

Tôi tin rằng những người đã sử dụng mô hình DeepSeek-R1 đều quen thuộc với quá trình suy nghĩ của nó trước khi đưa ra câu trả lời. Đây là một trong những lý do tại sao các mô hình lý luận lớn (LRM) bao gồm DeepSeek-R1 được đánh giá cao.
Tuy nhiên, đội ngũ gồm sáu nhà nghiên cứu từ Apple đã đặt câu hỏi về điều này. Bằng cách yêu cầu các mô hình giải quyết nhiều câu đố khác nhau, đội ngũ nghiên cứu phát hiện ra rằng độ chính xác của một số mô hình lý luận quy mô lớn tiên tiến, chẳng hạn như DeepSeek-R1, o3-mini và Claude-3.7-Sonnet-Thinking, đã sụp đổ sau khi vượt quá một ngưỡng phức tạp nhất định.

Hình ảnh | Các bài báo liên quan (Nguồn: https://ml-site.cdn-apple.com/papers/the-illusion-of-thinking.pdf)
Điều đáng chú ý là Samy Bengio, giám đốc cấp cao về nghiên cứu máy học của Apple, là đồng tác giả của bài báo lần. Anh không chỉ là em trai của người đoạt giải Turing là Yoshua Bengio mà còn là một trong những thành viên đầu tiên của đội ngũ Google Brain.

Hình ảnh | Sáu tác giả của bài báo có liên quan, người thứ hai từ bên phải là Samy Bengio (Nguồn: Data Map)
Một cư dân mạng trên X kết luận rằng Apple đã hành động giống như Gary Marcus, và bản thân Gary Marcus cũng đã đăng trên LinkedIn để khẳng định bài báo của Apple. Ông viết: "Bài báo mới nhất của Apple về khả năng 'lý luận' trong các mô hình ngôn ngữ lớn khá gây sốc. Tôi đã giải thích trong đó do (và khám phá một phản đối có thể xảy ra) trong một bài báo dài vào cuối tuần để chỉ ra lý do tại sao mọi người không nên quá ngạc nhiên."
Trong "bài viết dài cuối tuần" của Gary Marcus, ông viết: "Bài báo mới này của Apple càng khẳng định thêm lời chỉ trích của riêng tôi : ngay cả khi cái gọi là "mô hình suy luận" mới nhất đã được lặp lại vượt qua phiên bản o1, chúng vẫn không thể đạt được lý luận đáng tin cậy ngoài phân phối đối với các vấn đề kinh điển như Tháp Hà Nội. Đây chắc chắn là tin xấu đối với những nhà nghiên cứu hy vọng rằng "khả năng suy luận" hoặc "tính toán trong khi suy luận" có thể đưa các mô hình ngôn ngữ lớn trở lại đúng hướng và thoát khỏi việc mở rộng quy mô đơn giản, nhưng đã nhiều lần thất bại (không bao giờ có thể tạo ra một bước đột phá về mặt kỹ thuật xứng đáng với tên gọi "GPT-5")."

Hình ảnh | “Bài viết dài cuối tuần” của Gary Marcus được đăng trên trang web cá nhân của anh ấy (Nguồn: https://garymarcus.substack.com/p/a-knockout-blow-for-llms)
Vậy, đây là “tin xấu” hay “tin tốt”? Hãy bắt đầu với chi tiết trong bài báo của Apple.
Có thể hoàn thành tối đa 100 hành động đúng, nhưng không thể thực hiện đúng quá 5 bước
Trong nghiên cứu, đội ngũ nghiên cứu từ Apple đã phát hiện ra ba chế độ lý luận khác nhau: trong nhiệm vụ có độ phức tạp thấp, mô hình ngôn ngữ lớn tiêu chuẩn hoạt động tốt hơn mô hình lý luận lớn; trong nhiệm vụ có độ phức tạp lần bình, mô hình lý luận lớn hoạt động tốt hơn; và trong nhiệm vụ có độ phức tạp cao, cả hai loại mô hình đều không thể hoàn thành nhiệm vụ một cách hiệu quả.
Nỗ lực cần thiết cho việc suy luận trái ngược với trực giác giảm đi khi vấn đề đạt đến mức độ phức tạp quan trọng, cho thấy có thể có giới hạn trên cố hữu đối với mở rộng tính toán của các mô hình suy luận lớn.
Đội ngũ nghiên cứu cho biết nhận xét này thách thức các giả định phổ biến về khả năng của các mô hình lý luận lớn và cho thấy phương pháp hiện tại có thể có những rào cản cơ bản trong việc đạt được lý luận tổng quát.
Đáng chú ý nhất là đội ngũ đã quan sát thấy những hạn chế trong các mô hình suy luận lớn khi thực hiện các phép tính chính xác: Ví dụ, khi các mô hình được cung cấp một thuật toán để giải câu đố toán học Tháp Hà Nội, hiệu suất giải quyết bài toán của chúng không được cải thiện.
Hơn nữa, phân tích sâu sắc về những bước đi sai lầm đầu tiên của mô hình đã tiết lộ những mô hình hành vi đáng ngạc nhiên: ví dụ, mô hình có thể hoàn thành tới 100 bước đi đúng trong câu đố Tháp Hà Nội, nhưng không thể thực hiện đúng hơn năm bước đi trong trò chơi logic River Crossing.
Nhìn chung, đội ngũ nghiên cứu cho rằng bài báo này nêu bật cả ưu điểm và hạn chế của các mô hình suy luận quy mô lớn hiện có. Các kết luận nghiên cứu chính như sau:
Đầu tiên, đội ngũ nghiên cứu đặt câu hỏi về mô hình đánh giá hiện tại của các mô hình lý luận quy mô lớn dựa trên các chuẩn mực toán học đã được thiết lập và thiết kế một nền tảng thử nghiệm có thể kiểm soát được bằng cách sử dụng hoàn cảnh câu đố thuật toán.
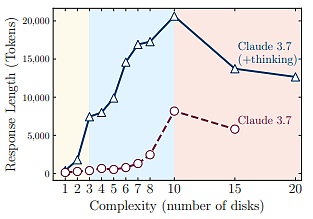
Thứ hai, các thí nghiệm của đội ngũ nghiên cứu cho thấy ngay cả các mô hình lý luận quy mô lớn tiên tiến nhất (như o3-mini, DeepSeek-R1 và Claude-3.7-Sonnet-Thinking) vẫn chưa phát triển được khả năng giải quyết vấn đề tổng quát. Trong hoàn cảnh khác nhau, khi độ phức tạp của vấn đề vượt quá một ngưỡng nhất định, độ chính xác của nó cuối cùng sẽ giảm xuống bằng không.
Thứ ba, đội ngũ nghiên cứu phát hiện ra rằng các mô hình lý luận quy mô lớn có giới hạn mở rộng về khả năng lý luận liên quan đến độ phức tạp của vấn đề. Điều này có thể được xác nhận bằng xu hướng giảm phản trực giác về số lượng mã thông báo suy nghĩ sau khi đạt đến một điểm phức tạp nhất định.
Thứ tư, đội ngũ nghiên cứu đã đặt câu hỏi về mô hình đánh giá hiện tại dựa trên độ chính xác cuối cùng. Phân tích cho thấy khi độ phức tạp của vấn đề tăng lên, giải pháp đúng sẽ xuất hiện muộn hơn trong quá trình lý luận so với giải pháp sai.
Thứ năm, đội ngũ nghiên cứu đã tiết lộ những hạn chế đáng ngạc nhiên về khả năng thực hiện các phép tính chính xác của các mô hình lý luận lớn, bao gồm việc không thể tận dụng các thuật toán rõ ràng và sự không nhất quán trong lý luận giữa các loại câu đố khác nhau.
Các mô hình suy luận lớn có khả năng tự điều chỉnh hạn chế
Có thể hiểu rằng mô hình suy luận quy mô lớn là một biến thể mới bắt nguồn từ mô hình ngôn ngữ lớn được tối ưu hóa cụ thể cho nhiệm vụ suy luận.
Các mô hình này là sản phẩm công nghệ mới có các tính năng cốt lõi nằm ở cơ chế "suy nghĩ" độc đáo, chẳng hạn như Chuỗi suy nghĩ tự phản xạ (CoT) và đã chứng minh hiệu suất tuyệt vời trong nhiều chuẩn mực lý luận.
Sự xuất hiện của các mô hình này đánh dấu một sự thay đổi mô hình có thể có trong cách các mô hình ngôn ngữ lớn xử lý lý luận phức tạp và giải quyết vấn đề. Một số nhà nghiên cứu cho rằng rằng đây là một bước quan trọng hướng tới khả năng trí tuệ nhân tạo tổng quát hơn.
Bất chấp quan điểm sâu sắc và tiến bộ về hiệu suất này, những lợi thế và hạn chế cơ bản của các mô hình lý luận lớn vẫn chưa được hiểu đầy đủ. Một câu hỏi quan trọng vẫn chưa được trả lời là: các mô hình lý luận lớn này có khả năng khái quát hóa lý luận hay chúng chỉ đơn giản là tận dụng các hình thức khớp mẫu khác nhau?
Hiệu suất của chúng thay đổi như thế nào khi độ phức tạp của vấn đề tăng lên? Với cùng một ngân sách tính toán cho các mã thông báo suy luận, chúng hoạt động như thế nào so với các mô hình ngôn ngữ lớn tiêu chuẩn không có cơ chế "suy nghĩ"?
Quan trọng nhất là những hạn chế cố hữu của phương pháp lý luận hiện tại là gì và cần có những cải tiến nào để đạt được khả năng lý luận mạnh mẽ hơn?
Đội ngũ nghiên cứu cho rằng rằng những hạn chế của mô hình đánh giá hiện tại đã dẫn đến việc thiếu phân tích có hệ thống về những vấn đề này. Đánh giá hiện tại chủ yếu tập trung vào các chuẩn mực toán học và chuẩn mực mã hóa đã được thiết lập. Các chuẩn mực này chắc chắn có giá trị, nhưng chúng thường có vấn đề về ô nhiễm dữ liệu và không thể cung cấp các điều kiện thử nghiệm có thể kiểm soát được trong các tình huống và mức độ phức tạp khác nhau.
Để hiểu rõ hơn về hành vi suy luận của các mô hình này, đội ngũ nghiên cứu cho rằng cần có một hoàn cảnh để có thể thực hiện các thí nghiệm được kiểm soát.
Để làm được điều này, họ sử dụng một hoàn cảnh giải đố được kiểm soát thay vì một chuẩn mực như các bài toán, trong đó họ điều chỉnh các yếu tố của câu đố trong khi vẫn giữ nguyên logic cốt lõi để có thể thay đổi độ phức tạp một cách có hệ thống và kiểm tra cả quá trình giải quyết và lập luận bên trong.
(Nguồn: Bản đồ dữ liệu)
Những câu đố này có các đặc điểm sau:
(1) Khả năng kiểm soát tốt sự phức tạp;
(2) Tránh sự ô nhiễm thường gặp trong các chuẩn mực hiện có;
(3) Chỉ cần dựa vào các quy tắc được đưa ra rõ ràng, nhấn mạnh khả năng suy luận thuật toán;
(4) Hỗ trợ đánh giá dựa trên mô phỏng chặt chẽ, cho phép kiểm tra giải pháp chính xác và phân tích lỗi chi tiết.
Thông qua nghiên cứu thực nghiệm, họ đã tiết lộ một số phát hiện quan trọng về các mô hình suy luận quy mô lớn hiện tại:
Đầu tiên, mặc dù các mô hình lý luận lớn có thể học các cơ chế tự phản ánh phức tạp thông qua học tăng cường, nhưng chúng không phát triển được khả năng giải quyết vấn đề tổng quát cho nhiệm vụ lập kế hoạch, với hiệu suất giảm xuống bằng không khi vượt quá ngưỡng phức tạp nhất định.
Thứ hai, việc so sánh mô hình suy luận quy mô lớn và mô hình lớn tiêu chuẩn đội ngũ nghiên cứu trong các phép tính suy luận tương đương đã cho thấy ba cơ chế suy luận khác nhau.
Cơ chế đầu tiên là đối với các vấn đề đơn giản hơn, ít kết hợp hơn, mô hình lớn tiêu chuẩn thể hiện hiệu quả và độ chính xác cao hơn.
Cơ chế thứ hai là các mô hình lý luận lớn có được lợi thế khi độ phức tạp của vấn đề tăng lên vừa phải.
Cơ chế thứ ba là cả hai lớp mô hình đều bị giảm hiệu suất hoàn toàn khi vấn đề trở nên phức tạp hơn khi độ sâu kết hợp tăng lên.
(Nguồn: Bản đồ dữ liệu)
Đáng chú ý là gần điểm lỗi này, mặc dù các mô hình suy luận lớn đang chạy ở mức thấp hơn nhiều so với giới hạn độ dài thế hệ, chúng bắt đầu mất đi nỗ lực suy luận (được đo bằng số lượng mã thông báo tại thời điểm suy luận) khi độ phức tạp của vấn đề tăng lên.
(Nguồn: Bản đồ dữ liệu)
Điều này cho thấy có một giới hạn cơ bản đối với khả năng suy luận của các mô hình suy luận lớn: thời gian suy luận của chúng tăng trưởng đáng kể theo độ phức tạp của vấn đề.
Ngoài ra, thông qua phân tích các quỹ đạo suy luận trung gian, đội ngũ nghiên cứu đã phát hiện ra một hiện tượng thường xuyên liên quan đến tính phức tạp của vấn đề. Đó là, trong các vấn đề đơn giản hơn, mô hình suy luận thường có thể nhanh chóng tìm ra giải pháp sai , nhưng sẽ tiếp tục khám phá các tùy chọn sai một cách không hiệu quả. Hiện tượng này là những gì mọi người thường gọi là "suy nghĩ quá mức".
Trong các bài toán có độ phức tạp trung bình, mô hình cần phải khám phá rộng rãi lượng lớn các đường dẫn sai trước khi có thể tìm ra giải pháp đúng. Trên một ngưỡng độ phức tạp nhất định, mô hình không thể tìm ra giải pháp đúng.
Bai Ting, phó giáo sư tại Đại học Bưu chính Viễn thông Bắc Kinh, nói với DeepTech rằng tương tự như tư duy của con người, đối với các vấn đề phức tạp, mặc dù chúng ta không biết câu trả lời đúng là gì, nhưng chúng ta thường biết câu trả lời sai. Cụ thể, điều này liên quan đến quy mô của không gian giải pháp. Không gian giải pháp cho các vấn đề đơn giản thường nằm ở đầu cuối của đường dẫn tư duy một cách tự nhiên do chuỗi logic ngắn và khả năng khớp tính năng cao. Không gian giải pháp cho các vấn đề phức tạp đang mở rộng theo cấp số nhân vì nó liên quan đến sự ghép nối biến đa chiều và lồng ghép phân cấp logic. Không gian giải pháp rất lớn, về mặt khách quan thể hiện chính nó như một hậu tố tương đối trong chuỗi tư duy.
Chuyện gì xảy ra bên trong "trí óc" của mô hình lý luận?
Trong nghiên cứu này, hầu hết các thí nghiệm được tiến hành trên các mô hình suy luận và các đối tác không suy luận của chúng, chẳng hạn như Claude 3.7 Sonnet (có/không có suy luận) và DeepSeek-R1/V3. Đội ngũ nghiên cứu đã chọn các mô hình này vì, không giống như các mô hình như o- sê-ri của OpenAI, chúng cho phép truy cập vào các mã thông báo suy nghĩ.
Đối với mỗi trường hợp câu đố, đội ngũ nghiên cứu đã tạo ra 25 mẫu và báo cáo hiệu suất trung bình của từng mô hình.
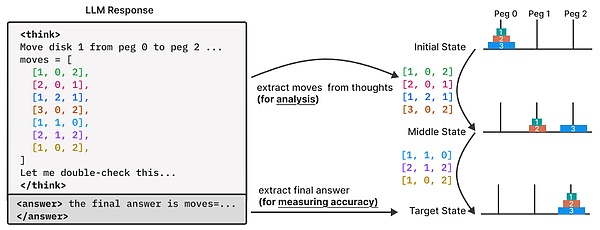
Để hiểu sâu hơn về quá trình tư duy của các mô hình lý luận, đội ngũ nghiên cứu đã tiến hành phân tích chi tiết dấu vết lý luận của chúng.
Trong giai đoạn này, họ đã xây dựng một hoàn cảnh thử nghiệm câu đố để đạt được phân tích độ sâu ngoài câu trả lời cuối cùng của mô hình, cho phép quan sát và phân tích chi tiết hơn về quỹ đạo lý luận (tức là "quá trình suy nghĩ") do mô hình tạo ra.
Cụ thể, họ đã sử dụng một trình mô phỏng câu đố để rút và phân tích các giải pháp trung gian được khám phá trong quá trình tư duy mô hình.
Sau đó, họ kiểm tra các mô hình và đặc điểm của các giải pháp trung gian này, tính chính xác của chúng so với vị trí tuần tự của chúng trong quá trình lý luận và cách các mô hình này phát triển khi độ phức tạp của vấn đề tăng lên.
Đối với phân tích này, đội ngũ nghiên cứu tập trung vào các dấu vết lý luận được tạo ra bởi mô hình lý luận Claude 3.7 Sonnet trong các thí nghiệm nhóm câu đố.
Đối với mỗi giải pháp trung gian được xác định trong dấu vết, đội ngũ nghiên cứu đã ghi lại những thông tin sau: (1) vị trí tương đối của nó trong quỹ đạo lý luận (được chuẩn hóa theo tổng chiều dài suy nghĩ), (2) tính đúng đắn của nó được xác minh bởi trình mô phỏng câu đố của đội ngũ nghiên cứu và (3) độ phức tạp của bài toán tương ứng.
Điều này cho phép đội ngũ nghiên cứu mô tả tiến trình và độ chính xác của quá trình hình thành giải pháp trong suốt quá trình suy luận.

Đội ngũ nghiên cứu phát hiện ra rằng đối với những vấn đề đơn giản hơn, mô hình lý luận thường tìm ra giải pháp đúng ngay từ đầu nhưng sau đó vẫn tiếp tục khám phá phương pháp không chính xác.
So với các giải pháp đúng (màu xanh lá cây), sự phân bố các giải pháp sai (màu đỏ) rõ ràng bị dịch chuyển về phía cuối Chuỗi. Khi độ phức tạp của vấn đề tăng lên vừa phải, xu hướng này đảo ngược: mô hình khám phá các giải pháp sai trước và chủ yếu đi đến giải pháp đúng sau trong quá trình suy nghĩ. Lần này, sự phân bố các giải pháp sai (màu đỏ) bị dịch chuyển xuống thấp hơn so với các giải pháp đúng (màu xanh lá cây).
Cuối cùng, đối với các vấn đề có độ phức tạp cao hơn, mô hình bắt đầu bị hỏng, nghĩa là mô hình không thể đưa ra bất kỳ giải pháp chính xác nào trong quá trình suy nghĩ.
Hình bên dưới trình bày phân tích bổ sung về độ chính xác của các giải pháp trong các phân đoạn trình tự suy nghĩ (khoảng thời gian) trong hoàn cảnh Tháp Hà Nội.

Có thể thấy rằng đối với những bài toán đơn giản hơn (giá trị N nhỏ hơn), độ chính xác của giải pháp có xu hướng giảm hoặc dao động khi suy nghĩ tiến triển, cung cấp thêm bằng chứng cho hiện tượng suy nghĩ quá mức.
Tuy nhiên, đối với các vấn đề phức tạp hơn, xu hướng này thay đổi—độ chính xác của giải pháp được cải thiện khi suy nghĩ tiến triển, cho đến khi đạt đến một ngưỡng nhất định. Vượt quá ngưỡng phức tạp này, trong "chế độ sụp đổ", độ chính xác của mô hình giảm xuống bằng không.
Bai Ting nói với DeepTech rằng mô hình cần phải lý giải lần trong các vấn đề phức tạp. Với tiền đề là không có giải pháp đúng, cơ chế lý giải mô hình có thể sử dụng lần lần lặp lại lý giải để tạo ra các chiến lược tối ưu hóa hiệu quả hoặc có thể là chiến lược bảo vệ tài nguyên để ngăn ngừa các lần lặp lại quá mức. Do đó, các phát hiện trong bài báo lần cần được phân tích và xác minh cẩn thận từ cấp độ triển khai mô hình.
Bai Ting chỉ ra rằng cũng có khả năng quá trình suy luận của các mô hình lớn về cơ bản là lời kêu gọi các mẫu bộ nhớ. Đối với các mô hình như DeepSeek-R1 và o3-mini, hiệu suất của chúng phụ thuộc rất nhiều vào phạm vi bao phủ của các mẫu bộ nhớ trong dữ liệu đào tạo. Khi độ phức tạp của vấn đề vượt quá ngưỡng bao phủ của mẫu bộ nhớ (chẳng hạn như hoàn cảnh câu đố có thể kiểm soát được do đội ngũ nghiên cứu của Apple thiết kế lần này), mô hình sẽ rơi vào trạng thái "độ chính xác bằng không".
Trong khi hoàn cảnh lần cho phép thực hiện các thí nghiệm được kiểm soát với khả năng kiểm soát chặt chẽ độ phức tạp của vấn đề, chúng chỉ đại diện cho một tập hợp nhỏ nhiệm vụ lý luận và có thể không nắm bắt được sự đa dạng của các vấn đề lý luận thực tế hoặc đòi hỏi nhiều kiến thức.
Cần lưu ý rằng nghiên cứu này chủ yếu dựa trên mô hình suy luận lớn biên giới đóng được truy cập thông qua API hộp đen. Hạn chế này ngăn cản đội ngũ nghiên cứu phân tích trạng thái nội bộ hoặc các thành phần kiến trúc của nó.
Hơn nữa, khi sử dụng trình mô phỏng câu đố xác định, đội ngũ cứu cho rằng lý luận có thể được xác minh hoàn hảo từng bước. Tuy nhiên, trong các miền ít có cấu trúc hơn, việc xác minh chính xác như vậy có thể khó đạt được, hạn chế khả năng chuyển giao phương pháp phân tích sang nhiều kịch bản lý luận hơn.
Nhìn chung, đội ngũ nghiên cứu đã kiểm tra các mô hình lý luận quy mô lớn tiên tiến theo góc nhìn về độ phức tạp của vấn đề thông qua hoàn cảnh giải quyết câu đố được kiểm soát. Kết quả này cho thấy những hạn chế của các mô hình hiện tại: nghĩa là, mặc dù có cơ chế tự phản ánh phức tạp, các mô hình này vẫn không thể phát triển khả năng lý luận tổng quát sau khi vượt quá ngưỡng phức tạp nhất định. Đội ngũ nghiên cứu cho rằng rằng kết quả lần có thể mở đường cho việc nghiên cứu khả năng lý luận của các mô hình này.






