

Vài ngày sau khi OpenAI ra mắt SearchGPT, phiên bản mã nguồn mở cũng đã xuất hiện.
Đội ngũ MMLab Trung Quốc tại Hồng Kông, Phòng thí nghiệm AI Thượng Hải và Tencent vừa triển khai Trợ lý Tìm kiếm Tầm nhìn . Thiết kế mô hình rất đơn giản và có thể được sao chép chỉ với hai RTX3090 .

Vision Search Assistant (VSA) dựa trên mô hình ngôn ngữ hình ảnh (VLM) và tích hợp khéo léo khả năng tìm kiếm trên web trong đó, cho phép cập nhật kiến thức bên trong VLM theo thời gian thực, giúp nó trở nên linh hoạt và thông minh hơn.
Hiện tại, VSA đã được thử nghiệm trên các ảnh tổng quát, cho kết quả trực quan hóa và định lượng tốt. Tuy nhiên, các loại hình ảnh khác nhau có những đặc điểm riêng và các ứng dụng VSA cụ thể hơn có thể được xây dựng cho các loại hình ảnh khác nhau (chẳng hạn như bảng biểu, hình ảnh thuốc, v.v.).
Điều thú vị hơn nữa là tiềm năng của VSA không chỉ giới hạn ở việc xử lý hình ảnh. Có nhiều không gian khám phá hơn, chẳng hạn như video, mô hình 3D, âm thanh và các lĩnh vực khác. Chúng tôi mong muốn thúc đẩy nghiên cứu đa phương thức lên tầm cao mới.

Hãy để VLM xử lý những hình ảnh chưa nhìn thấy và những khái niệm mới
Sự xuất hiện của các mô hình ngôn ngữ lớn (LLM) cho phép con người sử dụng khả năng trả lời câu hỏi không cần trả lời mạnh mẽ của mô hình để tiếp thu những kiến thức chưa quen thuộc.
Trên cơ sở này, các công nghệ như Tạo thế hệ nâng cao truy xuất (RAG) cải thiện hơn nữa hiệu suất của LLM trong nhiệm vụ trả lời câu hỏi miền mở, chuyên sâu về kiến thức. Tuy nhiên, khi VLM đối diện những hình ảnh chưa được nhìn thấy và những khái niệm mới, họ thường không thể tận dụng tốt những kiến thức đa phương thức mới nhất từ Internet.
Các Tác nhân Web hiện tại chủ yếu dựa vào việc truy xuất các câu hỏi của người dùng và tóm tắt nội dung văn bản HTML được truy xuất trả về, do đó, chúng có những hạn chế rõ ràng khi xử lý nhiệm vụ liên quan đến hình ảnh hoặc nội dung trực quan khác, tức là thông tin hình ảnh bị bỏ qua hoặc không được xử lý đầy đủ. .
Để giải quyết vấn đề này, đội ngũ đã đề xuất Trợ lý Tìm kiếm Tầm nhìn. Vision Search Assistant dựa trên mô hình VLM và có thể trả lời các câu hỏi về những hình ảnh chưa được nhìn thấy hoặc các khái niệm mới. Nó hoạt động giống như con người đang tìm kiếm và giải quyết các vấn đề trên Internet, bao gồm:
- Hiểu truy vấn
- Quyết định những đối tượng nào trong ảnh cần được tập trung vào và suy đoán mối tương quan giữa các đối tượng
- Tạo đối tượng văn bản truy vấn theo đối tượng
- Phân tích nội dung được công cụ tìm kiếm trả về dựa trên văn bản truy vấn và mức độ liên quan suy đoán
- Xác định xem thông tin hình ảnh và văn bản thu được có đủ để tạo ra câu trả lời hay không hoặc liệu nó có nên lặp lại và cải thiện quy trình trên không
- Kết hợp kết quả tìm kiếm để trả lời câu hỏi của người dùng
mô tả nội dung trực quan
mô-đun mô tả nội dung trực quan được sử dụng để rút các mô tả ở cấp độ đối tượng và mối tương quan giữa các đối tượng trong ảnh. Quá trình này được hiển thị trong hình bên dưới.
Đầu tiên, một mô hình phát hiện miền mở được sử dụng để thu được các vùng hình ảnh đáng chú ý. Tiếp theo, đối với mỗi vùng được phát hiện, VLM được sử dụng để thu được mô tả văn bản cấp đối tượng.
Cuối cùng, để thể hiện nội dung hình ảnh một cách toàn diện hơn, VLM được sử dụng để tương quan hơn nữa với các khu vực hình ảnh khác nhau nhằm thu được mô tả chính xác hơn về các đối tượng khác nhau.

Cụ thể, hãy để hình ảnh đầu vào của người dùng và câu hỏi của người dùng. Có thể thu được vùng quan tâm thông qua mô hình phát hiện miền mở:
Sau đó sử dụng mô hình VLM được đào tạo trước để mô tả nội dung trực quan của khu vực này tương ứng:
Để liên kết thông tin ở các khu vực khác nhau và cải thiện độ chính xác của mô tả, khu vực này có thể được ghép với các mô tả của các khu vực khác và VLM có thể sửa mô tả của khu vực đó:
Tại thời điểm này, mô tả chính xác về khu vực thị giác có liên quan cao đến nó sẽ được lấy từ đầu vào của người dùng.
Tìm kiếm kiến thức web: "Chuỗi tìm kiếm"
Cốt lõi của tìm kiếm kiến thức Web là một thuật toán lặp được gọi là "Chuỗi tìm kiếm", nhằm mục đích thu được kiến thức Web toàn diện với các mô tả trực quan có liên quan. Quá trình này được hiển thị trong hình bên dưới.

LLM được sử dụng trong Vision Search Assistant để tạo các câu hỏi phụ liên quan đến câu trả lời. LLM này được gọi là "Tác nhân lập kế hoạch". Các trang được công cụ tìm kiếm trả về sẽ được phân tích, lựa chọn và tóm tắt bởi cùng một LLM, được gọi là "Tác nhân tìm kiếm". Bằng cách này, có thể thu được kiến thức web liên quan đến nội dung trực quan.
Cụ thể, vì việc tìm kiếm được thực hiện trên mô tả nội dung trực quan của từng vùng riêng biệt nên vùng được lấy làm ví dụ và chỉ số trên này bị bỏ qua. Trong mô-đun, mô hình LLM tương tự được sử dụng để xây dựng tác nhân ra quyết định (Tác nhân lập kế hoạch) và tác nhân tìm kiếm (Tác nhân tìm kiếm). Tác nhân ra quyết định kiểm soát quá trình của toàn bộ Chuỗi tìm kiếm và tác nhân tìm kiếm tương tác với công cụ tìm kiếm để lọc và tóm tắt thông tin trang web.
Lấy vòng lặp đầu tiên làm ví dụ, tác nhân ra quyết định chia vấn đề thành các vấn đề phụ tìm kiếm và giao chúng cho tác nhân tìm kiếm để xử lý. Tác nhân tìm kiếm sẽ phân phối từng trang cho công cụ tìm kiếm, dẫn đến một tập hợp các trang. Công cụ tìm kiếm sẽ đọc tóm tắt trang và chọn tập hợp các trang (subscript set) phù hợp nhất với câu hỏi, phương pháp sau:
Đối với các trang đã chọn này, tác nhân tìm kiếm sẽ đọc nội dung chi tiết và tóm tắt:
Cuối cùng, bản tóm tắt của tất cả các vấn đề phụ được gửi đến tác nhân ra quyết định và tác nhân ra quyết định tóm tắt và thu được kiến thức về Web sau vòng lặp đầu tiên:
Quá trình lặp lại ở trên được lặp lại lần hoặc khi tác nhân ra quyết định cho rằng kiến thức Web hiện tại đủ để trả lời câu hỏi ban đầu, Chuỗi tìm kiếm sẽ dừng lại và thu được kiến thức Web cuối cùng.
thế hệ hợp tác
Cuối cùng, dựa trên hình ảnh gốc, mô tả trực quan và kiến thức về Web, VLM được sử dụng để trả lời các câu hỏi của người dùng. Quá trình này được hiển thị trong hình bên dưới. Cụ thể đáp án cuối cùng là:

Kết quả thí nghiệm
So sánh trực quan phần Hỏi & Đáp mở
Hình bên dưới so sánh kết quả Hỏi & Đáp tập mở cho các sự kiện mới (hai hàng đầu tiên) và hình ảnh mới (hai hàng dưới cùng).
So sánh Vision Search Assistant với Qwen2-VL-72B và InternVL2-76B, có thể dễ dàng nhận thấy Vision Search Assistant rất giỏi trong việc tạo ra các kết quả mới hơn, chính xác hơn và chi tiết hơn.
Ví dụ: trong ví dụ đầu tiên, Vision Search Assistant tóm tắt tình hình của Tesla vào năm 2024, trong khi Qwen2-VL bị giới hạn thông tin vào năm 2023 và InternVL2 nói rõ rằng nó không thể cung cấp thông tin theo thời gian thực về công ty.

Đánh giá bộ câu hỏi và câu trả lời mở
Trong đánh giá câu hỏi và câu trả lời mở, tổng cộng 10 chuyên gia con người đã tiến hành đánh giá đánh giá so sánh trên 100 cặp văn bản-hình ảnh được thu thập từ tin tức từ ngày 15 tháng 7 đến ngày 25 tháng 9, bao gồm tất cả các lĩnh vực hình ảnh và sự kiện mới lạ.
Các chuyên gia về con người đánh giá ba khía cạnh chính là tính xác thực, mức độ phù hợp và khả năng hỗ trợ.
Như được hiển thị trong hình ảnh bên dưới, Vision Search Assistant hoạt động tốt hơn ở cả ba khía cạnh so với Perplexity.ai Pro và GPT-4-Web.

Tính thực tế: Vision Search Assistant đạt 68%, tốt hơn Perplexity.ai Pro (14%) và GPT-4-Web (18%). Khách hàng tiềm năng quan trọng này chứng tỏ rằng Trợ lý Tìm kiếm Tầm nhìn luôn đưa ra các câu trả lời chính xác hơn, dựa trên thực tế.
Mức độ liên quan: Với điểm liên quan là 80%, Trợ lý Tìm kiếm Tầm nhìn thể hiện lợi thế đáng kể trong việc cung cấp các câu trả lời có mức độ liên quan cao. Để so sánh, Perplexity.ai Pro và GPT-4-Web lần lượt đạt được 11% và 9%, cho thấy khoảng cách đáng kể trong việc duy trì thời gian tìm kiếm trên web.
Khả năng hỗ trợ: Vision Search Assistant cũng vượt trội hơn các mô hình khác trong việc cung cấp đầy đủ bằng chứng và biện minh cho các phản hồi của nó, với điểm khả năng hỗ trợ là 63%. Perplexity.ai Pro và GPT-4-Web xếp sau với số điểm lần lượt là 19% và 24%. Những kết quả này nêu bật hiệu suất vượt trội của Vision Search Assistant trong nhiệm vụ mở, đặc biệt là trong việc cung cấp các câu trả lời toàn diện, phù hợp và được hỗ trợ tốt, khiến nó trở thành một phương pháp hiệu quả để xử lý hình ảnh và sự kiện mới.
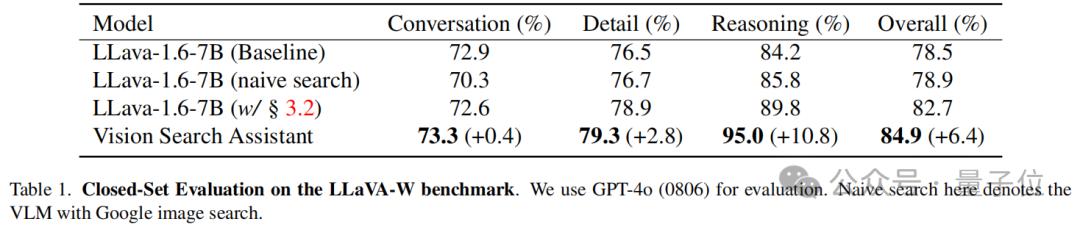
Đánh giá trả lời câu hỏi tập hợp đóng
Đánh giá tập hợp kín trên điểm chuẩn LLaVA W, trong đó gồm 60 câu hỏi bao gồm khả năng đối thoại, chi tiết và lý luận của VLM trong thực tế.
Đánh giá được thực hiện bằng mô hình GPT-4o(0806), sử dụng LLaVA-1.6-7B làm mô hình cơ sở, được đánh giá ở hai chế độ: chế độ tiêu chuẩn và chế độ "tìm kiếm ngây thơ" bằng thành phần tìm kiếm Google Image đơn giản.
Một phiên bản nâng cao của LLaVA-1.6-7B được trang bị mô-đun Chuỗi tìm kiếm cũng đã đánh giá .
Như được hiển thị trong bảng bên dưới, Vision Search Assistant cho thấy hiệu suất mạnh nhất trong tất cả các danh mục. Cụ thể, nó đạt được số điểm 73,3% ở hạng mục đối thoại, cải thiện nhẹ +0,4% so với mô hình LLaVA. Ở hạng mục chi tiết, Vision Search Assistant nổi bật với số điểm 79,3%, cao hơn +2,8% so với biến thể LLaVA hoạt động tốt nhất.
Về mặt suy luận, phương pháp VSA vượt trội hơn mô hình LLaVA hoạt động tốt nhất +10,8%. Điều này chứng tỏ rằng tích hợp nâng cao của tìm kiếm bằng hình ảnh và văn bản của Vision Search Assistant giúp nâng cao đáng kể khả năng suy luận của nó.
Hiệu suất tổng thể của Vision Search Assistant là 84,9%, cải thiện +6,4% so với mô hình cơ bản. Điều này cho thấy Vision Search Assistant hoạt động tốt trong cả nhiệm vụ đàm thoại và suy luận, mang lại lợi thế rõ ràng về khả năng trả lời câu hỏi trong thực tế.
Giấy: https://arxiv.org/abs/2410.21220 Trang chủ: https://cnzzx.github.io/VSA/Code: https://github.com/cnzzx/VSA
Bài viết này xuất phát từ tài khoản công khai WeChat "Qubit" , tác giả: đội ngũ VSA, 36 Krypton được phát hành với sự cho phép.





