

PPPT: Chiến đấu với Gossipsub Overhead bằng Chuyển đổi Giai đoạn Đẩy-Kéo
Tác giả: @cskiraly
Lưu ý: phiên bản đầu tiên của PPPT và các thuật toán được thảo luận ở đây đã được giới thiệu vào tháng 5 năm 2024 trong bài đăng FullDAS của chúng tôi. Phiên bản có phép đo cũng đã được trình bày và lưu hành dưới dạng slide vào tháng 1 năm 2025.
Gần đây, một số nhóm nghiên cứu đã bắt đầu làm việc về các chủ đề tương tự, trong khi chia sẻ ý tưởng trong nhiều diễn đàn thảo luận. Một trong những công trình tuyệt vời như vậy vừa được xuất bản dưới tên “GossipSub v2.0”. Nhóm ProbeLab cũng tham gia vào các nỗ lực chuẩn hóa liên quan. Chúng tôi không cung cấp so sánh trực tiếp giữa các phương pháp này trong bài đăng của mình, mà để lại để thảo luận thêm (ví dụ như trong các bình luận bên dưới).
Trong bài đăng trước, chúng tôi đã giới thiệu về Xuất bản hàng loạt , cho thấy những cải tiến đáng kể về độ trễ trong quá trình phân tán DAS, giải quyết tình trạng tắc nghẽn băng thông tại nhà xuất bản .
Ngay cả khi triển khai Batch Publishing tại nguồn, GossipSub vẫn đi kèm với chi phí băng thông lớn trong quá trình phân phối lại p2p do trùng lặp. Trong bài đăng này, chúng tôi giải quyết mối quan tâm này, chỉ ra các kỹ thuật để giảm hoặc thậm chí loại bỏ chi phí này.
Tất nhiên là không có bữa trưa miễn phí. Các kỹ thuật được giới thiệu ở đây đi kèm với sự thỏa hiệp, mà chúng tôi cũng sẽ trình bày chi tiết.
GossipSub Overhead
GossipSub được giới thiệu là “giao thức pubsub mục đích chung với các yếu tố khuếch đại vừa phải và các đặc tính mở rộng tốt” . Mặc dù hiệu quả băng thông của nó tốt hơn nhiều so với FloodSub ngây thơ, nhưng nó vẫn có chi phí băng thông đáng kể, gây lo ngại cho một số trường hợp sử dụng Ethereum.
GossipSub hoạt động dựa trên hai kỹ thuật chính mà chúng tôi gọi là đẩy và kéo trong bài viết này.
Đối với bất kỳ chủ đề nào, GossipSub sẽ xây dựng một lưới ngẫu nhiên có mức độ xấp xỉ D D và chủ động ĐẨY các thông điệp dọc theo lưới này.
Nó cũng phân phối siêu dữ liệu “HAVE” dọc theo biểu đồ lân cận lớn hơn (đây là phần tin đồn của GossipSub sử dụng cái gọi là tin nhắn IHAVE) và khôi phục các tin nhắn bị mất bằng cách KÉO dựa trên thông tin này.
Trong phiên bản cơ sở của GossipSub, PUSH được sử dụng để truyền bá nhanh, trong khi PULL chỉ được sử dụng để khôi phục tổn thất . Một nút nhận được tin nhắn từ một đối tác sẽ xếp hàng để gửi đến tất cả D-1 D − 1 trong số các đối tác lưới của nó ( D-1 D − 1 , vì nó không gửi lại cho đối tác mà nó nhận được). Đây là hành vi khi nhận lần đầu. Các lần nhận khác được coi là trùng lặp và dễ dàng được lọc ra. Câu hỏi mà chúng tôi cố gắng trả lời ở đây là:
Chúng ta có bao nhiêu bản sao và chúng ta có thể làm gì để giảm số lượng này mà không (hoặc chỉ ảnh hưởng ít) đến hiệu suất?
Số lượng bản sao so với số lượng bản sao
Đôi khi, lý luận về bản sao dễ hơn là bản sao. Nếu một nút nhận được C C bản sao của một thông điệp, chỉ có bản sao đầu tiên là hữu ích, trong khi C-1 C − 1 trong số này là bản sao.
Số lượng bản sao đã gửi
Một cách tầm thường, mỗi nút trong số N nút đăng ký chủ đề sẽ có một “lần tiếp nhận đầu tiên”, sau đó nó gửi D-1 D − 1 bản sao, vì vậy chúng ta sẽ có N * (D-1) N ∗ ( D − 1 ) bản sao được gửi trong toàn bộ hệ thống. Trong số tất cả những bản sao này, chỉ có N-1 N − 1 là hữu ích, những bản sao khác phải là bản sao.
Số lượng bản sao đã nhận
Số lượng bản sao trung bình mà một nút nhận được cũng sẽ giống nhau: D-1 D − 1 , đơn giản là vì khi cộng số lượng tin nhắn được gửi và nhận bởi tất cả các nút, chúng ta sẽ nhận được cùng một số. Tuy nhiên, D-1 D − 1 chỉ là giá trị trung bình. Số lượng bản sao nhận được có thể thay đổi rất nhiều từ nút này sang nút khác . Trên thực tế, nó nằm trong khoảng từ 1 1 đến D D (trên thực tế, bậc của nút có thể hơi lệch so với D D , do đó, số lượng bản sao nhận được cũng có thể lớn hơn một Bit ).
Những nút may mắn nhận được ít bản sao là ai?
Trực giác rất đơn giản: khi tin nhắn được gửi đi trước tiên bởi nguồn, các nút D D sẽ nhận được nó. Đây là các nút nhận được nó trong lần nhảy thứ nhất . Do cấu trúc ngẫu nhiên của lưới, nên khả năng chúng là hàng xóm lưới khá thấp. Khả năng hai trong số các nút nhảy thứ nhất gửi đến cùng một nút cũng thấp. Vì vậy, khi chúng gửi đến tất cả các hàng xóm của chúng (trừ nút quay lại nguồn), tất cả các nút nhảy thứ 2 sẽ nhận được bản sao đầu tiên của chúng và không gửi lại. Do đó, các nút nhảy thứ 1 của chúng ta sẽ hầu như không nhận được bản sao nào. Chúng ta có nhiều nút nhảy thứ 2 hơn các nút nhảy thứ nhất, một số (nhưng ít) trong số này sẽ được kết nối với nhau và một số hàng xóm của chúng (lần nhảy thứ 3) cũng sẽ là chung. ETC.
Gần cuối quá trình khuếch tán, sau nhiều lần nhảy , tình hình rất khác. Một nút đầu tiên nhận được thông điệp sau ví dụ 5 lần nhảy vẫn gửi nó đến D-1 D − 1 nút khác, nhưng khả năng những nút lân cận này là những nút đã nhận được thông điệp, tức là thông điệp bị trùng lặp, khá cao.
Số lượng hop so với số lượng trùng lặp nhận được
Mặc dù bộ đếm hop không phải là một phần của cấu trúc tin nhắn GossipSub chuẩn, chúng tôi đã sửa đổi mã nim-libp2p để bao gồm một bộ đếm hop, do đó chúng tôi có thể dễ dàng thu thập thông tin về sự phân phối các bản sao nhận được theo số hop-count. Chính xác hơn, chúng tôi sử dụng bộ đếm hop của bản sao đầu tiên được nhận, đây là một loại khoảng cách đồ thị từ nguồn. Một nút cũng nhận được các bản sao khác sau đó, rất có thể với số hop-count lớn hơn (mặc dù cũng có thể nhỏ hơn do độ trễ LINK (Chainlink) khác nhau). Để đơn giản ở đây, chúng tôi sử dụng bộ đếm hop của lần tiếp nhận đầu tiên, không phải đường dẫn ngắn nhất.
Xin lưu ý rằng bộ đếm hoa bia này chỉ dùng cho mục đích đo lường trong thí nghiệm của chúng tôi, không phải để sử dụng ngoài tự nhiên (xem phần về vấn đề quyền riêng tư sau).
Hình bên dưới hiển thị sự phân bố số lượng bản sao tin nhắn nhận được, theo khoảng cách từ nút đến nguồn ( firsthops : giá trị bộ đếm bước nhảy đầu tiên gặp phải).
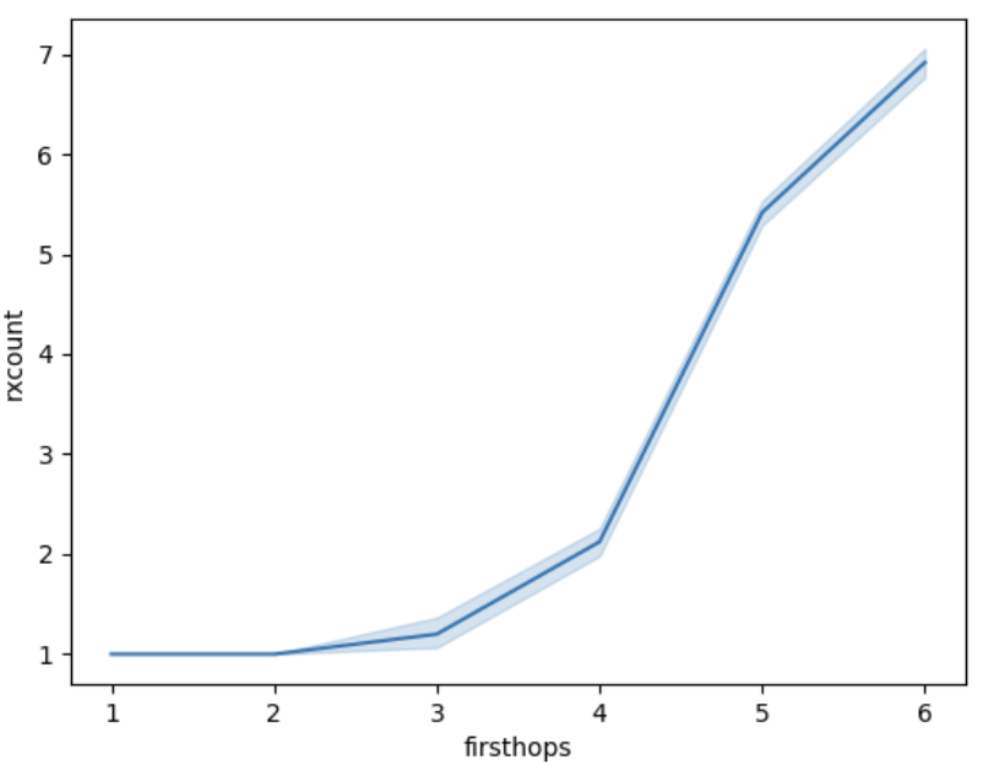
Hình 1: Số lượng tin nhắn được tiếp nhận (1 + bản sao) trên mỗi đối tác, theo khoảng cách từ đối tác đến nguồn tin nhắn.
Như chúng ta có thể thấy, một nút nhận được thông điệp càng muộn (số lần nhảy đầu tiên càng lớn) thì càng có nhiều bản sao sau lần tiếp nhận đầu tiên này. Nếu chúng ta thêm vào đó thực tế là số lượng nút cũng tăng theo cấp số nhân theo số lần nhảy đầu tiên , thì rõ ràng là để loại bỏ các bản sao, chúng ta nên loại bỏ chúng khỏi các giai đoạn sau của quá trình khuếch tán. Trong phần sau, chúng ta sẽ so sánh một số cách để cố gắng đạt được điều này, nhưng trước khi đi sâu vào đó, chúng ta sẽ chỉ ra trường hợp cực đoan, khi không có bản sao nào xảy ra.
Chế độ kéo
Cách đơn giản nhất để loại bỏ các bản sao là chỉ sử dụng chế độ PULL. Khi nhận được tin nhắn, một nút sẽ gửi tin nhắn D-1 D − 1 IHAVE đến các nút ngang hàng của nó. Đây là một sửa đổi nhỏ nhưng rất đơn giản của giao thức . Ở chế độ pull, mỗi lần nhảy mất nhiều thời gian hơn, vì IHAVE (A->B), IWANT (B->A) và sau đó là chính tin nhắn (A->B) làm tăng độ trễ gấp 3 lần so với PUSH đơn giản. IHAVE và IWANT cũng thêm các byte lưu lượng truy cập bổ sung, nhưng điều này có thể không đáng kể tùy thuộc vào kích thước tin nhắn.
Hình sau đây cho thấy mối quan hệ giữa các bản sao và số lần nhảy đầu tiên trong trường hợp Pull. Khá nhàm chán.
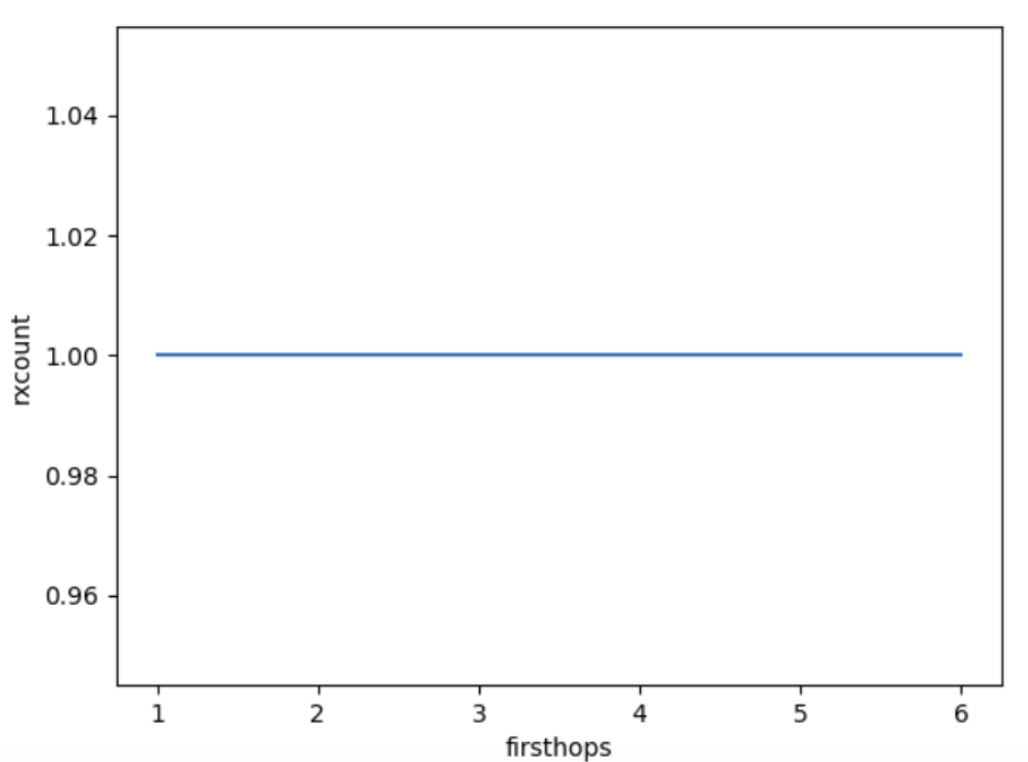
Hình 2: Số lượng tin nhắn tiếp nhận (1 + trùng lặp) trên mỗi đối tác khi sử dụng Pull thuần túy. Chỉ để cho thấy sự khác biệt so với Push, nếu không thì rất nhàm chán .
Sự ngăn chặn dựa trên sự chậm trễ
Ngoài việc chuyển từ PUSH sang PULL, chúng ta còn có một cách khác để giảm chi phí: chỉ cần tránh gửi.
Phần lớn các bản sao thực tế là do các tin nhắn đi qua cùng một LINK (Chainlink) A - B theo cả hai hướng. Nếu chúng ta thêm một độ trễ nhỏ ( \delta δ ) trước khi chuyển tiếp, một số bản sao có thể xuất hiện và sau đó chúng ta có thể tránh việc gửi lại trên LINK (Chainlink) đó, gửi ít hơn D-1 D − 1 bản sao. Lưu ý rằng IDONTWANT hoạt động trong chiều này, gửi một "cảnh báo" nhỏ trước khi chuyển tiếp, thậm chí trước khi xác thực tin nhắn.
Nếu chúng tôi nhận được bản sao trong khoảng thời gian này, chúng tôi sẽ không gửi lại trên các liên kết đó. Do đó, một số nút của chúng tôi sẽ gửi ít hơn D-1 D − 1 bản sao. Lưu ý rằng một số lần chờ xảy ra trong tất cả các triển khai do độ trễ xác thực tin nhắn GossipSub. Triển khai Nim đã sử dụng độ trễ này để ngăn chặn việc gửi tin nhắn, trong khi một số triển khai khác không làm như vậy.
Hiểu về sự đánh đổi giữa độ trễ và băng thông
Với tất cả phần giới thiệu ở trên, giờ đây chúng ta đã đi đến điểm mà chúng ta có thể lập bản đồ không gian đánh đổi giữa hai thái cực ĐẨY thuần túy và KÉO thuần túy, đồng thời thêm độ trễ vào logic quyết định.
Chúng tôi giới thiệu bốn chiến lược khác nhau, mỗi chiến lược có một tham số cho phép chúng tôi “điều chỉnh” sự đánh đổi.
Chờ ( \delta δ ) : điều dễ nhất chúng ta có thể làm là chỉ cần chờ một khoảng thời gian \delta δ sau khi nhận, trước khi gửi các bản sao. Nếu chúng ta nhận được các bản sao trong khoảng thời gian này, chúng ta không gửi lại trên các liên kết đó. Do đó, các nút của chúng ta có thể gửi ít hơn D-1 D − 1 bản sao. Lưu ý rằng một số lần chờ xảy ra trong tất cả các triển khai do độ trễ xác thực tin nhắn gossipsub. Triển khai Nim đã sử dụng độ trễ này để ngăn chặn việc gửi tin nhắn, trong khi một số triển khai khác không làm như vậy. (suppressNone)
Wait-and-Pull ( \delta δ ) : trong chiến lược này, chúng ta lại chờ \delta δ thời gian, nhưng nếu nhận được bản sao, chúng ta không chỉ ngăn chặn việc gửi. Chúng ta cũng chuyển sang chế độ PULL, gửi IHAVE trên tất cả các liên kết còn lại. (SuppressIfSeen)
Push-Pull ( d d ) : trong chiến lược này, chúng ta có D D neighbors, nhưng chúng ta chỉ PUSH đến một tập hợp con trong số này, trong khi chúng ta sử dụng chế độ PULL cho phần còn lại. Chúng ta sử dụng tham số d d để thiết lập sự đánh đổi, đẩy đến d d các đối tác được chọn ngẫu nhiên, trong khi gửi IWANT đến phần còn lại. (suppressAbove)
Chuyển đổi pha đẩy-kéo ( d d ) , hay PPPT: trong biến thể cuối cùng của chúng tôi, chúng tôi dựa vào bộ đếm hop. Khi một nút nhận được tin nhắn đầu tiên với giá trị hop-count là h h , nó sẽ gửi max(0, dh) m a x ( 0 , d − h ) PUSHes và PULL đến phần còn lại. (suppressOnHops)
Lưu ý rằng chỉ có cái cuối cùng trong số này sử dụng bộ đếm hop, phần còn lại có thể được triển khai mà không cần sửa đổi định dạng tin nhắn (chúng tôi sử dụng bộ đếm hop trong mã của mình để thu thập số liệu thống kê). Việc tiết lộ số hop-count là một chủ đề gây tranh cãi, chúng tôi sẽ thảo luận chi tiết hơn về vấn đề này sau.
Kịch bản mô phỏng
Để có được số liệu hiệu suất, chúng tôi sử dụng Shadow và trình mô phỏng dựa trên nim-libp2p . Chúng tôi chạy mô phỏng với các tham số sau:
1000 nút đã đăng ký chủ đề
kích thước tin nhắn nhỏ 1KB
hạn chế băng thông nút ở mức đối xứng 20 Mbps.
Độ trễ p2p: các biểu đồ trước đây có độ trễ đồng đều 50ms giữa các nút để đơn giản hóa việc trình bày hiệu ứng Đẩy so với Kéo. Tuy nhiên, tính đồng nhất này tạo ra các tác dụng phụ, vì vậy trong các biểu đồ sau, chúng tôi sử dụng độ trễ có được từ các phép đo trên Internet thực ( cơ sở dữ liệu RIPE Atlas ), ánh xạ từng nút của chúng tôi đến một vị trí ngẫu nhiên trên Trái đất. Độ trễ trung bình là 62ms, nhưng có nhiều liên kết nhanh hơn thế nhiều.
Hình sau đây cho thấy không gian đánh đổi giữa các bản sao và độ trễ tiếp nhận, với các điểm biểu thị hiệu suất của một chiến lược nhất định với một tham số nhất định theo hai số liệu:
trục x hiển thị độ trễ phân phối trung bình đạt được (chúng ta có thể vẽ một biểu đồ tương tự cho ví dụ độ trễ phần trăm thứ 95). Các giá trị nhỏ hơn sẽ tốt hơn, với PUSH thuần túy ở bên trái và PULL thuần túy ở bên phải.
trục y biểu thị số lượng bản sao trung bình . Các giá trị nhỏ hơn thì tốt hơn, với PULL thuần túy ở phía dưới (nhận được 1 bản sao) và pull thuần túy ở phía trên (trung bình khoảng D-1 D − 1 bản sao nhận được).
Khi chúng ta thay đổi tham số tương ứng của từng chiến lược, chúng ta có thể vẽ đường cong đánh đổi của chúng thỏa hiệp giữa các bản sao và độ trễ. Ví dụ, điểm cực trái của đường cong màu xanh lá cây biểu thị không phải chờ ( \delta=0 δ = 0 ), trong khi điểm cực phải cho thấy các bản sao giảm nhưng tăng độ trễ khi chúng ta chờ \delta=70~ms δ = 70 m s trước khi chuyển tiếp tin nhắn.
Tương tự, đối với các đường cong khác, điểm cực trái là khi chúng ta đặt tham số sao cho chiến lược không được kích hoạt. Điều này có nghĩa là ( \delta=0 δ = 0 ) đối với Wait-and-Pull, và giá trị lớn của d d (lớn hơn D D ) đối với Push-Pull và Push-Pull Phase Transition.
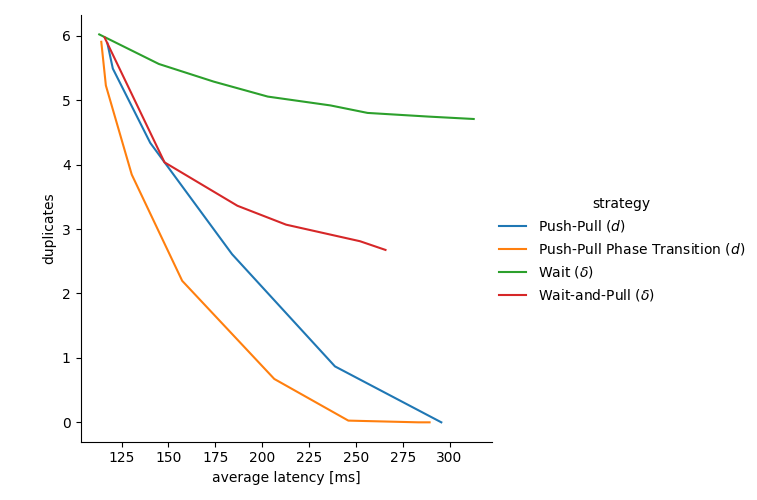
Hình 3: Sự đánh đổi giữa số lượng bản sao nhận được trung bình (tức là sử dụng băng thông) và độ trễ tiếp nhận trung bình. Mỗi đường cong biểu diễn một chiến lược, trong khi các điểm của đường cong biểu diễn các tham số hóa khác nhau của chiến lược.
Chờ ( \delta δ ) là phương pháp kém hiệu quả nhất, làm tăng độ trễ trong khi chỉ làm giảm nhẹ số lượng bản sao.
Wait-and-Pull ( \delta δ ) đạt được kết quả tốt hơn đáng kể. Trên thực tế, việc nhận được các bản sao trong một cửa sổ thời gian nhỏ có thể được sử dụng như một công cụ ước tính về việc ở giai đoạn sau trong quá trình khuếch tán, mà không cần có bộ đếm hop rõ ràng.
Đẩy-Kéo ( d d ) mang lại lợi nhuận ấn tượng, ngay cả khi đây là chiến lược cố định không yêu cầu ước tính hoặc đếm bước nhảy.
Cuối cùng, PPPT đạt hiệu suất tốt hơn bất kỳ chiến lược nào trước đây, cho phép chúng ta loại bỏ hầu hết các bản sao với độ trễ tăng nhẹ và tất cả các bản sao khi độ trễ tăng gấp đôi.
Cuộc thảo luận
Các chiến lược được trình bày ở trên chỉ là ví dụ về sự đa dạng lớn của các chiến lược khả thi. Có thể dễ dàng suy ra các kết hợp và biến thể của chúng. Chúng tôi không biết về một lý thuyết chung nào có thể cung cấp một số loại tối ưu, đặc biệt là trong bối cảnh không đồng nhất của Internet.
Mặc dù nghiên cứu của chúng tôi chỉ là sơ bộ và có thể đánh giá thêm nhiều khía cạnh khác (số lượng nút khác nhau; kích thước tin nhắn khác nhau; giới hạn băng thông khác nhau, ETC), chúng tôi có thể nêu bật một số khía cạnh:
Lợi thế của bộ đếm hoa bia là rõ ràng
Rõ ràng là việc thêm một bộ đếm hop có thể mang lại lợi ích đáng kể trong việc giảm trùng lặp trong khi vẫn giữ độ trễ ở mức thấp. Điều này không có gì đáng ngạc nhiên sau khi phân tích chi tiết về vị trí trùng lặp trong hệ thống, nó chỉ xác nhận rằng hop-count thực sự là một tác nhân kích hoạt tốt để thay đổi từ Push sang Pull.
Hiệu suất chiến lược cố định không tệ chút nào
Điều đáng ngạc nhiên hơn một Bit (ít nhất là với tôi) là một chiến lược cố định cũng hoạt động khá tốt, mặc dù đường cong hiệu suất rõ ràng đang bị ảnh hưởng do không có thông tin về số lần nhảy.
Số lượng hop và quyền riêng tư
Cũng cần phải rõ ràng rằng hop count đang làm tổn hại đến quyền riêng tư của nhà xuất bản… nếu có bất kỳ điều gì xảy ra ngay từ đầu. Chúng tôi lập luận rằng libp2p và GossipSub có những ứng dụng mà quyền riêng tư của nhà xuất bản không phải là mối quan tâm. Ngay cả trong các trường hợp sử dụng Ethereum, thường thì việc ẩn danh người gửi đã dễ dàng, và trong những trường hợp đó, hop-count không giúp việc này dễ dàng hơn đáng kể.
Số lượng hop có thể bị gian lận
Một nhược điểm khác của hop-count là dễ nói dối về nó. Ngoài ra, hop-count không nên là một phần của việc chấm điểm ngang hàng, vì nó sẽ tạo ra thêm động cơ gian lận. Tuy nhiên, chúng tôi cho rằng đây không phải là vấn đề cơ bản, vì một nút nói dối về hop-count sẽ chỉ làm chậm (hoặc tăng tốc) cây con của chính nó trong cây khuếch tán, mà không có tác động toàn cục.
Các trường hợp sử dụng GossipSub khác nhau
Chúng tôi trình bày các chiến lược giảm thiểu trùng lặp như một không gian đánh đổi vì một lý do: ngay cả trong Ethereum, GossipSub cũng có nhiều trường hợp sử dụng (chưa kể đến việc sử dụng bên ngoài Ethereum). Các chiến lược và tham số khác nhau có thể được lựa chọn cho các trường hợp sử dụng khác nhau (hoặc chủ đề hoặc kích thước tin nhắn).
Về việc tối ưu hóa các khu vực lân cận dựa trên RTT
Có lẽ cũng đáng đề cập rằng lý luận của chúng tôi về việc không có bản sao trong các bước nhảy đầu tiên giả định các vùng lân cận ngẫu nhiên. Thường có ý tưởng (trong tài liệu và trong các cuộc trò chuyện) là tối ưu hóa các vùng lân cận dựa trên RTT đã đo. Thật không may, việc tối ưu hóa như vậy có tác dụng phụ là thay đổi cấu trúc biểu đồ lớp phủ, dẫn đến nhiều bản sao hơn trong các bước nhảy đầu tiên và dẫn đến đường kính lớn hơn. Các tối ưu hóa dựa trên RTT có thể được thiết kế cẩn thận, nhưng điều quan trọng là phải nhận thức được các tác dụng phụ này.
Tôi có chi phí giao thông
Trong các số liệu của chúng tôi, chúng tôi đã tính đến các bản sao tin nhắn, nhưng không tính đến chi phí chung của tin nhắn IHAVE. Việc đơn giản hóa này có hợp lý hay không tùy thuộc vào kích thước tin nhắn và mối quan hệ của nó với ID tin nhắn và mã hóa của chúng trong tin nhắn IHAVE. Chúng tôi lưu ý rằng có thể thực hiện một số tối ưu hóa để di chuyển kim ở đây.
Nếu có tần suất tin nhắn cao trên một LINK (Chainlink), các tin nhắn IHAVE riêng lẻ của chúng có thể được tổng hợp thành một tin nhắn duy nhất với độ trễ bổ sung nhỏ.
Việc tổng hợp IHAVE này cũng có thể được thực hiện trên nhiều chủ đề , với độ trễ bổ sung được kiểm soát.
Trong một số trường hợp sử dụng, khi tin nhắn có thể nhận được ID từ không gian ID tin nhắn có cấu trúc , các tin nhắn IHAVE tổng hợp như vậy cũng có thể được nén. Đó là trường hợp của DAS, nơi chúng tôi đề xuất tin nhắn IHAVE dựa trên bitmap , nhưng nén dựa trên bitmap cũng có thể được sử dụng như một công cụ tổng quát hơn.
Làm thế nào để sinh sản
Số lượng hop và tất cả các chiến lược được triển khai như một phần của nim-libp2p và sẽ sớm được công bố dưới dạng một nhánh trong bản tiếp theo.
Khung mô phỏng của chúng tôi cũng có một số thay đổi tùy ý để phù hợp với các mô phỏng này, sẽ được công bố sau.



