

작성자: 탄즈신,선두 기술

이미지 출처: 무한 AI에 의해 생성됨
대규모 언어 모델(LLM)이 소프트웨어 개발 방식을 변화시키고 있으며, AI가 대규모로 인간 프로그래머를 대체할 수 있는지 여부가 업계의 관심사가 되고 있습니다.
불과 2년 만에 AI 대규모 모델은 기초 컴퓨터 과학 문제 해결에서 국제 프로그래밍 대회에서 인간 전문가와 경쟁할 수 있는 수준까지 발전했습니다. 예를 들어 OpenAI o1은 2024년 국제 정보학 올림피아드(IOI)에 인간 참가자와 동일한 조건으로 참가하여 금메달을 획득하며 강력한 프로그래밍 잠재력을 보여주었습니다.
동시에 AI의 반복 속도도 빨라지고 있습니다. SWE-Bench Verified 코드 생성 평가 기준에서 2024년 8월 GPT-4o의 점수는 33%였지만, 새로운 세대 o3 모델의 점수는 72%로 두 배 이상 증가했습니다.

AI 모델의 실제 세계 소프트웨어 엔지니어링 능력을 더 잘 평가하기 위해 오늘 OpenAI는 새로운 평가 기준 SWE-Lancer를 공개했습니다. 이는 모델 성능과 금전적 가치를 처음으로 연결했습니다.
SWE-Lancer는 Upwork 플랫폼의 1,400개 이상의 자유 소프트웨어 엔지니어링 작업을 포함하는 벤치마크로, 이 작업들의 실제 세계 총 보상 가치는 약 100만 달러입니다. AI가 얼마나 많은 돈을 벌 수 있을까요?
새로운 기준의 "특징"
SWE-Lancer 벤치마크 작업 가격은 실제 시장 가치를 반영합니다. 작업이 어려울수록 보상이 높습니다.
여기에는 독립적인 엔지니어링 작업과 관리 작업이 모두 포함되며, 기술 구현 방안 간에 선택할 수 있습니다. 이 기준은 프로그래머뿐만 아니라 아키텍트와 관리자를 포함한 전체 개발 팀을 대상으로 합니다.
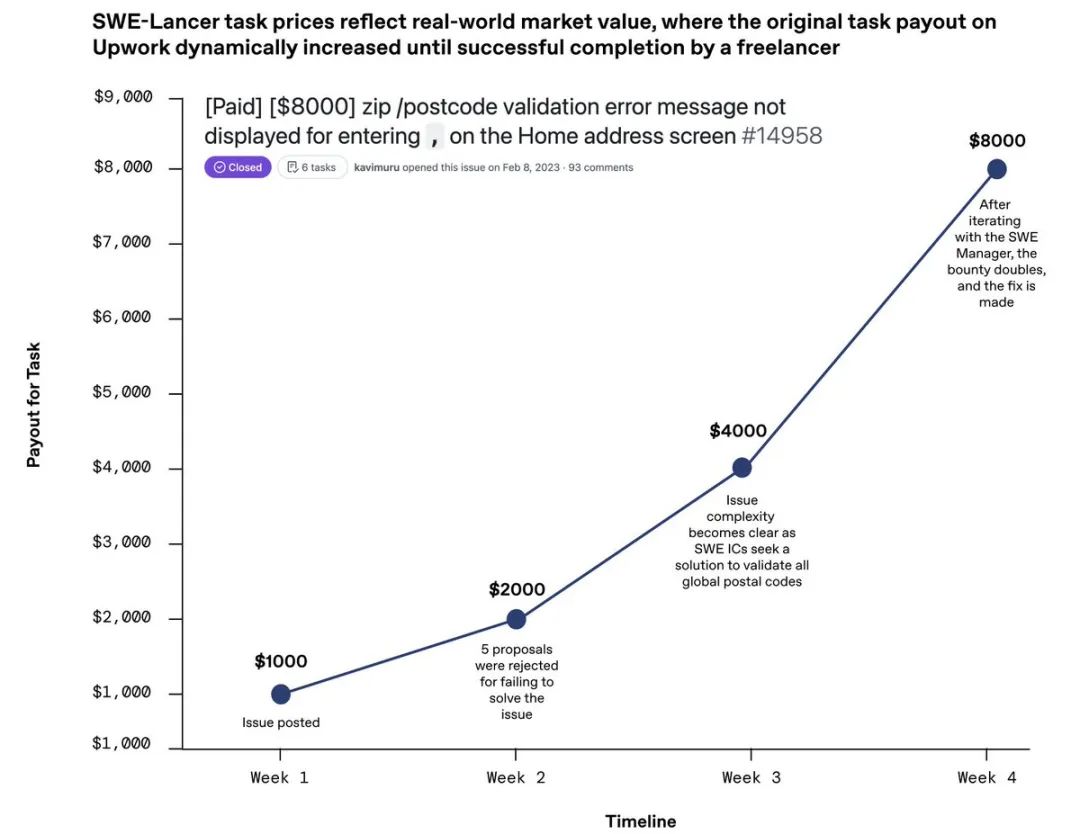
이전 소프트웨어 엔지니어링 테스트 기준과 비교하여 SWE-Lancer에는 다음과 같은 여러 가지 장점이 있습니다:
1. 1,488개의 모든 작업은 고용주가 자유 엔지니어에게 지불한 실제 보상을 나타내며, 시장이 결정한 자연스러운 난이도 gradient를 제공합니다. 보상은 250달러에서 32,000달러 사이로 상당히 큽니다.
이 중 35%의 작업 가치가 1,000달러를 초과하고 34%의 작업 가치가 500달러에서 1,000달러 사이입니다. 개별 기여자(IC) 소프트웨어 엔지니어링(SWE) 작업 그룹에는 764개의 작업이 포함되어 있으며 총 가치는 41.4775만 달러입니다. SWE 관리 작업 그룹에는 724개의 작업이 포함되어 있으며 총 가치는 58.5225만 달러입니다.
2. 실제 세계의 대규모 소프트웨어 엔지니어링에는 단순히 코드를 작성하는 것 외에도 능력 있는 기술 관리가 필요합니다. 이 벤치마크는 모델이 SWE "기술 관리자"의 역할을 수행하는 실제 세계 데이터를 사용하여 평가합니다.
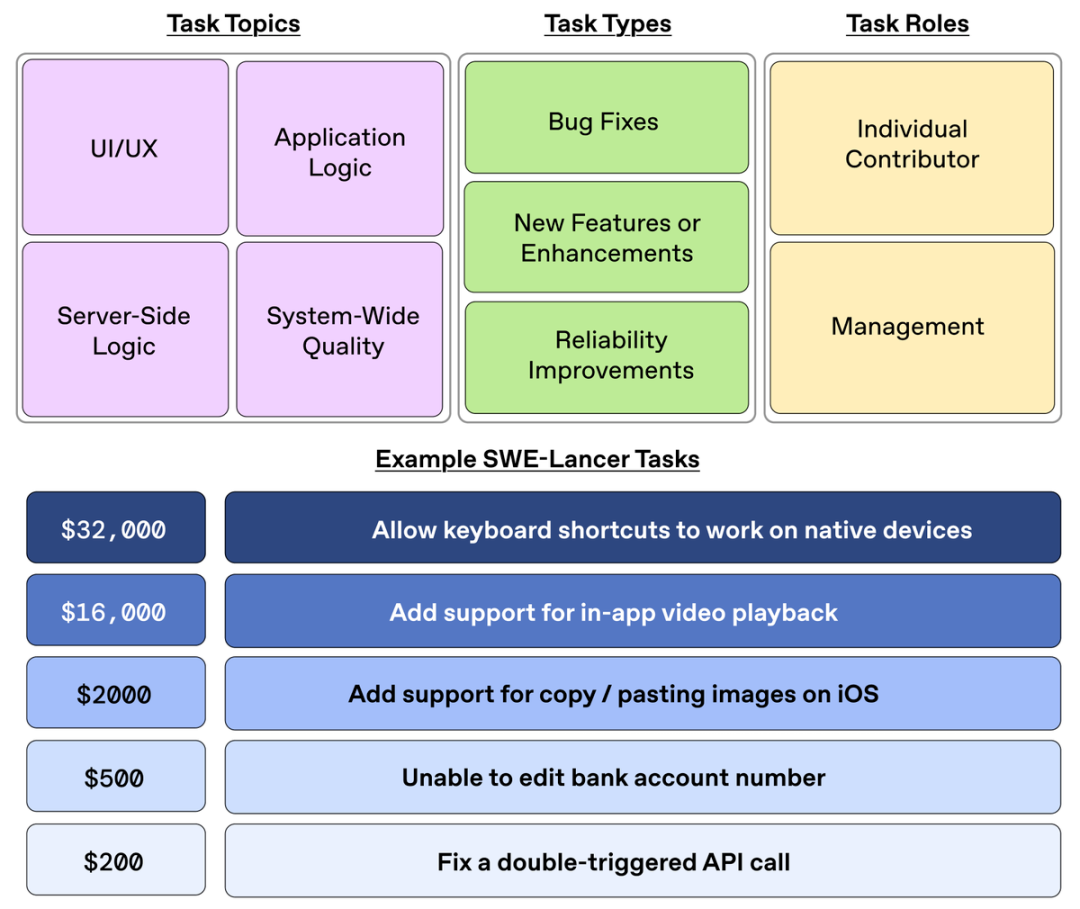
3. 고급 풀스택 엔지니어링 평가 기능을 갖추고 있습니다. SWE-Lancer는 수백만 명의 실제 사용자가 있는 플랫폼의 작업을 나타내므로 실제 세계의 소프트웨어 엔지니어링을 나타냅니다.
여기에는 모바일 및 웹 엔지니어링 개발, API, 브라우저 및 외부 애플리케이션과의 상호 작용, 복잡한 문제 검증 및 재현 등의 작업이 포함됩니다.
예를 들어 일부 작업은 250달러를 들여 신뢰성을 높이고(API 호출 문제 수정), 1,000달러를 들여 취약점을 수정하고(권한 차이 문제 해결), 16,000달러를 들여 새로운 기능을 구현하는 것(웹, iOS, Android 및 데스크톱에 앱 내 비디오 재생 지원 추가)입니다.
4. 다양한 도메인. IC SWE 작업의 74%와 SWE 관리 작업의 76%가 애플리케이션 로직을 다루며, IC SWE 작업의 17%와 SWE 관리 작업의 18%가 UI/UX 개발을 다룹니다.
작업 난이도 측면에서 SWE-Lancer에 선택된 작업은 매우 도전적입니다. 오픈 소스 데이터 세트의 작업을 평균적으로 26일 동안 Github에서 해결할 수 있습니다.
또한 OpenAI는 편향되지 않은 데이터 수집 상황을 설명했으며, Upwork에서 대표적인 작업 샘플을 선택하고 100명의 전문 소프트웨어 엔지니어를 고용하여 모든 작업에 대한 엔드-투-엔드 테스트를 작성하고 검증했습니다.
AI 코딩 수익 능력 PK
많은 기술 리더들이 AI 모델이 "저급" 엔지니어를 대체할 수 있다고 계속 주장하고 있지만, 기업이 LLM을 완전히 인간 소프트웨어 엔지니어를 대체할 수 있는지에 대해서는 여전히 의문이 있습니다.
초기 평가 결과에 따르면 현재 테스트된 AI 최고 모델은 100만 달러의 잠재적 총 보상을 훨씬 밑돌고 있습니다.
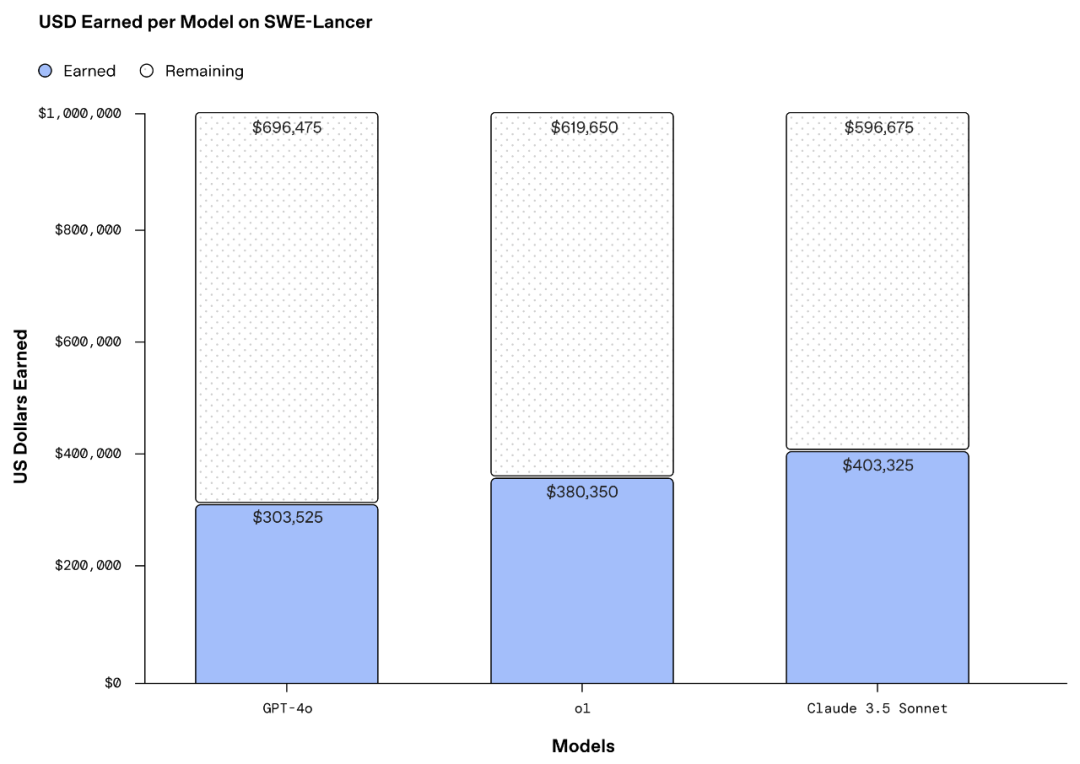
전반적으로 모든 모델이 SWE 관리 작업에서 IC SWE 작업보다 더 나은 성과를 보였습니다. IC SWE 작업은 여전히 AI 모델에 의해 충분히 극복되지 않았으며, 현재 테스트된 모델 중 가장 좋은 성과를 보인 것은 Anthropic이 개발한 Claude 3.5 Sonnet입니다.
IC SWE 작업에서 모든 모델의 단일 통과율과 수익률은 30% 미만이었지만, SWE 관리 작업에서 가장 좋은 성과를 보인 모델 Claude 3.5 Sonnet의 점수는 45%였습니다.
Claude 3.5 Sonnet는 IC SWE와 SWE 관리 작업 모두에서 강력한 성능을 보였습니다. IC SWE 작업에서 두 번째로 좋은 모델 o1보다 9.7% 높았고, SWE 관리 작업에서는 3.4% 높았습니다.
수익으로 환산하면 가장 좋은 성과를 보인 Claude 3.5 Sonnet가 전체 데이터 세트에서 40만 달러 이상의 총 수익을 올렸습니다.
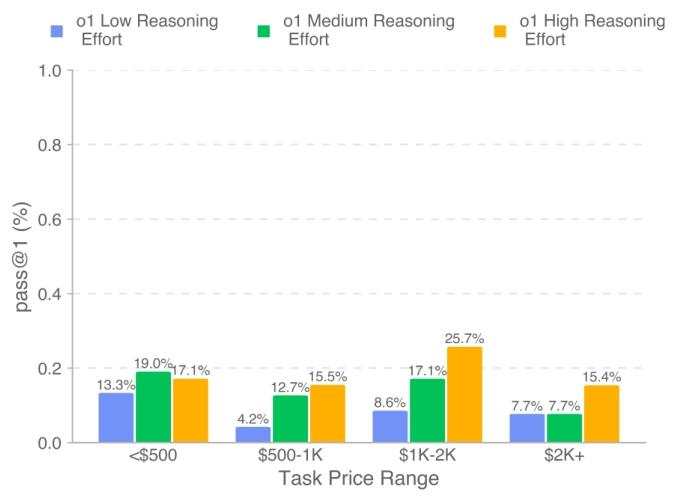
주목할 점은 더 높은 추론 계산량이 "AI 수익"에 큰 도움이 된다는 것입니다.
IC SWE 작업에서 깊이 있는 추론 도구를 활용한 o1 모델 실험에서는 추론 계산량을 높이면 단일 통과율을 9.3%에서 16.5%로 높일 수 있었고, 수익도 1.6만 달러에서 2.9만 달러로, 수익률도 6.8%에서 12.1%로 높아졌습니다.
연구원들은 최고 모델 Claude 3.5 Sonnet가 IC SWE 문제의 26.2%를 해결했지만, 나머지 대부분의 솔루션에는 여전히 오류가 있어 신뢰할 수 있는 배포를 위해서는 많은 개선이 필요하다고 요약했습니다. 그 다음은 o1, 그 다음은 GPT-4o이며, 관리 작업의 단일 통과율은 일반적으로 IC SWE 작업의 단일 통과율의 두 배 이상입니다.
이는 AI 에이전트가 인간 소프트웨어 엔지니어를 대체할 수 있다는 관점이 과도하게 선전되고 있지만, 기업은 여전히 신중해야 한다는 것을 의미합니다. AI 모델은 "저급" 코딩 문제를 해결할 수 있지만 "저급" 소프트웨어 엔지니어를 대체할 수는 없습니다. 왜냐하면 그들은 일부 코드 오류의 근본 원인을 이해하지 못하고 더 많은 확장 오류를 범하기 때문입니다.
현재 평가 프레임워크는 다중 모달 입력을 지원하지 않으며, 연구원들은 "투자 수익률"을 평가하지 않았습니다. 예를 들어 작업을 완료할 때 자유 계약자에게 지불한 보상과 API 사용 비용을 비교하는 것이 이 기준의 다음 개선 중점이 될 것입니다.
"AI 증강형" 프로그래머가 되기
현재로서는 AI가 인간 프로그래머를 완전히 대체하려면 아직 갈 길이 멉니다. 소프트웨어 엔지니어링 프로젝트를 개발하는 것은 단순히 요구 사항에 따라 코드를 생성하는 것 이상의 일이기 때문입니다.
예를 들어 프로그래머는 종종 매우 복잡하고 추상적이며 모호한 고객 요구 사항에 직면합니다. 이를 해결하려면 다양한 기술 원리, 비즈니스 로직 및 시스템 아키텍처에 대한 깊이 있는 이해가 필요합니다. 복잡한 소프
장기적으로 볼 때, AI 기술 발전으로 인한 프로그래머 직위의 대체성은 여전히 존재하지만, 단기적으로는 "AI 증강형 프로그래머"가 주류가 될 것이며, 최신 AI 도구 사용 능력은 우수한 프로그래머의 핵심 기술 중 하나입니다.





