

원문: 장예(Ye Zhang)
컴파일러: FF
연설은 4개 부분으로 나누어 1부에서는 Zhang Ye가 개발 배경과 애초에 zkEVM이 왜 필요한지, 지난 2년 동안 zkEVM이 인기를 끌게 된 이유를 소개했고, 2부에서는 전체 과정을 통해 어떻게 zkEVM이 개발되었는지 설명했습니다. 산술화 및 증명 시스템을 포함하여 zkEVM을 처음부터 구축하기 위한 세 번째 부분에서는 몇 가지 흥미로운 연구 질문을 통해 zkEVM을 구축할 때 발생하는 문제에 대해 이야기하고 마지막으로 zkEVM을 사용하는 다른 애플리케이션을 소개합니다.


배경과 동기

전통적인 레이어 1 블록체인에는 P2P 네트워크를 통해 함께 유지 관리되는 일부 노드가 있습니다. 사용자의 트랜잭션을 수신하면 EVM 가상 머신에서 이를 실행하고 호출 계약 및 스토리지를 읽고 트랜잭션에 따라 전역 상태 트리를 업데이트합니다.
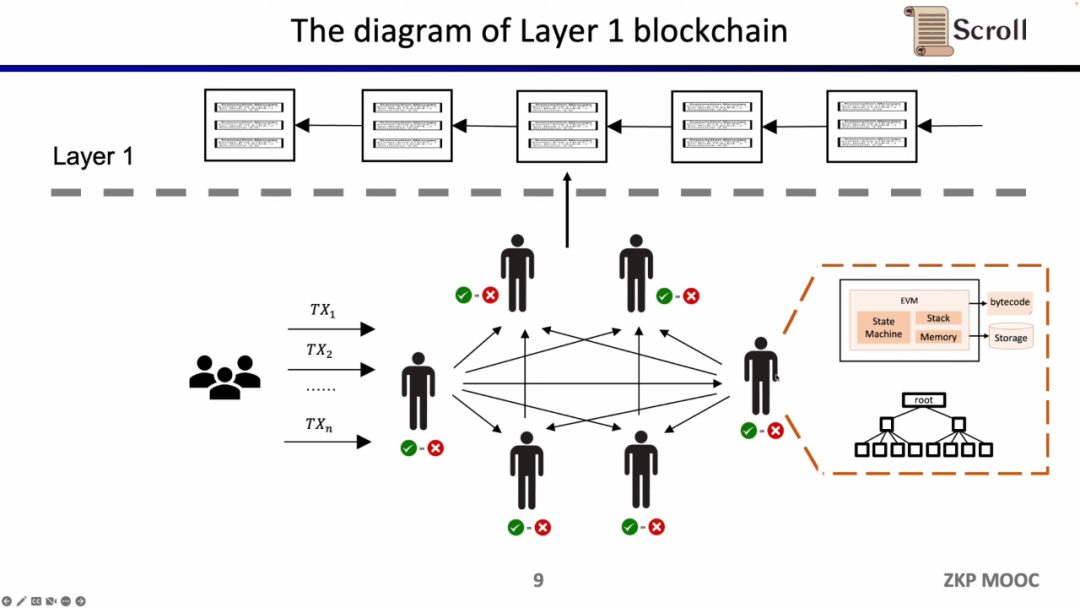
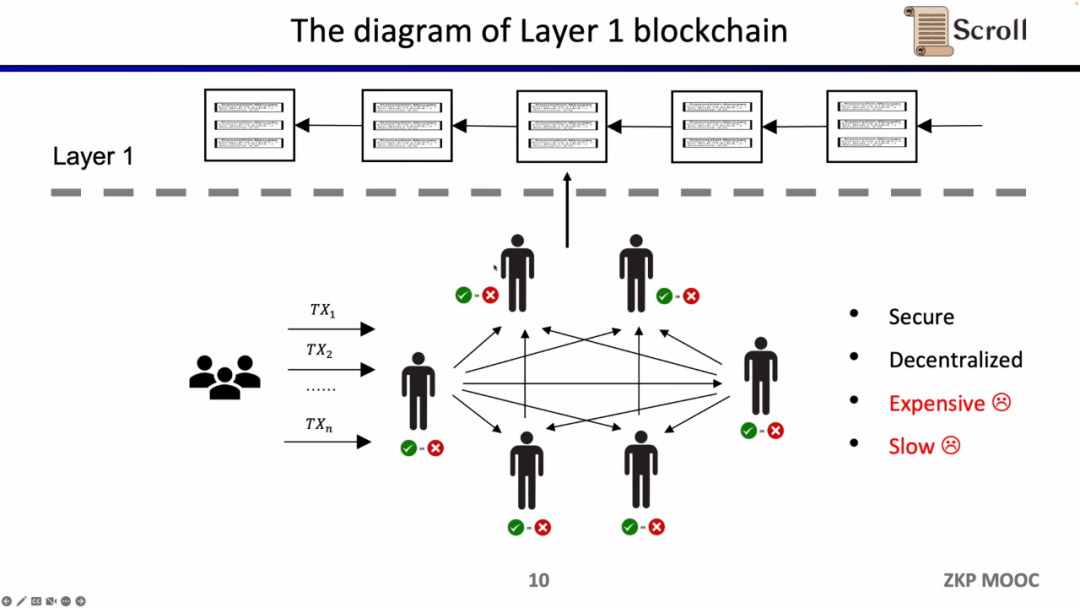
이러한 아키텍처의 장점은 탈중앙화와 보안이지만, 단점은 L1의 거래 수수료가 비싸고 거래 확인이 느리다는 점이다.
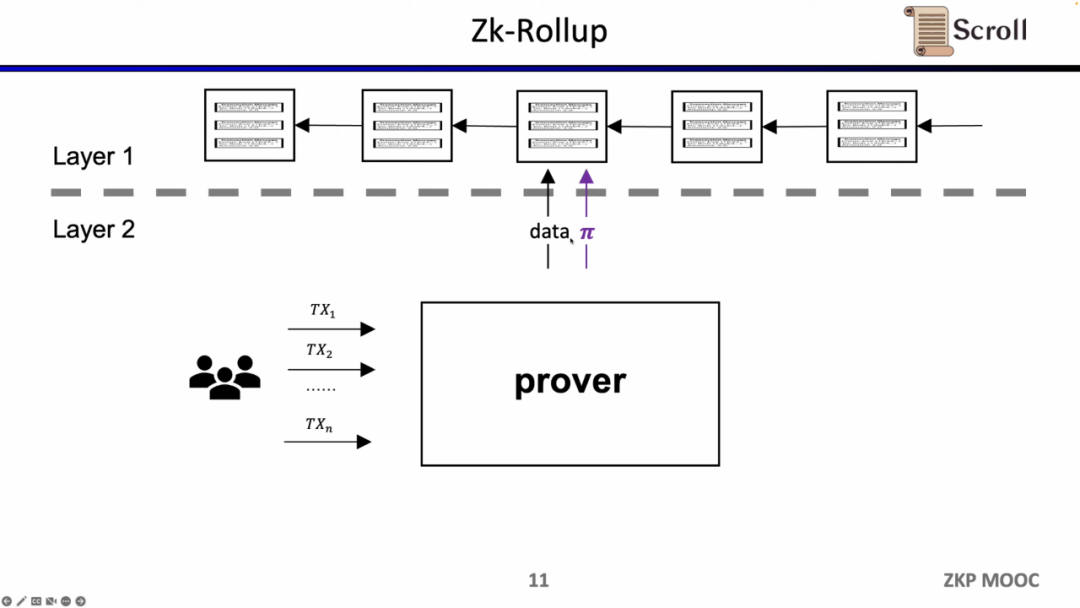
ZK-Rollup 아키텍처에서 L2 네트워크는 데이터의 정확성을 확인하기 위해 데이터와 증명만 L1에 업로드하면 되며, L1에서 증명은 영지식 증명 회로를 통해 계산됩니다.
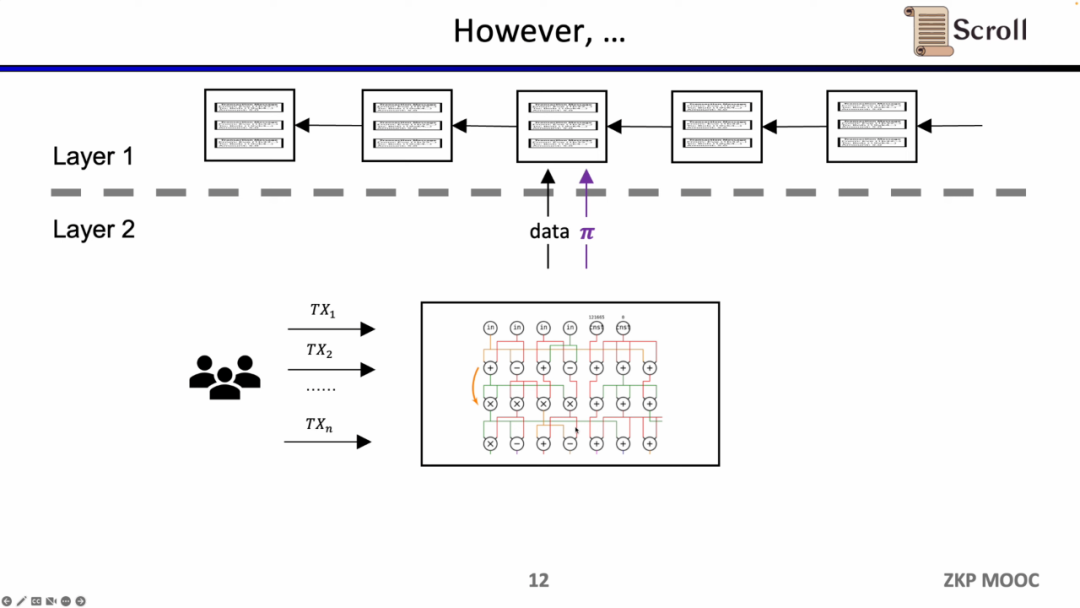
초기 ZK-Rollup에서는 특정 애플리케이션을 위해 회로가 설계되었으며, 사용자는 서로 다른 증명자에게 트랜잭션을 보내야 하고, 서로 다른 애플리케이션의 ZK-Rollup은 자신의 데이터와 증명을 L1에 제출했습니다. 이로 인해 발생하는 문제는 원래 L1 계약의 구성성이 손실된다는 것입니다.
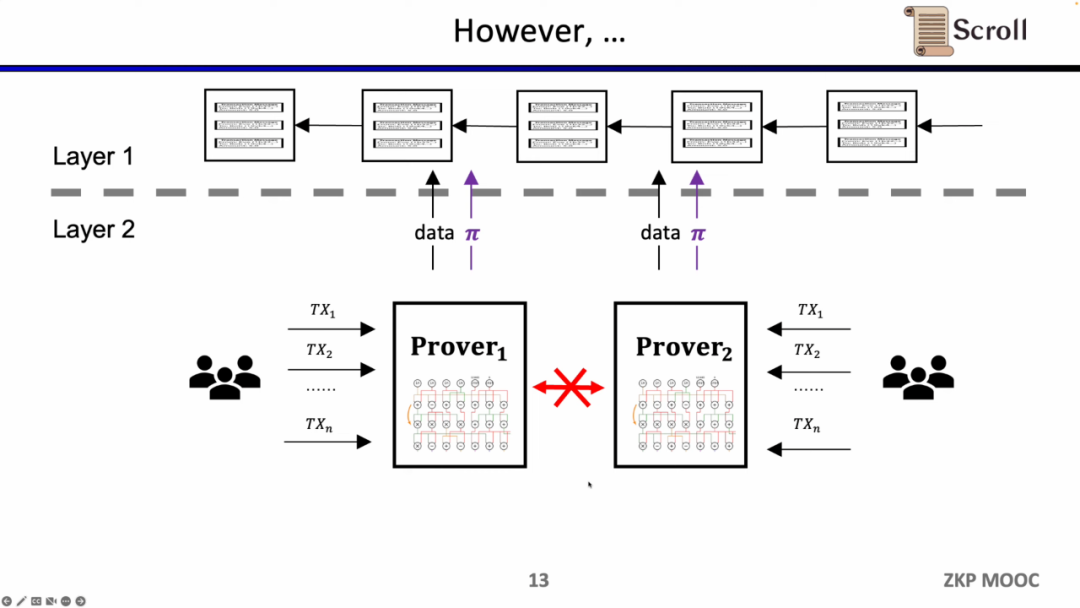
Scroll이 하는 일은 범용 ZK-Rollup인 기본 zkEVM 솔루션입니다. 이는 더욱 사용자 친화적일 뿐만 아니라 개발자에게 L1에서 더 나은 개발 경험을 제공합니다. 물론, 이에 대한 개발은 매우 어렵고 현재 증명 생성 비용도 매우 높습니다.
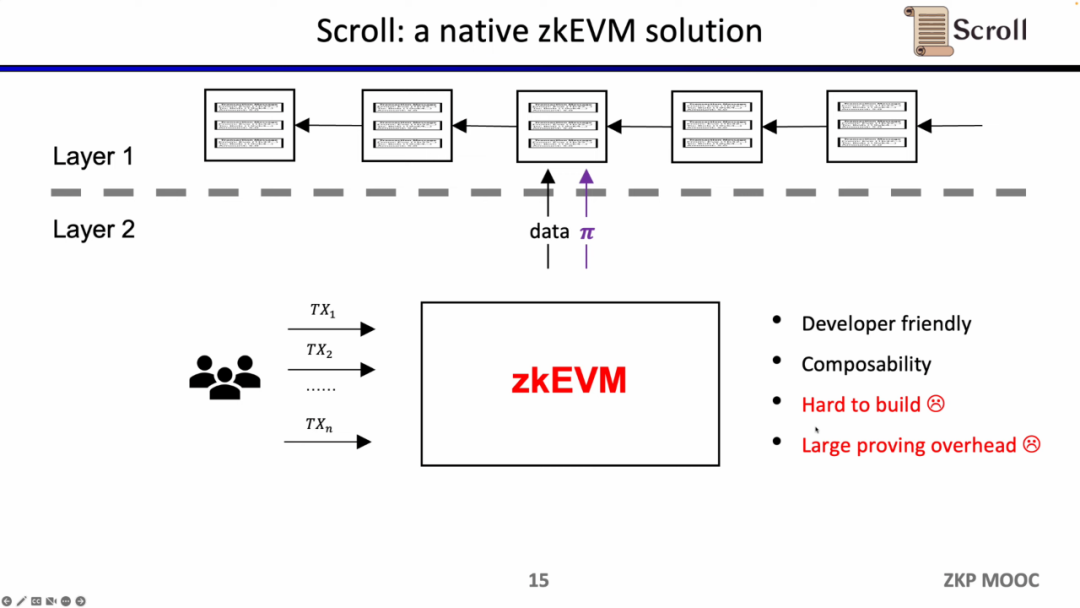
다행스럽게도 지난 2년 동안 영지식 증명의 효율성이 크게 향상되었으며, 이것이 지난 2년 동안 zkEVM이 인기를 얻은 이유입니다. 이것이 가능해지는 이유는 적어도 4가지가 있습니다. 첫 번째는 다항식 확약의 출현입니다. 원래 Groth16 증명 시스템에서는 제약의 규모가 매우 컸지만 다항식 확약은 고차 제약을 지원하고 규모를 줄일 수 있습니다. 증명, 둘째, 룩업 테이블과 맞춤형 게이트의 출현으로 보다 유연한 설계를 지원하고 증명의 효율성을 높일 수 있습니다. 셋째, GPU, FPGA 및 ASIC을 통해 증명 시간을 1~2배 단축할 수 있는 획기적인 하드웨어 가속입니다. 네 번째 재귀 증명에서는 여러 증명을 하나의 증명으로 압축하여 증명을 더 작고 검증하기 쉽게 만들 수 있습니다. 그래서 이 4가지 요소를 합치면 영지식 증명의 생성 효율이 2년 전보다 3배나 높아진다는 것이 스콜의 유래이기도 하다.
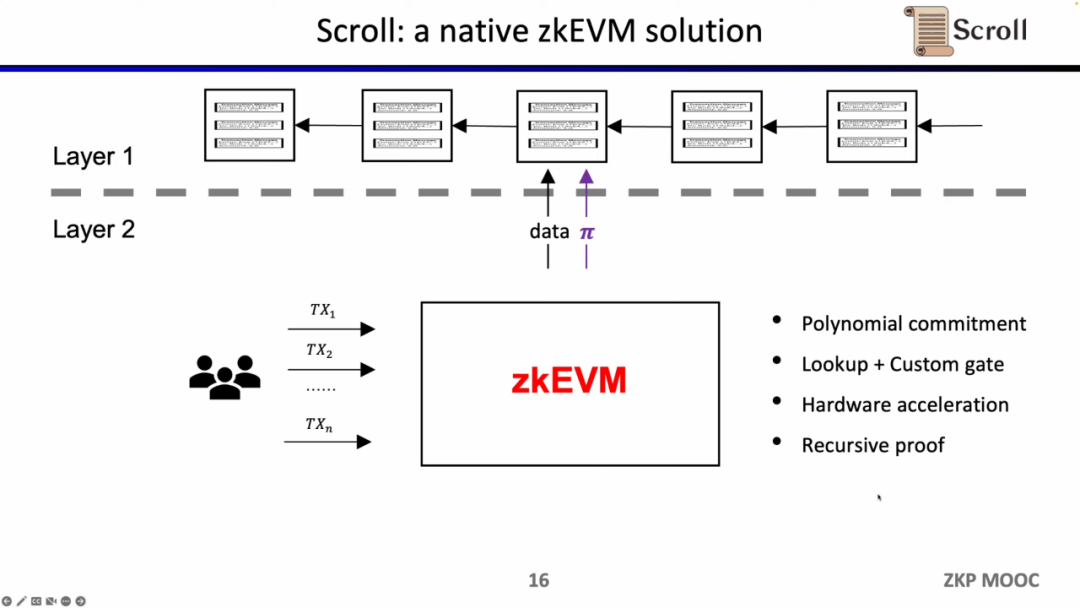
Justin Drake의 정의에 따르면 zkEVM은 세 가지 범주로 나눌 수 있습니다. 첫 번째 범주는 언어 수준 호환성입니다. 가장 큰 이유는 EVM이 ZK용으로 설계되지 않았고 ZK에 친숙하지 않은 많은 opcode를 포함하므로 오류가 발생할 수 있기 때문입니다. 추가 오버헤드가 많다. 따라서 Starkware 및 zkSync와 같은 회사는 Solidity 또는 Yul을 언어 수준에서 ZK 친화적인 컴파일러로 컴파일하기로 선택합니다.
두 번째 유형은 Scroll이 하고 있는 바이트코드 수준에서의 호환성으로, EVM의 바이트코드 처리가 올바른지 직접적으로 증명하고, 이더리움의 실행 환경을 직접 상속한다. 여기에서 이루어질 수 있는 몇 가지 절충점은 ZK 친화적인 데이터 구조를 사용하는 등 EVM과 다른 상태 루트를 사용하는 것입니다. Hermez와 Consensys도 비슷한 일을 하고 있습니다.
세 번째 범주는 합의 수준의 호환성입니다. 여기서의 절충점은 EVM을 변경하지 않고 유지해야 할 뿐만 아니라 증명 시간이 길어지더라도 이더리움과의 완전한 호환성을 달성하기 위해 저장 구조를 포함해야 한다는 것입니다. 스크롤은 이더리움의 ZK화를 실현하기 위해 이더리움 재단의 PSE 팀과 협력하여 구축되고 있습니다.

zkEVM을 0에서 1로 빌드

두 번째 부분에서 Zhang Ye는 ZKVM을 처음부터 구축하는 방법을 모두에게 보여주었습니다.
완전한 과정
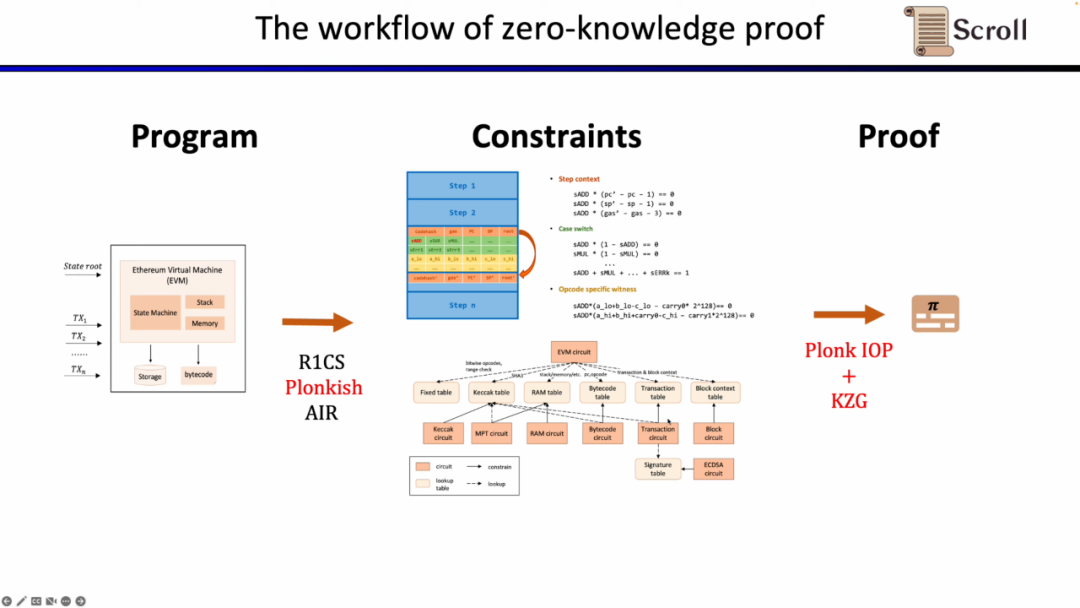
우선 ZKP의 프론트엔드 부분에서는 수학적 산술을 통해 계산을 표현해야 하는데, 가장 흔히 사용되는 것은 선형 R1CS와 Plonkish, AIR이다. 연산을 통해 제약 조건을 얻은 후 ZKP 백엔드에서 증명 알고리즘을 실행하여 계산의 정확성을 입증해야 합니다. 가장 일반적으로 사용되는 다항식 대화형 오라클 증명(Polynomial IOP)과 다항식 확약 방식(PCS)은 다음과 같습니다.
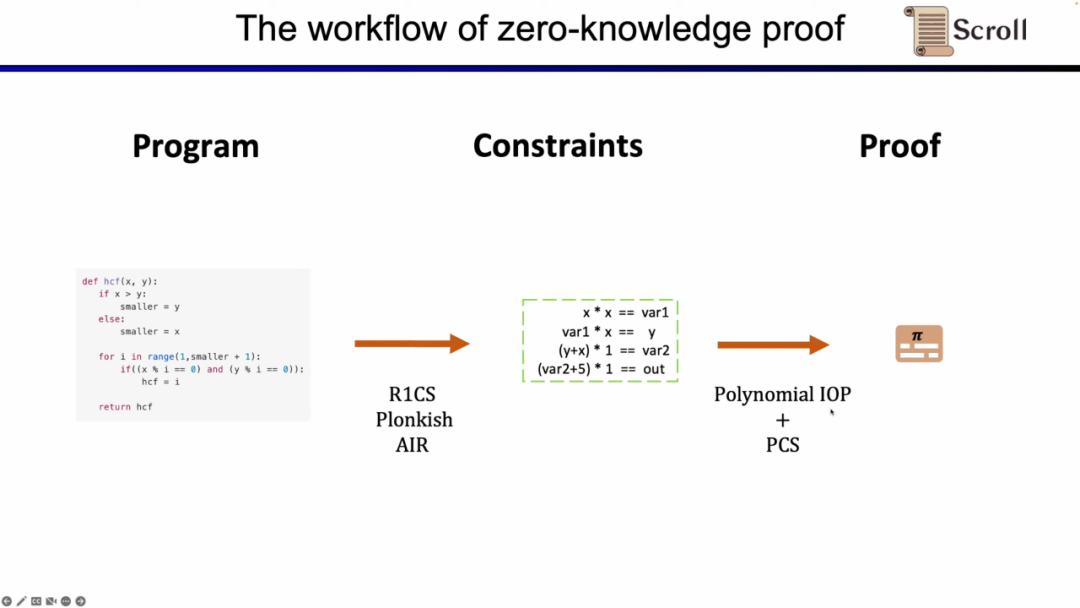
여기서 우리는 zkEVM, Scroll이 Plonkish, Plonk IOP 및 KZG의 조합을 사용한다는 것을 증명해야 합니다.
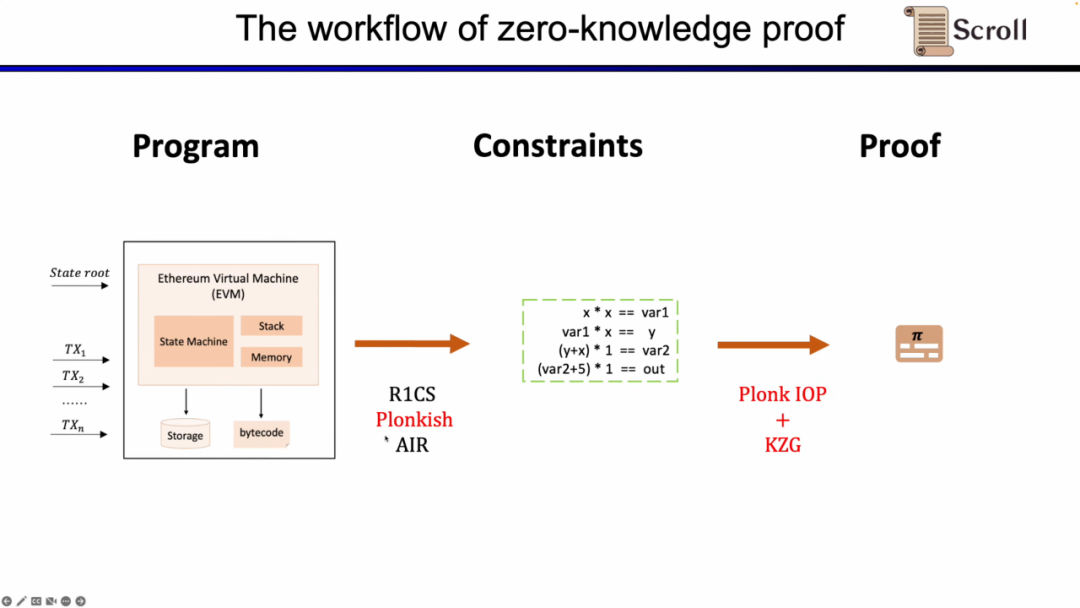
우리가 이 세 가지 솔루션을 사용하는 이유를 이해합니다. 먼저 가장 간단한 R1CS부터 시작합니다. R1CS의 제약 조건은 선형 결합과 선형 결합의 곱이 선형 결합과 같다는 것입니다. 추가 오버헤드 없이 변수의 선형 조합을 추가할 수 있지만 각 제약 조건의 최대 차수는 2입니다. 따라서 고차 작업의 경우 더 많은 제약 조건이 필요합니다.

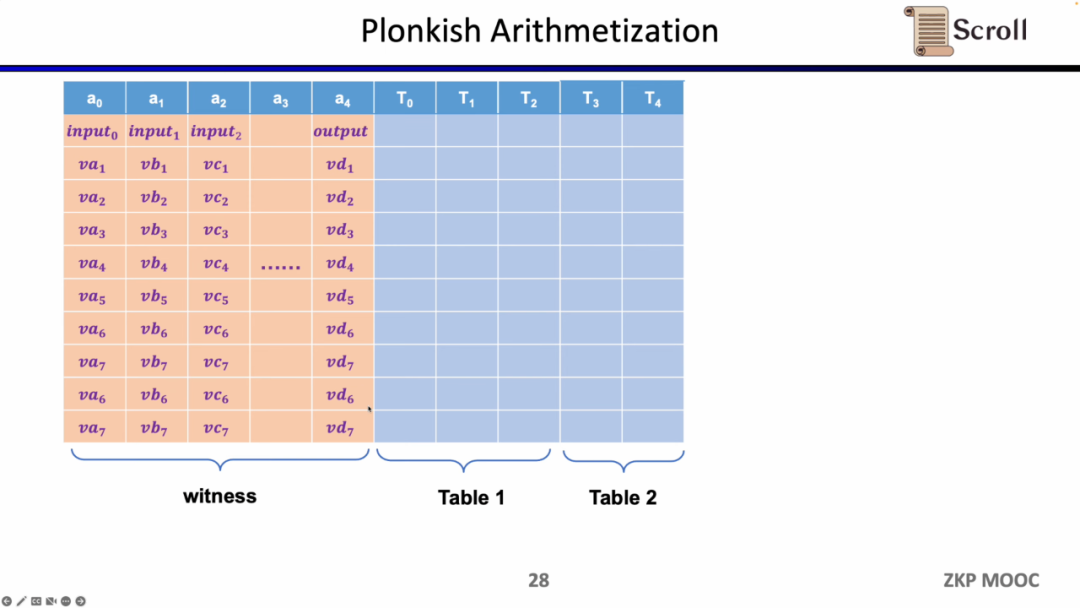
Plonkish에서는 입력, 출력 및 중간 변수의 증인을 포함하여 모든 변수를 테이블에 채워야 합니다. 또한 다양한 제약 조건을 정의할 수 있습니다. Plonkish에는 세 가지 유형의 제약 조건이 있습니다.
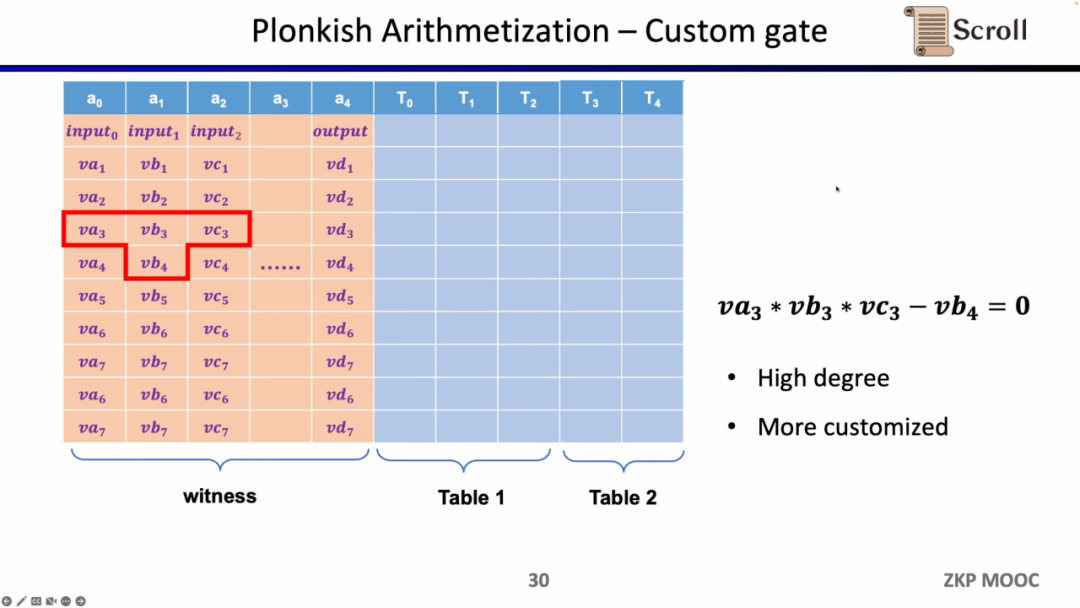
첫 번째 제약 조건 유형은 사용자 정의 게이트입니다. va3 * vb3 * vc3 - vb4 =0과 같이 서로 다른 셀 간의 다항식 제약 조건 관계를 정의할 수 있습니다. R1CS와 비교할 때 모든 변수에 대한 제약 조건을 정의할 수 있고 매우 다른 제약 조건을 정의할 수 있으므로 순서가 더 높을 수 있습니다.
두 번째 유형의 제약조건은 동등성 검사인 순열(Permuation)입니다. 이는 서로 다른 셀의 등가성을 확인하는 데 사용할 수 있으며 이전 게이트의 출력이 다음 게이트의 입력과 동일하다는 것을 증명하는 것과 같이 회로의 서로 다른 게이트를 연결하는 데 자주 사용됩니다.

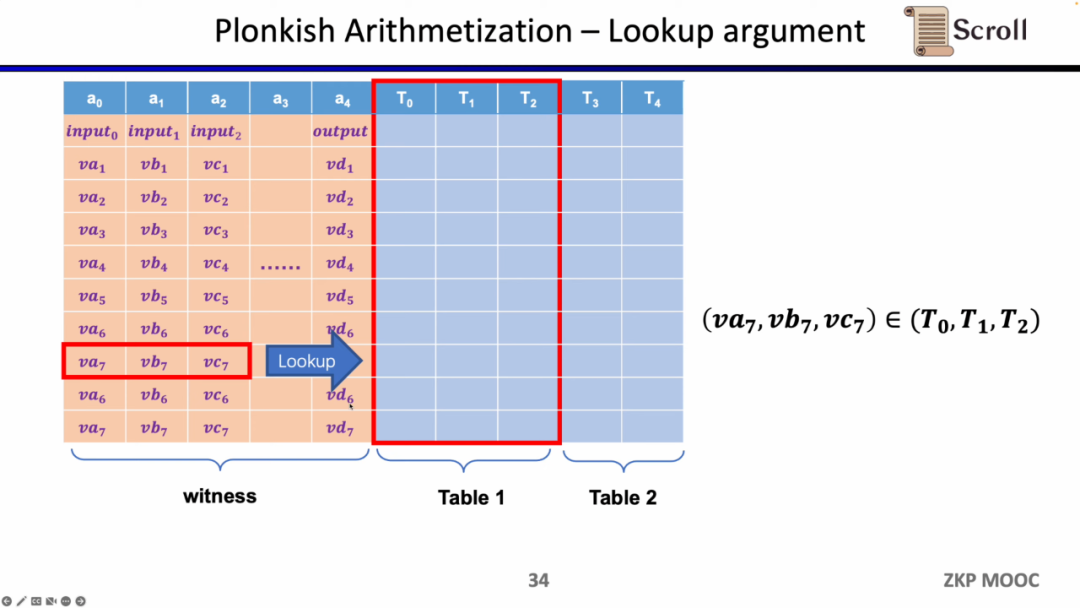
마지막 제약 조건 유형은 조회 테이블입니다. 룩업 테이블은 변수 간의 관계로 이해할 수 있으며, 이를 테이블로 표현할 수 있습니다. 예를 들어 vc7이 0-15 범위에 있음을 증명하려면 R1CS에서 먼저 이 값을 4비트 바이너리로 분해한 다음 각 비트가 0-1 범위에 있음을 증명해야 합니다. 네 가지 제약 조건이 필요합니다. Plonkish에서는 동일한 열에 가능한 모든 범위를 나열할 수 있으며 vc7이 해당 열에 속한다는 것만 증명하면 됩니다. 이는 범위 증명에 매우 효율적입니다. zkEVM에서 조회 테이블은 메모리 읽기 및 쓰기를 증명하는 데 매우 유용합니다.
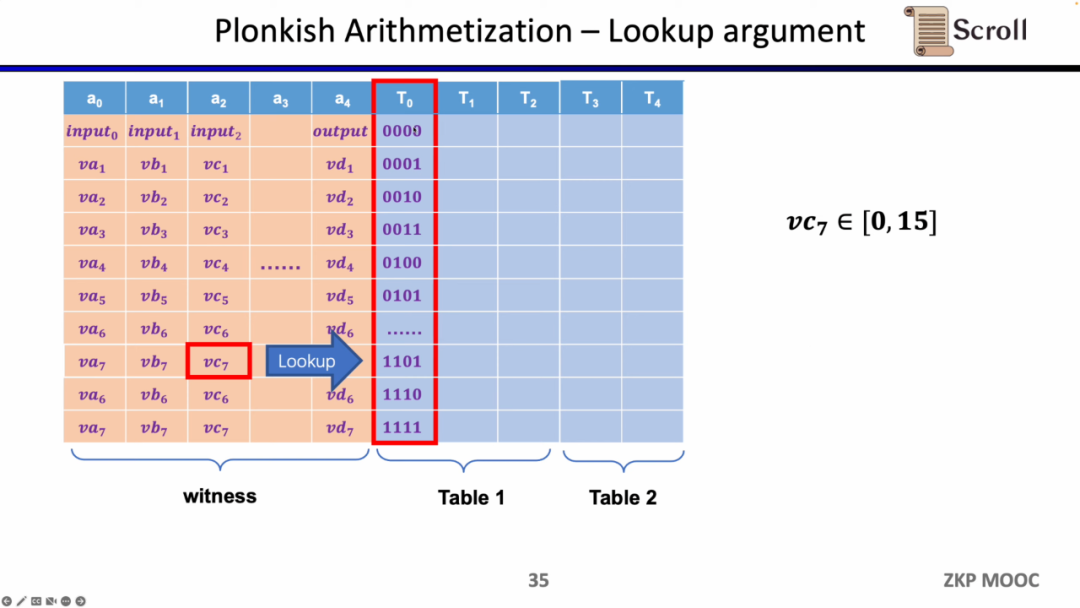
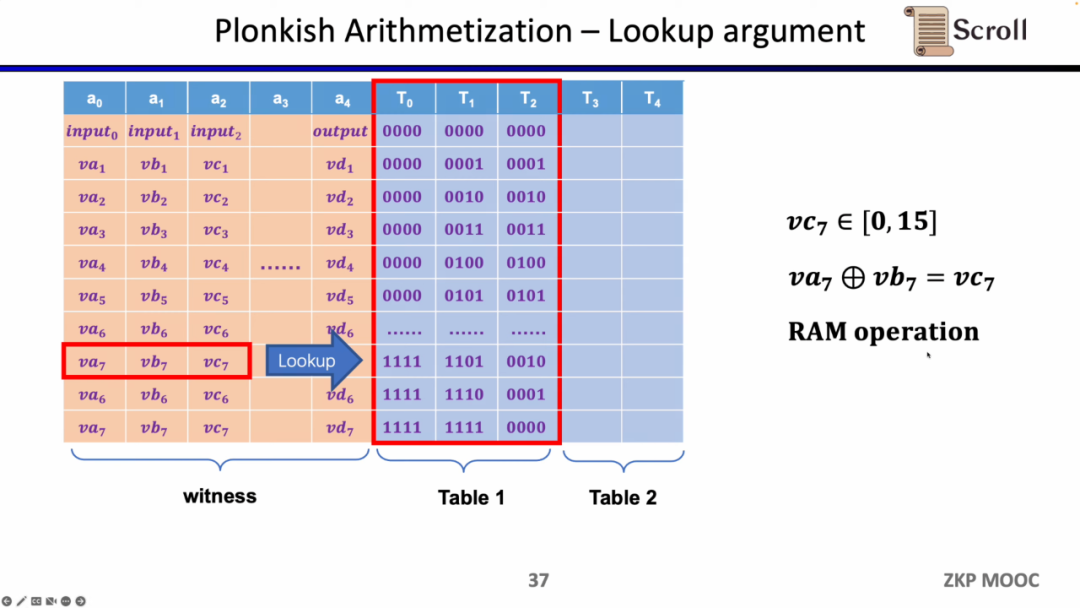
요약하자면, Plonkish는 다양한 회로 요구 사항을 충족하는 데 매우 유연할 수 있는 맞춤형 게이트, 등가 검사 및 조회 테이블도 지원합니다. STARK의 간단한 비교입니다. STARK의 각 행은 제약 조건입니다. 제약 조건은 행 간의 상태 전환을 나타내야 하지만 Plonkish의 사용자 지정 제약 조건의 유연성은 분명히 더 높습니다.
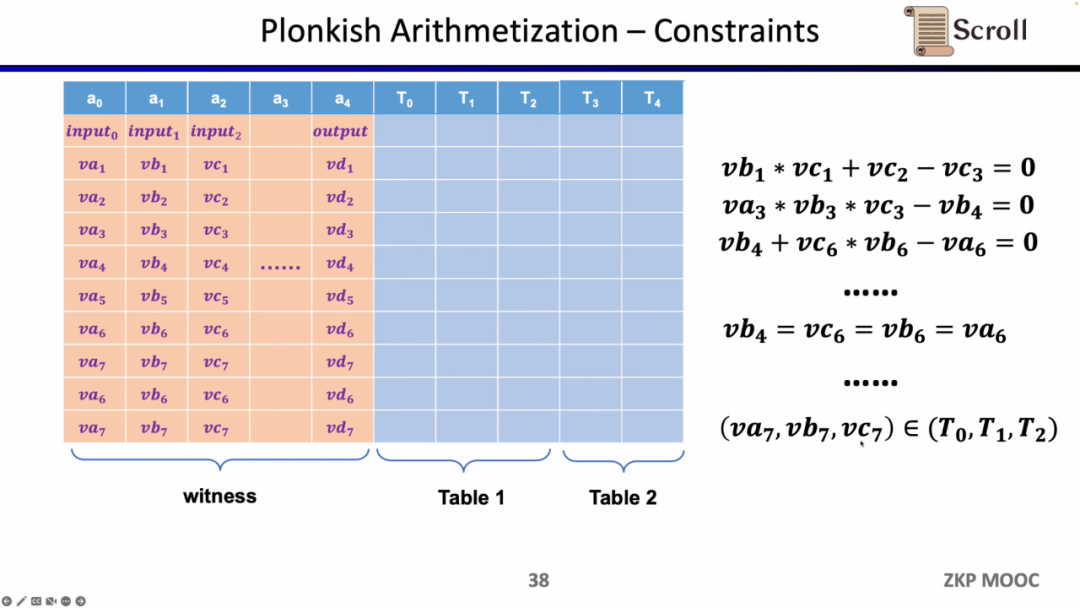
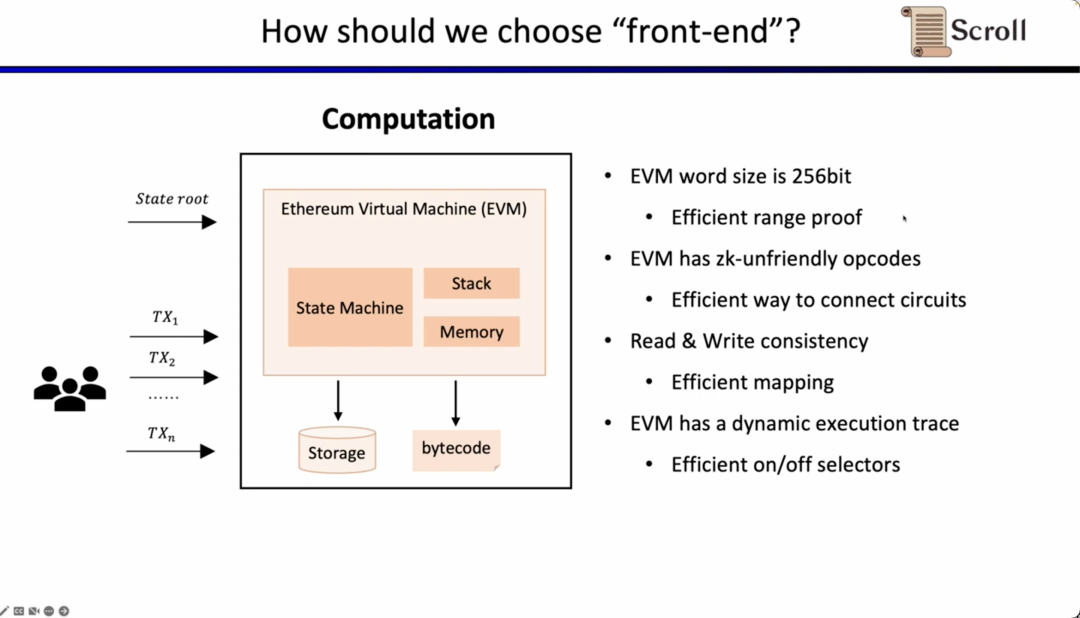
이제 문제는 zkEVM에서 프런트 엔드를 선택하는 방법입니다. zkEVM에는 네 가지 주요 과제가 있습니다. 첫 번째 과제는 EVM의 필드가 256비트이므로 변수를 효율적으로 범위 제한해야 한다는 것입니다. 두 번째 과제는 EVM에 ZK에 적합하지 않은 opcode가 많기 때문에 이러한 작업을 증명하려면 매우 큰 규모의 제약이 필요하다는 것입니다. Keccak-256과 같은 코드, 세 번째 과제는 메모리 읽기 및 쓰기 문제입니다. 읽은 내용이 이전에 작성한 내용과 일치함을 증명하기 위한 효과적인 매핑이 필요합니다. 네 번째 과제는 EVM의 실행 추적입니다. 동적으로 변경되므로 다양한 실행 추적에 적응하려면 사용자 지정 게이트가 필요합니다. 위의 고려 사항을 위해 Plonkish를 선택했습니다.
다음으로 zkEVM의 전체 프로세스를 살펴보겠습니다. 초기 전역 상태 트리를 기반으로 새 트랜잭션이 들어온 후 EVM은 저장되고 호출된 계약의 바이트코드를 읽고 트랜잭션을 기반으로 해당 실행 추적을 생성합니다. PUSH, PUSH, STORE, CALLVALUE를 수행한 다음 전역 상태를 점진적으로 업데이트하여 트랜잭션 후 전역 상태 트리를 얻습니다. zkEVM은 초기 전역 상태 트리, 트랜잭션 자체, 트랜잭션 이후의 전역 상태 트리를 입력으로 사용하고 EVM 사양을 사용하여 실행 추적의 정확성을 증명합니다.
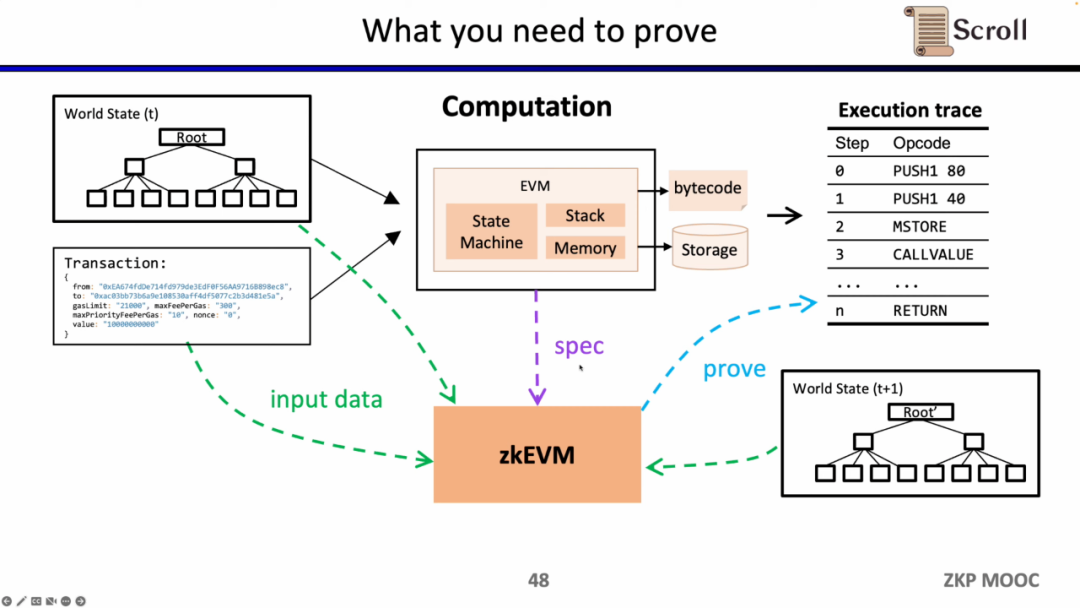
EVM 회로의 세부 사항을 살펴보면 실행 추적의 각 단계에는 해당 회로 제약 조건이 있습니다. 구체적으로 각 단계의 회로 제약 조건에는 단계 컨텍스트, 케이스 전환 및 Opcode 특정 증인이 포함됩니다. 단계 컨텍스트에는 실행 추적에 해당하는 코드해시, 남은 가스 및 카운터가 포함되어 있습니다. 케이스 스위치에는 모든 opcode, 모든 오류 조건 및 해당 단계의 작업이 포함되어 있습니다. Opcode 특정 감시에는 피연산자 대기와 같이 opcode에 필요한 추가 증인이 포함되어 있습니다.
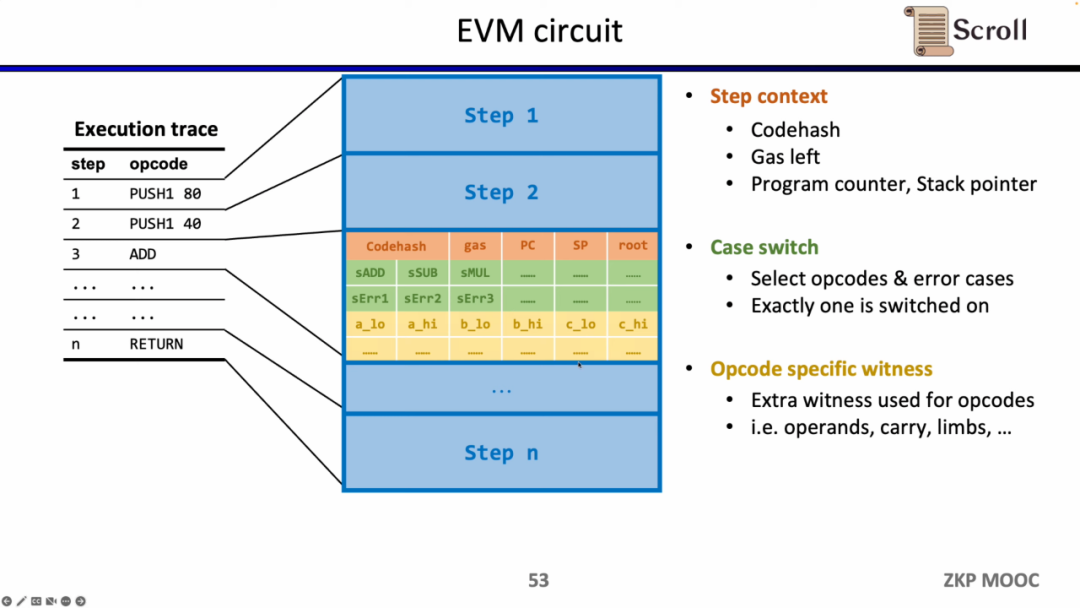
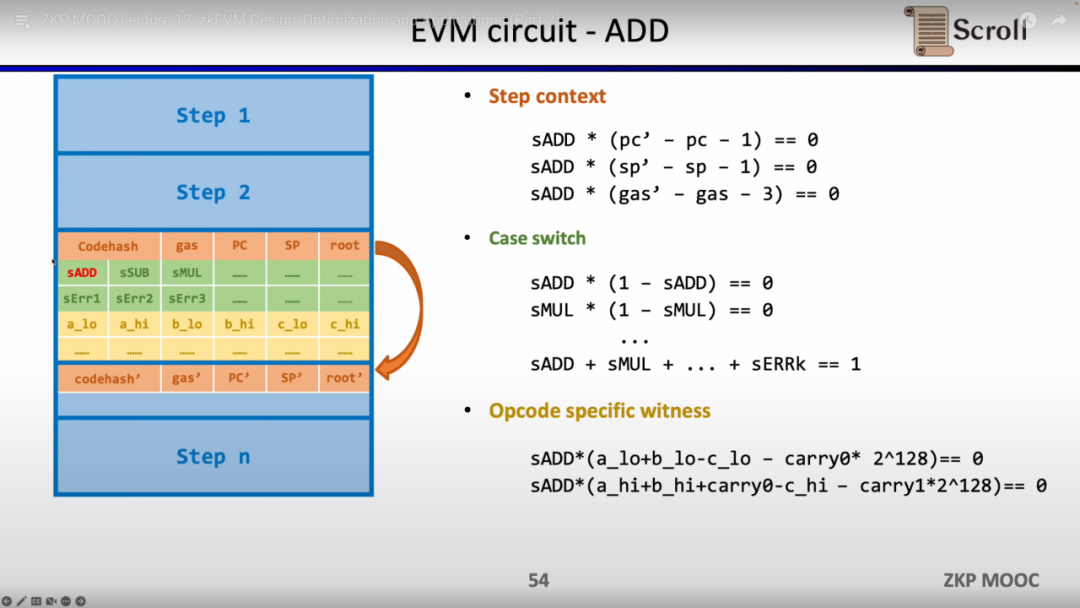
단순 덧셈을 예로 들면, 덧셈 opcode의 제어 변수 sADD가 1로 설정되어 있고, 다른 opcode의 제어 변수는 모두 0인지 확인해야 합니다. Step Context에서는 gas' - gas - 3 = 0으로 설정하여 소모된 가스를 3으로 제한합니다. 마찬가지로 카운터도 제한합니다. 스택 포인터는 단계 이후에 1을 누적합니다. Case Switch에서는 변수는 opcode를 통해 1로 제어됩니다. 이 단계를 추가 연산으로 제한하려면 Opcode 특정 증인에서 피연산자의 실제 추가를 제한합니다.
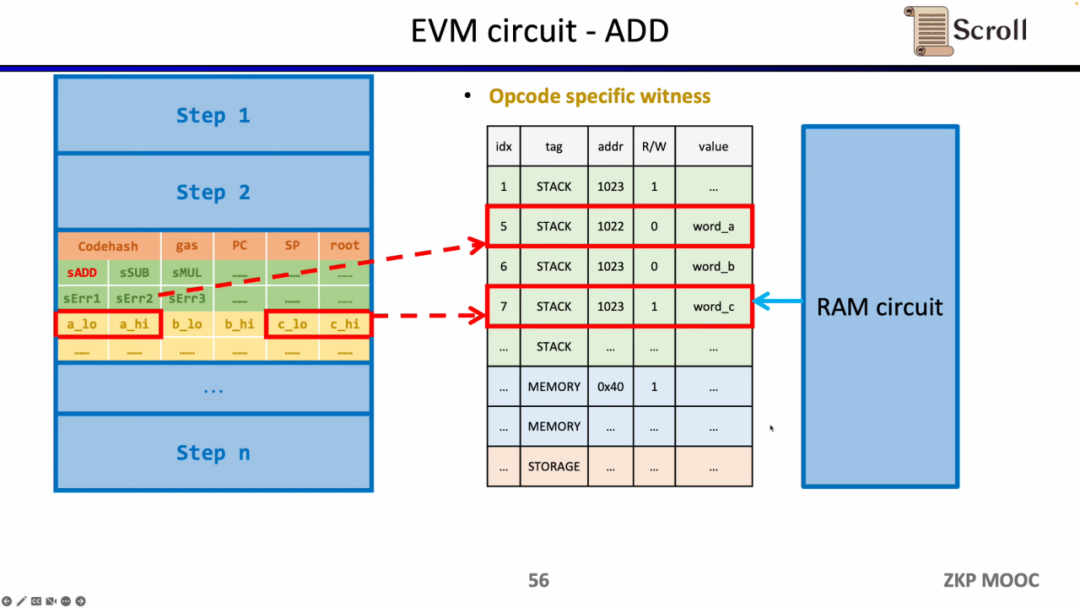
또한 메모리에서 읽는 피연산자의 정확성을 보장하려면 추가 회로 제약 조건이 필요합니다. 여기서는 먼저 피연산자가 메모리에 속한다는 것을 증명하기 위한 조회 테이블을 구축해야 합니다. 그리고 메모리 회로(RAM 회로)를 통해 메모리 테이블의 정확성을 검증합니다.
zk에 적합하지 않은 해시 함수에도 동일한 방법을 적용할 수 있는데, 해시 함수의 조회 테이블을 구축하고, 실행 추적의 해시 입력 및 출력을 조회 테이블에 매핑한 후, 추가 해시 회로를 사용하여 해시 함수를 검증합니다. 조회 테이블의 정확성.
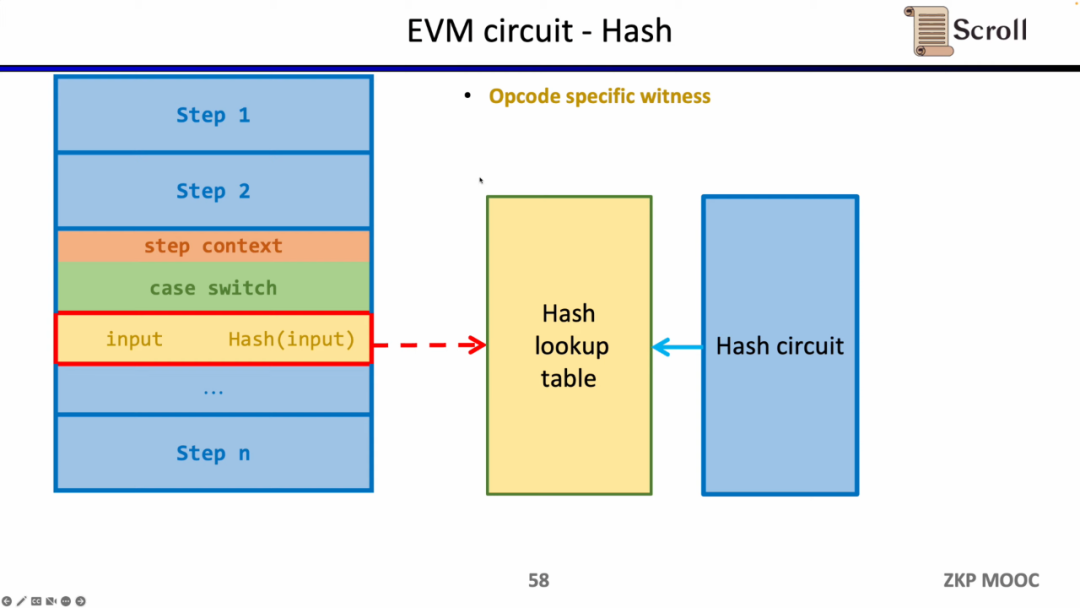
이제 zkEVM의 회로 아키텍처를 살펴보겠습니다. 핵심 EVM 회로는 실행 추적의 각 단계의 정확성을 제한하는 데 사용됩니다. EVM 회로 제약이 어려운 일부 장소에서는 고정 테이블, Keccak을 포함한 조회 테이블을 사용하여 매핑합니다. 테이블, RAM 테이블, 바이트코드, 트랜잭션, 블록 컨텍스트를 사용한 다음 Keccak 테이블을 제한하는 Keccak 회로와 같은 별도의 회로를 사용하여 이러한 조회 테이블을 제한합니다.
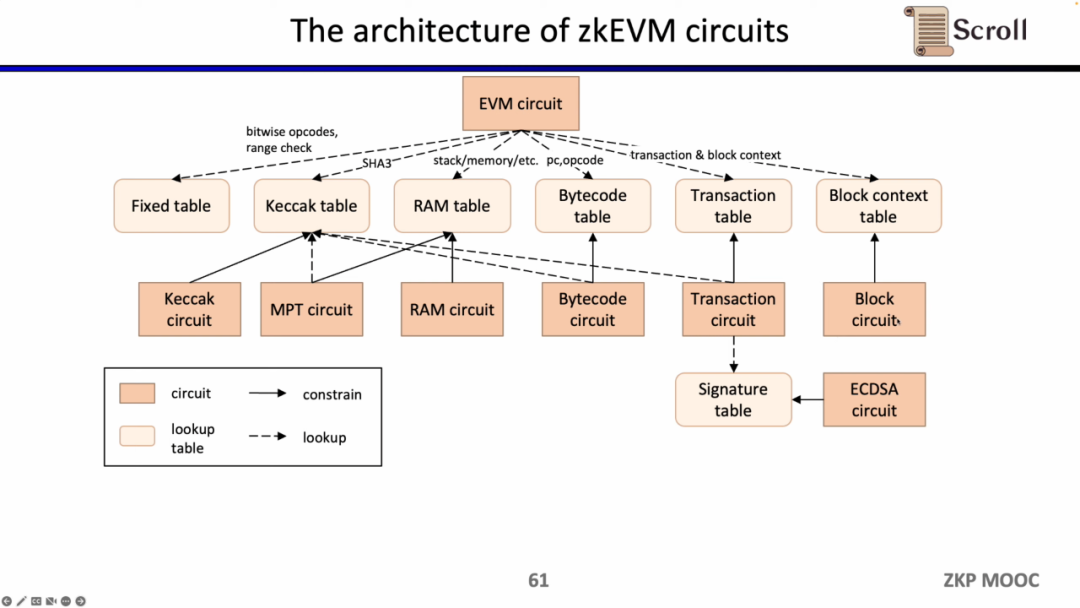
요약하자면, zkEVM의 전체 작업 흐름은 아래 그림에 나와 있습니다.
증명 시스템
위에서 언급한 EVM 회로, 메모리 회로, 저장 회로 등을 L1에서 직접 검증하는 것은 비용이 많이 들기 때문에 Scroll의 증명 시스템은 2계층 아키텍처를 채택합니다.
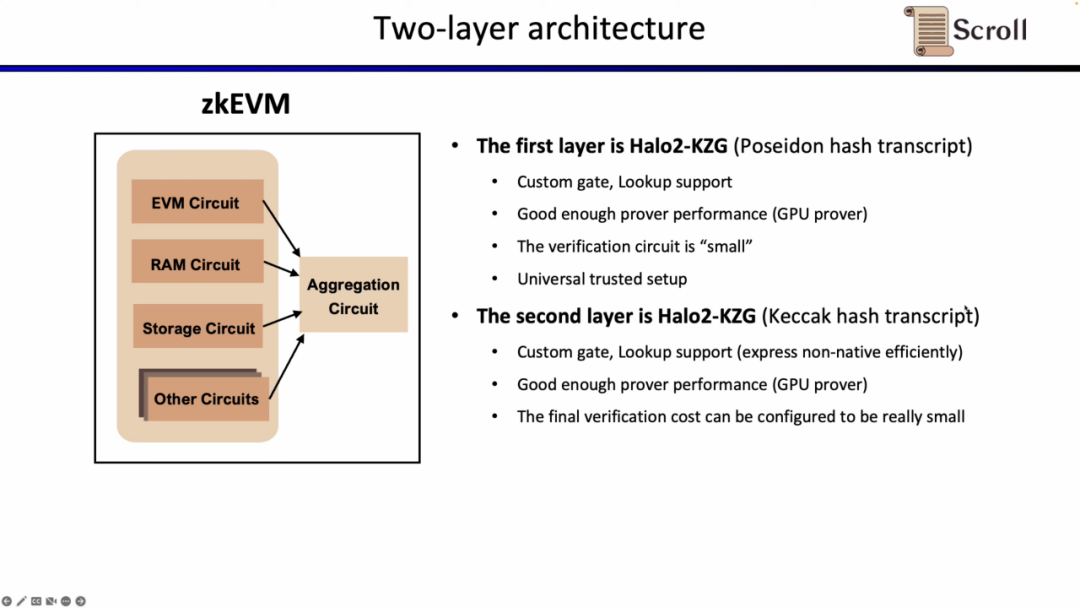
첫 번째 계층은 EVM 자체를 직접적으로 증명하는 역할을 담당하므로 증명을 생성하는 데 많은 양의 계산이 필요합니다. 따라서 1단계 증명 시스템은 맞춤형 게이트 및 조회 테이블을 지원하고, 하드웨어 가속에 적합하며, 낮은 피크 메모리에서 병렬로 계산을 생성하고, 신속하게 검증할 수 있는 작은 검증 회로를 가져야 합니다. 유망한 대안으로는 Plonky2, Starky, eSTARK 등이 있는데, 모두 기본적으로 프런트엔드에 Plonk를 사용하지만 백엔드에 FRI를 사용할 수도 있으며 위의 4가지 특성을 모두 충족합니다. 또 다른 유형의 대체 솔루션으로는 Zcash가 개발한 Halo2와 Halo2의 KZG 버전이 있습니다.
최근 FFT를 제거한 HyperPlonk와 같은 유망한 새로운 증명 시스템도 있으며, NOVA 증명 시스템은 더 작은 재귀 증명을 달성할 수 있습니다. 다만 연구에서는 R1CS만 지원하고 있는데, 앞으로 Plonkish를 지원하고 실무에 적용할 수 있다면 매우 실용적이고 효율적일 것입니다.
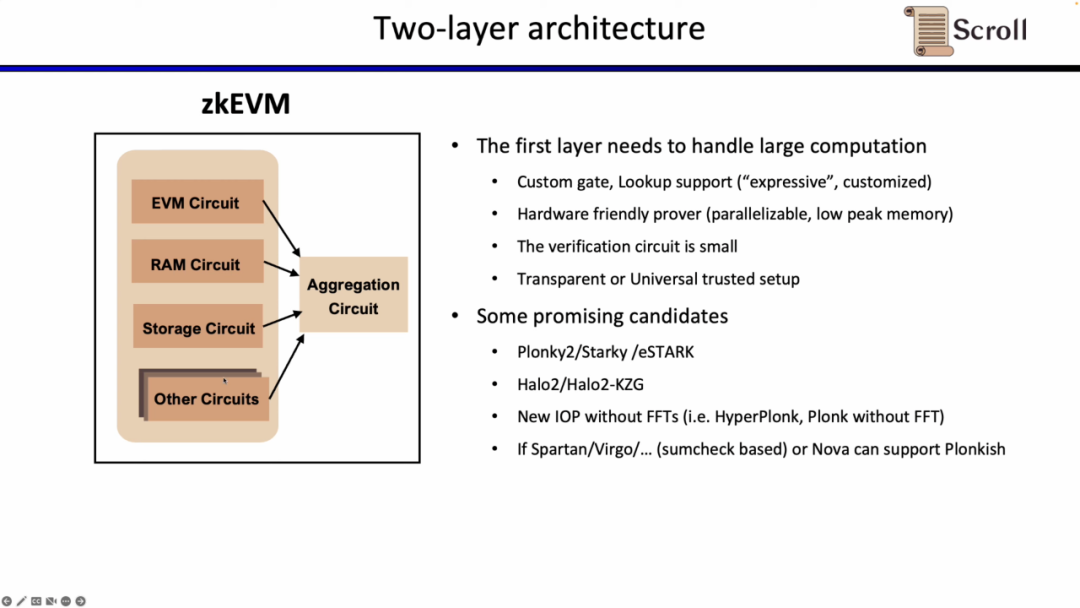
2단계 증명 시스템은 1단계 증명의 정확성을 증명하는 데 사용되며 EVM에서 효율적으로 검증되어야 합니다. 이상적으로는 하드웨어 가속에 친화적이고 투명하거나 보편적인 설정을 지원해야 합니다. 유망한 대안으로는 Groth16 및 열 없는 Plonkish 증명 시스템이 있습니다. Groth16은 현재 연구에서 여전히 매우 높은 증명 효율성을 대표하는 시스템이며, Plonkish 증명 시스템 역시 적은 수의 열로도 높은 증명 효율성을 달성할 수 있습니다.
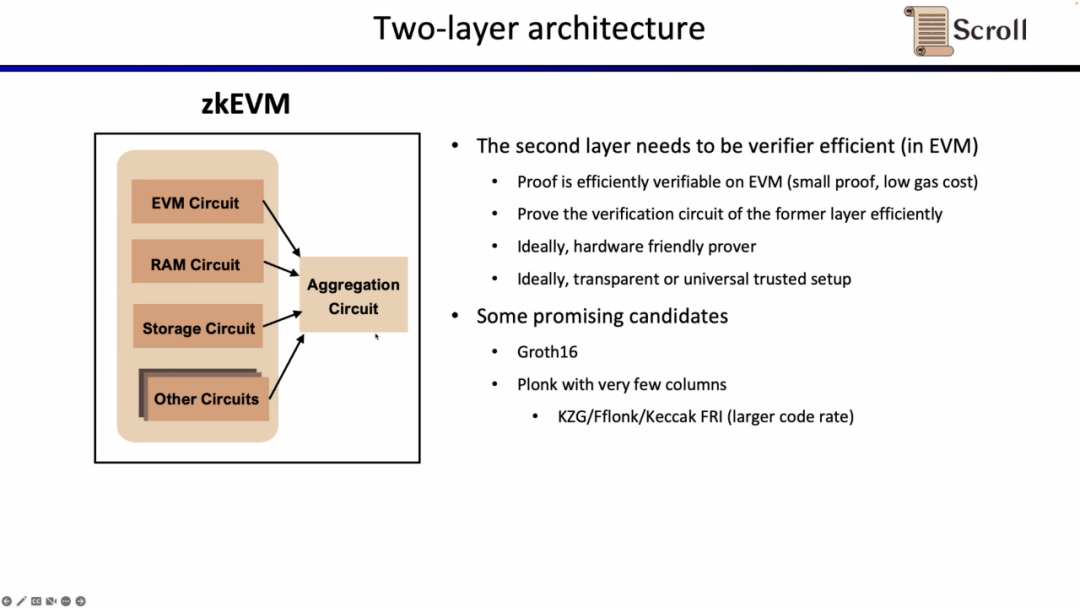
Scroll에서는 2계층 교정 시스템 모두에서 Halo2-KZG 교정 시스템을 사용합니다. Halo2-KZG는 맞춤형 게이트 및 조회 테이블을 지원할 수 있기 때문에 GPU 하드웨어 가속에서도 잘 작동하며 검증 회로의 크기가 작아서 빠르게 검증할 수 있습니다. 차이점은 첫 번째 레이어 증명 시스템에서는 포세이돈 해싱을 사용하여 증명 효율성을 더욱 향상시키는 반면, 두 번째 레이어 증명 시스템은 이더리움에서 직접 검증되기 때문에 여전히 Keccak 해싱을 사용한다는 점입니다. Scroll은 또한 2단계 증명 시스템에서 생성된 집계된 증명을 추가로 집계하기 위해 다층 증명 시스템의 가능성을 탐색하고 있습니다.
현재 구현에서 Scroll의 첫 번째 수준 증명 시스템 EVM 회로에는 116개의 열, 2496개의 사용자 정의 게이트, 50개의 조회 테이블이 있고 최고 차수는 9이며 1M Gas에서 2^18 라인이 필요합니다. 집계 회로에는 열 23개, 커스텀 게이트 1개, 룩업 테이블 7개만 있고 가장 높은 순서는 5입니다. EVM 회로, 메모리 회로 및 저장 회로를 집계하려면 2^25개의 행이 필요합니다.

Scroll은 GPU 하드웨어 가속에 대해서도 많은 연구와 최적화 작업을 해왔습니다.EVM 회로의 경우 최적화된 GPU 증명자는 30초만 소요되며 이는 CPU 증명자보다 9배 더 효율적입니다.집합 회로의 경우 최적화 후 GPU 증명자만 149초가 소요되며 이는 CPU보다 15배 더 효율적입니다. 현재 최적화 조건에서 1M Gas의 1단계 증명 시스템은 약 2분, 2단계 증명 시스템은 약 3분 정도 소요됩니다.

흥미로운 연구 질문

세 번째 부분에서 Zhang Ye는 프런트 엔드 산술 회로부터 증명자 구현에 이르기까지 Scroll의 zkEVM 구축 과정에서 흥미로운 연구 문제에 대해 이야기했습니다.
회로
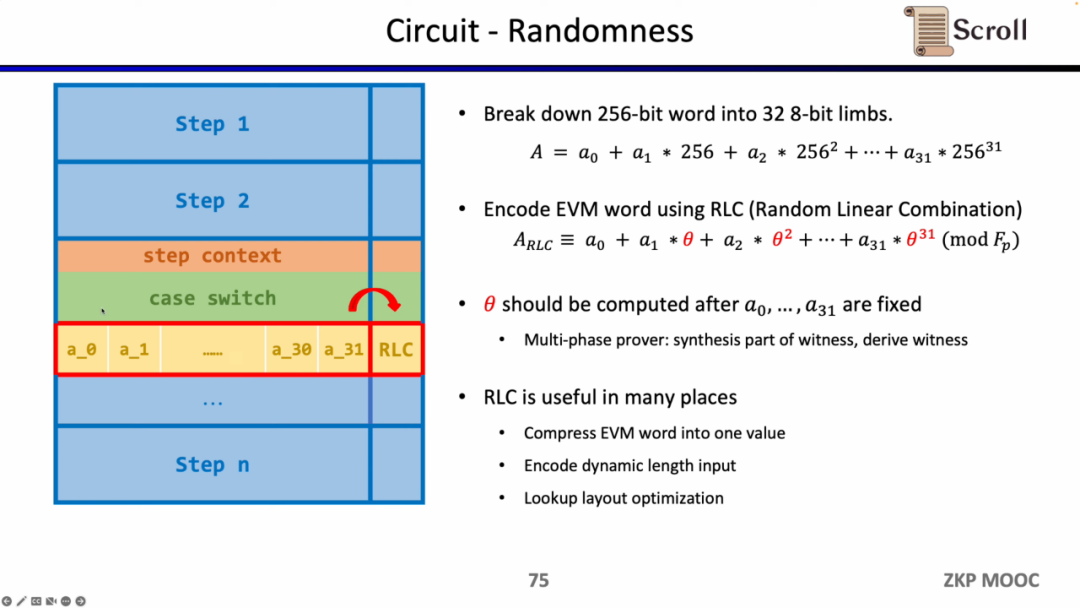
첫 번째는 회로의 무작위성입니다. EVM 필드는 256비트이므로 범위 증명을 보다 효율적으로 수행하려면 이를 32개의 8비트 필드로 분할해야 합니다. 그런 다음 RLC(Random Linear Combination) 방법을 사용하여 난수를 사용하여 32개의 필드를 1로 인코딩합니다. 원본 256비트 필드를 확인하려면 이 필드만 확인하면 됩니다. 그러나 문제는 변조되지 않도록 필드를 분할한 후 난수를 생성해야 한다는 것입니다. 따라서 Scroll 및 PSE 팀은 필드 분할 후 난수를 사용하여 RLC를 생성하도록 하는 다단계 증명 솔루션을 제안했으며 이 솔루션은 Challenge API에 캡슐화되어 있습니다. RLC는 zkEVM에 많은 응용 시나리오를 가지고 있으며 EVM 필드를 하나의 필드로 압축할 수 있을 뿐만 아니라 가변 길이 입력을 암호화하거나 조회 테이블의 레이아웃을 최적화할 수 있지만 여전히 해결해야 할 공개 문제가 많이 있습니다.
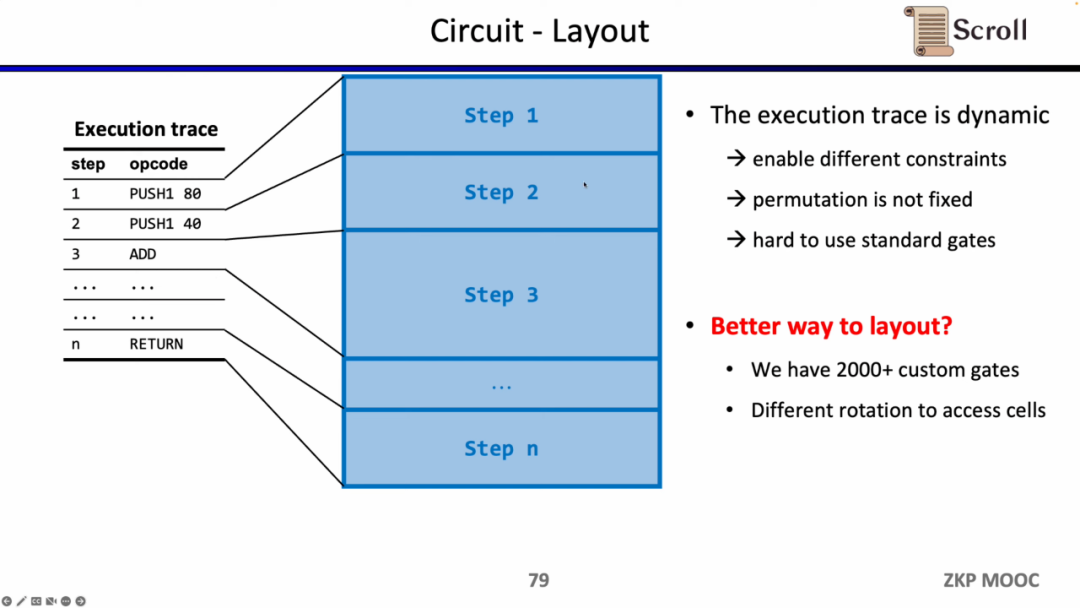
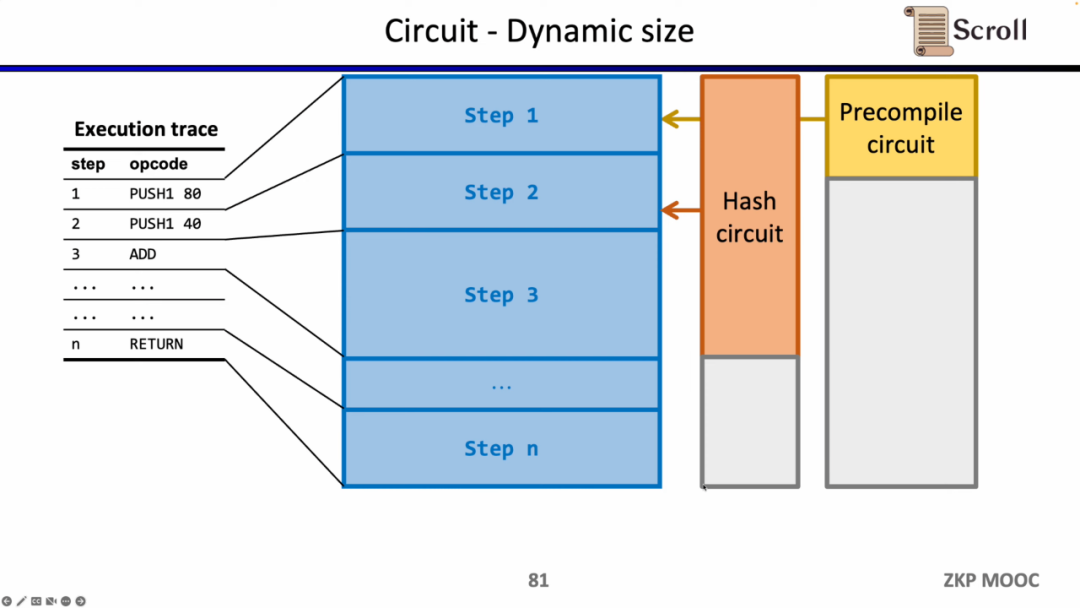
회로에 대한 두 번째 흥미로운 연구 질문은 회로 레이아웃입니다. Scroll 프론트 엔드가 Plonkish를 사용하는 이유는 EVM의 실행 추적이 동적으로 변경되고 다양한 제약 조건과 변경 등가 테스트를 지원할 수 있어야 하며 R1CS의 표준화된 게이트를 구현하려면 더 큰 회로 규모가 필요하기 때문입니다. 그러나 Scroll은 현재 동적으로 변화하는 실행 추적을 충족하기 위해 2,000개가 넘는 맞춤형 게이트를 사용하고 있으며 Opcode를 Micro Opcode로 분할하거나 동일한 테이블의 셀을 재사용하는 등 회로 레이아웃을 더욱 최적화하는 방법도 모색하고 있습니다.
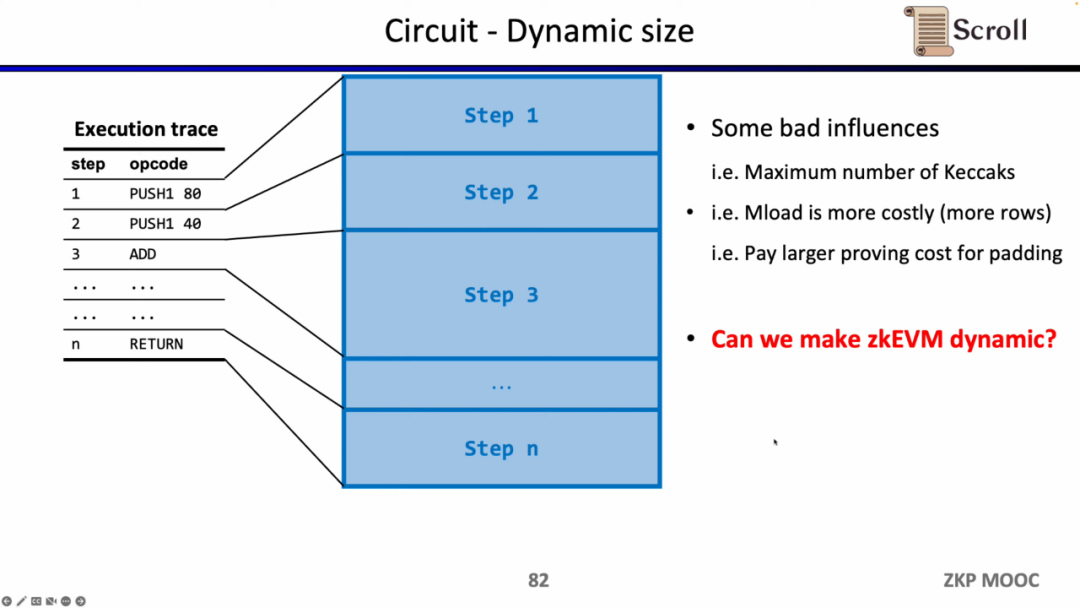
회로에 대한 세 번째 흥미로운 연구 질문은 동적 스케일링입니다. 다양한 opcode의 회로 규모는 다르지만 동적으로 변화하는 실행 추적을 충족하려면 각 단계의 opcode가 Keccak 해싱과 같은 최대 회로 규모를 충족해야 하므로 실제로 추가 오버헤드를 지불하게 됩니다. zkEVM이 동적으로 변화하는 실행 추적에 동적으로 적응할 수 있다고 가정하면 불필요한 오버헤드가 절약됩니다.
증명자
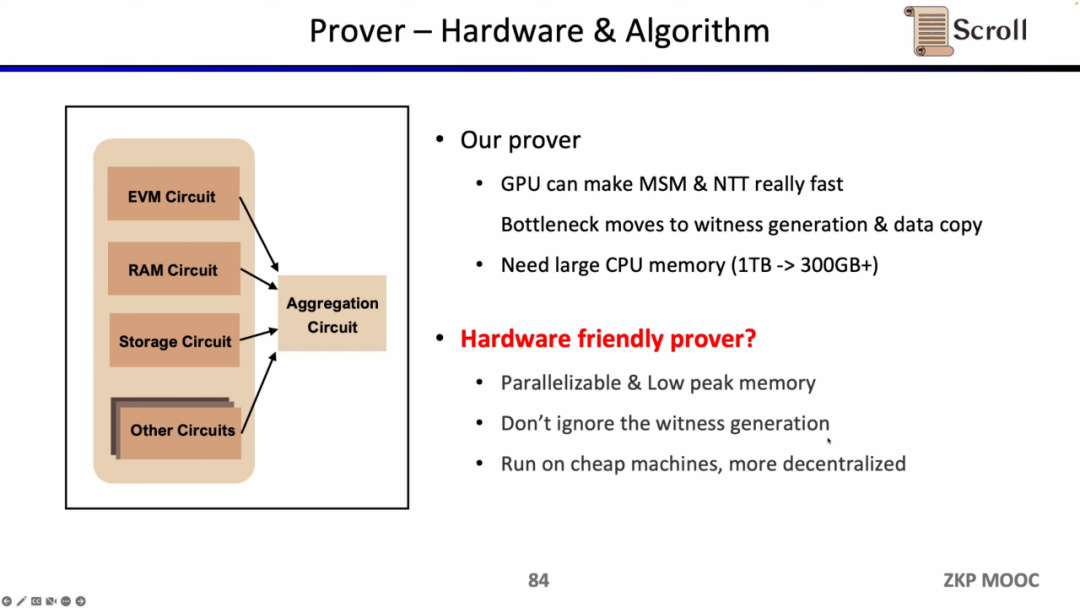
증명자 측면에서 Scroll은 GPU 가속 측면에서 MSM 및 NTT에 대해 많은 최적화를 수행했지만 이제 병목 현상은 증인 생성 및 데이터 복사로 이동했습니다. MSM과 NTT가 증명 시간의 80%를 차지한다고 가정하기 때문에 하드웨어 가속이 이 효율성을 몇 배로 향상시킬 수 있다고 하더라도 데이터를 생성하고 복사하는 원래의 20% 증명 시간은 새로운 병목 현상이 됩니다. 증명자의 또 다른 문제는 많은 메모리가 필요하므로 더 저렴하고 분산화된 하드웨어 솔루션을 모색해야 한다는 것입니다.
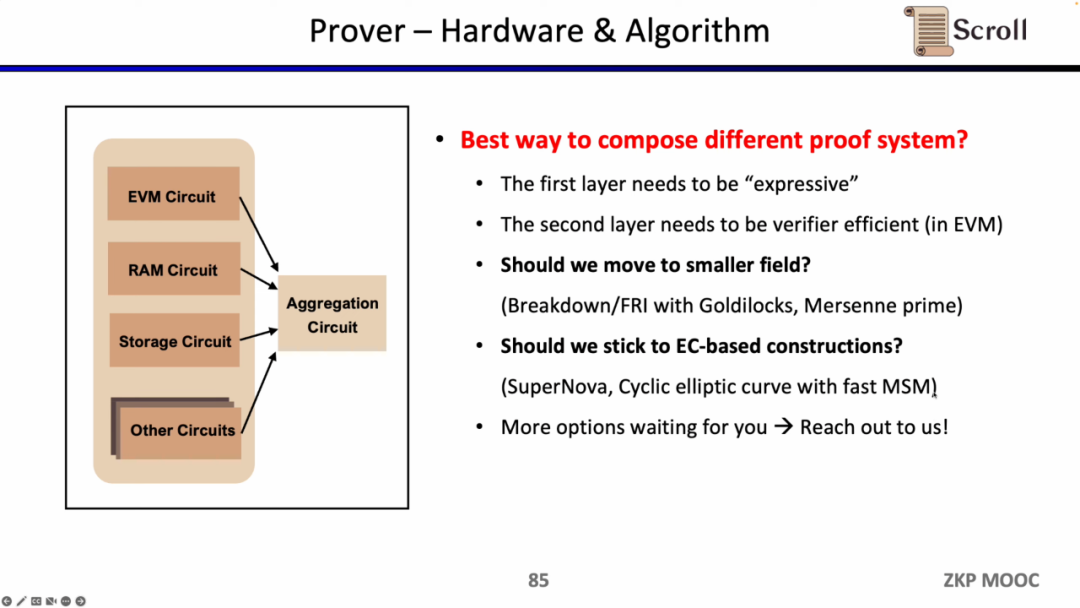
동시에 Scroll은 증명자의 효율성을 향상시키기 위해 하드웨어 가속 및 증명 알고리즘도 탐색하고 있습니다. 현재 64비트 Goldilocks 도메인, 32비트 Mersenne Prime 등을 사용하는 등 더 작은 도메인으로 전환하거나 타원 곡선(EC)을 기반으로 하는 새로운 증명 시스템을 고수하는 두 가지 주요 방향이 있습니다. . 물론 다른 경로도 가능하며, 아이디어가 있는 친구들은 Scroll에 직접 문의하는 것을 환영합니다.
안전
zkEVM을 구축할 때 보안이 가장 중요합니다. PSE와 Scroll이 공동으로 구축한 zkEVM은 약 34,000줄의 코드를 가지고 있는데, 소프트웨어 엔지니어링 관점에서 볼 때 이러한 복잡한 코드 기반이 오랫동안 취약점에서 자유로울 수는 없습니다. Scroll은 현재 업계 최고의 감사 회사를 포함하여 수많은 감사를 통해 zkEVM 코드 베이스를 검토하고 있습니다.


zkEVM을 사용하는 다른 애플리케이션

4부에서는 zkEVM을 사용하는 다른 애플리케이션을 살펴봅니다.
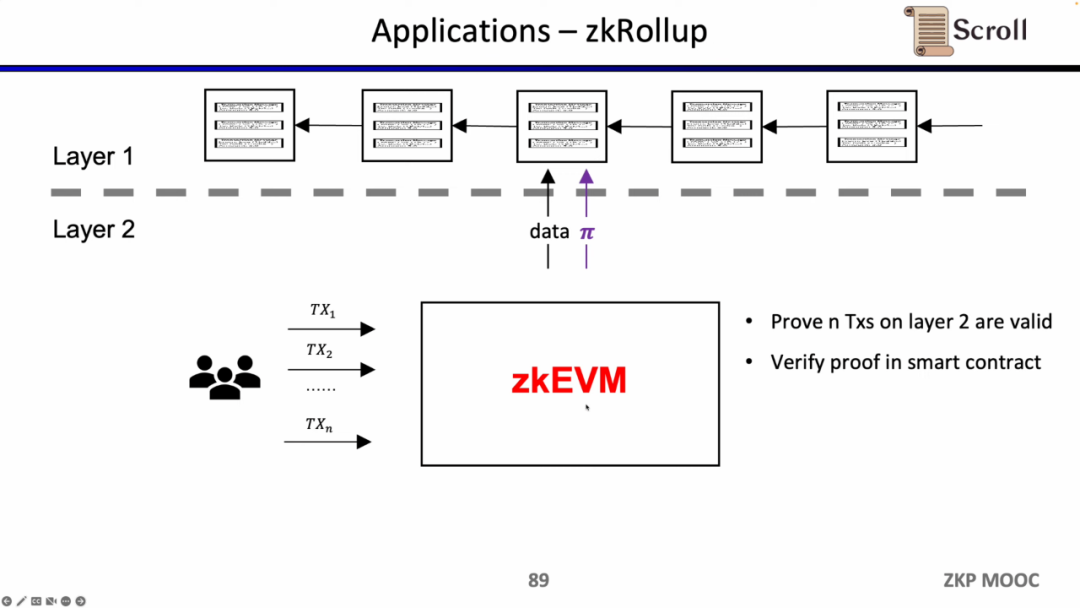
zkRollup 아키텍처에서는 L2의 n개 트랜잭션이 L1의 스마트 계약을 통해 유효한지 확인합니다.
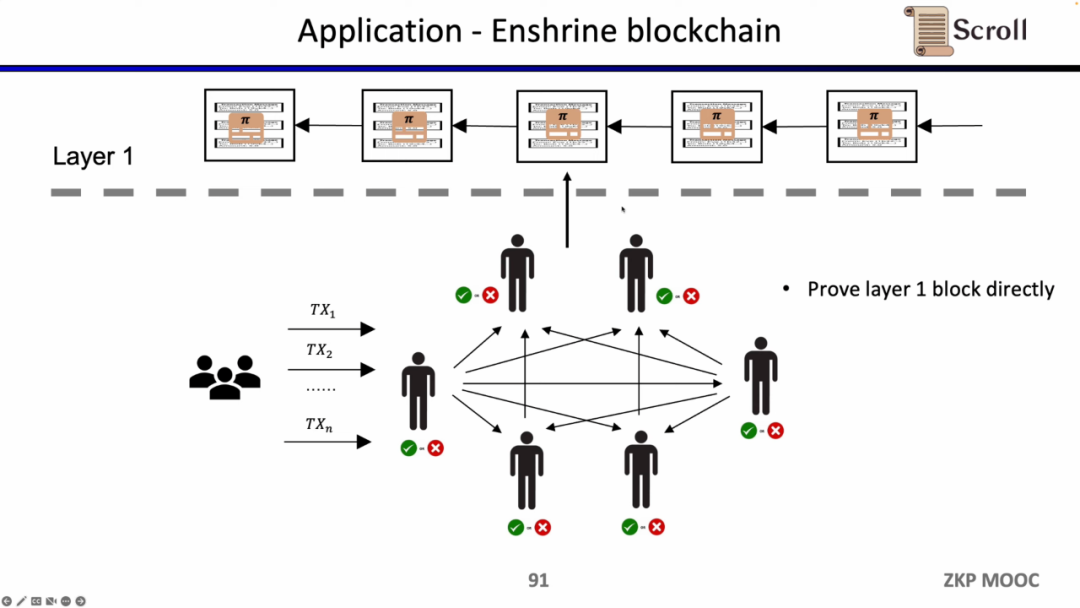
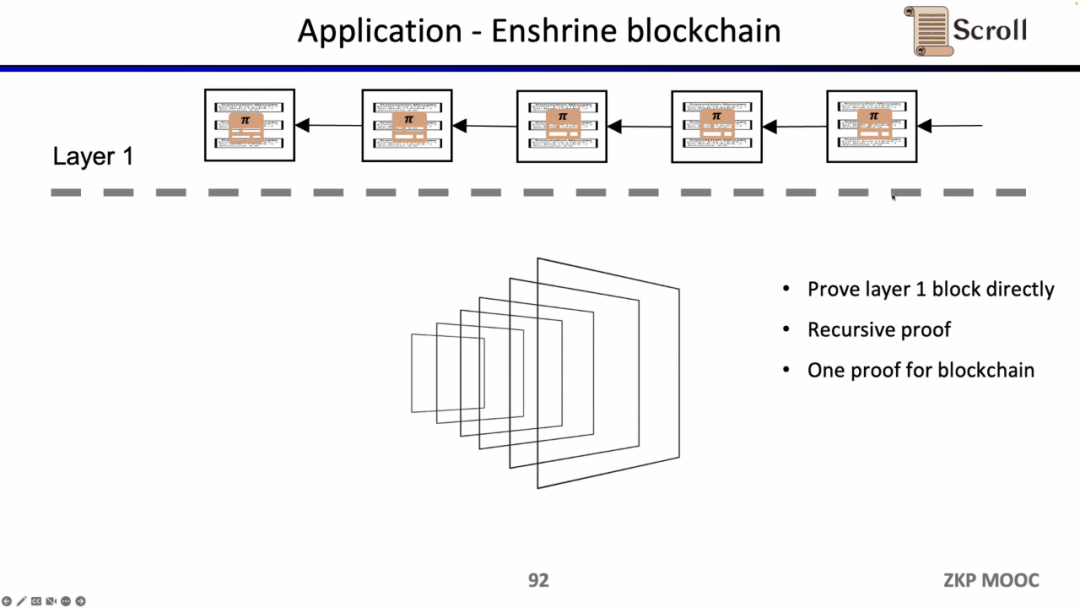
L1 블록을 직접 검증한다면 L1 노드는 트랜잭션을 반복적으로 실행할 필요가 없고 각 블록 인증서의 유효성만 검증하면 됩니다. 이러한 아키텍처 솔루션을 Enshrine Blockchain이라고 합니다. 현재 이더리움에서 직접 구현하는 것은 이더리움 블록 전체를 검증해야 하기 때문에 매우 어렵습니다. 여기에는 다수의 서명 검증이 포함되어 검증 시간이 길어지고 보안이 저하됩니다. 물론 Mina와 같이 단일 증명을 사용하여 전체 블록체인을 검증하기 위해 재귀 증명을 사용하는 다른 퍼블릭 체인도 이미 있습니다.
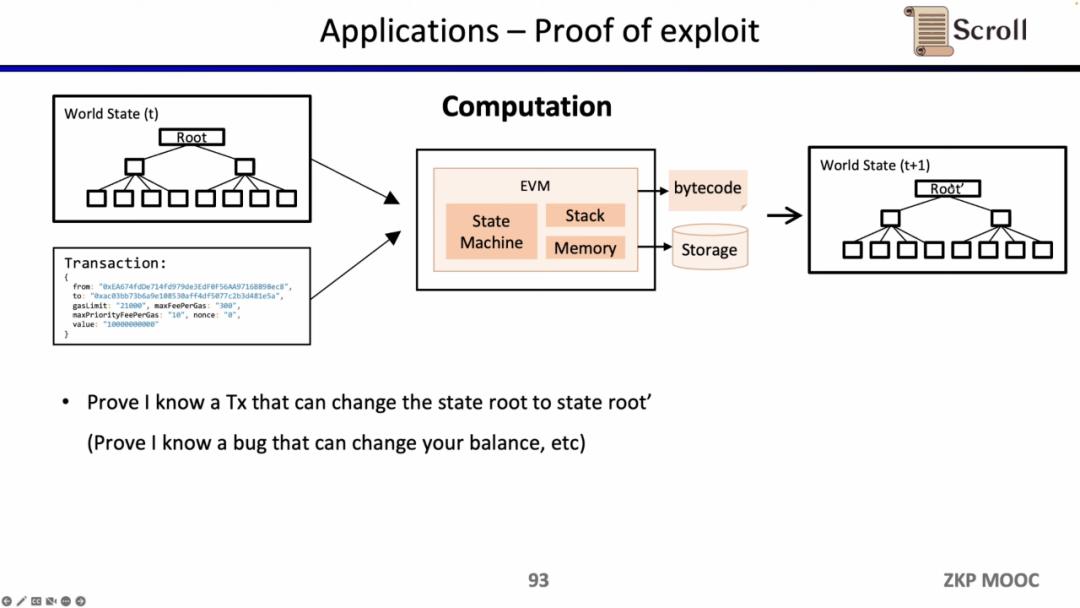
zkEVM은 상태 전환을 증명할 수 있기 때문에 화이트 해커가 특정 스마트 계약의 취약성을 알고 있음을 증명하고 프로젝트 당사자로부터 포상금을 추구하는 데 사용할 수도 있습니다.
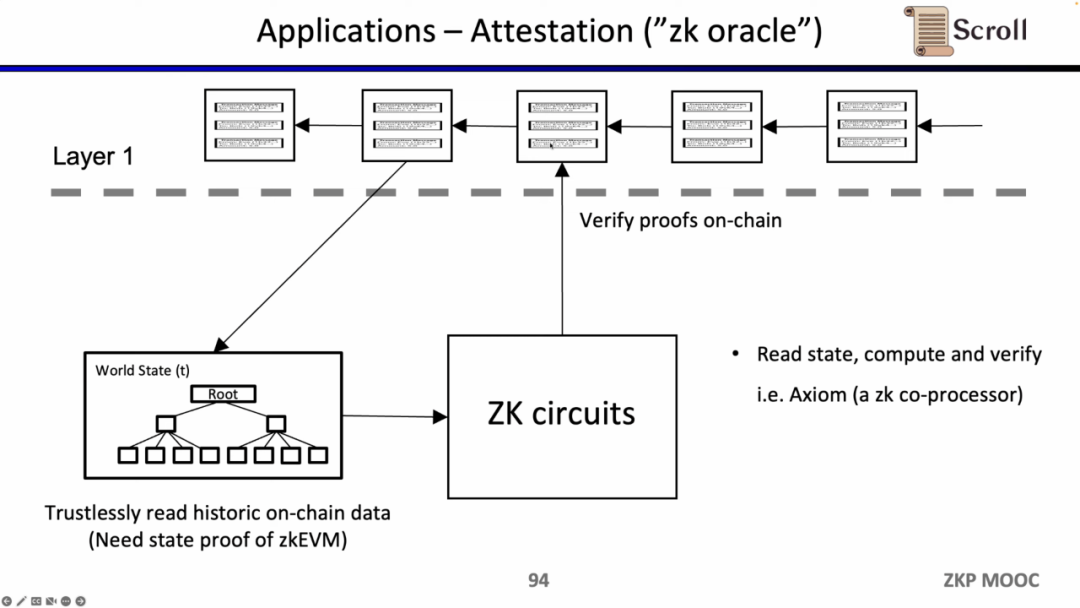
마지막 활용 사례는 과거 데이터에 대한 주장을 영지식 증명을 통해 증명해 오라클로 활용하는 것인데, 현재 Axiom이 이 분야의 제품을 만들고 있다. 최근 ETHBeijing Hackathon에서 GasLockR 팀은 이 기능을 활용하여 역사적인 가스 오버헤드를 증명했습니다.
마지막으로 Scroll은 매우 진보된 산술 회로와 증명 시스템을 사용하고 재귀를 증명하기 위해 하드웨어 가속을 통해 빠른 검증기를 구축하여 Ethereum용 zkRollup의 범용 확장 솔루션을 구축하고 있습니다. 현재 알파 테스트 네트워크는 온라인 상태이며 오랫동안 안정적으로 운영되고 있습니다.
물론 프로토콜 설계 및 메커니즘 설계, 영지식 엔지니어링 및 실제 효율성을 포함하여 아직 해결해야 할 몇 가지 흥미로운 문제가 있습니다. 누구나 Scroll에 참여하여 함께 구축할 수 있습니다!







