

이 기사는 기계로 번역되었습니다
원문 표시
Karpathy는 자신이 어떻게 로컬 AI 지식 기반을 구축했는지 공유했습니다.
제가 사용한 방법과 유사하지만, 배울 점이 많으니 참고하시기를 추천합니다.
두 사람 모두 Obsidian과 순수 로컬 Markdown을 사용했고, 백링크와 색인을 통해 서로 연결했습니다.
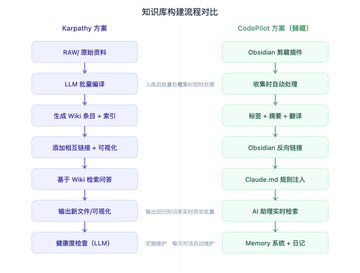
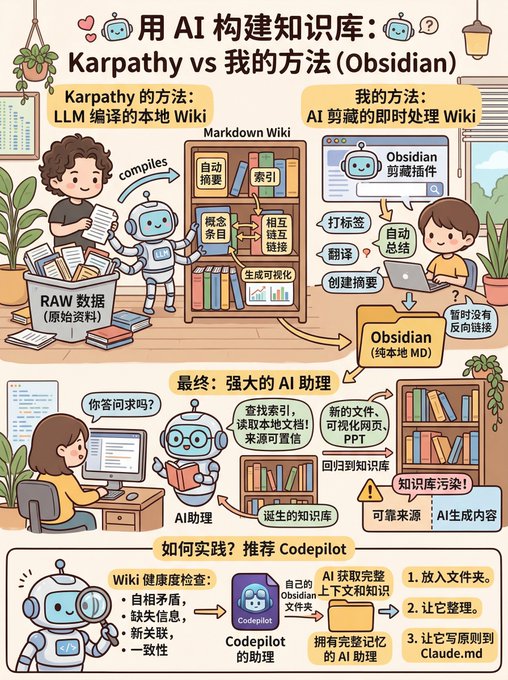
Karpathy는 대규모 언어 모델을 기반으로 개인 위키 지식 기반을 구축하고, 모든 원자료를 RAW라는 디렉토리에 저장했습니다.
그런 다음 대규모 언어 모델이 이 원자료들을 Markdown 위키로 컴파일하여 요약, 색인, 개념 항목, 상호 링크, 시각화 등을 자동으로 생성하는 기능을 구현했습니다.
저는 이미 Obsidian 클리핑 플러그인을 사용하여 콘텐츠 수집 과정에서 이러한 작업을 수행했습니다.
콘텐츠 수집 과정에서 AI는 태깅, 자동 요약, 번역, 요약 생성 등의 작업을 자동으로 처리합니다. 현재는 백링크가 생성되지 않았습니다.
위키 구축이 완료되면, 데이터 출처의 신뢰성을 확인하기 위해 위키에서 질문을 할 수 있습니다.
예를 들어, 대규모 언어 모델은 단순히 웹 페이지를 검색하는 데 그치지 않고 자동으로 색인을 검색하고 관련 문서를 읽어 답변이나 보고서를 작성합니다. 이러한 방식으로 모델이 수집하는 정보는 사용자에게 가장 관련성이 높습니다.
또한, 모델은 단순히 한 문장을 출력하는 데 그치지 않고 새로운 문서, 시각적 웹 페이지, 파워포인트 프레젠테이션 등을 생성하여 지식 기반에 다시 반영함으로써 지식 기반을 더욱 풍부하고 포괄적으로 만들어 줍니다.
하지만 Obsidian 개발자들이 지적했듯이, 이러한 방식은 지식 기반을 오염시킬 수 있다는 문제점을 내포하고 있습니다. 따라서 신뢰할 수 있는 출처의 정보와 AI가 생성한 콘텐츠를 구분하는 것이 좋습니다.
또 다른 장점은 대규모 모델을 통해 위키의 건전성 검사를 수행할 수 있다는 것입니다. 여기에는 모순점 식별, 누락된 정보 보완, 새로운 연결 발견, 일관성 개선 등이 포함됩니다.
이미 많은 기업에서 이러한 방식을 활용하고 있으며, 저 또한 CodePilot에 이 접근 방식을 적용했습니다.
어시스턴트 폴더 선택과 관련해서는 일반적으로 Obsidian 폴더를 사용하는 것을 권장합니다.
자신만의 Obsidian 폴더가 있다면, AI는 사용자의 모든 컨텍스트와 지식에 직접 접근할 수 있습니다.
예를 들어, 저는 제 Obsidian 폴더와 인터넷에서 AI 시대의 UI 디자인 원칙에 대한 기사들을 검색하도록 했습니다. 결과는 매우 훌륭했습니다.
이런 식으로, 완벽한 기억력을 가진 AI 비서를 바로 얻을 수 있습니다.
실제로 어떻게 활용해야 할지 모르겠다면 Codepilot의 어시스턴트를 사용해 보세요.
Obsidian 폴더를 어시스턴트 안에 넣고 정리하도록 한 다음, 이러한 원칙들을 Claude.md 형식으로 저장하도록 하세요.

Andrej Karpathy
@karpathy
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating

바나나로 만든 이미지 🍌

歸藏(guizang.ai)
@op7418
用香蕉做一张图片,来解释 Karpathy 的方法和我的方法之间的一些区别和共性 x.com/op7418/status/…
Twitter에서
면책조항: 상기 내용은 작자의 개인적인 의견입니다. 따라서 이는 Followin의 입장과 무관하며 Followin과 관련된 어떠한 투자 제안도 구성하지 않습니다.
라이크
즐겨찾기에 추가
코멘트
공유




