

클라우드 서비스 회사인 Cloudflare는 AI 봇이 웹사이트에서 불법적으로 데이터를 수집하는 것을 방지하는 데 도움이 되는 새로운 도구를 출시했습니다.
인공 지능(AI) 모델을 교육하기 위한 데이터에 대한 수요가 증가하는 상황에서 많은 AI 회사는 웹 사이트에서 데이터를 "스크래핑"하기 위해 봇을 배포하여 저작권 침해 및 정보 무단 사용 의 위험을 초래했습니다.
Google, OpenAI, Apple과 같은 일부 AI 회사는 웹사이트 소유자가 robots.txt 파일을 통해 봇을 차단할 수 있도록 허용하지만, Cloudflare는 일부 AI 회사가 콘텐츠 통제에도 불구하고 데이터를 수집하기 위해 "법을 우회"할 수 있는 방법을 찾을 수 있다고 우려하고 있습니다.
TechCrunch 와 공유하면서 회사는 "고객은 AI 봇이 웹 사이트에 액세스하는 것을 원하지 않습니다." 라고 말했습니다.
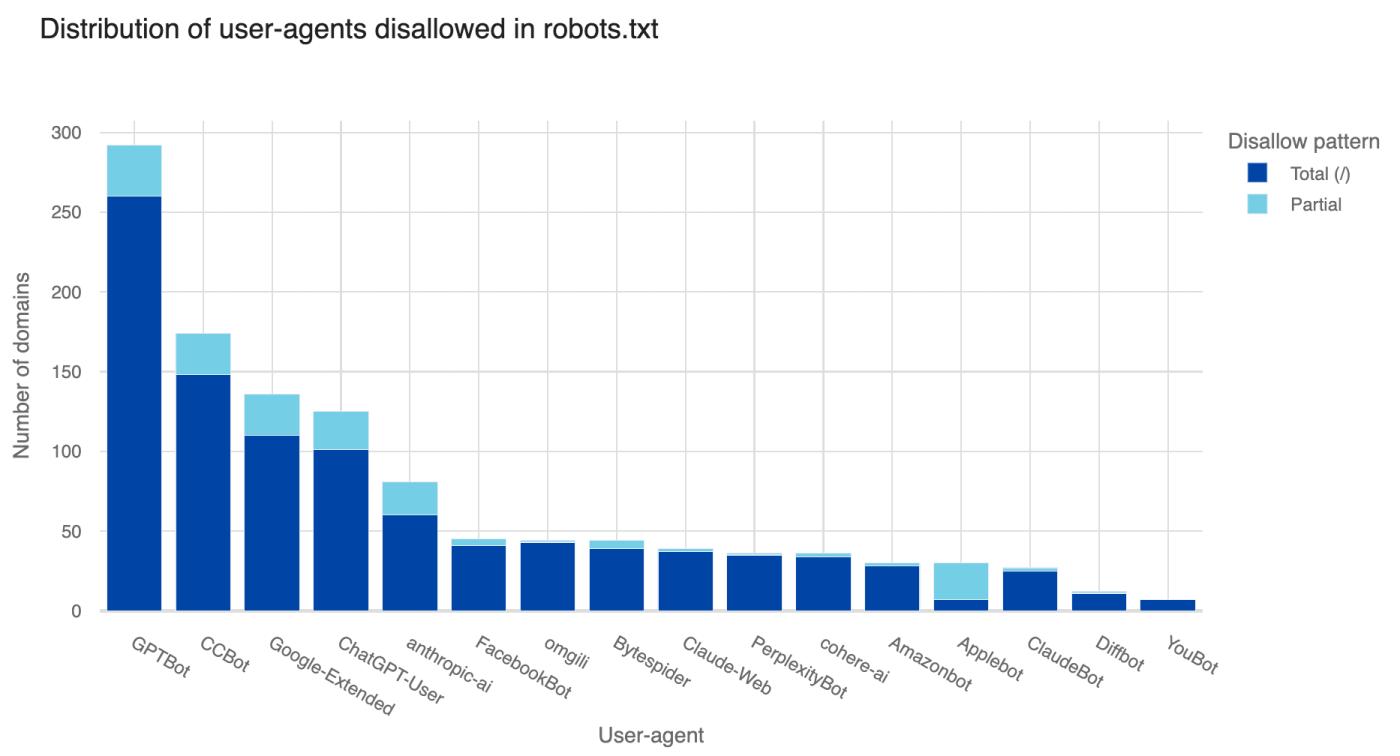
실제로 OpenAI만 사용해도 여러 연구에 따르면 600개 이상의 뉴스 게시자와 상위 1,000개 웹사이트 중 26%가 OpenAI의 봇을 비활성화 한 것으로 나타났습니다.
이러한 상황에 직면하여 Cloudflare는 AI 봇의 활동을 연구 및 분석하여 자동 봇 감지 알고리즘을 개선했습니다. 알고리즘은 AI 봇이 웹 사용자를 "사칭"하려고 하는지 여부를 포함한 여러 요소를 고려합니다.
Cloudflare는 "악의적인 행위자는 도구와 프레임워크를 사용하여 대규모로 데이터를 수집하는 경우가 많습니다." 라고 말했습니다. 이러한 신호를 기반으로 우리의 알고리즘은 AI 봇에 정확하게 플래그를 지정할 수 있습니다.”
이 새로운 도구는 Cloudflare 플랫폼을 사용하는 웹사이트에 완전히 무료입니다. 웹사이트 소유자는 Cloudflare가 검토하고 블랙리스트에 올릴 의심스러운 AI 봇을 신고할 수도 있습니다.
Cloudflare 외에도 Reddit도 대부분의 자동화된 봇이 라이선스 없이 데이터를 사용하는 것을 차단하겠다고 발표하면서 비슷한 조치를 취했습니다. Mashable에 따르면 Reddit은 robots.txt 파일을 수정하여 웹 크롤러를 제한할 예정입니다.
그러나 봇 차단이 항상 효과적인 것은 아닙니다. 일부 AI 회사는 경쟁 우위를 확보하기 위해 robots.txt 규칙을 무시했다는 비난을 받았습니다. AI 검색 엔진인 Perplexity는 콘텐츠를 '스크래핑'하기 위해 사용자를 사칭한 혐의로 기소되었으며, OpenAI와 Anthropic은 robots.txt를 반복적으로 위반한 것으로 알려졌습니다.
Cloudflare와 같은 도구는 익명의 AI 봇을 탐지하는 데 정확성이 입증되면 유용할 수 있습니다. 그러나 특정 AI를 차단하는 경우 사이트를 목록에서 제외하는 Google AI 개요와 같은 AI 도구의 트래픽을 게시자가 희생해야 하는 더 큰 문제는 해결되지 않습니다.
Cloudflare는 새로 발표된 "2024년 애플리케이션 보안 현황" 보고서에서 사이버 보안 팀이 최신 애플리케이션의 위협을 처리하는 데 어려움을 겪고 있다고 밝혔습니다.
따라서 소프트웨어 공급망, DDoS 공격 및 악성 봇은 전문 애플리케이션 보안 팀의 주요 과제입니다. Cloudflare는 고객을 위해 매일 2,090억 건의 사이버 공격을 방지한다고 강조합니다.
Cloudflare의 공동 창립자이자 CEO인 Matthew Prince는 온라인 애플리케이션이 보안을 거의 고려하지 않고 구축되는 경우가 많아 공격에 취약하다고 말했습니다.






