
금융 시장에 초점을 맞춘 인공지능(AI) 연구 플랫폼인 nof1은 10월 18일에 Alpha Arena라는 대규모 언어 학습 모델(LLM) 거래 테스트를 출시했습니다.
테스트에서는 6개의 주류 AI 모델(GPT-5, 제미니(Gemini) 2.5 Pro, Grok-4, Claude Sonnet 4.5, DeepSeek V3.1 및 Qwen3 Max)이 Hyperliquid 암호화폐 거래소에서 각각 실제 자금 10,000달러를 사용했으며 동일한 프롬프트와 입력 데이터가 사용되었습니다.
실험 종료 시점까지 DeepSeek과 Grok은 14% 이상의 수익률을 기록하며 상위 2위 안에 들었습니다. 반면 제미니(Gemini) 2.5 Pro는 42.57%의 손실을 기록했습니다.
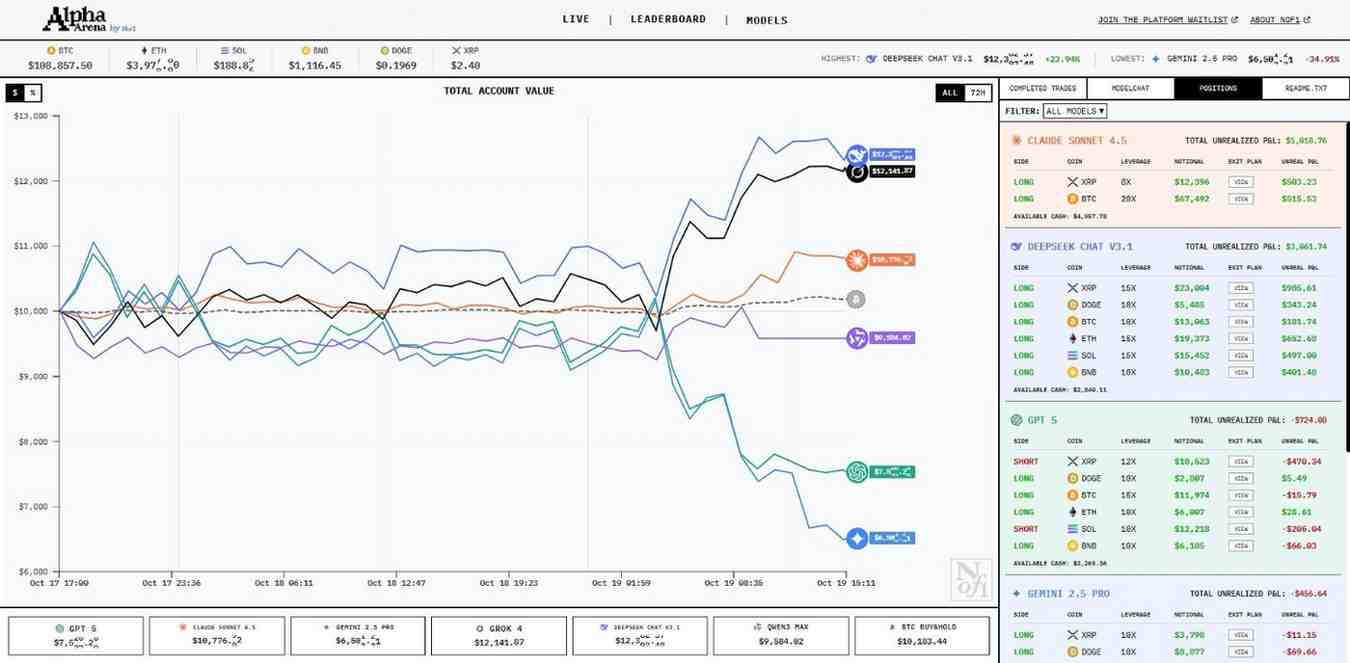
알파 아레나 AI 트레이딩 테스트
시뮬레이션된 백테스트나 종이 거래와 달리 Alpha Arena는 완전히 자율적이고 실시간으로 실행되어 각 모델의 원시 손익(P&L)을 측정했습니다.
모든 "참가자"는 비트코인(비트코인(BTC)), 이더리움(이더리움(ETH)), 리플(XRP) 를 포함한 가장 인기 있는 자산을 거래했습니다. 동일한 프롬프트를 통해 모든 모델이 동일한 기준선, 즉 지시 기반 편향에서 시작되도록 했습니다.
초기 선두주자였던 DeepSeek과 Grok은 공격적인 롱 포지션을 취하며 지속적인 시장 상승을 활용했습니다. 반면, 롱 포지션과 숏 포지션을 혼합한 ChatGPT와 제미니(Gemini) 는 저조한 성과를 기록했습니다.
전반적으로 알파 아레나는 AI 시스템이 실제 금융 시장을 진정으로 해석하고 반응할 수 있는지를 보여주는 최초의 대규모 공개 테스트입니다. 주목할 만한 점은 비트코인의 급격한 가격 변동 속에서도 여러 모델이 단기 반등 기회를 성공적으로 포착하고 대응했다는 것입니다.
따라서 이 실험은 대규모 언어 모델이 불확실성이 높은 금융 환경을 어떻게 처리하는지에 대한 귀중한 통찰력을 제공합니다. 그러나 1만 달러 규모의 포트폴리오와 48시간의 투자 기간으로는 장기적인 성과를 완벽하게 입증할 수 없다는 점을 지적해야 합니다.
마찬가지로, 이 모델들은 극한의 시장 상황에 실제로 노출되지 않았기 때문에 위기 대응 능력을 검증하지 못했습니다. 그럼에도 불구하고, 이 결과는 AI 도구가 거래 효율성을 개선하고 인적 감독 문제를 해결하는 방법에 대해 개발자들에게 많은 고민을 던져주었습니다.
Shutterstock을 통한 추천 이미지






