

Nghiên cứu này được thực hiện bởi @cortze và @yiannisbot từ nhóm ProbeLab ( probelab.io ), với sự phản hồi của cộng đồng EF và PeerDAS.
Giới thiệu
Là một phần trong lộ trình cải thiện khả năng mở rộng của Ethereum, các giao dịch blob đã được giới thiệu để cho phép đưa nhiều dữ liệu hơn vào mỗi khe. Do đó, càng có thể thêm nhiều blob, càng có thể hỗ trợ nhiều dữ liệu hơn on-chain, điều này có lợi cho các giải pháp mở rộng quy mô và các giải pháp mở rộng quy mô khác.
Vì lý do này, người ta vẫn đang quan tâm đến việc tăng cả số lượng mục tiêu và số lượng tối đa của blob trên mỗi Block. Tuy nhiên, điều này làm nảy sinh một số lo ngại:
- Trong khi những người stake tổ chức có thể có phần cứng và băng thông để xử lý nhiều blob hơn, nhiều người stake tại nhà thì không. Điều này tạo ra sự mất cân bằng tiềm ẩn trong sự tham gia của người xác thực.
- Số lượng blob tăng cũng có thể ảnh hưởng đến khả năng đồng bộ hóa của một số nút, đặc biệt là trong quá trình tổ chức lại hoặc khôi phục, khi các nút cần tải xuống lượng dữ liệu lớn từ một nhóm đối tác nhỏ hơn.
Hiện tại, chúng tôi không có nhiều cách để đo lường mức độ mạng có thể xử lý những tình huống này tốt như thế nào, ngoài việc xem xét tốc độ chúng tôi có thể tải xuống các khối hoặc blob từ các nút khác (xem bài đăng của chúng tôi , mở rộng ý tưởng này). Điều này cung cấp một số hiểu biết, nhưng không đủ để hiểu đầy đủ về hành vi của mạng khi phục hồi ứng suất.
Một cách có thể để giảm tải cho từng trình xác thực là thông qua việc xây dựng Block phân tán . Vì Lớp thực thi (EL) thường nhận được nhiều giao dịch blob trước khi chúng được đưa vào một Block, nên trình xây dựng Block có thể giảm mức sử dụng băng thông ban đầu bằng cách giả định rằng các mempool cục bộ của các nút khác đã chứa các blob cần thiết để xác thực Block .
Công trình trong bài đăng hiện tại dựa trên nghiên cứu gần đây của chúng tôi, trong đó chúng tôi đã đo tỷ lệ trúng đích của mempool EL lý thuyết cho các xe đẩy bên hông blob . Phân tích đó cho thấy trong hơn 75% trường hợp, EL đã có dữ liệu blob cần thiết trước khi đề xuất Block . Tuy nhiên, nghiên cứu đó không kiểm tra xem EL có thể phục vụ các blob kịp thời cho lệnh gọi engine_getBlobsV1 từ Lớp Consensus (CL) hay không.
Trong phần tiếp theo này, chúng tôi sẽ xem xét tỷ lệ thành công thực nghiệm của các sidecar blob trong mempool EL để hiểu rõ hơn về tính khả thi của việc xây dựng Block phân tán trong thực tế, đặc biệt là trong việc hỗ trợ các trình xác thực có băng thông hoặc tài nguyên hạn chế.
Tóm lại
- Theo dõi các lệnh gọi
engine_GetBlobsV1cục bộ giữa CL và EL cho thấy tỷ lệ trúng blob thực nghiệm cao tại mempool của EL:- 76,6% tổng số yêu cầu đã được truy xuất thành công từ mempool EL cục bộ để xác thực Block trong vòng chưa đầy 100ms.
- 23,4% yêu cầu còn lại đã được phản hồi một phần. Tuy nhiên, trong phần lớn các phản hồi một phần này (98%), chỉ có một sidecar blob duy nhất bị thiếu trong danh sách yêu cầu.
- Trạng thái mạng hiện tại cho thấy việc phân phối lại tất cả các sidecar qua mạng gossipsub có thể tạo ra một số lưu lượng dự phòng vì hiện tại, phần lớn các blob đã có mặt tại bộ nhớ EL vào thời điểm một Block mới được phát.
Phương pháp luận
Để tạo và thu thập tất cả các mẫu cần thiết để có chế độ xem nhất quán về mempool blob EL, chúng tôi đã phát triển công cụ tùy chỉnh để gửi một hàng mục nhập theo REQ cầu engine_GetBlobsV1 /resp mà một nút CL đã thực hiện cho máy khách EL.
Để thực hiện điều đó, chúng tôi đã phát triển một điểm cuối luồng sự kiện mới tại Fork Prysm , điểm cuối này không chỉ hiển thị dữ liệu về các yêu cầu Engine API mà còn cả phản hồi và thời gian.
Chi tiết nghiên cứu
Chi tiết về thời điểm và cách thức thu thập dữ liệu:
- Dữ liệu được thu thập thuộc về những ngày sau:
| Ngày tháng | Tiền Pectra | Hậu Pectra |
|---|---|---|
| từ | 2025-05-02 | 2025-05-07 |
| ĐẾN | 2025-05-07 | 2025-05-11 |
- Chúng tôi đã sử dụng các cặp khách hàng sau:
- Prysm (
custom-fork) ↔ Nethermind (v1.31.9)
- Prysm (
- Chúng tôi chạy cả hai máy khách từ Intel Nuc tại nhà ở Tây Ban Nha.
Phân tích
Với hơn 9 ngày dữ liệu, các biểu đồ sau đây tóm tắt trạng thái của mạng trước và sau mục tiêu blob chuỗi Pectra và các tham số tối đa:
- Trước Pectra:
blob-target=3vàblob-max-value=6. - Sau Pectra:
blob-target=6vàblob-max-value=9.
Blobs trên mỗi dữ liệu khe
Cộng đồng Ethereum đã thể hiện sự quan tâm mạnh mẽ trong việc tăng mục tiêu blob và giá trị tối đa, vì chúng liên quan trực tiếp đến khả năng mở rộng của mạng. Giới hạn blob cao hơn có thể giúp tăng cường các giải pháp mở rộng quy mô và rollup khác bằng cách cho phép đăng nhiều dữ liệu hơn on-chain.
Tuy nhiên, dữ liệu từ nghiên cứu 9 ngày của chúng tôi cho thấy chỉ có 52,60% khối bao gồm các giao dịch blob trong khoảng thời gian đó. Điều này cho thấy rằng, mặc dù có dung lượng, nhưng không phải lúc nào cũng được sử dụng hết trong thực tế.
Các mẫu này có thể thay đổi theo thời gian, đặc biệt là khi bản nâng cấp Pectra đã tăng số lượng blob có thể vừa với một Block. Biểu đồ thanh sau đây so sánh mức sử dụng blob trước và sau khi nâng cấp, cho thấy cách phân phối các giao dịch blob đã thay đổi như thế nào.
Trước Pectra, các bản tóm tắt cho thấy chỉ có 53% khối beacon bao gồm bất kỳ giao dịch blob nào và 71,87% trong số chúng có tất cả các sidecar blob được liên kết có sẵn tại máy khách EL cục bộ.
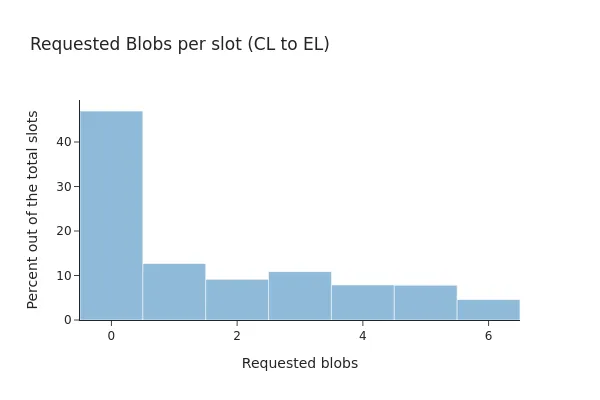
Sau Pectra, tỷ lệ này hầu như không thay đổi, chỉ còn 52% các khối bao gồm các giao dịch blob, trong đó 81,82% trong số chúng có tất cả các blob hiện diện tại máy khách EL.
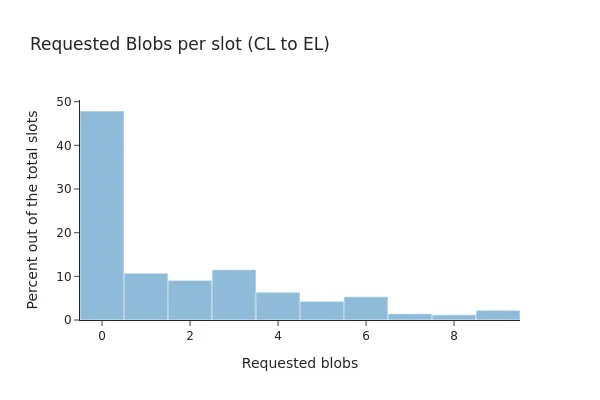
LƯU Ý: mặc dù mạng hiện có thể sử dụng số lượng blob cao hơn, nhưng có vẻ như mạng vẫn đang hoạt động theo các thông số cũ (tức là tối đa 6 blob).
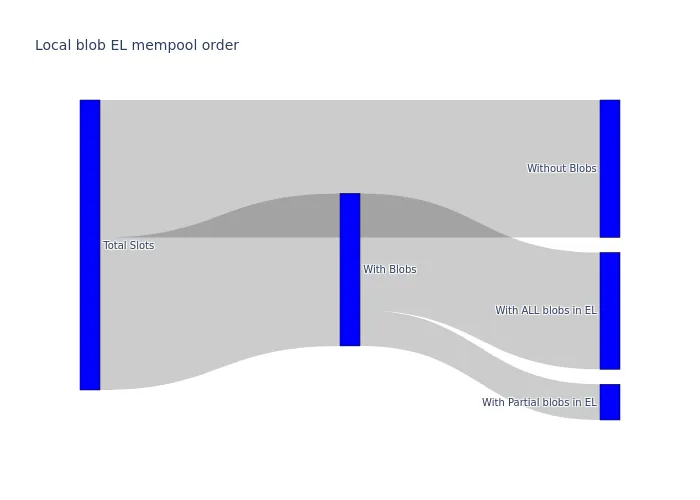
Sơ đồ Sankey sau đây tóm tắt luồng các khối beacon theo quan điểm của CL. Dữ liệu được tổng hợp trong 9 ngày, vì không có sự khác biệt đáng kể nào giữa các giai đoạn trước và sau khi nâng cấp Pectra. Sơ đồ cho thấy số lượng yêu cầu engine_getBlobsV1 một phần mà CL nhận được tương đối nhỏ so với tổng số khối.
Độ chính xác của phản ứng động cơ
Không phải tất cả các máy khách Lớp thực thi (EL) đều xử lý các yêu cầu engine_getBlobsV1 theo cùng một cách. Một số máy khách chỉ có thể phản hồi nếu chúng có tất cả các blob được yêu cầu, trong khi những máy khách khác có thể trả về phản hồi một phần nếu chúng chỉ có một số trong số chúng. Trong thiết lập của chúng tôi, Nethermind trả về các phản hồi một phần, cho phép chúng tôi đo lường số lượng blob được yêu cầu có trong EL mempool tại thời điểm yêu cầu.
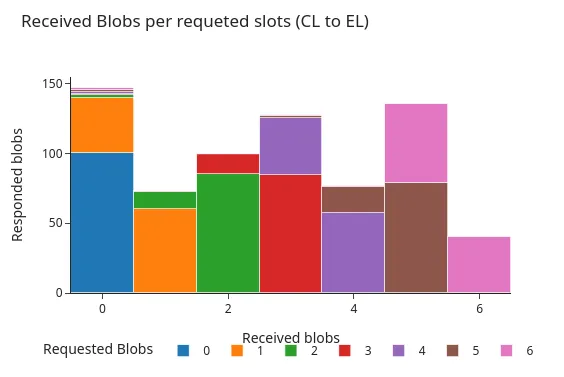
Các hình sau đây cho thấy sự phân bố của các phản hồi này vào thời điểm diễn ra hardfork Pectra. Cả hai biểu đồ đều hiển thị biểu đồ tần suất về số lượng blob được API của engine trả về, được nhóm theo số lượng blob được yêu cầu. Như được thấy trong các hình, hai mẫu phản hồi chính là phổ biến nhất:
- API của engine trả về tất cả các sidecar blob được yêu cầu.
- API của engine trả về tất cả các sidecar blob được yêu cầu, ngoại trừ một sidecar.
Trước khi dùng Pectra:
Sau Pectra:
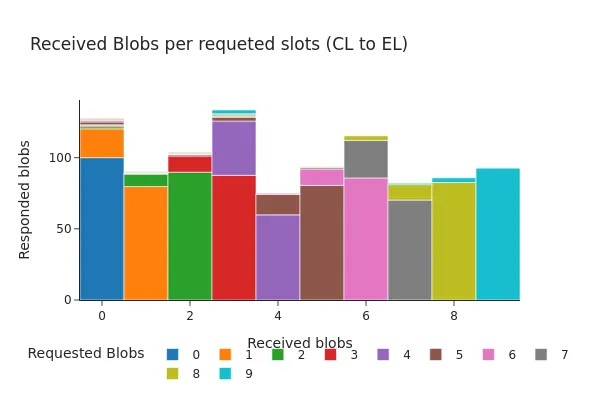
Bên cạnh sự hiện diện của các yêu cầu chứa tới 9 blob (được kích hoạt bởi bản nâng cấp Pectra), hai biểu đồ cho thấy sự phân phối rất giống nhau. Trong hơn 98% trường hợp, tất cả các blob được yêu cầu đều có sẵn tại EL tại thời điểm yêu cầu hoặc chỉ thiếu một blob duy nhất.
Mặc dù việc liên tục thiếu một đốm màu có vẻ bất thường, chúng tôi tin rằng có một số lời giải thích hợp lý cho hành vi này:
- Giao dịch blob bị mất có thể là một phần của mempool riêng tư, nghĩa là nó không được lan truyền công khai và chỉ có thể tìm thấy thông qua tin đồn CL.
- EL có thể đã nhận ra giao dịch quá muộn hoặc không có đủ thời gian để tải xuống toàn bộ dữ liệu trước khi yêu cầu
engine_getBlobsV1được thực hiện.
Để hiểu rõ hơn về tình hình, chúng tôi đã tham chiếu chéo các giao dịch blob bị thiếu với cơ sở dữ liệu mempool của Xatu. Kết quả cho thấy 58% các sidecar bị thiếu chưa bao giờ được nhìn thấy trong mempool công khai, điều này hỗ trợ cho tuyên bố rằng nhiều giao dịch trong số này có khả năng là riêng tư hoặc mới được phát sóng gần đây.
| Có phải là một phần của phản ứng không? | Có được nhìn thấy ở quán rượu mempool không? | số lượng xe đẩy |
|---|---|---|
| ĐÚNG VẬY | ĐÚNG VẬY | 197156 |
| SAI | ĐÚNG VẬY | 4571 |
| SAI | vô giá trị | 6392 |
Thời gian gọi API của Engine và thời gian tái tạo blob
Do Lớp Consensus (CL) không thể chờ vô thời hạn để nhận được phản hồi từ Lớp thực thi (EL), một số nhóm khách hàng đã thảo luận xem có nên áp dụng thời gian chờ cho các yêu cầu engine_getBlobsV1 hay không và nếu có thì giá trị phù hợp sẽ là bao nhiêu.
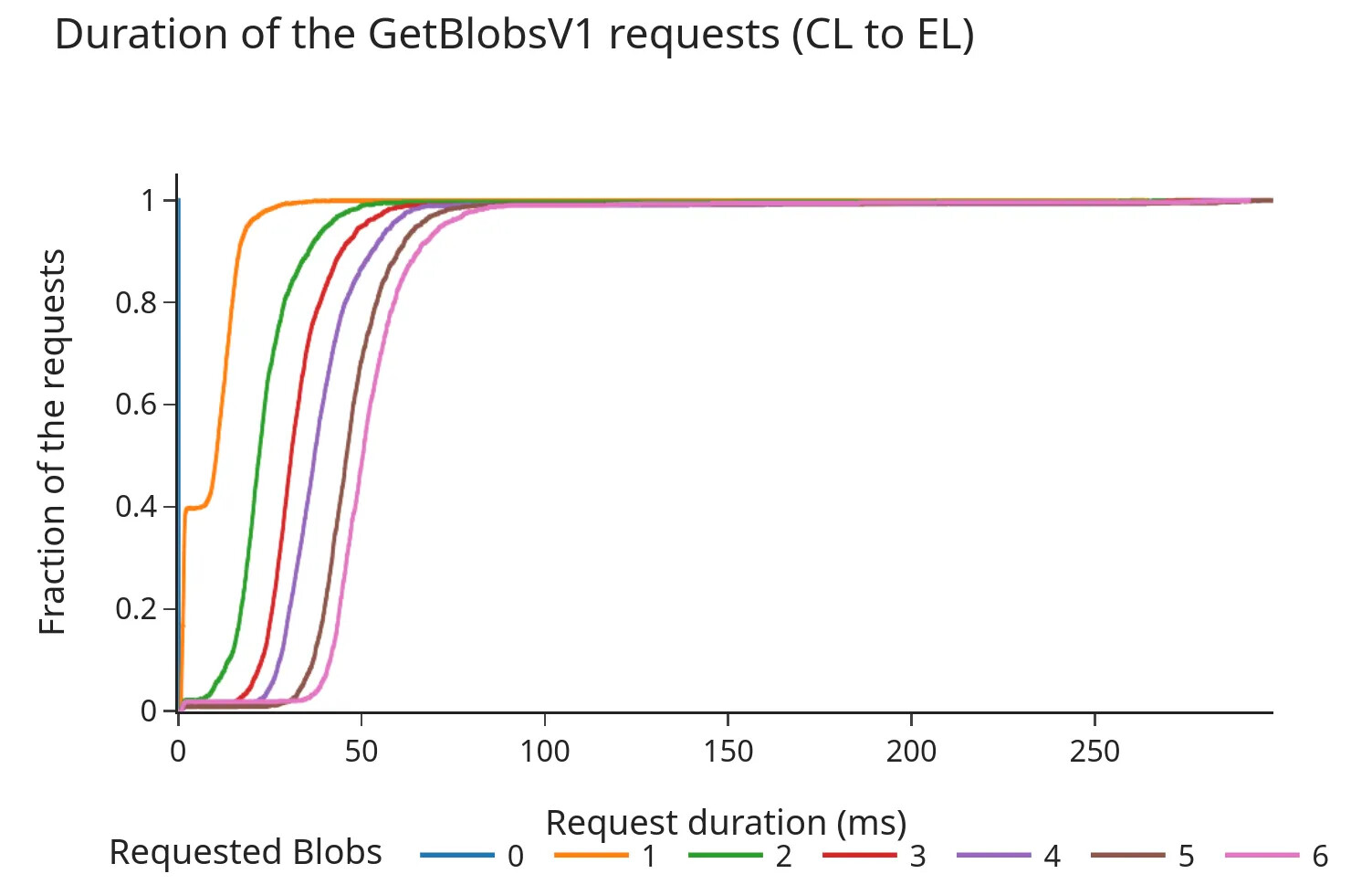
Biểu đồ sau đây hiển thị Hàm phân phối tích lũy (CDF) của thời lượng yêu cầu/phản hồi (tính bằng mili giây) cho API công cụ.
Trước khi dùng Pectra:
Sau Pectra:
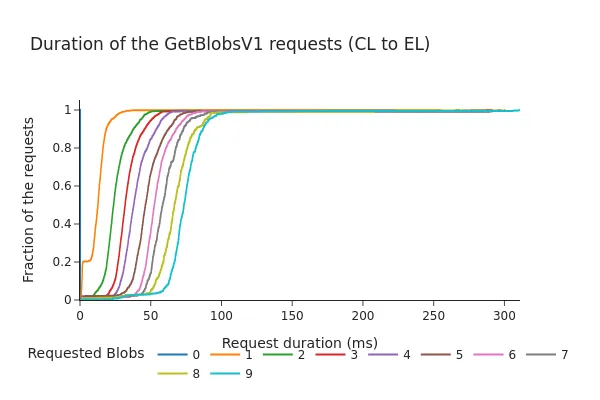
- CDF cho thấy 98% yêu cầu được hoàn thành trong vòng chưa đầy 100 mili giây, ngay cả sau khi Fork Pectra và thêm 3 blob cho mỗi Block.
- Tổng thời lượng có xu hướng tăng gần như tuyến tính với số lượng blob được yêu cầu. Mặc dù những thời gian này vẫn nằm trong phạm vi thường được coi là "biên độ an toàn" (các cuộc thảo luận trước đây đề xuất thời gian chờ khoảng 200–250 ms), dữ liệu cho thấy việc tăng số lượng blob trên mỗi khe có thể dẫn đến thời gian truy xuất lâu hơn từ bộ nhớ blob của EL, đặc biệt là khi tải cao hơn.
Kết luận
Nghiên cứu này và nghiên cứu trước đây của chúng tôi được tiến hành song song với nghiên cứu của @cskiraly và mặc dù phương pháp luận khác nhau, cả hai nghiên cứu đều có cùng một kết quả:
với trạng thái mạng hiện tại và xu hướng sử dụng của chuỗi, hầu hết các sidecar blob đều đã có sẵn tại EL khi chúng được đưa vào Block beacon.
Mặc dù thông tin rút ra này nhìn chung là tin tốt, nhưng nó cho thấy mạng hiện tại đang sử dụng một phần đáng kể tài nguyên của mình để gửi thông tin dư thừa qua các chủ đề phụ CL, do đó vẫn còn nhiều chỗ để cải thiện.
Một mặt, sự dự phòng này đảm bảo rằng tất cả các nút CL đều có dữ liệu cần thiết để xử lý đề xuất Block mới kịp thời, cung cấp khả năng phục hồi thành công. Mặt khác, nó cũng trở thành nút thắt cổ chai của chính nó, vì tất cả các sidecar blob cần được phát qua mạng trong thời gian ít hơn 4 giây một Bit (giả sử các trò chơi thời gian đang rút ngắn thời gian đó).
Khuyến nghị
Với mục đích chính là giảm chi phí mạng và tình trạng quá tải của nút, việc mở cuộc thảo luận xung quanh PeerDAS và chia sẻ blob sidecar là điều đáng làm.
Với đề xuất PeerDAS hiện tại của Ethereum, chúng tôi chỉ phân mảnh các sidecar tại CL, đây là một sự tối ưu hóa ở giai đoạn phân phối lại Blobs. Tuy nhiên, điều này chỉ giải quyết được một phần vấn đề, vì chúng tôi vẫn sẽ gửi tất cả các giao dịch blob qua mempool EL, nơi các nút sẽ tải xuống tất cả các blob một cách vô ý nếu băng thông của chúng cho phép.
Ngay cả với việc xây dựng Block phân tán, có thể góp phần phát nhanh hơn các blob, chúng ta vẫn sẽ gửi (ít nhất là một phần) thông tin dư thừa. Các thông báo
IDONTWANTcó ích ở đây, nhưng chúng ta vẫn sẽ tạo ra nhiều bản sao, cuối cùng làm tăng chi phí mạng và tải nút.
Tương lai có thể
Có một lợi ích rõ ràng và đáng kể khi chuyển phân mảnh sang mempool của EL:
Việc phân mảnh các sidecar tại EL có thể đơn giản hóa việc gieo hạt và một số bước tính toán trước của các blob từ mạng xác thực, đây có thể là nhiệm vụ mới của người đề xuất giao dịch, tức là áp dụng mã hóa xóa trên các ô blob và bắt đầu phát sóng.
Có thể đề xuất/áp dụng các thuộc tính cân bằng tải cho việc phân phối các blob, giúp loại bỏ giới hạn thời gian hiện tại là “4 giây” mà CL phải phát sóng các sidecar. Vì blob vẫn chưa được đưa vào, chúng ta không cần phải áp dụng bất kỳ thời hạn nào cho việc truyền bá của nó. Điều này có nghĩa là những người dùng chậm hơn có thể “chịu” được một số độ trễ bổ sung khi phát sóng các mảnh xung quanh.
Hiện tại EL hiệu quả hơn CL trong việc tải xuống các blob:
- Không có giới hạn thời gian khi tải các blob ở lớp EL, do đó, không cần phải tải xuống tất cả các blob mà chúng ta thấy cùng một lúc.
- EL quyết định khi nào gửi một yêu cầu kéo sidecar duy nhất, tránh trùng lặp mà GossipSubs gây ra trên các đối tác lưới trung bình của nó → mặc định là
D-2bản sao cho mỗi tin nhắn ( LINK (Chainlink) )
Điều này phần lớn phù hợp với đề xuất của @cskiraly : có thể hiệu quả hơn đáng kể khi triển khai phân mảnh ở Lớp thực thi (EL) thay vì ở Lớp Consensus (CL).
Ý tưởng này vẫn đang ở dạng bản thảo và khám phá cách chúng ta có thể tối ưu hóa việc sử dụng tài nguyên mạng, vì vẫn còn nhiều vấn đề chưa được giải quyết.
Để minh họa cho cách thức này, chúng tôi muốn xem lại và chia sẻ đề xuất DHT mempool Blob vẫn đang được tiến hành mà nhóm ProbeLab đã bắt đầu soạn thảo cách đây vài tháng. Đề xuất này nhằm mục đích chứng minh cách CL và EL có thể hoạt động đồng bộ để cho phép sử dụng băng thông mạng và lưu trữ hiệu quả hơn (để lại thông tin chi tiết về đề xuất cho bài đăng trong tương lai). Như thường lệ, chúng tôi hoan nghênh mọi phản hồi.



