Tác giả: Giang Tín Lăng,Nguồn điện cho AI

Nguồn ảnh: Được tạo bởi AI vô hạn
DeepSeek đã huấn luyện mô hình suy luận R1 của họ như thế nào?
Bài viết này chủ yếu dựa trên báo cáo kỹ thuật được công bố bởi DeepSeek, giải mã quá trình huấn luyện DeepSeek - R1; tập trung thảo luận bốn chiến lược xây dựng và nâng cao mô hình suy luận.
Bài gốc đến từ nhà nghiên cứu Sebastian Raschka, được đăng tại:
https://magazine.sebastianraschka.com/p/understanding-reasoning-llms
Bài viết sẽ tóm tắt phần cốt lõi về huấn luyện mô hình R1.
Trước tiên, dựa trên báo cáo kỹ thuật của DeepSeek, dưới đây là sơ đồ huấn luyện R1.
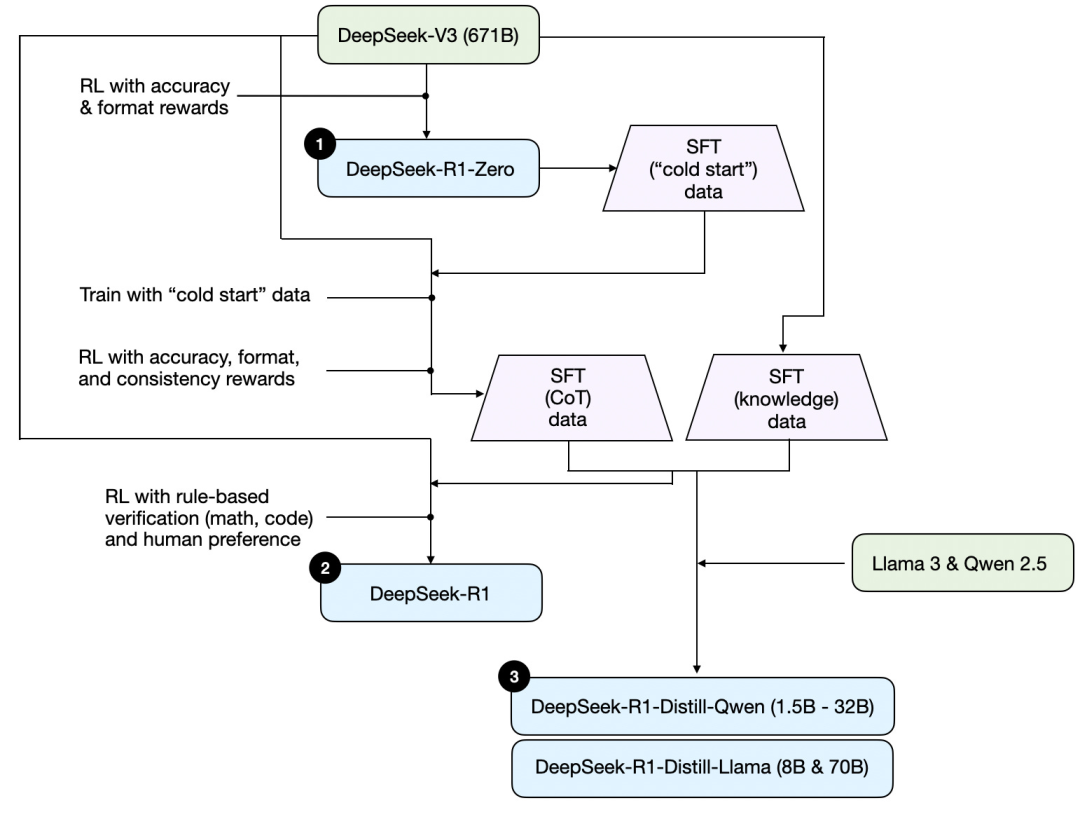
Hãy cùng tìm hiểu quy trình được minh họa trong hình trên, trong đó:
(1) DeepSeek - R1 - Zero: Mô hình này được xây dựng dựa trên mô hình cơ sở DeepSeek - V3 được công bố vào tháng 12 năm ngoái. Nó được huấn luyện bằng học tăng cường (RL) với hai cơ chế thưởng. Phương pháp này được gọi là huấn luyện "khởi động lạnh", vì nó không bao gồm bước vi chỉnh giám sát (SFT), thường là một phần của học tăng cường có phản hồi từ con người (RLHF).
(2) DeepSeek - R1: Đây là mô hình suy luận chủ lực của DeepSeek, được xây dựng dựa trên DeepSeek - R1 - Zero. Nhóm đã tối ưu hóa nó thông qua một giai đoạn vi chỉnh giám sát bổ sung và tiếp tục huấn luyện học tăng cường, cải thiện mô hình R1 - Zero "khởi động lạnh".
(3) DeepSeek - R1 - Distill: Nhóm DeepSeek đã sử dụng dữ liệu vi chỉnh giám sát được tạo ra trong các bước trước để tinh chỉnh các mô hình Qwen và Llama, nhằm tăng cường khả năng suy luận của chúng. Mặc dù không phải là quá trình chưng cất truyền thống, nhưng quy trình này liên quan đến việc sử dụng đầu ra của mô hình DeepSeek - R1 671B lớn hơn để huấn luyện các mô hình nhỏ hơn (Llama 8B và 70B, cũng như Qwen 1.5B - 30B).
Dưới đây sẽ giới thiệu bốn phương pháp chính để xây dựng và nâng cao mô hình suy luận.
1. Mở rộng tại thời điểm suy luận / Inference-time scaling
Một cách để nâng cao khả năng suy luận của LLM (mô hình ngôn ngữ lớn) là mở rộng tại thời điểm suy luận - tăng tài nguyên tính toán trong quá trình suy luận để cải thiện chất lượng đầu ra.
Ví dụ đơn giản, giống như con người có thể đưa ra câu trả lời tốt hơn cho các vấn đề phức tạp khi có thêm thời gian suy nghĩ, chúng ta cũng có thể áp dụng một số kỹ thuật để thúc đẩy LLM "suy nghĩ" sâu hơn khi tạo ra câu trả lời.
Một cách đơn giản để thực hiện mở rộng tại thời điểm suy luận là thông qua kỹ thuật gợi ý tinh vi / Prompt Engineering. Một ví dụ điển hình là gợi ý chuỗi suy nghĩ / CoT Prompting, tức là thêm các cụm từ như "suy nghĩ từng bước" vào gợi ý đầu vào. Điều này sẽ thúc đẩy mô hình tạo ra các bước trung gian của quá trình suy luận, thay vì trực tiếp đưa ra câu trả lời cuối cùng, thường mang lại kết quả chính xác hơn cho các vấn đề phức tạp. (Lưu ý rằng, đối với các câu hỏi dựa trên kiến thức đơn giản như "Thủ đô của Pháp là gì", chiến lược này sẽ không có ý nghĩa, đây cũng là một quy tắc kinh nghiệm hữu ích để xác định xem mô hình suy luận có phù hợp với truy vấn đầu vào hay không.)

Phương pháp chuỗi suy nghĩ (CoT) nêu trên có thể được coi là mở rộng tại thời điểm suy luận, vì nó tăng số lượng token đầu ra, do đó tăng chi phí suy luận.
Một cách khác để mở rộng tại thời điểm suy luận là sử dụng chiến lược bỏ phiếu và tìm kiếm. Một ví dụ đơn giản là bỏ phiếu đa số, tức là yêu cầu LLM tạo ra nhiều câu trả lời, sau đó chọn câu trả lời đúng đắn thông qua bỏ phiếu đa số. Tương tự, chúng ta cũng có thể sử dụng tìm kiếm chùm và các thuật toán tìm kiếm khác để tạo ra câu trả lời tối ưu hơn.
Tôi khuyến nghị xem xét bài báo "Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters".
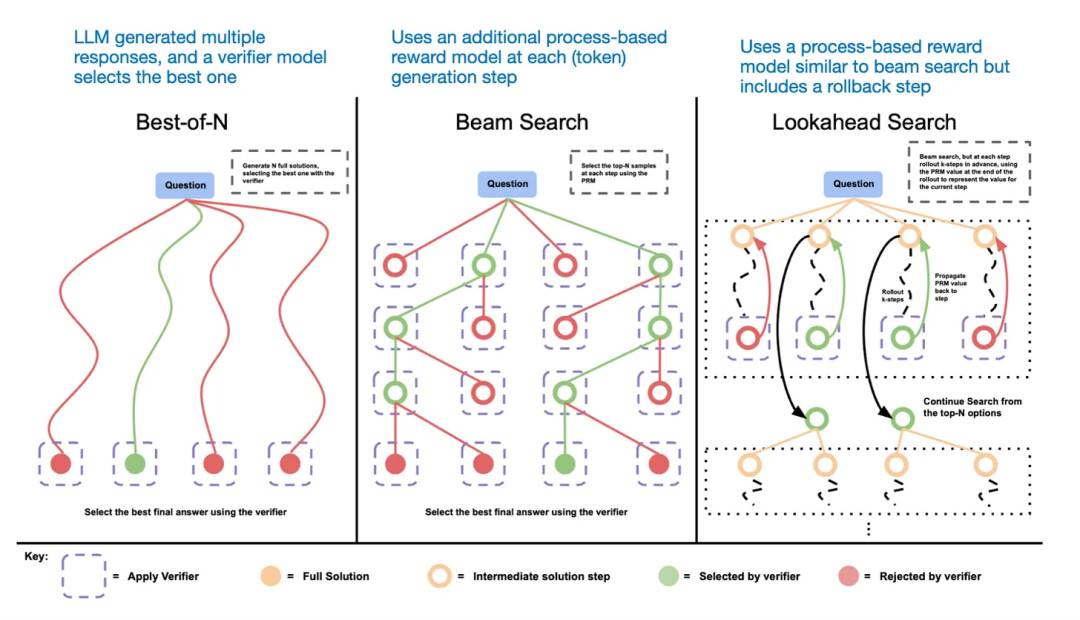
Các phương pháp dựa trên tìm kiếm khác nhau phụ thuộc vào mô hình dựa trên phần thưởng của quá trình để chọn câu trả lời tốt nhất.
Báo cáo kỹ thuật DeepSeek R1 cho biết mô hình của họ không sử dụng kỹ thuật mở rộng tại thời điểm suy luận. Tuy nhiên, kỹ thuật này thường được triển khai ở lớp ứng dụng trên LLM, vì vậy DeepSeek có thể đã áp dụng kỹ thuật này trong các ứng dụng của họ.
Tôi đoán rằng các mô hình o1 và o3 của OpenAI có thể sử dụng kỹ thuật mở rộng tại thời điểm suy luận, điều này có thể giải thích tại sao chúng có chi phí sử dụng tương đối cao hơn so với các mô hình như GPT-4o. Ngoài mở rộng tại thời điểm suy luận, o1 và o3 rất có thể được huấn luyện thông qua quy trình học tăng cường tương tự như DeepSeek R1.
2. Học tăng cường thuần túy / Pure RL
Một điểm đáng chú ý trong báo cáo DeepSeek R1 là họ phát hiện ra rằng khả năng suy luận có thể nảy sinh như một hành vi từ học tăng cường thuần túy. Hãy cùng tìm hiểu ý nghĩa của điều này.
Như đã đề cập trước đó, DeepSeek đã phát triển ba mô hình R1. Mô hình đầu tiên là DeepSeek - R1 - Zero, được xây dựng dựa trên mô hình cơ sở DeepSeek - V3. Khác với quy trình học tăng cường điển hình, thường có bước vi chỉnh giám sát (SFT) trước khi học tăng cường, DeepSeek - R1 - Zero được huấn luyện hoàn toàn bằng học tăng cường, không có bước vi chỉnh giám sát/SFT ban đầu, như minh họa trong hình dưới đây.
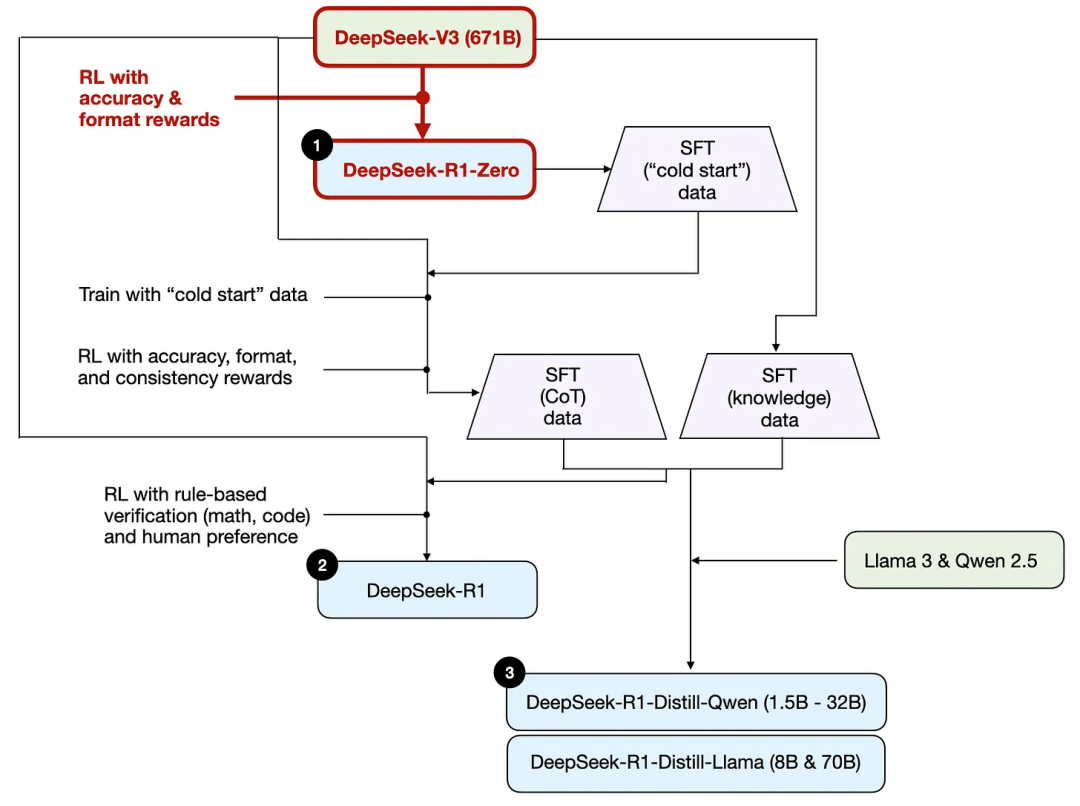
Mặc dù vậy, quá trình học tăng cường này tương tự như phương pháp học tăng cường có phản hồi từ con người (RLHF) thường được sử dụng để vi chỉnh sở thích cho LLM. Tuy nhiên, như đã nêu ở trên, điểm khác biệt then chốt của DeepSeek - R1 - Zero là họ bỏ qua giai đoạn vi chỉnh giám sát (SFT) để điều chỉnh hướng dẫn. Đây là lý do tại sao họ gọi đây là học tăng cường "thuần túy" / "Pure RL".
Về phần thưởng, họ không sử dụng mô hình thưởng dựa trên sở thích của con người, mà thay vào đó sử dụng hai loại thưởng: thưởng độ chính xác và thưởng định dạng.
Thưởng độ chính xác / accuracy reward sử dụng trình biên dịch LeetCode để xác minh câu trả lời lập trình và sử dụng hệ thống xác định để đánh giá câu trả lời toán học.
Thưởng định dạng / format reward dựa trên một bộ đánh giá LLM để đảm bảo câu trả lời tuân thủ định dạng mong muốn, chẳng hạn như đặt các bước suy luận trong các thẻ nhãn.
Điều đáng ngạc nhiên là, phương pháp này đủ để cho phép LLM phát triển các kỹ năng suy luận cơ bản. Các nhà nghiên cứu đã quan sát thấy một khoảnh khắc "aha", khi mô hình bắt đầu tạo ra dấu vết của quá trình suy luận trong các câu trả lời của nó, mặc dù không có huấn luyện cụ thể liên quan, như minh họa trong hình sau, trích từ báo cáo kỹ thuật R1.

Mặc dù R1 - Zero không phải là mô hình suy luận hàng đầu, nhưng như hình trên cho thấy, nó thực sự thể hiện khả năng suy luận thông qua việc tạo ra các bước "suy nghĩ" trung gian. Điều này chứng minh rằng sử dụng học tăng cường thuần túy để phát triển mô hình suy luận là khả thi, và DeepSeek là nhóm đầu tiên trình bày (hoặc ít nhất là công bố kết quả) về phương pháp này.
3. Vi chỉnh giám sát và học tăng cường (SFT + RL)
Tiếp theo, hãy xem xét quá trình phát triển mô hình suy luận chủ lực của DeepSeek, DeepSeek - R1, có thể được coi là sách giáo khoa về xây dựng mô hình suy luận. Mô hình này được xây dựng dựa trên DeepSeek - R1 - Zero, kết
Sau đó, 680.000 + 200.000 mẫu SFT này được sử dụng để tinh chỉnh hướng dẫn/instruction finetuning cho mô hình cơ bản DeepSeek - V3, sau đó thực hiện một vòng RL cuối cùng. Ở giai đoạn này, đối với các vấn đề toán học và lập trình, họ lại sử dụng phương pháp dựa trên quy tắc để xác định phần thưởng chính xác, trong khi đối với các loại vấn đề khác, họ sử dụng nhãn ưu tiên của con người. Tóm lại, điều này rất giống với học tập tăng cường dựa trên phản hồi của con người (RLHF) thông thường, chỉ là dữ liệu SFT chứa (nhiều hơn) các ví dụ về chuỗi suy nghĩ. Và ngoài phần thưởng dựa trên ưu tiên của con người, RL còn có phần thưởng có thể xác minh được.
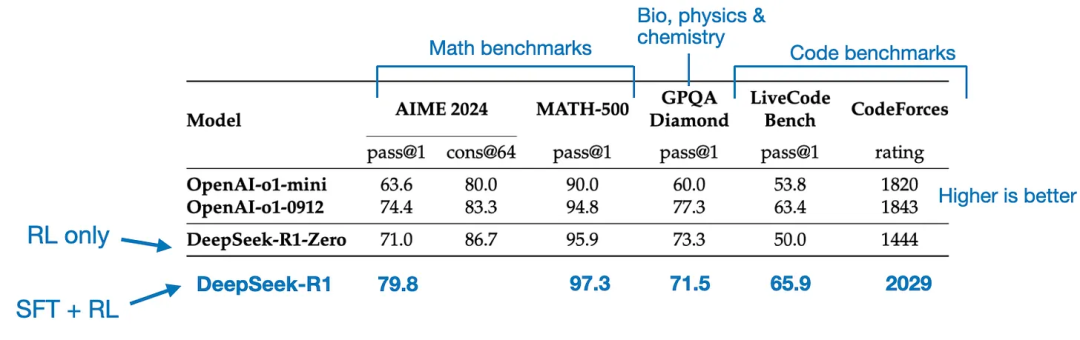
Mô hình cuối cùng DeepSeek - R1, do các giai đoạn SFT và RL bổ sung, có sự cải thiện đáng kể về hiệu suất so với DeepSeek - R1 - Zero, như bảng dưới đây cho thấy.
4. Tinh chỉnh giám sát thuần túy (SFT) và chưng cất
Cho đến nay, chúng tôi đã giới thiệu ba phương pháp then chốt để xây dựng và cải thiện các mô hình suy luận:
1/ Mở rộng khi suy luận, đây là một kỹ thuật có thể nâng cao khả năng suy luận mà không cần đào tạo lại hoặc sửa đổi mô hình cơ bản theo bất kỳ cách nào.
2/ Học tập tăng cường thuần túy (Pure RL), như được sử dụng trong DeepSeek - R1 - Zero, cho thấy suy luận có thể xuất hiện như một hành vi được học, mà không cần tinh chỉnh giám sát.
3/ Tinh chỉnh giám sát (SFT) + Học tập tăng cường (RL), từ đó tạo ra mô hình suy luận DeepSeek, DeepSeek - R1.
Còn lại - "chưng cất" mô hình. DeepSeek cũng đã phát hành các mô hình nhỏ hơn được đào tạo thông qua quá trình chưng cất mà họ gọi là. Trong bối cảnh LLM, chưng cất không nhất thiết tuân theo phương pháp chưng cất kiến thức cổ điển trong học sâu. Truyền thống, trong chưng cất kiến thức, một mô hình "học sinh" nhỏ hơn được đào tạo trên đầu ra logic của mô hình "giáo viên" lớn hơn và tập dữ liệu mục tiêu.
Tuy nhiên, ở đây, chưng cất có nghĩa là tinh chỉnh hướng dẫn/instruction finetuning các LLM nhỏ hơn, chẳng hạn như Llama 8B và 70B, cũng như Qwen 2.5B (0.5B - 32B), trên tập dữ liệu tinh chỉnh giám sát (SFT) được tạo ra bởi các LLM lớn hơn, chẳng hạn như DeepSeek - V3 và một điểm kiểm tra/checkpoint trung gian của DeepSeek - R1. Thực tế, tập dữ liệu tinh chỉnh giám sát/SFT được sử dụng cho quá trình chưng cất này là giống với tập dữ liệu được mô tả ở phần trước để đào tạo DeepSeek - R1.
Để làm rõ quá trình này, tôi đã nhấn mạnh phần chưng cất trong hình dưới đây.
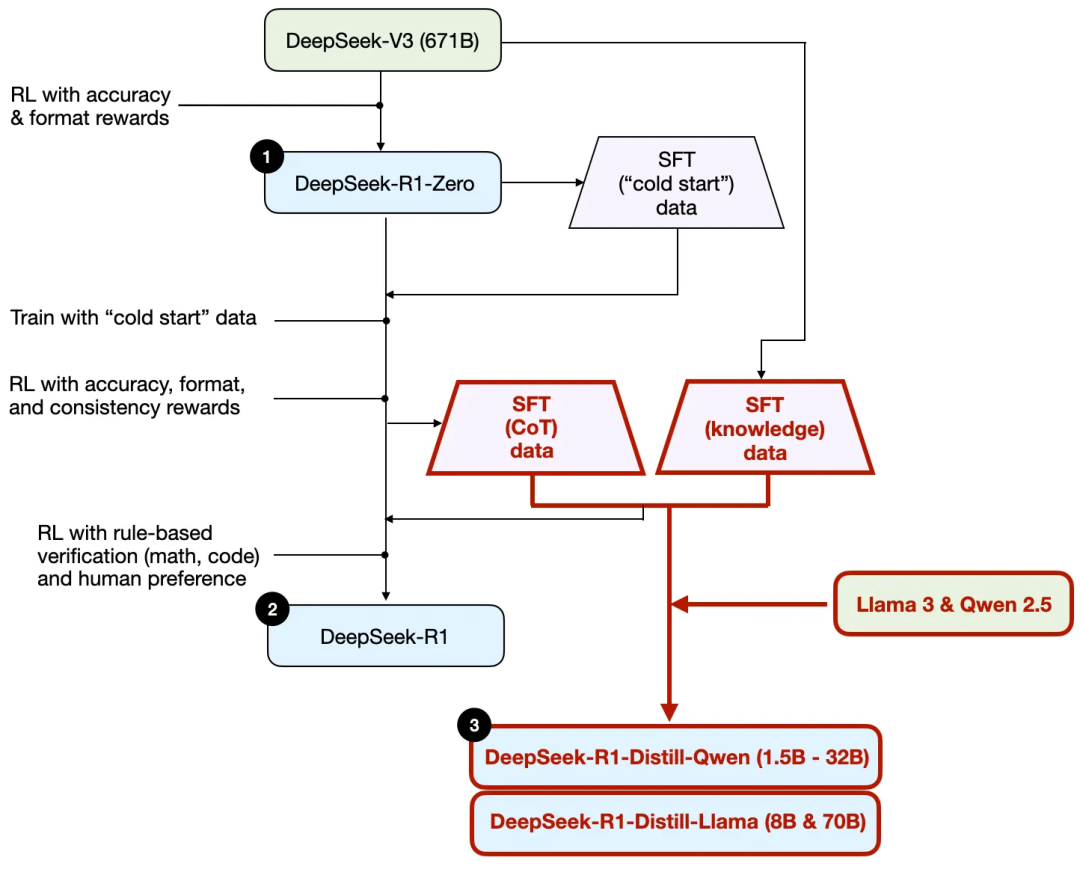
Tại sao họ lại phát triển những mô hình chưng cất này? Có hai lý do chính:
1/ Các mô hình nhỏ hơn hiệu quả hơn. Điều này có nghĩa là chúng có chi phí vận hành thấp hơn và có thể chạy trên phần cứng thấp cấp, đặc biệt hấp dẫn với nhiều nhà nghiên cứu và người yêu thích.
2/ Như một nghiên cứu trường hợp về tinh chỉnh giám sát (SFT) thuần túy. Những mô hình chưng cất này là một chuẩn so sánh thú vị, thể hiện mức độ mà các mô hình có thể đạt được chỉ bằng tinh chỉnh giám sát thuần túy, mà không có học tập tăng cường.
Bảng dưới đây so sánh hiệu suất của những mô hình chưng cất này với các mô hình phổ biến khác, cũng như DeepSeek - R1 - Zero và DeepSeek - R1.
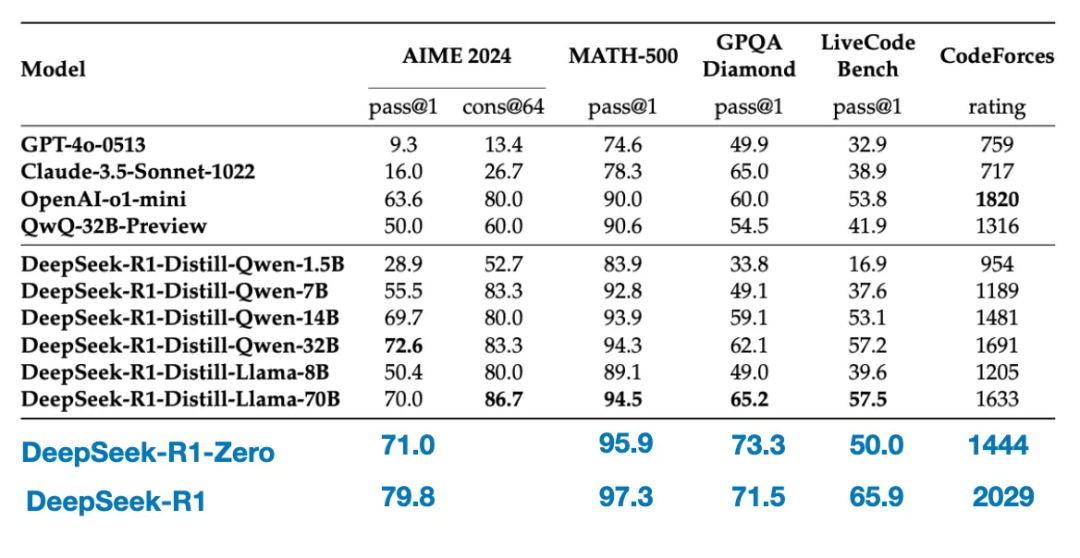
Như chúng ta thấy, mặc dù các mô hình chưng cất nhỏ hơn DeepSeek - R1 nhiều cấp độ, nhưng chúng rõ ràng mạnh hơn nhiều so với DeepSeek - R1 - Zero, mặc dù vẫn yếu hơn DeepSeek - R1. Cũng thú vị là những mô hình này cũng hoạt động khá tốt so với o1 - mini (nghi ngờ o1 - mini có thể là một phiên bản chưng cất tương tự của o1).
Một so sánh thú vị khác cũng đáng được đề cập. Nhóm DeepSeek đã kiểm tra xem liệu hành vi suy luận bùng nổ xuất hiện trong DeepSeek - R1 - Zero có thể xuất hiện trong các mô hình nhỏ hơn hay không. Để nghiên cứu điều này, họ đã trực tiếp áp dụng phương pháp học tập tăng cường thuần túy giống như trong DeepSeek - R1 - Zero cho Qwen - 32B.
Bảng dưới đây tóm tắt kết quả của thí nghiệm này, trong đó QwQ - 32B - Preview là mô hình suy luận tham chiếu dựa trên Qwen 2.5 32B do nhóm Qwen phát triển. So sánh này cung cấp thêm một số nhận xét về việc liệu học tập tăng cường thuần túy có thể gây ra khả năng suy luận trong các mô hình nhỏ hơn nhiều so với DeepSeek - R1 - Zero hay không.
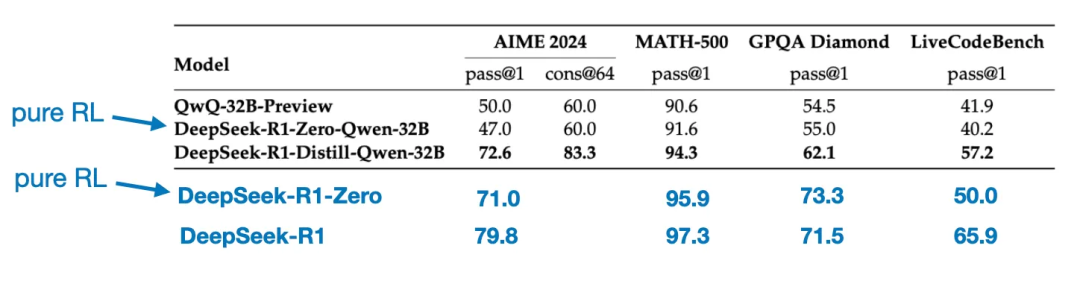
Thú vị là, kết quả cho thấy:ối với các mô hình nhỏ hơn, chưng cất hiệu quả hơn nhiều so với học tập tăng cường thuần túy. Điều này phù hợp với quan điểm rằng chỉ dựa vào học tập tăng cường có thể không đủ để gây ra khả năng suy luận mạnh mẽ trong các mô hình quy mô này, và khi xử lý các mô hình nhỏ, tinh chỉnh giám sát dựa trên dữ liệu suy luận chất lượng cao có thể là một chiến lược hiệu quả hơn.
Kết luận
Chúng tôi đã thảo luận bốn chiến lược khác nhau để xây dựng và nâng cao các mô hình suy luận:
Mở rộng khi suy luận: không cần đào tạo thêm, nhưng sẽ tăng chi phí suy luận. Chi phí triển khai quy mô lớn sẽ cao hơn khi số lượng người dùng hoặc truy vấn tăng lên. Tuy nhiên, đối với việc nâng cao hiệu suất của các mô hình mạnh hiện có, đây vẫn là một phương pháp đơn giản và hiệu quả. Tôi rất nghi ngờ rằng o1 đã sử dụng mở rộng khi suy luận, điều này cũng giải thích tại sao chi phí tạo ra mỗi token của o1 lại cao hơn so với DeepSeek - R1.
Học tập tăng cường thuần túy (Pure RL): Từ góc độ nghiên cứu, điều này rất thú vị vì nó cho phép chúng ta hiểu sâu hơn về quá trình suy luận xuất hiện như một hành vi nổi lên. Tuy nhiên, trong phát triển mô hình thực tế, kết hợp học tập tăng cường và tinh chỉnh giám sát (RL + SFT) là lựa chọn tốt hơn, vì cách tiếp cận này có thể xây dựng các mô hình suy luận mạnh hơn. Tôi cũng rất nghi ngờ rằng o1 cũng được đào tạo bằng RL + SFT. Cụ thể hơn, tôi tin rằng o1 bắt đầu từ một mô hình cơ bản yếu hơn và nhỏ hơn so với DeepSeek - R1, nhưng đã sử dụng RL + SFT và mở rộng khi suy luận để bù đắp khoảng cách.
Như đã nêu ở trên, RL + SFT là phương pháp then chốt để xây dựng các mô hình suy luận có hiệu suất cao. DeepSeek - R1 đã cho chúng ta thấy một bản mẫu xuất sắc để đạt được mục tiêu này.
Chưng cất: là một phương pháp rất hấp dẫn, đặc biệt phù hợp để tạo ra các mô hình nhỏ hơn và hiệu quả hơn. Tuy nhiên, hạn chế của nó là không thể thúc đẩy sự đổi mới hoặc tạo ra thế hệ mô hình suy luận tiếp theo. Ví dụ, chưng cất luôn phụ thuộc vào các mô hình mạnh hơn hiện có để tạo ra dữ liệu tinh chỉnh giám sát (SFT).
Tiếp theo, một hướng thú vị mà tôi mong đợi là kết hợp RL + SFT (phương pháp 3) với mở rộng khi suy luận (phương pháp 1). Rất có thể đây chính là những gì OpenAI đang làm với o1, chỉ là o1 có thể dựa trên một mô hình cơ bản yếu hơn so với DeepSeek - R1, điều này cũng giải thích tại sao DeepSeek - R1 lại có hiệu suất suy luận vượt trội và chi phí tương đối thấp.