이 연구는 ProbeLab 팀의 @cortze와 @yiannisbot에 의해 수행되었으며, 이더리움 재단(EF)과 PeerDAS 커뮤니티의 피드백을 받았습니다.
소개
이더리움의 확장성 개선 로드맵의 일환으로, 블롭 트랜잭션이 도입되어 각 슬롯에 더 많은 데이터를 포함할 수 있게 되었습니다. 따라서 더 많은 블롭을 추가할수록 온체인에서 더 많은 데이터를 지원할 수 있어 롤업 및 기타 확장 솔루션에 도움이 됩니다.
[이하 생략하고 전체 내용을 한국어로 번역했습니다.]| 응답의 일부였나요? | 펍 멤풀에서 확인되었나요? | 사이드카 수 |
|---|---|---|
| 참 | 참 | 197156 |
| 거짓 | 참 | 4571 |
| 거짓 | 널 | 6392 |
엔진 API 호출 및 블롭 재구성 시간
합의 계층(CL)은 실행 계층(EL)의 응답을 무기한 기다릴 수 없기 때문에, 여러 클라이언트 팀들은 engine_getBlobsV1 요청에 대한 타임아웃을 적용해야 하는지, 그렇다면 적절한 값은 무엇인지에 대해 논의해왔습니다.
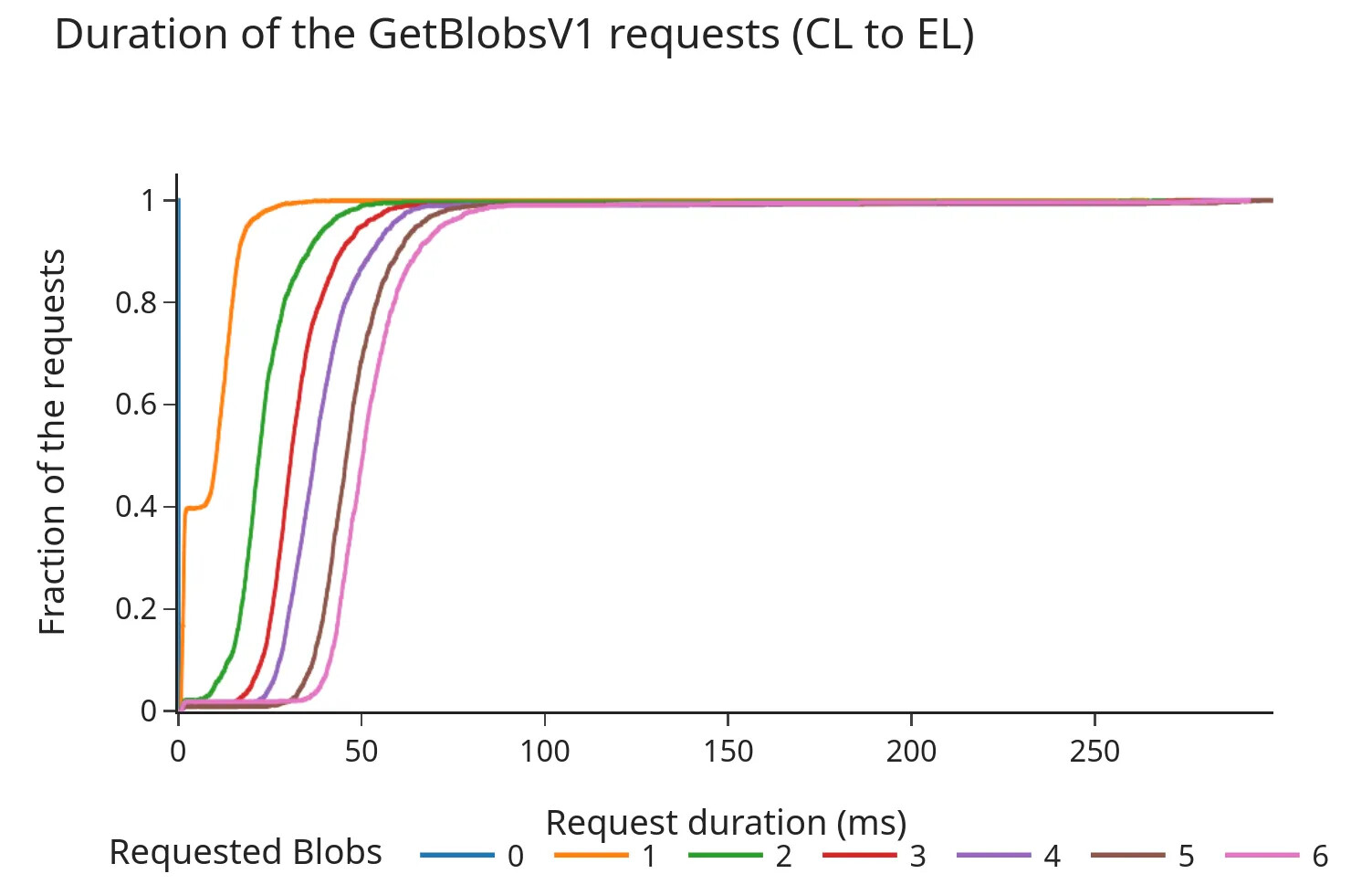
다음 그래프는 엔진 API에 대한 요청/응답 지속 시간(밀리초)의 누적 분포 함수(CDF)를 보여줍니다.
페크트라 이전:
페크트라 이후:
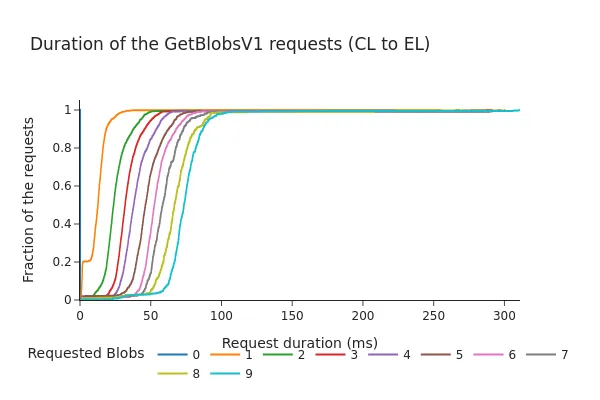
- CDF는 페크트라 포크와 블록당 3개의 추가 블롭 추가 후에도 98%의 요청이 100밀리초 미만에 완료됨을 보여줍니다.
- 총 지속 시간은 요청된 블롭 수와 거의 선형적으로 증가하는 경향이 있습니다. 이러한 시간들은 여전히 "안전 마진" 내에 있지만(이전 논의에서는 200-250밀리초 정도의 타임아웃을 제안), 데이터는 슬롯당 블롭 수 증가가 EL의 블롭 멤풀에서 더 긴 페치 시간으로 이어질 수 있음을 나타냅니다.
결론
이 연구와 이전 연구는 @cskiraly의 연구와 병행하여 수행되었으며, 방법론은 다르지만 두 연구 모두 같은 결론에 도달했습니다:
현재 네트워크 상태와 체인의 사용 추세에서, 대부분의 블롭 사이드카는 비콘 블록에 포함되기 전에 이미 EL에서 사용 가능합니다.
이 결론은 전반적으로 좋은 소식이지만, 현재 네트워크가 CL 사이드카 주제를 통해 중복 정보를 전송하는 데 상당한 자원을 사용하고 있음을 보여주며, 이는 개선의 여지가 있음을 시사합니다.
한편으로 이러한 중복성은 모든 CL 노드가 새로운 블록 제안을 제때 처리하는 데 필요한 데이터를 확보하도록 보장하여 성공적으로 복원력을 제공합니다. 다른 한편으로는 모든 블롭 사이드카를 4초 미만에 네트워크에 브로드캐스트해야 하는 자체적인 병목 현상을 만듭니다.
권장 사항
네트워크 오버헤드와 노드 과부하를 줄이는 것을 주요 목적으로, PeerDAS와 블롭 사이드카 공유에 대한 논의를 시작할 가치가 있습니다.
이더리움의 현재 PeerDAS 제안에서는 CL에서만 사이드카를 샤딩하고 있어, 블롭의 재분배 단계에서 최적화를 수행합니다. 그러나 이는 문제를 부분적으로만 해결하며, 여전히 모든 블롭 트랜잭션을 EL 멤풀을 통해 전송하게 됩니다.
분산 블록 빌딩을 통해 블롭의 더 빠른 브로드캐스트에 기여할 수 있더라도, 여전히 (적어도 부분적으로) 중복된 정보를 전송하게 됩니다.
IDONTWANT메시지가 여기서 도움이 되지만, 여전히 많은 중복을 생성하여 궁극적으로 네트워크 오버헤드와 노드 부하를 증가시킵니다.
가능한 미래
EL의 멤풀에서 샤딩을 이동하면 명확하고 중요한 이점이 있습니다:
EL에서 사이드카 샤딩을 수행하면 검증 네트워크의 블롭 시딩 및 일부 사전 계산 단계를 단순화할 수 있으며, 이는 트랜잭션 제안자의 새로운 의무가 될 수 있습니다. 즉, 블롭 셀에 대한 소거 코딩을 적용하고 브로드캐스트를 시작하는 것입니다.
블롭 배포에 대한 로드 밸런싱 특성을 제안/적용할 수 있어 CL이 사이드카를 브로드캐스트해야 하는 현재의 "4초" 시간 제한을 제거할 수 있습니다. 블롭이 아직 포함되지 않았기 때문에 전파에 대한 마감 시간을 적용할 필요가 없습니다. 이는 느린 사용자도 조각 주변을 브로드캐스트할 때 약간의 추가 지연을 "감당할" 수 있음을 의미합니다.
현재 EL은 CL보다 블롭 다운로드에 더 효율적입니다:
- EL 계층에서 블롭을 가져올 때 시간 제한이 없으므로 한 번에 모든 블롭을 다운로드할 필요가 없습니다.
- EL은 단일 풀 사이드카 요청을 보낼 시기를 결정하여 GossipSub이 평균 메시 피어에 유발하는 중복을 방지합니다 → 기본적으로 메시지당
D-2중복 (링크)
이는 @cskiraly의 제안과 대체로 일치합니다: 합의 계층(CL)이 아닌 실행 계층(EL)에서 샤딩을 구현하는 것이 훨씬 더 효율적일 수 있습니다.
이 아이디어는 아직 초안 형태이며, 네트워크 리소스 사용을 최적화하는 방법을 탐색하고 있어 아직 해결해야 할 여러 가지 불확실한 점들이 있습니다.
이것이 어떻게 보일 수 있는지의 예로, ProbeLab 팀이 몇 달 전부터 초안을 작성하기 시작한 진행 중인 블롭 멤풀 DHT 제안을 다시 검토하고 공유하고 싶습니다. 이는 CL과 EL이 네트워크 대역폭과 저장소를 더 효율적으로 사용할 수 있도록 동기화하는 방법을 보여주는 것을 목표로 합니다(제안의 세부 사항은 향후 게시물로 남겨둡니다). 항상 그렇듯이 모든 피드백을 환영합니다.