

블록체인 시스템에서 KV 조회에 따른 실제 디스크 I/O 비용 이해하기
실제 블록체인 상태 워크로드 환경에서의 Pebble에 대한 실증 연구
추상적인
많은 블록체인 분석 및 성능 모델은 키-값(KV) 저장소 읽기가 O(log N) 디스크 I/O 복잡성을 발생시킨다고 가정합니다(예: TrieDB , QMDB ). 특히 Pebble이나 RocksDB와 같은 LSM 트리 엔진을 사용할 때 이러한 가정이 두드러집니다. 이는 SST 탐색의 최악의 시나리오에 근거한 것으로, 조회 시 여러 레벨에 접근해야 하고 각 레벨에서 블룸 필터, 인덱스 블록 및 데이터 블록을 검사해야 하는 상황을 가정합니다.
하지만 이 모델은 실제 상황을 제대로 반영하지 못하는 것으로 나타났습니다. 실제로는 캐시에 대부분의 필터 및 인덱스 블록이 저장되어 I/O 횟수를 크게 줄일 수 있습니다.
실제 캐싱 환경에서 LSM 기반 데이터베이스의 디스크 I/O 동작을 이해하기 위해, 대표적인 엔진인 Pebble을 사용하여 22GB에서 2.2TB ( 키 개수 2억 개에서 200억 개 )에 이르는 데이터셋을 대상으로 광범위한 제어 실험을 수행한 결과는 다음과 같습니다.
- Bloom 필터( LLast 제외)와 Top-Index가 캐시에 저장되면 대부분의 부정 조회는 디스크 I/O가 발생하지 않으며 , Get 작업당 I/O 횟수는 급격히 감소하여 약 2회 정도가 됩니다.
(인덱스 블록 1개 읽기 및 데이터 블록 1개 읽기). - 모든 인덱스 블록이 캐시에 들어갈 경우, Get 작업당 I/O 횟수는 전체 데이터베이스 크기와 거의 무관하게 약 1.0~1.3 으로 수렴합니다.
- 데이터 블록 캐싱은 순수 무작위 읽기 작업 부하에서 전체 I/O에 미미한 영향만 미칩니다.
전반적으로 캐시 용량이 Bloom 필터(LLast 제외)와 Top-Index를 저장하기에 충분할 때
블록체인과 유사한 워크로드에서 전체 데이터베이스 크기의 약 0.1%~0.2%를 차지하는 Pebble은 임의 읽기에 대해 실질적으로 O(1) 디스크 I/O 동작을 보여 일반적인 한계를 뛰어넘습니다.
각 키-값(KV) 조회는 본질적으로 O(log N) 물리적 I/O 비용을 발생시킨다는 가정이 있습니다. 이는 블록체인 트라이 데이터베이스 및 실행 계층 스토리지 시스템의 성능 모델링 및 설계에 직접적인 영향을 미칩니다.
동기 부여
블록체인 실행 계층은 일반적으로 수십억 개의 무작위로 접근되는 키를 처리하기 위해 LSM-트리 키 검증 저장소에 의존합니다. 일반적인 가정은 다음과 같습니다.
“LSM 트리에서 각 KV 조회는
O(log N)디스크 I/O 비용을 발생시킵니다.”
하지만 실제 블록체인 시스템에서는 이러한 가정이 종종 성립하지 않습니다. Pebble과 같은 최신 LSM 기반 KV 엔진은 다음과 같은 요소에 크게 의존합니다.
- 대부분의 부정 검색을 제거하는 블룸 필터;
- 작고 재사용성이 뛰어난 인덱스 구조;
- 자주 액세스하는 메타데이터를 메모리에 저장하는 블록 캐시 및 OS 페이지 캐시.
결과적으로 KV 조회의 실제 물리적 I/O 동작은 종종 작은 상수(≈1~2 I/O)로 제한되며, 블룸 필터와 인덱스 블록이 캐시에 들어가면 전체 데이터베이스 크기와 거의 무관해집니다.
이러한 관찰 결과는 중요한 실질적인 질문을 제기합니다.
실제 블록체인 시나리오에서 임의 키-값(KV) 조회에 필요한 디스크 I/O 비용은 얼마입니까?
본 연구는 다음과 같은 목적을 달성하기 위해 직접적이고 실증적인 측정을 통해 이 질문에 답하고자 합니다.
- 일반적인
O(log N)KV 조회 가정의 타당성을 검증하거나 반박하십시오. - 읽기 I/O를 거의 일정하게 유지하는 데 실제로 필요한 캐시 용량을 정량화하십시오.
- 블록체인 실행 계층 영구 키-값(KV) 저장소 백엔드(상태 트라이 및 스냅샷 KV 저장소 포함)에 대한 경험적 캐시 크기 조정 권장 사항을 제공합니다.
우리는 어떻게 가설을 검증했을까요?
이 섹션에서는 현실적인 캐싱 조건에서 Pebble의 실제 읽기 I/O 비용이 최악의 경우 O(log N) 모델에서 제시하는 LSM 트리 깊이보다는 메타데이터의 캐시 상주 시간에 의해 주로 결정된다는 가설을 검증하는 방법을 설명합니다. 먼저 Pebble의 읽기 경로를 분석하여 구체적인 I/O 발생 원인을 파악한 다음, 읽기 동작에서 I/O 비용 변화를 특징짓는 두 가지 캐시 기반 변곡점을 소개합니다. 마지막으로, 이러한 단계를 실증적으로 관찰하고 Get당 I/O 에 미치는 영향을 정량화하는 데 사용된 실험 설정을 간략하게 설명합니다.
페블 이해하기
Pebble 읽기 경로 및 I/O 소스
Pebble에서 Get 작업은 다음과 같이 진행됩니다.
1. Lookup MemTable / Immutable MemTables and return value if found ( in memory) 2. Lookup MANIFEST to find candidate SST files ( in memory) 3. For each SST:a) Load Top - level index at reader initialization (used to locate internal index blocks after filter check )b) Table - level Bloom filter check ( except LLast) → skip SST if key absentc) Internal index block lookup → locate data blockd) Data block lookup → read value and return위의 읽기 경로는 이 문서 전체에 걸쳐 나타나는 여러 내부 구성 요소를 참조합니다. 이해를 돕기 위해 여기에서 간략하게 소개합니다.
최상위 지수(줄여서 Top-Index)
SST별로 생성된 아주 작은 최상위 인덱스가 내부 인덱스 블록을 가리킵니다.
거의 모든 조회에서 언급되며 일반적으로 완전히 캐시된 상태로 유지됩니다.
내부 인덱스 블록(줄여서 인덱스 블록)
각 SST 내의 인덱스 블록은 키 범위를 데이터 블록에 매핑합니다.
이러한 항목은 필터 검사가 성공적으로 완료된 후에 액세스되며, 캐시되지 않은 경우 디스크 I/O가 한 번 발생할 수 있습니다.
마지막
LSM 트리의 가장 깊은 레벨입니다. 대부분의 데이터를 저장하며 조회 시 블룸 필터를 사용하지 않습니다 .
따라서 LLast에 도달하는 조회는 최상위 인덱스 → 인덱스 블록 → 데이터 블록의 전체 경로를 따릅니다.
필터에서 LLast를 제외하는 이유는 무엇입니까?
LLast에 대한 블룸 필터는 크기가 지나치게 크고 캐시에 유지하는 데 비용이 많이 들며, 대부분의 긍정적인 조회는 결국 LLast를 참조하기 때문에 실제적인 이점이 제한적입니다. 따라서 Pebble은 LLast에 대해 블룸 필터를 사용하지 않습니다 .
실질적인 캐시 전환점 두 가지
위에서 설명한 읽기 경로를 보면, Get 작업은 소수의 잘 정의된 메타데이터 구성 요소를 반복적으로 참조한다는 것을 알 수 있습니다. 이러한 구성 요소가 캐시에 상주하는지 여부가 읽기 경로의 어느 부분에서 물리적 I/O가 발생하는지를 직접적으로 결정합니다. 이러한 관찰과 각 메타데이터 클래스의 총 캐시 사용량을 기반으로, 다음 섹션에서 읽기 I/O 동작을 분석하는 기준으로 두 개의 캐시 크기 임계값(캐시 변곡점)을 정의합니다.
변곡점 1 — Filter + Top-Index
캐시에는 다음이 저장될 수 있습니다.
- 모든 Bloom 필터(LLast 제외)
- 모든 상위 인덱스 블록
→ 부정 조회는 거의 항상 메모리에서 해결됩니다.
변곡점 2 — Filter + All-Index
캐시에는 다음이 저장될 수 있습니다.
- 모든 Bloom 필터(LLast 제외)
- 모든 레벨의 모든 인덱스 블록
→ 긍정적인 조회는 인덱스 누락을 방지하고 최소 I/O에 근접합니다.
구성 요소 정의
- 필터: LLast 레벨을 제외한 모든 레벨에 대한 블룸 필터
- 최상위 인덱스: SST별 최상위 인덱스 블록 전체
- 전체 인덱스: 최상위 인덱스 + 모든 내부 인덱스 블록
읽기 I/O 동작의 세 가지 캐시 기반 단계
위에서 정의한 두 개의 캐시 변곡점을 기반으로 캐시 크기를 세 단계로 나누고 각 단계에서 예상되는 읽기 I/O 동작을 설명합니다.
1단계 —
Cache Size < Inflection Point 1
필터 및 상위 인덱스 누락이 빈번하게 발생하여 불필요한 SST 검사가 많아지고, 결과적으로 읽기 I/O 비용이 높아질 것으로 예상됩니다 .2단계 —
Inflection Point 1 < Cache Size < Inflection Point 2
필터와 최상위 인덱스가 캐시되므로 부정 검색은 대부분 메모리에서 해결됩니다. 인덱스 블록이 캐시에 저장되기 시작하면 읽기 I/O가 감소할 것으로 예상 됩니다.3단계 —
Cache Size > Inflection Point 2
필터와 모든 인덱스 블록이 캐시되므로 나머지 I/O는 주로 데이터 블록에서 발생할 것으로 예상되며 , 그 이후로는 효율성이 떨어집니다.
실험 장치 구성
이 섹션에서는 블록체인과 유사한 워크로드 환경에서 Pebble의 실제 랜덤 읽기 I/O 동작을 평가하는 데 사용된 실험 방법론을 설명합니다. 캐시 상주 시간 및 Get당 I/O 횟수를 측정하는 데 사용된 실험 환경, 데이터 세트, 워크로드 및 지표를 요약하고, 특히 안정적인 랜덤 읽기 동작에 초점을 맞춥니다.
하드웨어 및 소프트웨어
- CPU: 32코어
- 메모리: 128GB
- 디스크: 7TB NVMe RAID0
- 운영체제: 우분투
- 스토리지 엔진: Pebble v1.1.5
참고: 모든 실험은 Pebble v1.1.5에서 수행되었습니다. Pebble v2 이상 버전에서는 읽기 경로 동작, 필터 레이아웃 또는 캐싱 동작이 다를 수 있으므로 별도로 평가해야 합니다.
모든 벤치마크 코드, Pebble 계측 데이터 및 실험 기록은 공개되어 있습니다.
재현성을 위해 bench_kvdb 에서 이용 가능합니다.
데이터셋
| 데이터셋 | 작은 | 중간 | 크기가 큰 |
|---|---|---|---|
| 열쇠 | 2억 개의 키 | 2B 키 | 20B 키 |
| DB 크기 | 22GB | 224GB | 2.2TB |
| 파일 개수 | 1418 | 7105 | 34647 |
| 필터 + 상위 인덱스 | 32MB (0.14%) | 284MB (0.12%) | 2.52GB (0.11%) |
| 필터(LLast 포함) | 238MB | 2.3 GB | 23GB |
| 종합지수 | 176MB | 1.7GB | 18GB |
| 필터 + 전체 인덱스 | 207MB (0.91%) | 2.0GB (0.89%) | 20.5GB (0.91%) |
키: 32바이트 해시
값: 110바이트 (게스 트라이 노드의 평균 RLP 크기와 거의 동일)
업무량
- 순수 무작위 읽기
- 테스트당 10M Get 작업
- 워밍업: 키 공간의 0.05%
- 범위 스캔 없음
- 동시에 대용량 쓰기 또는 압축 작업이 발생하지 않음
메모.
모든 실험은 동시적인 대량 쓰기 작업, 압축 압력 또는 범위 스캔 없이 단일 노드에서 안정적인 순수 무작위 읽기 워크로드 에 초점을 맞춥니다.
미터법
우리는 Pebble의 내부 통계를 활용하여 읽기 동작을 분석합니다. 여기에는 다음이 포함됩니다.
- 블룸 필터 적중률
- 최고 인덱스 적중률
- 인덱스 블록 적중률
- 데이터 블록 적중률
- 전체 블록 캐시 적중률
- 겟당 I/O 횟수 — 최종 목표 지표
Pebble에서 Get 작업 중 모든 블록 읽기(필터, 상위 인덱스, 인덱스 및 데이터 블록)가 수행됩니다.
모든 조회는 블록 캐시를 통해 이루어집니다. 모든 조회는 먼저 캐시를 참조하며, 블록 캐시 미스가 발생하더라도 일반적으로 최소한의 사전 읽기 및 압축 간섭 하에 단일 물리적 읽기 작업만 수행됩니다.
여기서 BlockCacheMiss 는 모든 블록 유형에 걸쳐 발생한 블록 캐시 미스 총 횟수입니다.
(블룸 필터, 상위 인덱스 블록, 인덱스 블록 및 데이터 블록)이며, GetCount는 측정된 완료된 Get 작업 수입니다.
결과적으로 BlockCacheMiss 실제 물리적 읽기 부하를 면밀히 추적하고 조회당 I/O 비용에 대한 안정적이고 구현에 부합하는 측정값을 제공합니다.
결과
먼저 캐시 크기가 블룸 필터, 상위 인덱스 블록 및 인덱스 블록의 적중률에 미치는 영향을 분석합니다. 그런 다음 이러한 영향이 전체 블록 캐시 적중률과 궁극적으로 I/O/Get 지표에 어떻게 반영되는지 보여줍니다.
이 섹션 전체에서 변곡점 1(IP1) 은 모든 비-LLast Bloom 필터와 Top-Index 블록을 저장하는 데 필요한 캐시 크기(벤치 데이터 세트에서 DB 크기의 약 0.11%~0.14% )를 나타내고, 변곡점 2(IP2)는 모든 비-LLast Bloom 필터와 모든 인덱스 블록을 저장하는 데 필요한 캐시 크기(벤치 데이터 세트에서 DB 크기의 약 0.9% )를 나타냅니다.
블룸 필터 및 상위 인덱스 적중률
| 캐시 크기 | 소규모 데이터 세트 (필터 적중률) | 중간 크기 데이터 세트 (필터 적중률) | 대규모 데이터 세트 (필터 적중률) | 소규모 데이터 세트 (최고 인덱스 적중률) | 중간 규모 데이터 세트 (최고 인덱스 적중률) | 대규모 데이터 세트 (최고 인덱스 적중률) |
|---|---|---|---|---|---|---|
| IP1에서 | 98.5% | 99.6% | 98.9% | 96.4% | 97.8% | 95.4% |
| IP1을 넘어서 (≈0.2% DB) | 100% | 100% | 100% | 100% | 100% | 100% |
캐시가 변곡점 1을 초과하면 블룸 필터와 최상위 인덱스 모두 거의 100% 적중률을 달성하고 음수 조회는 메모리에서 해결됩니다.
인덱스 블록 적중률
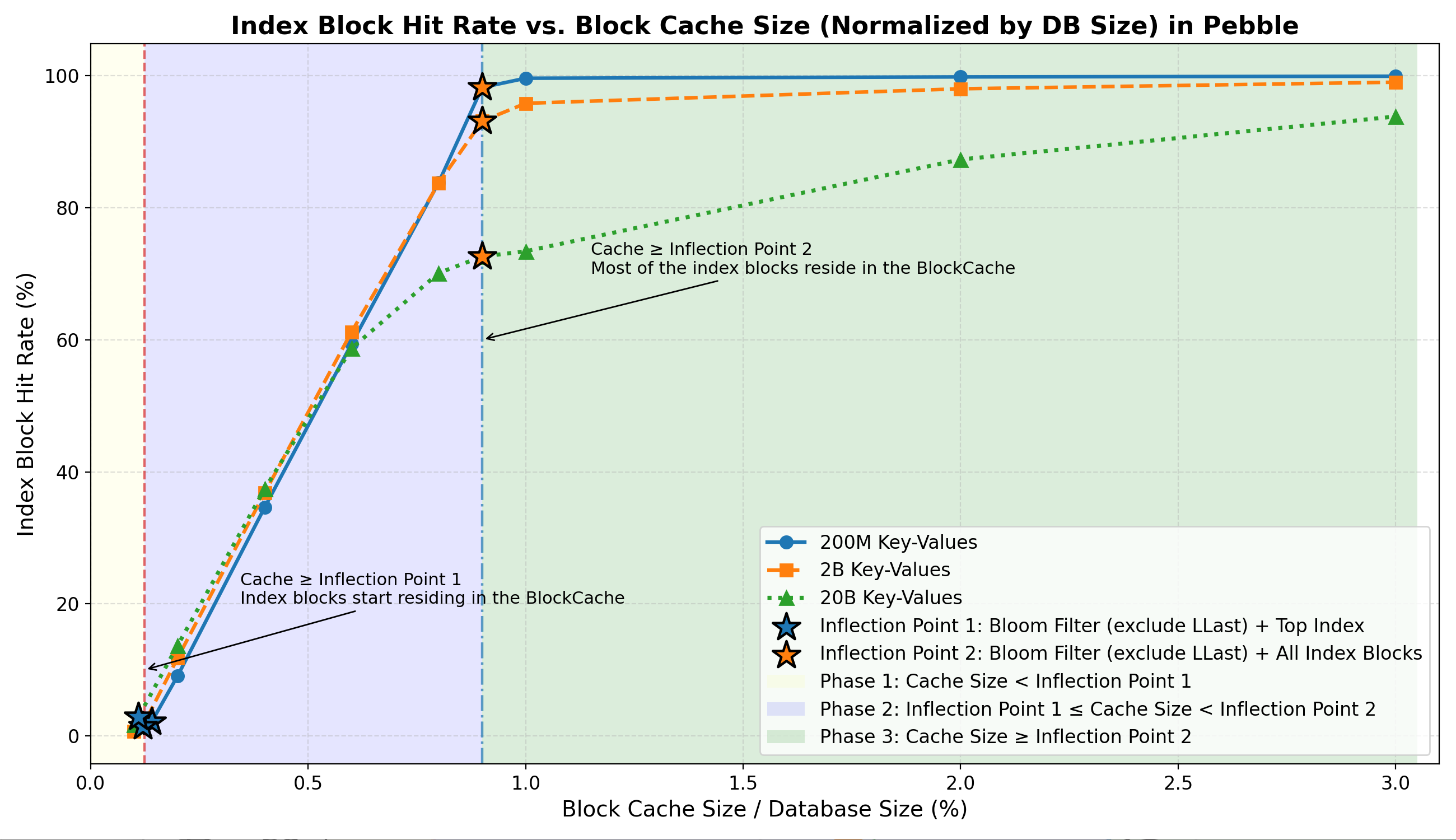
- 1단계: 캐시된 인덱스 블록 수가 매우 적습니다(약 1%~3% ).
- 2단계: 캐시가 변곡점 2에 가까워짐에 따라 인덱스 적중률이 약 70~99%까지 급격히 상승합니다 .
- 3단계: 대부분의 인덱스 블록이 메모리에 상주하며, 적중률은 높은 수준(약 70%~99%) 에 도달하고 더 이상의 향상은 미미합니다.
데이터 블록 적중률
| 캐시 크기 | 소규모 데이터 세트 (데이터 블록 적중률) | 중간 크기 데이터 세트 (데이터 블록 적중률) | 대규모 데이터 세트 (데이터 블록 적중률) |
|---|---|---|---|
| IP1에서 | 1.0% | 0.7% | 1.3% |
| IP1을 넘어서 (≈0.2% DB) | 1.2% | 0.9% | 1.6% |
| IP2에서 | 1.4% | 1.1% | 2.4% |
| IP2를 넘어서 (약 3% DB) | 3.2% | 3.0% | 4.3% |
세 단계 모두에서 데이터 블록 적중률은 일관되게 낮게 유지되며, 데이터 블록 캐싱은 무작위 읽기 워크로드에서 관찰된 I/O 감소에 거의 기여하지 않습니다 .
전체 블록 캐시 적중률
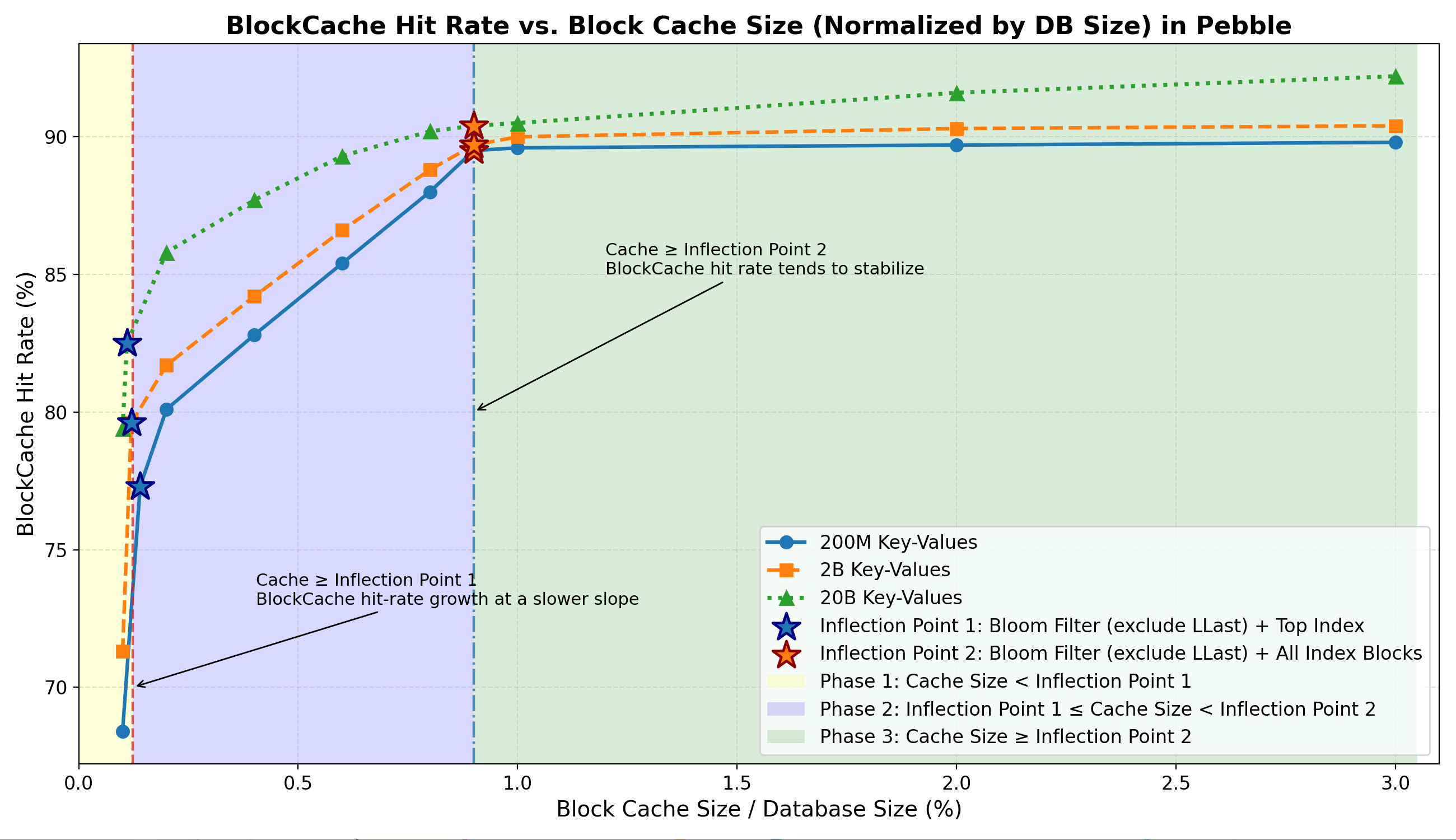
- 1단계: Bloom 필터와 Top Index의 빠른 메모리 상주 로 인해 적중률이 급격히 상승합니다.
- 2단계: 인덱스 블록이 상주하게 되면서 적중률이 더 완만한 속도 로 증가합니다.
- 3단계: 무작위 읽기 작업 부하에서 데이터 블록 캐싱의 영향이 미미하므로 적중률이 안정화됩니다 .
읽기 I/O 비용(Get당)(핵심 결과)
이 섹션에서는 다양한 메타데이터 구성 요소의 캐시 상주 시간이 궁극적으로 종단 간 임의 읽기 I/O 비용에 어떻게 영향을 미치는지 요약합니다.
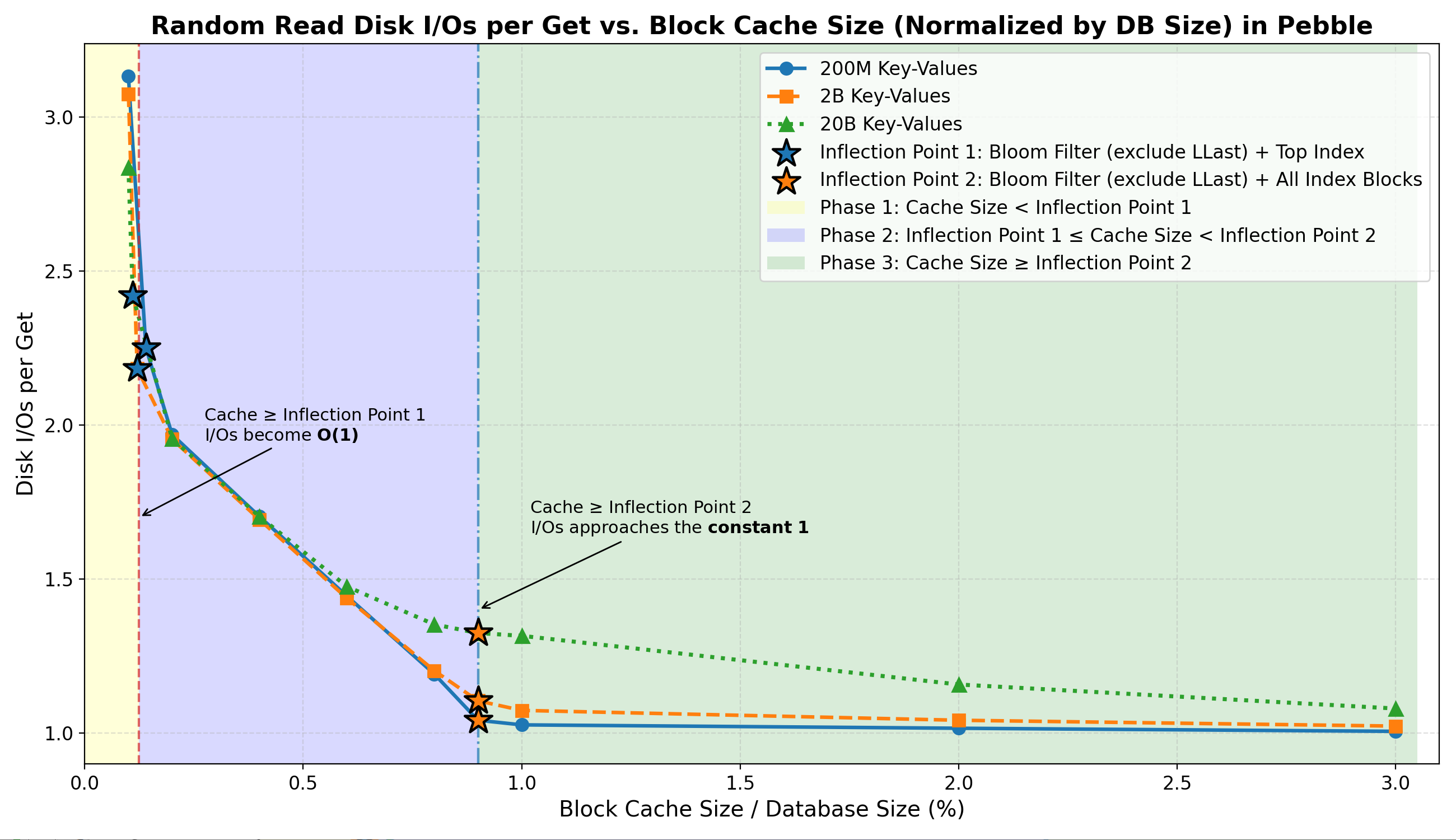
- 변곡점 1 (
Filter + Top-Index)
캐시가 이 지점에 도달하면:- 필터 및 상위 색인 검색 성공률이 약 100% 에 달합니다.
- 대부분의 부정 조회는 메모리에서 완전히 해결됩니다 .
-
I/Os per Get~2.2–2.4( 실질적으로 O(1) 조회 )로 안정화됩니다 .
- 2단계 (두 변곡점 사이)
이 전환 영역에서는:- 인덱스 블록 상주 기간이 빠르게 증가하고 인덱스 블록 적중률이 약 70%~99% 까지 급격히 상승합니다.
- Get당 I/O 횟수가 1.0~1.3으로 급격히 감소합니다.
- 변곡점 2 (
Filter + All-Index)
이 지점 이후로는:-
I/Os per Get엄격한 하한 ~1에 근접합니다 . - 캐시 크기를 더 늘려도 I/O 감소 효과는 미미합니다 .
-
- 데이터 블록 캐싱은 모든 단계에서 무시할 수 있을 정도로 미미합니다.
- 데이터셋 크기(22GB~2.2TB)에 관계없이 일관된 동작을 보였습니다.
이는 다음을 확인시켜 줍니다:
전반적으로 무작위 읽기 I/O는 주로 블룸 필터와 인덱스 상주에 의해 좌우됩니다.
결론 및 권고사항
Pebble의 이론적인 최악의 읽기 복잡도는 O(log N) 이지만, 실제 캐시 구성에서는 이러한 한계를 관찰하기 어렵습니다.
Bloom 필터(LLast 제외)와 인덱스 블록의 충분한 캐시 상주로 인해 Pebble의 실제 읽기 I/O 동작은 실질적으로 O(1) 이며 Get 작업당 1~2 I/O 로 일관되게 수렴합니다.
캐시 구성 권장 사항
본 연구 결과는 Pebble의 읽기 I/O 비용이 LSM 트리 깊이보다는 캐시에 저장되는 메타데이터 구성 요소 에 의해 주로 결정됨을 보여줍니다. 따라서 실제로는 원하는 읽기 성능을 기준으로 캐시 크기를 직접 선택할 수 있습니다.
거의 일정한 읽기 성능(Get당 약 2회의 I/O)
변곡점 1 이후의 캐시(LLast 및 Top-Index 블록을 제외한 블룸 필터).
이 방식은 아주 작은 캐시 (일반적으로 데이터베이스 크기의 0.2% 미만 )만 필요로 하며, 대부분의 부정 조회 I/O를 제거합니다.
예측 가능한 읽기 성능이 요구되는 메모리 제약 환경에 적합합니다.거의 단일 I/O 읽기(Get당 약 1.0~1.3 I/O)
변곡점 2 이후의 캐시(블룸 필터 + 모든 인덱스 블록).
이를 위해서는 작은 캐시 (일반적으로 데이터베이스 크기의 1.5% 미만 )가 필요하며, 읽기 속도를 실질적인 하한선에 가깝게 만듭니다.
지연 시간에 민감한 실행 계층 및 읽기 작업이 많은 워크로드에 적합합니다.
변곡점 2 이후에는 캐시 크기를 더 늘려도 무작위 읽기 작업 부하에서 I/O 감소 효과가 미미해 집니다.






