할 수 있습니다"라고 말하는 이유입니다.
Huang Renxun은 또한 가속 컴퓨팅이 놀라운 결과를 가져오지만 쉽지 않다고 말했습니다. 그렇게 많은 돈을 절약할 수 있는데 왜 사람들은 그렇게 오랫동안 하지 않았나요? 그 이유는 매우 어렵기 때문이다. C 컴파일러를 통해 실행될 수 있는 소프트웨어는 없으며 갑자기 애플리케이션이 100배 빨라졌습니다. 논리적이지도 않습니다. 그렇게 할 수 있었다면 CPU를 개조했을 것입니다.
소프트웨어를 다시 작성해야 한다는 사실이 가장 어려운 부분이었습니다. CPU에 작성된 알고리즘을 다시 표현하여 가속, 오프로드 및 병렬 실행이 가능하도록 소프트웨어를 완전히 다시 작성해야 했습니다. 컴퓨터 과학에서 이 연습은 매우 어렵습니다.

Huang Renxun은 지난 20년 동안 NVIDIA가 세상을 더 쉽게 만들어 왔다고 말했습니다. 물론 아주 유명한 cuDNN은 신경망을 다루는 딥러닝 라이브러리입니다. Nvidia에는 유체 역학 및 신경망이 물리 법칙을 준수해야 하는 기타 여러 애플리케이션에 사용할 수 있는 AI 물리 라이브러리가 있습니다. NVIDIA는 전 세계 네트워크인 인터넷이 정의된 것과 동일한 방식으로 통신 네트워크를 정의하고 가속화할 수 있는 CUDA 가속 5G 라디오인 Arial Ran이라는 훌륭한 새 라이브러리를 보유하고 있습니다. 가속화 기능을 통해 모든 통신을 클라우드 컴퓨팅 플랫폼과 동일한 유형의 플랫폼으로 변환할 수 있습니다.
cuLITHO는 칩 제조에서 가장 계산 집약적인 부분인 마스크 제작을 처리할 수 있는 전산 리소그래피 플랫폼입니다. TSMC는 생산에 cuLITHO를 사용하여 대량 에너지와 비용을 절약하고 있습니다. TSMC는 더 깊고 좁은 트랜지스터에 대한 추가 알고리즘 및 계산을 준비하기 위해 스택 속도를 높이는 것을 목표로 합니다. Parabricks는 NVIDIA의 유전자 시퀀싱 라이브러리로, 세계 최고 처리량의 유전자 시퀀싱 라이브러리입니다. cuOpt는 조합 최적화, 경로 계획 최적화, 매우 복잡한 순회 판매원 문제 해결을 위한 놀라운 라이브러리입니다.
과학자들은 일반적으로 이 문제를 해결하려면 양자 컴퓨터가 필요하다는 데 동의합니다. NVIDIA는 가속 컴퓨팅에서 실행되고 매우 빠르게 실행되는 알고리즘을 개발하여 23개의 세계 기록을 세웠습니다. cuQuantum은 양자 컴퓨터 시뮬레이션 시스템입니다. 양자 컴퓨터를 설계하려면 시뮬레이터가 필요합니다. 양자 알고리즘을 설계하려면 양자 시뮬레이터가 필요합니다. 양자 컴퓨터가 존재하지 않는다면 이러한 양자 컴퓨터를 어떻게 설계하고 이러한 양자 알고리즘을 생성합니까? 여러분은 오늘날 세계에서 가장 빠른 컴퓨터를 사용하고 있습니다. 바로 NVIDIA CUDA입니다. 위에서 Nvidia에는 양자 컴퓨터를 시뮬레이션하는 시뮬레이터가 있습니다. 전 세계 수십만 명의 연구자가 사용하고 있으며 모든 주요 양자 컴퓨팅 프레임 에 통합되어 있으며 과학 슈퍼컴퓨팅 센터에서 널리 사용됩니다.
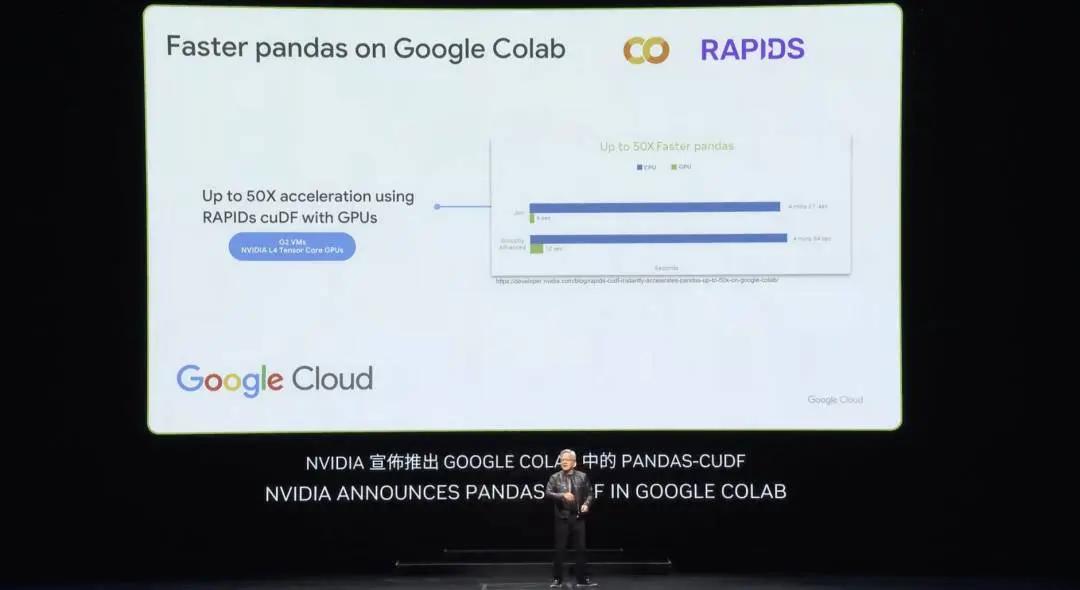
cuDF는 놀라운 데이터 처리 라이브러리입니다. 데이터 처리는 오늘날 클라우드 지출의 대부분을 차지하므로 모두 가속화되어야 합니다. cuDF는 많은 기업에서 사용하고 있는 Spark, Polars라는 새로운 라이브러리인 Pandas, 그래프 처리 데이터베이스 라이브러리인 NetworkX 등 전 세계에서 사용되는 주요 라이브러리를 가속화합니다. 이것들은 단지 몇 가지 예일 뿐이고, 다른 많은 예들도 있습니다.
Huang은 Nvidia가 생태계가 가속화된 컴퓨팅을 활용할 수 있도록 이러한 라이브러리를 만들어야 한다고 말했습니다. NVIDIA가 cuDNN을 만들지 않았다면 CUDA, TensorFlow 및 PyTorch에서 사용되는 알고리즘 간의 거리가 너무 멀기 때문에 CUDA만으로는 전 세계 딥 러닝 과학자들이 사용할 수 없었을 것입니다. 이는 OpenGL 없이 컴퓨터 그래픽을 수행하거나 SQL 없이 데이터를 처리하는 것과 거의 같습니다. 이러한 도메인별 라이브러리는 총 350개의 라이브러리로 구성된 NVIDIA의 보물입니다. Nvidia가 수많은 시장을 열 수 있게 해주는 것은 바로 이러한 라이브러리입니다.
지난주 Google은 세계에서 가장 인기 있는 데이터 과학 라이브러리인 Pandas를 클라우드에서 가속화할 것이라고 발표했습니다. 여러분 중 많은 분이 이미 전 세계 천만 명의 데이터 과학자가 사용하고 매달 1억 7천만 번 다운로드되는 Pandas를 사용하고 계실 것입니다. 데이터 과학자의 스프레드시트입니다. 이제 단 한 번의 클릭만으로 cuDF를 사용해 Google 클라우드 데이터센터 플랫폼인 Colab에서 Pandas를 가속화할 수 있는데, 가속 효과는 정말 놀랍습니다.
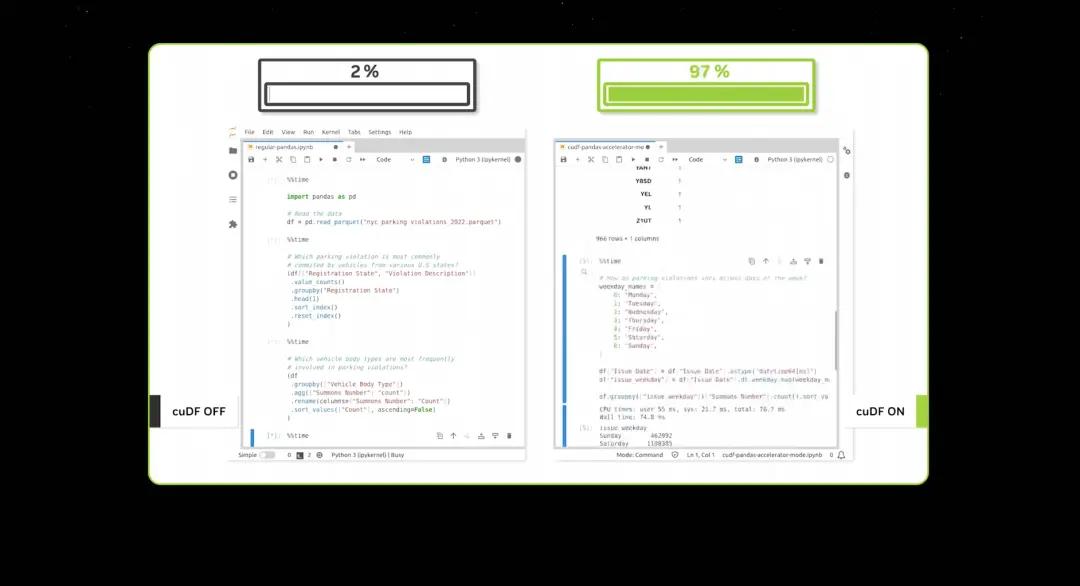
데이터 처리를 매우 빠르게 가속화하면 데모에 실제로 시간이 오래 걸리지 않습니다. 이제 CUDA는 소위 티핑 포인트(tipping point)에 도달했지만 훨씬 더 좋습니다. CUDA는 이제 선순환을 달성했습니다.
이런 일은 거의 발생하지 않습니다. 역사 전반에 걸쳐 모든 컴퓨팅 아키텍처의 플랫폼을 살펴보면. 마이크로프로세서 CPU를 예로 들면, 60년 동안이나 이 수준에서 변하지 않았습니다. 이러한 유형의 컴퓨팅, 가속 컴퓨팅은 이미 존재하며, 새로운 플랫폼을 만드는 것은 닭과 달걀의 문제이기 때문에 매우 어렵습니다.
귀하의 플랫폼을 사용하는 개발자가 없다면 당연히 사용자도 없을 것입니다. 하지만 사용자가 없으면 설치 기반도 없습니다. 설치 기반이 없으면 개발자는 관심을 갖지 않습니다. 개발자는 대규모 설치 기반을 위한 소프트웨어를 작성하고 싶어하지만 대규모 설치 기반에는 사용자가 설치 기반을 만들도록 유도하기 위해 대량 의 응용 프로그램이 필요합니다.
이 닭고기와 달걀이라는 질문은 거의 깨지지 않습니다. NVIDIA는 분야별로 라이브러리를 구축하고 가속 라이브러리를 하나씩 구축하는 데 20년을 보냈습니다. 이제 전 세계적으로 500만 명의 개발자가 NVIDIA 플랫폼을 사용하고 있습니다.
NVIDIA는 의료부터 금융 서비스, 컴퓨터 산업, 자동차 산업, 거의 모든 주요 산업, 거의 모든 과학 분야에 이르기까지 모든 산업에 서비스를 제공하고 있으며 NVIDIA의 아키텍처에는 너무 많은 고객이 있기 때문에 OEM 및 클라우드 서비스 제공업체는 NVIDIA 시스템 구축에 관심이 있습니다. 이곳 대만과 같은 우수한 시스템 구축업체는 Nvidia의 시스템 구축에 관심이 있습니다. 이를 통해 시장에서 선택할 수 있는 시스템이 더 많아지고, 이는 물론 R&D 규모를 확장할 수 있는 더 큰 기회를 창출하여 더욱 가속화됩니다. 애플리케이션.
애플리케이션 속도를 높일 때마다 계산 비용은 감소합니다. 100배 가속은 97%, 96%, 98% 절감을 의미합니다. 따라서 100배 속도 향상에서 200배 속도 향상, 1000배 속도 향상으로 진행함에 따라 계산의 한계 비용은 계속해서 감소합니다.
NVIDIA는 컴퓨팅 비용을 대폭 절감함으로써 시장, 개발자, 과학자 및 발명가가 점점 더 많은 컴퓨팅 리소스를 소비하는 알고리즘을 점점 더 많이 발견하고 궁극적으로 컴퓨팅 한계 비용의 질적 도약이 있을 것이라고 믿습니다. 컴퓨팅을 사용하는 새로운 방법이 등장했다는 의미입니다.
사실, 이것이 바로 지금 일어나고 있는 일입니다. 수년에 걸쳐 NVIDIA는 지난 10년 동안 특정 알고리즘의 한계 계산 비용을 백만 배나 줄였습니다. 따라서 전체 인터넷 데이터를 포함하는 LLM을 교육하는 것은 이제 매우 합리적이고 상식이며 누구도 의심하지 않을 것입니다. 자신만의 소프트웨어를 작성할 만큼 많은 데이터를 처리할 수 있는 컴퓨터를 만들 수 있다는 생각입니다. AI는 컴퓨팅을 점점 더 저렴하게 만들면 누군가가 이를 유용하게 사용할 것이라는 완전한 믿음에서 탄생했습니다.
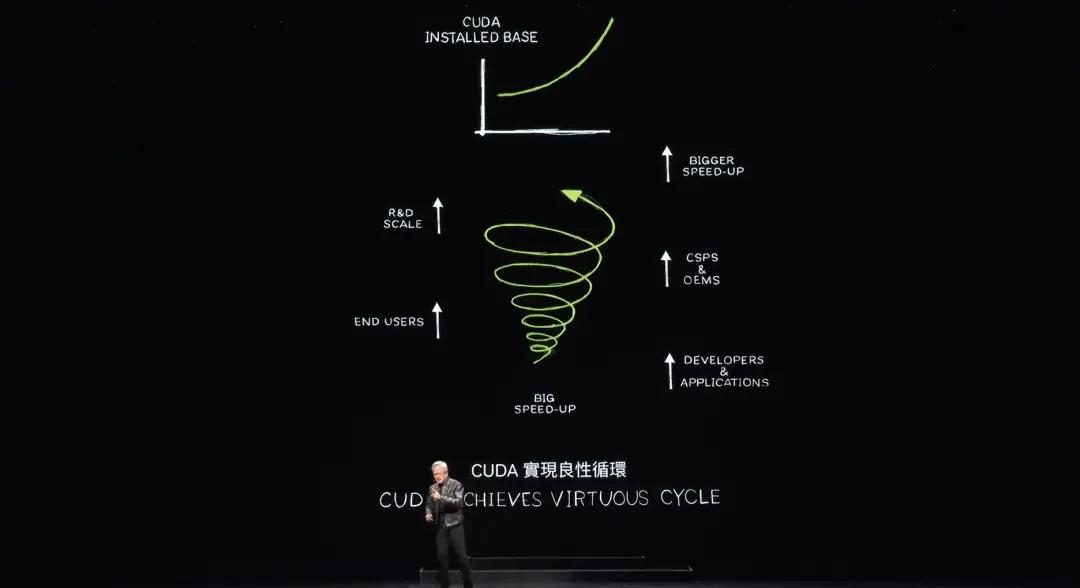
오늘날 CUDA는 선순환을 달성했습니다. 설치 기반이 증가하고 컴퓨팅 비용이 감소하여 더 많은 개발자가 더 많은 아이디어를 내놓고 더 많은 수요가 발생합니다. 이제 우리는 매우 중요한 출발점에 와 있습니다.
황은 계속해서 지구의 디지털 트윈을 생성할 어스 2(Earth 2) 아이디어를 언급했습니다. 지구를 시뮬레이션함으로써 미래를 더 잘 예측하고 재난을 더 잘 피할 수 있으며, 기후 변화의 영향을 더 잘 이해할 수 있습니다. 더 나은 적응.

연구원들이 2012년에 CUDA를 발견했는데, 이는 NVIDIA가 AI와 처음으로 접촉한 날이었습니다. 딥러닝을 가능하게 하는 과학자들과 함께 일할 수 있다는 것은 특권입니다.
AlexNet은 엄청난 컴퓨터 비전 혁신을 달성했습니다. 그러나 더 중요한 것은 한발 물러서서 딥 러닝의 배경과 기초, 장기적인 영향과 잠재력을 이해하는 것이 중요합니다. NVIDIA는 이 기술이 확장할 수 있는 엄청난 잠재력을 가지고 있다는 것을 알고 있습니다. 수십 년 전에 발명되고 발견된 알고리즘이 갑자기 더 많은 데이터, 더 큰 네트워크, 그리고 매우 중요하게 더 많은 컴퓨팅 리소스로 인해 딥 러닝은 인간 알고리즘이 할 수 없는 일을 달성합니다.
이제 더 큰 네트워크, 더 많은 데이터, 더 많은 컴퓨팅 리소스를 사용하여 아키텍처를 더욱 확장하면 어떤 일이 가능할지 상상해 보십시오. 2012년 이후 NVIDIA는 GPU 아키텍처를 변경하고 Tensor 코어를 추가했습니다. NVIDIA는 10년 전 NVLink를 발명했고, CUDA, TensorRT, NCCL이 Mellanox, TensorRT-ML, Triton 추론 서버를 인수하여 모두 새로운 컴퓨터에 통합되었습니다. 아무도 그것을 이해하지 못하고, 누구도 그것을 요구하지 않으며, 누구도 그 의미를 이해하지 못합니다.
실제로 Huang은 아무도 그것을 사고 싶어하지 않을 것이라고 확신했기 때문에 Nvidia는 GTC에서 이를 발표했고 샌프란시스코에 본사를 둔 소규모 회사인 OpenAI는 Nvidia에게 하나를 제공해달라고 요청했습니다.
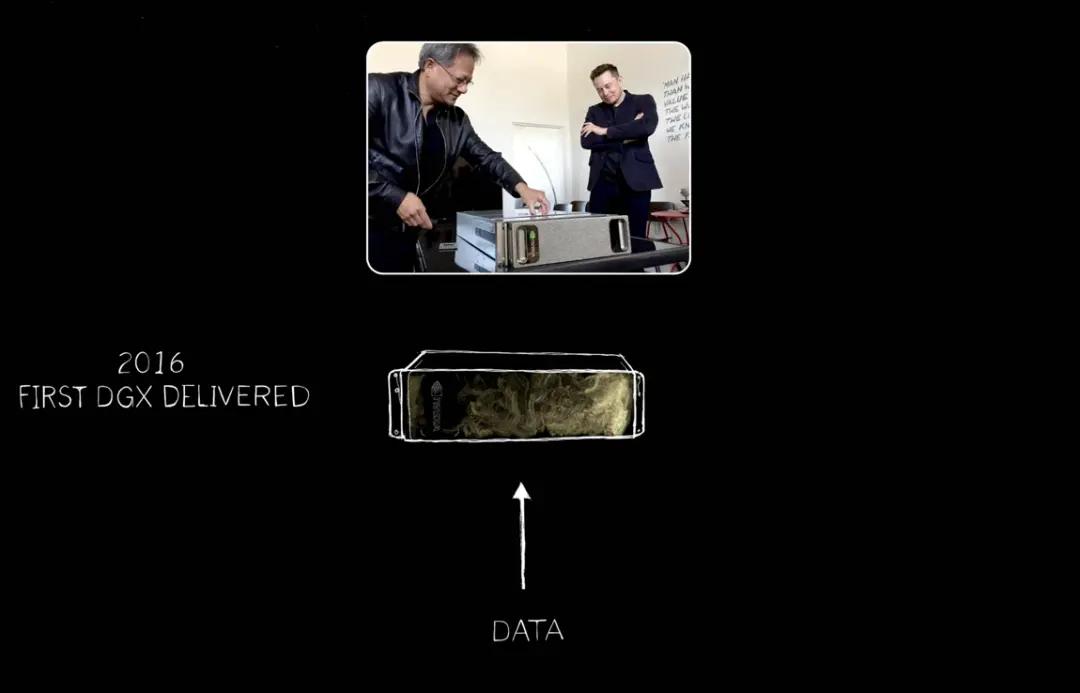
2016년 Jen-Hsun Huang은 세계 최초의 AI 슈퍼컴퓨터인 최초의 DGX를 OpenAI에 제공했습니다. 그 후에는 AI 슈퍼컴퓨터, AI 장치에서 대형 슈퍼컴퓨터 또는 더 큰 규모로 계속 확장하세요.
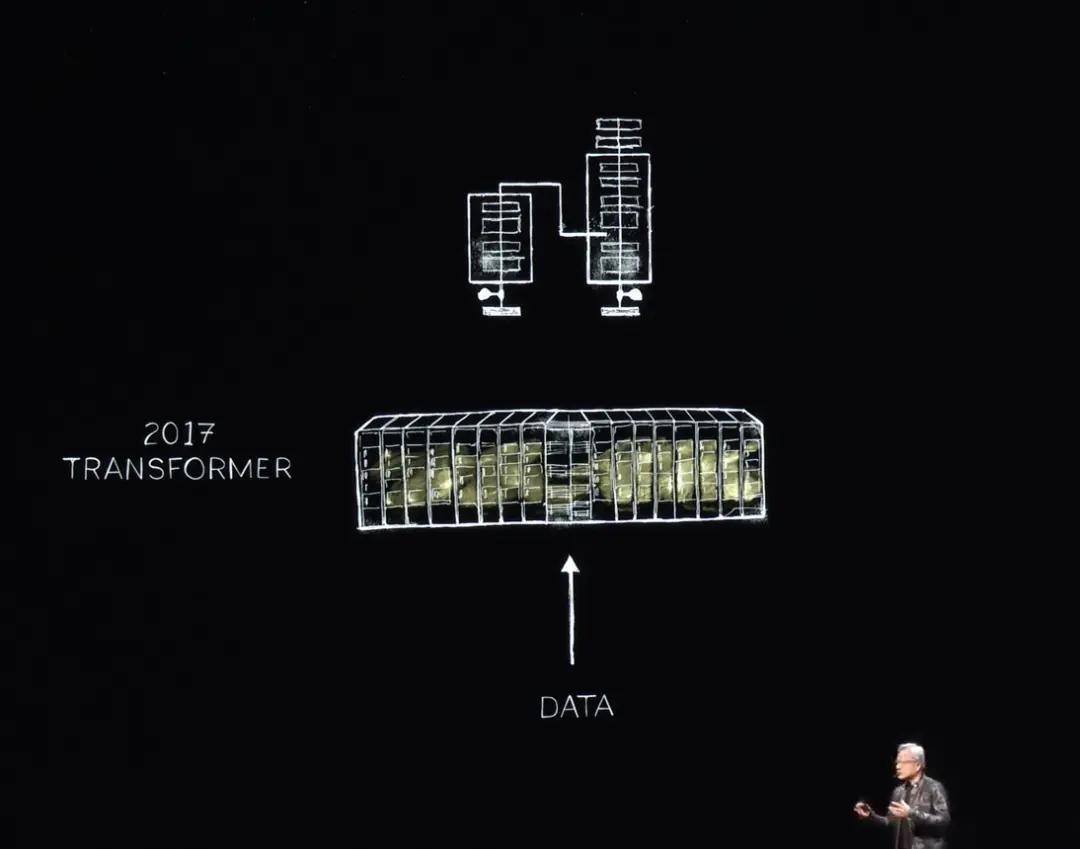
2017년까지 전 세계는 대량 교육을 통해 장기적인 시퀀스 패턴을 식별하고 학습할 수 있는 Transformer를 발견했습니다. 이제 NVIDIA는 이러한 LLM을 교육하여 자연어 이해의 획기적인 발전을 이룰 수 있습니다. 계속해서 더 큰 시스템이 구축되었습니다.
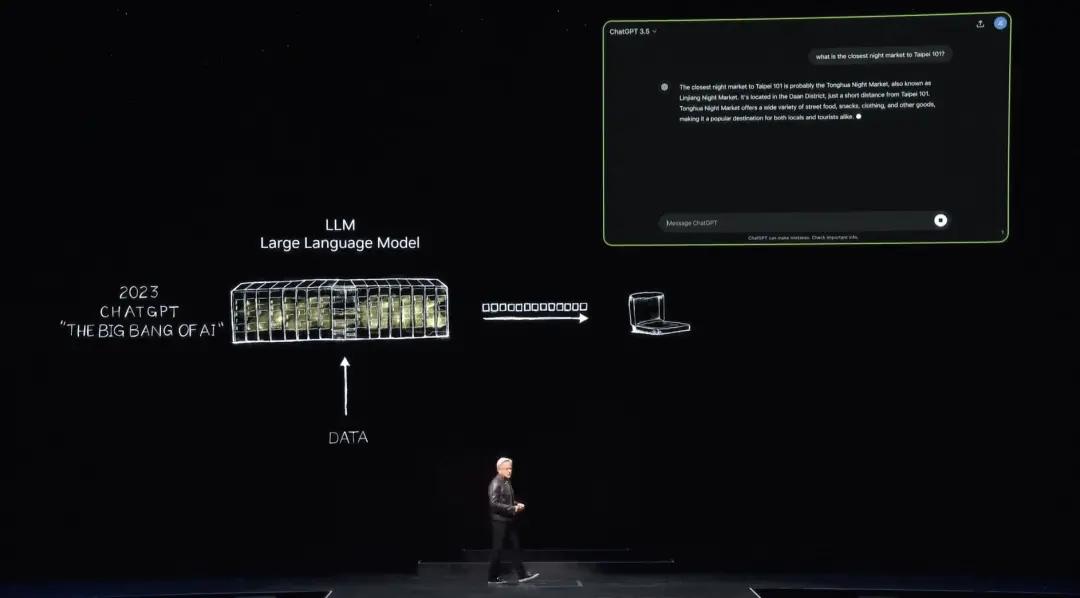
그런 다음 2022년 11월, OpenAI는 훈련을 위해 수천 대의 Nvidia GPU와 초대형 AI 슈퍼컴퓨터를 사용하여 ChatGPT를 출시했습니다. 이는 5일 만에 100만 명, 2개월 만에 1억 명에 도달하여 역사상 최대 규모의 Quick 애플리케이션이 되었습니다.
ChatGPT가 세상에 공개되기 전에 AI는 인식, 자연어 이해, 컴퓨터 비전, 음성 인식에 관한 것이었습니다. 그것은 인식과 탐지에 관한 것입니다. 생성 AI 문제를 세계 최초로 토큰을 생성하여 해결한 것은 이번이 처음이며, 이 토큰은 단어입니다. 물론 일부 토큰은 이제 이미지, 차트, 표, 노래, 단어, 음성 및 비디오가 될 수 있습니다. 이러한 토큰은 의미를 이해할 수 있는 모든 것이 될 수 있으며 화학적 토큰, 단백질 토큰, 유전자 토큰이 될 수 있습니다. 이전에 Earth 2 프로젝트에서 본 것은 생성된 날씨 토큰이었습니다.
우리는 물리학을 이해할 수 있고 배울 수 있습니다. 물리학을 배울 수 있다면 AI 모델의 물리학을 가르칠 수 있습니다. AI 모델은 물리학의 의미를 학습한 후 물리학을 생성할 수 있습니다. 필터링이 아닌 생성을 통해 1km로 좁혔습니다. 따라서 우리는 이 방법을 사용하여 거의 모든 가치 있는 토큰을 생성할 수 있습니다. 자동차의 스티어링 휠 컨트롤과 로봇 팔의 모션을 생성할 수 있습니다. 우리가 배울 수 있는 모든 것은 이제 생성될 수 있습니다.
AI공장
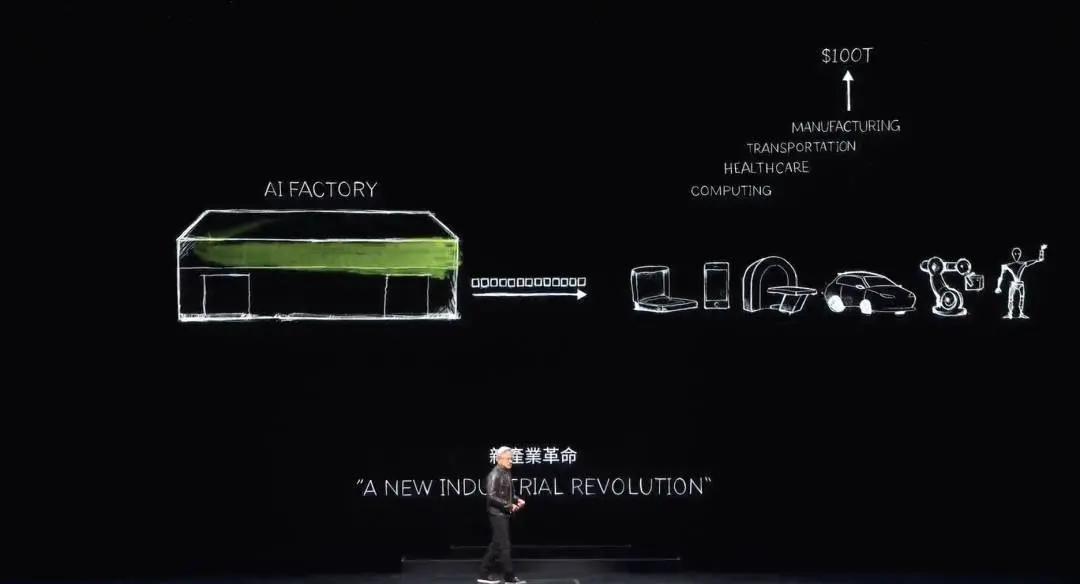
이제 우리는 생성 AI 시대에 진입했습니다. 그러나 정말 중요한 것은 원래 슈퍼컴퓨터 역할을 했던 이 컴퓨터가 이제는 데이터 센터로 진화했다는 것입니다. 그것은 단 하나의 것, 즉 토큰을 생성하고 생성하고... 생산하는 AI 공장입니다. 큰 가치를 지닌 새로운 상품.
1890년대 후반 니콜라 테슬라는 발전기를 발명했고, 엔비디아는 AI 발전기를 발명했다. 발전기는 전자를 생성하고 NVIDIA AI 생성기는 토큰을 생성합니다. 이 두 가지 모두 시장에서 큰 기회를 가지며 거의 모든 산업에서 완전히 대체 가능합니다. 이것이 바로 이것이 새로운 산업 혁명인 이유입니다.
Nvidia는 이제 특별한 가치를 제공하는 모든 산업을 위한 새로운 상품을 생산하는 새로운 공장을 갖게 되었습니다. 이 방법은 확장성이 뛰어나고 재현성도 매우 높습니다.
매일 얼마나 다양한 생성 AI 모델이 발명되고 있는지 주목하세요. 이제 모든 산업이 유입되고 있습니다. 처음으로 3조 달러 규모의 IT 산업이 100조 달러 규모의 산업에 직접 서비스를 제공하는 무언가를 창출하고 있습니다. 더 이상 단순한 정보 저장이나 데이터 처리 도구가 아닌 모든 산업에 필요한 인텔리전스를 생성하는 공장입니다. 이는 제조업이 될 것이지만, 컴퓨터 제조업이 아니라 컴퓨터를 이용한 제조업이 될 것입니다.
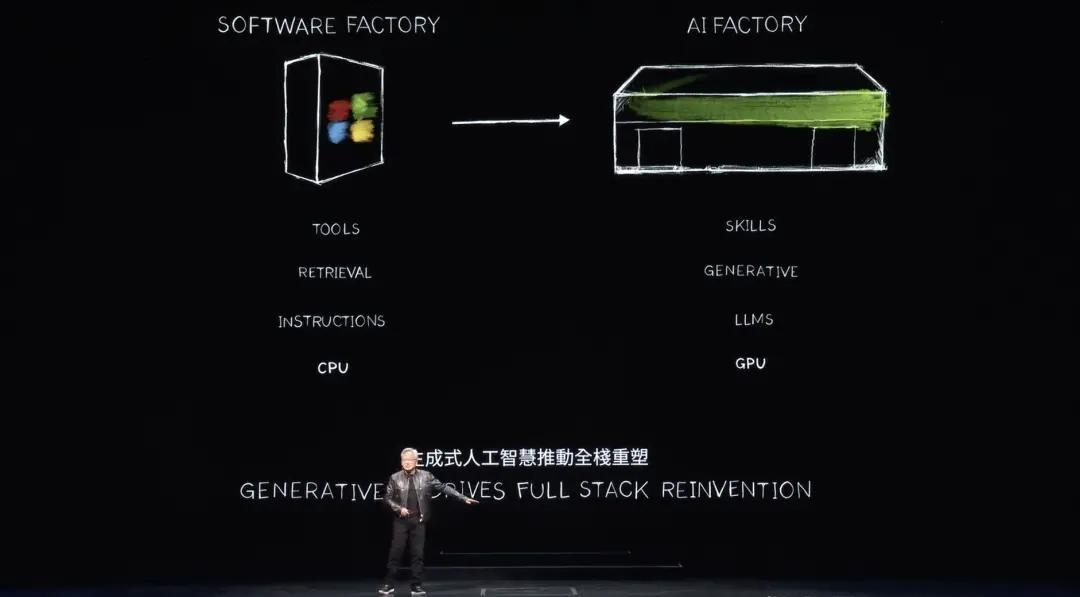
이런 일은 역사상 한번도 일어난 적이 없습니다. 가속 컴퓨팅은 AI를 가져왔고, 생성적 AI를 가져왔고, 이제 산업 혁명을 가져오고 있습니다. 산업에 미치는 영향도 매우 중요합니다. 많은 산업에서 토큰이라는 새로운 상품, 즉 새로운 상품을 창출할 수 있지만 우리 산업에 미치는 영향도 매우 깊습니다.
지난 60년 동안 CPU의 범용 컴퓨팅에서 GPU의 가속 컴퓨팅에 이르기까지 컴퓨팅의 모든 계층이 변경되었으며 컴퓨터에는 명령이 필요합니다. 이제 컴퓨터는 LLM, AI 모델을 처리합니다. 과거에는 컴퓨팅 모델이 검색을 기반으로 했습니다. 휴대폰을 터치할 때마다 미리 녹음된 일부 텍스트, 이미지 또는 비디오가 검색되어 재구성되어 추천 시스템을 기반으로 제공됩니다.
Huang은 미래에는 컴퓨터가 가능한 한 많은 데이터를 생성하고 필요한 정보만 검색할 것이라고 말했습니다. 그 이유는 생성된 데이터가 정보를 얻는 데 더 적은 에너지가 필요하기 때문입니다. 생성된 데이터도 더욱 상황에 맞습니다. 그것은 지식을 암호화하고 당신을 이해할 것입니다. 컴퓨터에 정보나 파일을 가져오도록 요청하는 대신 컴퓨터가 질문에 직접 답변하도록 합니다. 컴퓨터는 더 이상 우리가 사용하는 도구가 아니라 기술을 생성하고 작업을 수행하게 될 것입니다.
NIM, NVIDIA 추론 마이크로서비스

이는 업계에서 생산하는 소프트웨어라기보다는 1990년대 초반의 혁명적인 아이디어였습니다. Microsoft가 PC 산업에 혁명을 일으킨 소프트웨어 패키징 아이디어를 창안했음을 기억하십시오. 패키징 소프트웨어 없이 PC로 무엇을 할 수 있을까요? 이것이 업계를 이끌었고 이제 Nvidia는 새로운 공장, 새로운 컴퓨터를 갖게 되었습니다. 우리는 NIM, 즉 NVIDIA Inference Microservices라는 새로운 종류의 소프트웨어를 그 위에 실행할 것입니다.
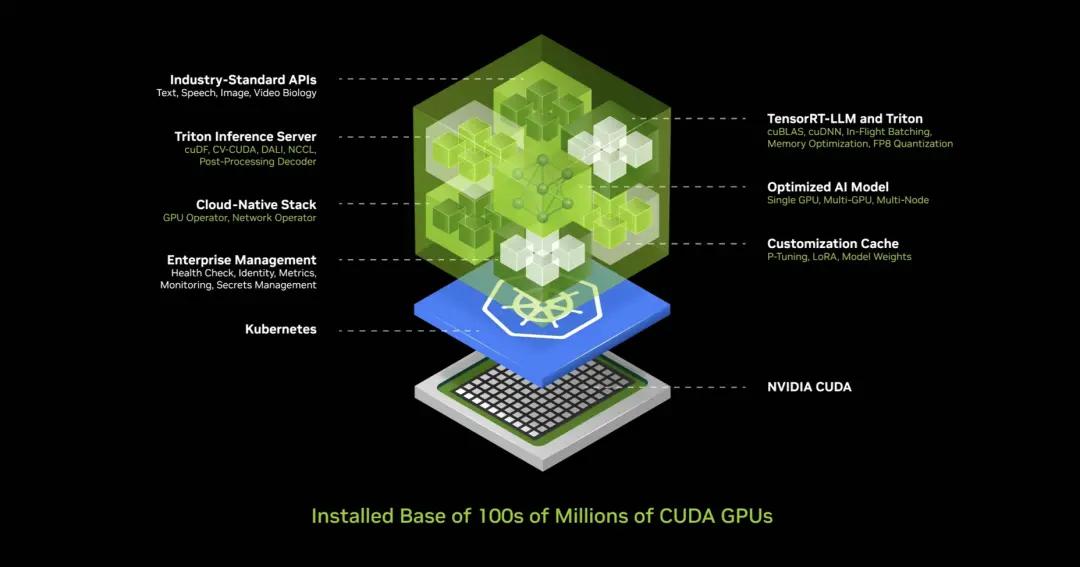
NIM은 이 공장 내부에서 실행됩니다. 이 NIM은 AI인 사전 훈련된 모델입니다. AI 자체는 매우 복잡하지만 AI를 실행하는 컴퓨팅 스택은 매우 복잡합니다. ChatGPT를 사용할 때 그 뒤에 있는 스택은 대량 소프트웨어입니다. 이 작업의 배경에는 대량 소프트웨어가 있으며 모델이 수십억에서 수조 개의 매개변수를 포함하여 거대하기 때문에 매우 복잡합니다. 한 대의 컴퓨터에서만 실행되는 것이 아니라 여러 대의 컴퓨터에서 실행됩니다. 여러 GPU에 작업 부하를 분산하고, 텐서 병렬 처리, 파이프라인 병렬 처리, 데이터 병렬 처리, 다양한 병렬 처리, 전문 병렬 처리 등과 같은 다양한 병렬 처리를 사용하여 작업 부하를 여러 GPU에 최대한 빠르게 분산하여 적절하게 처리해야 합니다.
공장에서 운영하는 경우 처리량은 수익과 직접적인 관련이 있기 때문입니다. 처리량은 서비스 품질과 직접적인 관련이 있으며, 처리량은 서비스를 사용할 수 있는 사람의 수와 직접적인 관련이 있습니다.
우리는 이제 데이터 센터 처리량 활용이 중요한 세상에 살고 있습니다. 과거에는 이것이 중요했지만 지금만큼은 아닙니다. 과거에는 이것이 중요했지만 사람들은 이를 측정하지 않았습니다. 오늘날 이곳은 공장이기 때문에 시작 시간, 런타임, 활용도, 처리량, 유휴 시간 등 모든 매개변수가 측정됩니다. 공장의 운영은 회사의 재무 성과와 직접적으로 연관되어 있으며 이는 대부분의 회사에 있어서 매우 복잡합니다.

그렇다면 엔비디아는 무엇을 했나요? NVIDIA는 대량 의 소프트웨어로 가득 찬 이 AI 상자를 만들었습니다. 이 컨테이너에는 CUDA, cuDNN, TensorRT 및 Triton 추론 서비스가 포함되어 있습니다. 클라우드 네이티브이고 Kubernetes 환경에서 자동으로 확장되며 AI를 모니터링하기 위한 관리 서비스와 후크가 있습니다. 공통 API, 표준 API를 가지고 있고, 박스와 채팅을 할 수 있습니다. 이 NIM을 다운로드하고 컴퓨터에 CUDA가 있는 한 채팅을 할 수 있습니다. 물론 현재 어디에나 있습니다. 모든 컴퓨터 제조업체의 모든 클라우드에서 사용할 수 있습니다. 모든 소프트웨어와 400가지 종속 항목이 하나로 통합되어 수억 대의 PC에서 사용할 수 있습니다.
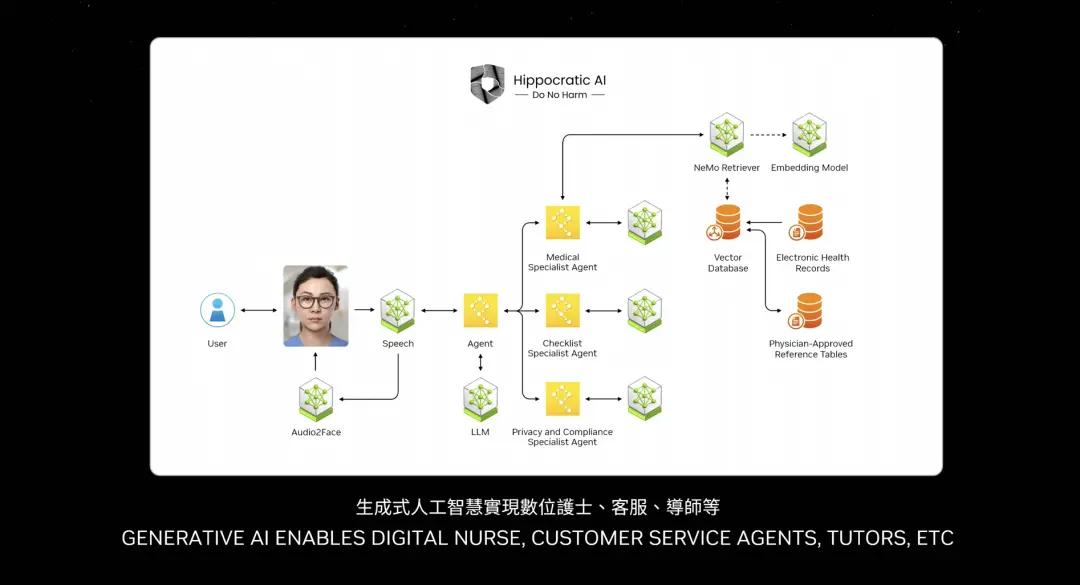
NVIDIA는 이 NIM을 테스트했으며 사전 훈련된 모든 모델은 전체 설치, Pascal, Ampere 및 Hopper의 모든 다른 버전과 다양한 버전에서 테스트되었습니다. 나는 몇몇 이름조차 잊어버렸다. 놀라운 발명품입니다. 제가 가장 좋아하는 발명품 중 하나입니다.
Jensen Huang은 Nvidia가 언어 기반, 비전 기반, 이미지 기반, 의료, 디지털 생물학 등 모든 다양한 버전을 보유하고 있으며 디지털 인간을 위한 버전도 있다고 말했습니다. ai.nvidia com을 방문하세요.
Huang Renxun은 또한 NVIDIA가 오늘 HuggingFace에서 완전히 최적화된 Llama3 NIM을 출시했으며, 여러분이 직접 사용해 볼 수 있고 가져갈 수도 있다고 말했습니다. 무료로 제공됩니다. 클라우드, 어느 클라우드에서나 실행할 수 있습니다. 이 컨테이너를 다운로드하여 자체 데이터 센터에 배치하고 고객이 사용할 수 있도록 할 수 있습니다.
Nvidia는 물리학, RAG라고 불리는 의미 검색용 버전, 시각적 언어, 모든 종류의 다양한 언어 등 다양한 분야의 버전을 보유하고 있습니다. 이를 사용하는 방법은 이러한 마이크로서비스를 더 큰 애플리케이션에 연결하는 것입니다.
미래의 가장 중요한 애플리케이션 중 하나는 확실히 고객 서비스가 될 것입니다. 에이전트는 거의 모든 산업에 필요합니다. 이는 고객 서비스에 있어서 수조 달러에 해당합니다. 간호사는 어떤 측면에서는 고객 서비스 대리인이기도 합니다. 일부 비처방 또는 비진단 간호사는 기본적으로 소매 업계, 퀵 서비스 식품, 금융 서비스 및 보험 업계의 고객 서비스입니다. 이제 언어 모델과 AI를 통해 수천만 개의 고객 서비스를 향상할 수 있습니다. 따라서 여러분이 보는 이 상자는 기본적으로 NIM입니다.
일부 NIM은 작업을 제공하고 작업을 결정하며 이를 계획으로 분해하는 추론 에이전트입니다. 일부 NIM은 정보를 검색합니다. 일부 NIM은 검색을 수행할 수 있습니다. 일부 NIM은 Jen-Hsun Huang이 이전에 언급한 cuOpt와 같은 도구를 사용할 수 있습니다. SAP에서 실행되는 도구를 사용할 수 있습니다. 그래서 ABAP라는 특정 언어를 배워야 합니다. 일부 NIM은 SQL 쿼리를 수행해야 할 수도 있습니다. 그래서 이 NIM들은 모두 전문가들이고 이제 하나의 팀으로 구성되고 있습니다.
그럼 무엇이 바뀌었나요? 애플리케이션 계층이 변경되었습니다. 지침으로 작성되었던 애플리케이션은 이제 AI 팀을 구성하는 애플리케이션입니다. 프로그램 작성 방법을 아는 사람은 거의 없지만 문제를 분석하고 팀을 구성하는 방법은 거의 모든 사람이 알고 있습니다. 나는 미래에는 모든 회사가 대량 NIM 컬렉션을 보유하게 될 것이라고 믿습니다. 원하는 전문가를 다운로드하여 팀으로 연결하면 연결 방법을 정확히 알 필요도 없습니다. 에이전트인 NIM에게 작업을 제공하고 에이전트가 작업 배포 방법을 결정하도록 하면 됩니다. 팀 리더 에이전트는 작업을 세분화하여 다양한 팀 구성원에게 할당합니다. 팀 구성원은 작업을 수행하고 팀 리더에게 결과를 반환하며, 팀 리더는 결과에 대해 추론하고 정보를 제공합니다. 이는 인간과 마찬가지로 가까운 미래, 미래의 애플리케이션 형태입니다.
물론 텍스트 안내와 음성 안내를 통해 이러한 대규모 AI 서비스와 상호 작용할 수 있습니다. 그러나 인간 형태와 상호 작용하려는 응용 프로그램이 많이 있습니다. 엔비디아는 이를 디지털 휴먼이라고 부르며 디지털 휴먼 기술을 연구해왔다.
Huang Renxun은 계속해서 디지털 인간이 당신과 상호 작용하는 훌륭한 에이전트가 되어 상호 작용을 더욱 매력적이고 자비롭게 만들 수 있는 잠재력을 가지고 있다고 소개했습니다. 물론 디지털 인간이 더욱 자연스럽게 보이도록 하려면 이 거대한 현실 격차를 해소해야 합니다. 인간이 하는 것과 같은 방식으로 컴퓨터가 우리와 상호 작용하는 미래를 상상해 보십시오. 이것이 바로 디지털 인류의 놀라운 현실이다. 디지털 휴먼은 고객 서비스부터 광고, 게임까지 산업에 혁명을 일으킬 것입니다. 디지털 휴먼의 가능성은 무궁무진합니다.
현재 주방의 스캔 데이터를 사용하세요. 당신의 휴대폰을 통해 그들은 AI 인테리어 디자이너가 되어 아름답고 사실적인 제안을 생성하고 재료와 가구의 소스를 제공하는 데 도움을 줄 것입니다.
NVIDIA는 귀하가 선택할 수 있는 여러 가지 디자인 옵션을 생성했습니다. 그들은 또한 AI 고객 서비스 에이전트가 되어 상호 작용을 더욱 생생하고 개인화하게 만들거나 디지털 의료 종사자가 되어 환자를 확인하여 시기적절하고 개인화된 치료를 제공할 수도 있습니다. 그들은 심지어 차세대 마케팅 및 광고 트렌드를 설정하는 AI 브랜드 홍보대사가 될 것입니다.
생성적 AI와 컴퓨터 그래픽의 새로운 혁신을 통해 디지털 인간은 인간과 같은 방식으로 우리를 보고, 이해하고, 상호 작용할 수 있습니다. 제가 본 바로는 일종의 녹음이나 제작 설정을 하고 있는 것 같습니다. 디지털 휴먼의 기반은 다국어 음성 인식 및 합성을 기반으로 구축된 AI 모델과 대화를 이해하고 생성할 수 있는 LLM 모델입니다.
이러한 AI는 다른 생성 AI에 연결되어 사실적인 3D 안면 메시를 동적으로 애니메이션화합니다. 마지막으로, AI 모델은 빛이 피부에 어떻게 침투하고, 산란하고, 다양한 지점에서 빠져나가는지 시뮬레이션하는 실시간 경로 추적 지하 산란을 활성화하여 사실적인 모습을 재현하여 피부에 부드럽고 반투명한 느낌을 줍니다.
Nvidia Ace는 배포가 용이하고 완전히 최적화된 마이크로서비스(NIM)에 패키지된 디지털 휴먼 기술 제품군입니다. 개발자는 Ace NIM을 기존 프레임, 엔진 및 디지털 인간 경험에 통합할 수 있으며 Nematons SLM 및 LLM NIM은 우리의 의도를 이해하고 다른 모델과 조정합니다.
대화형 음성 및 번역을 위한 Riva Speech Nims, 얼굴 및 신체 애니메이션을 위한 Audio to Face 및 Gesture NIM, 피부와 머리카락의 신경 렌더링을 위한 Omniverse RTX 및 DLSS.
정말 믿을 수가 없어요. 이러한 Ace는 클라우드나 PC에서 실행될 수 있고 모든 RTX GPU에 텐서 코어 GPU가 포함되어 있으므로 Nvidia는 이날을 대비하여 이미 AI GPU를 덤핑 있습니다. 그 이유는 간단합니다. 새로운 컴퓨팅 플랫폼을 만들기 위해서는 먼저 설치 기반이 필요하기 때문입니다.
드디어 앱이 나타납니다. 설치 기반을 만들지 않고 어떻게 애플리케이션이 존재할 수 있습니까? 그래서 당신이 그것을 만든다면 그들은 아마 오지 않을 것입니다. 그러나 당신이 그것을 짓지 않으면 그들은 올 수 없습니다. 따라서 Nvidia는 모든 RTX GPU에 Tensor Core 프로세서를 설치합니다. Nvidia는 현재 전 세계적으로 1억 대의 GeForce RTX AI PC를 보유하고 있으며 Nvidia는 200대를 덤핑 있습니다.
Computex에서 NVIDIA는 4개의 놀라운 새로운 노트북을 선보였습니다. 그들은 모두 AI를 실행할 수 있습니다. 미래의 노트북과 PC는 AI가 될 것이다. 그것은 계속해서 당신을 돕고 백그라운드에서 당신을 도울 것입니다. PC는 또한 AI로 강화된 애플리케이션을 실행할 것입니다.
물론 사진 편집, 쓰기 도구, 사용하는 모든 것이 AI로 향상됩니다. 귀하의 PC는 또한 디지털 휴먼과 함께 AI 애플리케이션을 호스팅합니다. 따라서 AI는 다양한 방식으로 나타나며 PC에서 사용될 것입니다. PC는 매우 중요한 AI 플랫폼이 될 것입니다.
그럼 여기서 어디로 가야 할까요? 앞서 데이터센터 확장에 대해 이야기한 적이 있습니다. 확장할 때마다 새로운 도약을 발견합니다. DGX에서 대규모 AI 슈퍼컴퓨터로 확장할 때 NVIDIA는 Transformer가 매우 큰 데이터 세트를 학습할 수 있도록 지원합니다. 처음에는 데이터를 수동으로 감독했으며 AI를 훈련하려면 사람의 주석이 필요했습니다. 안타깝게도 사람이 라벨을 붙인 데이터는 제한되어 있습니다.
Transformer는 비지도 학습을 가능하게 합니다. 이제 Transformer는 대량 의 데이터, 영상, 이미지 등을 간단히 살펴보고, 대량 의 데이터를 학습하여 스스로 패턴과 관계를 찾아낼 수 있습니다.

차세대 AI는 물리학을 기반으로 해야 합니다. 오늘날 대부분의 AI는 물리 법칙을 이해하지 못하며 물리적 세계에 뿌리를 두지 않습니다. 이미지, 영상, 3D 그래픽은 물론 다양한 물리적 현상을 생성하기 위해서는 물리학을 기반으로 하고 물리 법칙을 이해하는 AI가 필요합니다. 이는 하나의 소스인 비디오 학습을 통해 가능합니다.
또 다른 방법은 데이터를 합성하고, 데이터를 시뮬레이션하는 것이고, 또 다른 방법은 컴퓨터가 서로 학습하도록 하는 것입니다. 이는 사실 알파고의 셀프 플레이와 다르지 않습니다. 동일한 능력으로 게임을 하다 보면 시간이 지날수록 더욱 똑똑해집니다. 여러분은 이런 유형의 AI가 등장하는 것을 보게 될 것입니다.
AI 데이터를 합성하고 강화학습을 활용해 생성한다면 데이터 생성 속도는 계속해서 높아질 것이다. 데이터 생성이 증가할 때마다 제공해야 하는 계산량도 증가해야 합니다.
우리는 AI가 물리 법칙을 학습하고 물리적 세계의 데이터에 뿌리를 내릴 수 있는 단계에 진입하려고 합니다. 따라서 Nvidia는 모델이 계속 성장할 것이며 더 큰 GPU가 필요할 것으로 예상합니다.
블랙웰

Blackwell은 이 세대를 위해 설계되었으며 몇 가지 매우 중요한 기술을 보유하고 있습니다. 첫 번째는 칩의 크기입니다. Nvidia는 TSMC에서 가장 큰 칩을 만들고 세계에서 가장 발전된 SerDes인 초당 10TB 연결을 통해 두 칩을 연결합니다. 그런 다음 Nvidia는 두 개의 칩을 컴퓨팅 노드에 놓고 Grace CPU를 통해 연결합니다.
Grace CPU는 다양한 용도로 사용될 수 있습니다. 훈련 상황에서 빠른 체크포인트 및 재시작에 사용할 수 있습니다. 추론 및 생성 상황 모두에서 AI가 사용자가 원하는 대화의 맥락을 이해할 수 있도록 상황별 메모리를 저장하는 데 사용할 수 있습니다. 이는 Nvidia의 2세대 Transformer 엔진으로, 이를 기반으로 정확도를 동적으로 조정할 수 있습니다. 계산 계층에서 요구하는 정확도와 범위.
이는 서비스 제공업체가 AI를 도난이나 변조로부터 보호해야 하는 보안 AI가 탑재된 2세대 GPU입니다. 이는 여러 GPU를 함께 연결할 수 있는 5세대 NVLink입니다. 이에 대해서는 잠시 후에 자세히 설명하겠습니다.
이는 신뢰성과 가용성 엔진을 갖춘 Nvidia의 1세대 GPU입니다. 이 RAS 시스템을 사용하면 모든 트랜지스터, 플립플롭, 온칩 메모리 및 오프칩 메모리를 테스트하여 칩 고장 여부를 현장에서 확인할 수 있습니다. 10,000개의 GPU를 갖춘 슈퍼컴퓨터의 평균 실패 간격은 시간 단위로 측정됩니다. 100,000개의 GPU를 갖춘 슈퍼컴퓨터의 평균 실패 간격은 분 단위로 측정됩니다.
따라서 신뢰성을 향상시키는 기술을 개발하지 않고 슈퍼컴퓨터를 장기간 실행하고 몇 달 동안 모델을 훈련시키는 것은 거의 불가능합니다. 신뢰성은 가동 시간을 늘려 비용에 직접적인 영향을 미칩니다. 마지막으로 압축해제 엔진이 있는데, 데이터 처리는 반드시 수행되어야 하는 가장 중요한 작업 중 하나입니다. NVIDIA는 NVIDIA가 현재 가능한 것보다 20배 빠르게 스토리지에서 데이터를 클레임 할 수 있도록 하는 데이터 압축 및 압축 해제 엔진을 추가했습니다.

Blackwell은 생산 중이며 두 개가 서로 연결된 모든 Blackwell 칩을 볼 수 있는 대량 기술을 보유하고 있습니다. 보시다시피 이것은 세계에서 가장 큰 칩입니다. 그런 다음 두 개의 칩을 초당 10TB로 연결하면 성능이 놀랍습니다.
NVIDIA 컴퓨팅의 각 세대는 부동 소수점 컴퓨팅 성능을 1,000배씩 증가시킵니다. 무어의 법칙은 8년 안에 약 40~60배 증가할 것입니다. 그리고 지난 8년 동안 무어의 법칙 성장은 크게 둔화되었습니다. 무어의 법칙을 최대한 활용하더라도 Blackwell 성능과 비교할 수 없습니다.
계산량이 엄청납니다. 컴퓨팅 성능을 높일 때마다 비용은 감소합니다. NVIDIA는 컴퓨팅 성능을 향상하여 GPT-4 교육에 필요한 에너지 요구 사항을 1,000GWh에서 3GWh로 줄였습니다. 파스칼에는 1000GWh의 에너지가 필요합니다. 1000GWh는 1GW의 데이터 센터가 필요하다는 의미입니다. 세상에 GW 데이터센터는 없지만, GW 데이터센터가 있으면 한 달은 걸린다. 100MW 규모의 데이터센터를 운영한다면 약 1년이 소요된다. 그러므로 누구도 그러한 시설을 짓지 않을 것입니다.
이것이 8년 전에는 ChatGPT와 같은 LLM이 불가능했던 이유입니다. 향상된 에너지 효율성과 함께 성능을 개선함으로써 Nvidia는 이제 Blackwell의 에너지 요구 사항을 1,000GWh에서 3GWh로 줄였는데, 이는 놀라운 개선입니다. 예를 들어 GPU가 10,000개라면 며칠, 어쩌면 10일 정도 걸릴 것입니다. 불과 8년 만에 달성한 진전은 엄청납니다.
이 부분은 토큰을 추론하고 생성하는 것에 관한 것입니다. GPT-4 토큰을 생성하려면 이틀 동안 두 개의 전구를 켜야 합니다. 단어를 생성하려면 약 3개의 토큰이 필요합니다. 따라서 Pascal이 GPT-4를 생성하고 ChatGPT 경험을 제공하는 데 필요한 에너지는 거의 불가능합니다. 그러나 이제 각 토큰은 0.4줄만 사용하며 극히 낮은 에너지로도 토큰을 생성할 수 있습니다.

Blackwell은 큰 도약을 이루었습니다. 그렇다 해도 규모가 크지는 않습니다. 그래서 더 큰 기계를 만들어야 했습니다. 그래서 Nvidia가 이를 구축하는 방식을 DGX라고 합니다.

이것은 공랭식이며 내부에 8개의 GPU가 있는 DGX Blackwell입니다. 이 GPU의 방열판 크기를 보세요. 약 15kW이며 완전 공냉식입니다. 이 버전은 x86을 지원하며 Nvidia가 출시한 Hoppers 인프라에 들어갑니다. Nvidia에는 모듈 시스템을 의미하는 MGX라는 새로운 시스템이 있습니다.
Blackwell 보드 2개, 노드 1개에는 Blackwell 칩 4개가 있습니다. 이 Blackwell 칩은 수냉식이며 72개의 GPU는 새로운 NVLink를 통해 함께 연결됩니다. 이것은 5세대 NVLink 스위치입니다. NVLink 스위치 자체는 기술적으로 경이롭고, 세계에서 가장 진보된 스위치이며, 데이터 속도가 놀랍습니다. 이 스위치는 모든 Blackwell을 함께 연결하므로 거대한 72 GPU Blackwell이 있습니다.
이것의 장점은 도메인에서 GPU 도메인이 이제 이전 세대의 8개 GPU와 비교하여 72개 GPU를 갖는 GPU처럼 보인다는 것입니다. 따라서 대역폭이 9배 증가합니다. AI 부동소수점 컴퓨팅 성능은 18배, 45배 향상됐다. 그리고 전력 소비는 10배만 증가했습니다. 이것은 100킬로와트이고 저것은 10킬로와트입니다. 이것은.
물론, 언제든지 더 많은 것을 함께 연결할 수 있으며, 그 방법은 나중에 보여 드리겠습니다. 하지만 기적은 바로 이 칩, 바로 이 NVLink 칩입니다. 사람들은 이 NVLink 칩이 다양한 GPU를 모두 연결하기 때문에 얼마나 중요한지 깨닫기 시작했습니다. LLM은 매우 크기 때문에 하나의 GPU에만 배치할 수 없고 하나의 노드에만 배치할 수도 없습니다. 제가 방금 옆에 서 있던 새로운 DGX와 같이 수조 개의 매개변수가 포함된 LLM을 수용할 수 있는 전체 GPU 랙이 필요합니다.
NVLink 스위치 자체는 500억 개의 트랜지스터, 74개 포트, 포트당 400Gbps, 7.2Tbps의 단면 대역폭을 갖춘 놀라운 기술입니다. 하지만 중요한 것은 칩에서 축소 연산을 수행하기 위해 딥러닝에서 매우 중요한 수학 기능이 스위치 내에 있다는 것입니다. 이것이 바로 DGX입니다.
Huang은 많은 사람들이 Nvidia의 작업과 Nvidia가 GPU를 만들어 그토록 커지는 이유에 대해 질문했고 일부 사람들은 혼란스러워한다고 말했습니다. 그래서 어떤 사람들은 이것이 GPU의 모습이라고 생각합니다.
이제 이것은 GPU입니다. 이것은 세계에서 가장 발전된 GPU 중 하나이지만 이것은 게임용 GPU입니다. 당신과 나는 GP가 어떤 것인지 알고 있습니다. 이것은 GPU입니다. 신사 숙녀 여러분, DGX GPU입니다. 이 GPU의 뒷면은 NVLink 백본이라는 것을 알고 있습니다. NVLink 백본은 5,000개의 와이어로 구성되어 있으며 길이가 2마일에 달하며 두 개의 GPU를 함께 연결하며 전기적, 기계적 측면에서 경이롭습니다. 트랜시버를 사용하면 전체 길이의 구리선을 구동할 수 있어 단일 랙에서 20kW의 전력 소비를 절약할 수 있습니다.

Huang Renxun은 두 가지 유형의 네트워크가 있다고 말했습니다. InfiniBand는 전 세계 슈퍼컴퓨팅 및 AI 공장에서 널리 사용되고 있으며 놀라운 속도로 성장하고 있습니다. 그러나 모든 데이터 센터가 InfiniBand를 처리할 수 있는 것은 아닙니다. 이미 생태계에 너무 많은 이더넷 투자가 이루어졌고 InfiniBand 스위치 및 네트워크를 관리하려면 어느 정도 전문 지식이 필요하기 때문입니다.
따라서 NVIDIA는 InfiniBand 기능을 이더넷 아키텍처에 도입하는데 이는 매우 어렵습니다. 이유는 간단합니다. 이더넷은 모든 노드, 모든 컴퓨터가 인터넷의 다른 사람과 연결되어 있고 대부분의 통신이 데이터 센터와 인터넷 반대편에 있는 사람 간에 이루어지기 때문에 높은 평균 처리량을 위해 설계되었습니다.
하지만 딥러닝과 AI팩토리, GPU는 주로 서로 통신한다. 제품의 일부를 모아서 축소하고 재배포하면서 서로 소통합니다. 일부 제품의 수집, 축소 및 재배포. 이런 종류의 트래픽은 매우 폭주하며, 중요한 것은 평균 처리량이 아니라 마지막으로 도착하는 처리량입니다. 그래서 Nvidia는 여러 기술을 개발하고 네트워크 인터페이스 카드와 스위치가 통신할 수 있는 엔드투엔드 아키텍처를 만들었으며 이를 달성하기 위해 4가지 기술을 적용했습니다. 우선, Nvidia는 세계에서 가장 발전된 RDMA를 보유하고 있으며 이제 이더넷에서 네트워크 수준 RDMA를 수행할 수 있습니다. 이는 놀라운 일입니다.
둘째, Nvidia에는 혼잡 제어 기능이 있습니다. 스위치는 항상 빠른 원격 측정을 수행하며 GPU 또는 네트워크 인터페이스 카드가 너무 많은 정보를 보내는 경우 이슈 생성을 피하기 위해 물러나도록 지시할 수 있습니다.
셋째, 적응형 라우팅입니다. 이더넷에는 순차적인 전송과 수신이 필요합니다. Nvidia가 혼잡하거나 사용하지 않는 것으로 간주하는 포트는 순서에 관계없이 사용 가능한 포트로 전송되고 BlueField는 순서가 올바른지 확인하기 위해 반대쪽 순서.
마지막으로 소음 차단입니다. 데이터 센터에서는 항상 여러 모델의 훈련이나 기타 작업이 진행되고 있으며, 이들의 소음과 트래픽은 서로 간섭하고 지터를 유발할 수 있습니다. 따라서 훈련된 모델의 노이즈로 인해 마지막 모델이 너무 늦게 도착하면 전체 훈련 속도가 크게 저하됩니다.
교육을 위해 50억 달러 또는 30억 달러 규모의 데이터 센터를 구축했다는 사실을 기억하십시오. 네트워크 활용도가 40% 감소하여 훈련 시간이 20% 증가한다면 50억 달러 규모의 데이터 센터는 실제로 60억 달러 규모의 데이터 센터와 동일합니다. 따라서 비용에 미치는 영향은 매우 큽니다. Spectrum X를 사용하는 이더넷은 네트워크가 본질적으로 무료이면서도 성능을 크게 향상시킵니다.
Nvidia는 전체 이더넷 제품 라인을 보유하고 있습니다. 초당 51.2Tbps의 속도와 256개의 포트를 갖춘 Spectrum X800입니다. 다음은 내년에 출시될 Spectrum X800 Ultra라는 512포트 모델과 X16입니다. 중요한 개념은 X800은 수천 개의 GPU용으로 설계되었고, X800 Ultra는 수십만 개의 GPU용으로 설계되었으며, X16은 수백만 개의 GPU용으로 설계되었으며, 멀티 GPU 데이터센터 시대가 다가오고 있다는 것입니다.
미래에 인터넷이나 컴퓨터와 이루어지는 거의 모든 상호 작용에는 생성 AI가 어딘가에서 실행될 것입니다. 이 생성적 AI는 귀하와 함께 작업하고, 상호 작용하며, 비디오, 이미지, 텍스트는 물론 디지털 인간까지 생성합니다. 여러분은 거의 항상 컴퓨터와 상호 작용하며, 항상 컴퓨터에 연결된 생성 AI가 있습니다. 일부는 로컬로, 일부는 장치에, 그리고 아마도 대부분은 클라우드에 있습니다. 이러한 생성 AI는 일회성 답변을 제공하는 것이 아니라 여러 번의 반복을 통해 답변의 품질을 향상시키는 등 대량 추론을 수행합니다. 따라서 앞으로 생성되는 콘텐츠의 양은 엄청날 것입니다.
물론 Blackwell은 세계가 생성 AI 시대를 맞이하던 시기에 출시된 Nvidia 플랫폼의 1세대였습니다. 세계가 AI공장의 중요성을 깨닫고 있는 것처럼, 이는 새로운 산업혁명의 시작입니다. NVIDIA는 거의 모든 OEM, 컴퓨터 제조업체, 클라우드 서비스 제공업체, GPU 클라우드, 주권 클라우드, 심지어 통신 회사에서도 지원됩니다. Blackwell의 성공, 채택 및 열정은 놀라웠습니다. 모두에게 감사드리고 싶습니다.
예, 이 놀라운 성장 기간 동안 NVIDIA는 지속적으로 성능을 개선하고, 훈련 비용과 추론 비용을 지속적으로 절감하며, AI 기능을 지속적으로 확장하여 모든 회사가 접근할 수 있도록 하고자 합니다. NVIDIA가 성능을 개선할수록 비용 절감 효과도 커집니다. Hopper 플랫폼은 확실히 역사상 가장 성공적인 데이터 센터 프로세서이며, 정말 놀라운 성공 사례입니다.
그러나 Blackwell이 도착했으며 보시다시피 각 플랫폼에는 여러 가지가 포함되어 있습니다. CPU, GPU, NVLink, 네트워크 인터페이스, 모든 GPU를 연결하는 NVLink 스위치, 가능한 한 큰 도메인이 있습니다. 무엇을 할 수 있든 Nvidia는 이를 대규모의 초고속 스위치에 연결합니다.
각 세대마다 GPU뿐만 아니라 전체 플랫폼이 있다는 것을 알게 될 것입니다. 전체 플랫폼을 구축하세요. 전체 플랫폼을 AI 공장 슈퍼컴퓨터에 통합합니다. 그러나 그것을 분해하여 세상에 공개하십시오. 그 이유는 여러분 모두가 흥미롭고 혁신적인 구성을 만들고 이를 다양한 데이터 센터와 다양한 고객 요구에 맞게 조정할 수 있기 때문입니다. 일부는 엣지 컴퓨팅용이고 일부는 통신용입니다. 시스템을 개방하고 혁신할 수 있게 하면 다양한 혁신이 가능합니다. 그래서 Nvidia는 통합형으로 설계했지만 모듈 시스템을 만들 수 있도록 고객에게 세분화했습니다.
Blackwell 플랫폼이 등장했고 Nvidia의 기본 철학은 매우 간단합니다. 매년 전체 데이터 센터를 구축하고, 이를 분해하여 부품으로 판매하고, TSMC의 프로세스 기술, 패키징 기술, 메모리 기술 등 모든 것을 기술의 한계까지 밀어붙이는 것입니다. , SerDes 기술, 광학 기술 등 모든 것이 한계에 도달했습니다. 그런 다음 모든 소프트웨어가 전체 설치 기반에서 작동하는지 확인하십시오.
소프트웨어 관성은 컴퓨터에서 가장 중요한 것 중 하나입니다. 컴퓨터가 이전 버전과 호환되고 기존의 모든 소프트웨어 아키텍처와 호환되면 훨씬 더 빨리 시장에 출시될 수 있습니다. 따라서 생성된 전체 소프트웨어 설치 기반을 활용할 수 있다면 속도는 놀라울 것입니다.

Huang Renxun은 Blackwell이 출시되었으며 내년에는 Blackwell Ultra가 될 것이라고 말했습니다. H100 및 H200과 마찬가지로 한계를 뛰어 넘는 흥미로운 차세대 Blackwell Ultra를 볼 수 있습니다. 제가 언급한 차세대 Spectrum 스위치는 이런 도약이 이루어진 것은 이번이 처음이며, 차세대 플랫폼은 Ruben이라고 불리며, 1년 뒤에는 Ruben Ultra 플랫폼이 있을 것입니다.
표시된 모든 칩은 전체 개발 중이며 100% 개발 중입니다. 이는 NVIDIA의 올해의 리듬이며, 모두 100% 아키텍처와 호환되며 NVIDIA가 구축하는 모든 풍부한 소프트웨어입니다.
AI 로봇

다음에 무엇이 올지 이야기해 보겠습니다. AI의 다음 물결은 물리 법칙을 이해하고 우리와 함께 일할 수 있는 물리적 AI입니다. 그러므로 그들은 세계 모델, 세계를 해석하는 방법, 세계를 인식하는 방법을 이해해야 합니다. 또한 우리의 문제를 이해하고 작업을 수행하려면 뛰어난 인지 능력이 필요합니다.
로봇은 더 넓은 개념이다. 물론, 제가 로봇이라고 하면 보통 인간형 로봇을 의미하지만, 완전히 틀린 말은 아닙니다. 모든 것이 로봇이 될 것입니다. 모든 공장은 로봇화되고, 공장은 로봇을 조정하고, 이러한 로봇은 로봇 제품을 만들고, 로봇은 서로 협력하여 로봇 제품을 만듭니다. 이를 달성하기 위해서는 몇 가지 획기적인 발전이 필요합니다.
다음으로 Huang Renxun은 다음과 같이 언급한 동영상을 보여주었습니다.
로봇의 시대가 도래했습니다. 언젠가는 움직이는 모든 것이 자율적이 될 것입니다. 전 세계의 연구원과 기업은 실제 세계에서 지침을 이해하고 복잡한 작업을 자율적으로 수행하는 물리 기반 AI 모델을 기반으로 하는 로봇을 개발하고 있습니다. 다중 모드 LLM은 로봇이 주변 세계를 학습, 감지 및 이해하고 행동을 계획할 수 있도록 하는 획기적인 기술입니다.
인간의 시연을 통해 로봇은 이제 총체적 및 미세 운동 기술을 사용하여 세계와 상호 작용하는 데 필요한 기술을 배울 수 있습니다. 로봇공학을 발전시키는 핵심 기술은 강화학습이다. LLM이 특정 기술을 배우기 위해 RLHF를 요구하는 것처럼, 생성 물리학 AI는 물리 피드백을 사용하여 시뮬레이션된 세계에서 기술을 배울 수 있습니다. 이러한 시뮬레이션 환경은 로봇이 물리 법칙을 따르는 가상 세계에서 작업을 수행하여 결정을 내리는 방법을 배우는 곳입니다. 이러한 로봇 체육관에서 로봇은 복잡하고 역동적인 작업을 수행하는 방법을 안전하고 빠르게 학습하여 수백만 번의 시행착오를 통해 기술을 향상시킬 수 있습니다.
Nvidia는 물리 AI용 운영 체제로 Nvidia Omniverse를 구축했습니다. Omniverse는 실시간 물리적 렌더링, 물리적 시뮬레이션 및 생성 AI 기술을 결합한 가상 세계 시뮬레이션 개발 플랫폼입니다. Omniverse에서 로봇은 로봇이 되는 법을 배웁니다. 물체를 잡고 다루거나 장애물과 위험을 피하면서 최적의 경로를 찾기 위해 환경을 자율적으로 탐색하는 등 물체를 자율적이고 정확하게 조작하는 방법을 배웁니다. Omniverse에서의 학습은 시뮬레이션과 현실 사이의 격차를 최소화하고 학습된 행동의 전달을 최대화합니다.
생성 물리학 AI로 로봇을 구축하려면 모델을 훈련하기 위한 Nvidia AI 슈퍼컴퓨터, 모델을 실행하기 위한 Nvidia Jetson Orin 및 차세대 Jetson Thor 로봇 슈퍼컴퓨터, 로봇이 기술을 학습하고 향상시킬 수 있는 Nvidia Omniverse 등 세 대의 컴퓨터가 필요합니다. 시뮬레이션된 세계에서. 개발자와 기업이 필요로 하는 플랫폼, 가속 라이브러리, AI 모델을 구축하고 자신에게 가장 적합한 스택을 사용할 수 있도록 합니다. AI의 다음 물결이 도래했습니다. 물리적 AI로 구동되는 로봇은 다양한 산업에 혁명을 일으킬 것입니다.
Huang Renxun은 이것이 미래가 아니라 지금 일어나고 있다고 말했습니다. NVIDIA는 여러 가지 방법으로 시장에 서비스를 제공할 것입니다. 먼저 엔비디아는 로봇 공장 및 창고용, 물체를 조작하는 로봇용, 모바일 로봇용, 휴머노이드 로봇용 등 로봇 시스템 유형별 플랫폼을 만들 예정이다. 따라서 Nvidia가 수행하는 거의 모든 것과 마찬가지로 모든 로봇 공학 플랫폼은 컴퓨터, 가속 라이브러리 및 사전 훈련된 모델입니다. 컴퓨터, 가속 라이브러리 및 사전 훈련된 모델. 비디오에서 알 수 있듯이 로봇은 로봇이 되는 방법을 배우는 Omniverse에서 모든 것이 테스트되고 훈련되고 통합됩니다.
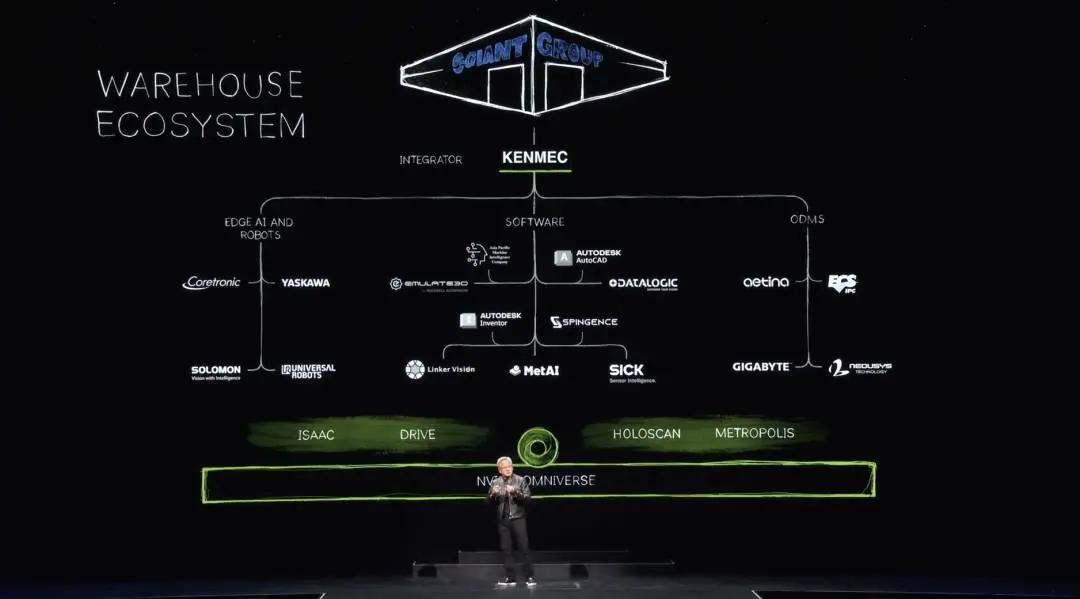
물론 로봇창고 생태계는 복잡하다. 점점 더 자동화되고 있는 현대적인 창고를 구축하려면 많은 회사, 많은 도구, 많은 기술이 필요합니다. 언젠가는 완전히 자동화될 것입니다. 따라서 각 생태계에는 소프트웨어 산업에 연결된 SDK 및 API, 엣지 AI 산업 및 기업에 연결된 SDK 및 API, Odms용으로 설계된 PLC 및 로봇 시스템의 시스템 통합이 있습니다. 이는 궁극적으로 통합업체에 의해 통합되어 고객의 창고에 구축됩니다. 다음은 Kenmac이 Giant Group을 위해 구축한 로봇 창고의 예입니다.
Huang은 계속해서 공장은 완전히 다른 생태계를 가지고 있으며 Foxconn은 세계에서 가장 진보된 공장 중 일부를 건설하고 있다고 말했습니다. 그들의 생태계에는 다시 엣지 컴퓨터와 로봇, 공장을 설계하는 소프트웨어, 워크플로우, 프로그래밍 로봇, 디지털과 AI 공장을 조정하는 PLC 컴퓨터가 포함됩니다. Nvidia는 모든 생태계에 연결되는 SDK를 보유하고 있으며 이는 대만 전역에서 일어나고 있습니다.

Foxconn은 공장의 디지털 트윈을 구축하고 있습니다. Delta는 공장의 디지털 트윈을 구축하고 있습니다. 그건 그렇고, 절반은 현실, 절반은 디지털, 절반은 옴니버스입니다. Pegatron은 로봇 공장의 디지털 트윈을 구축하고 있으며 Quanta는 로봇 공장의 디지털 트윈을 구축하고 있습니다.
Huang Renxun은 다음과 같은 동영상을 계속 시연했습니다.

세계가 전통적인 데이터 센터를 생성적 AI 공장으로 현대화함에 따라 Nvidia 가속 컴퓨팅에 대한 수요가 급증하고 있습니다. 세계 최대 전자제품 제조업체인 폭스콘은 이러한 수요를 충족시키기 위해 엔비디아 옴니버스와 AI를 활용한 로봇 공장 건설을 준비하고 있다. 플랜트 계획자는 Omniverse를 사용하여 Siemens Team Center X 및 Autodesk Revit과 같은 주요 산업 애플리케이션의 시설 및 장비 데이터를 디지털 트윈으로 통합합니다.
디지털 트윈 내에서 Nvidia Metropolis 기반 비전 AI를 사용하여 바닥 레이아웃과 생산 라인 구성을 최적화하고 최적의 카메라 위치를 배치하여 향후 작업을 모니터링했습니다. 가상 통합을 통해 계획자는 건설 중 물리적 변경 주문으로 인한 막대한 비용을 절감할 수 있습니다. Foxconn 팀은 정확한 장치 레이아웃을 전달하고 확인하기 위한 정보 소스로 디지털 트윈을 사용합니다.
Omniverse 디지털 트윈은 Foxconn 개발자가 로봇 인식 및 작동을 위한 Nvidia Isaac AI 애플리케이션과 센서 융합을 위한 Metropolis AI 애플리케이션을 교육하고 테스트하는 로봇 체육관 역할도 합니다.
Huang은 계속해서 Omniverse에서 Foxconn이 조립 라인의 Jetson 컴퓨터에 런타임을 배포하기 전에 두






