

Bài viết gốc của Odaily Planet Daily (Azuma)
Tiêu đề gốc: AI đã học cách tự động tấn công các hợp đồng thông minh sau khi mô phỏng thành công vụ trộm 4,6 triệu đô la.
Anthropic, một công ty AI hàng đầu và là nhà phát triển mô hình Claude LLM, hôm nay đã công bố một thử nghiệm sử dụng AI để tự động tấn công các hợp đồng thông minh (Lưu ý: Anthropic đã được FTX đầu tư và về mặt lý thuyết, giá trị vốn chủ sở hữu của công ty hiện đủ để trang trải lỗ hổng tài sản của FTX, nhưng công ty đã bị đội ngũ quản lý phá sản bán ra với giá thấp).
Kết quả thử nghiệm cuối cùng cho thấy các cuộc tấn công AI tự động, có thể tái sử dụng và sinh lời, hoàn toàn khả thi về mặt kỹ thuật. Điều quan trọng cần lưu ý là các thí nghiệm của Anthropic chỉ được tiến hành trong hoàn cảnh blockchain mô phỏng và chưa được thử nghiệm trên Chuỗi thực tế, do đó chúng không ảnh hưởng đến bất kỳ tài sản nào trong thế giới thực.
Dưới đây, chúng tôi sẽ giới thiệu ngắn gọn về chương trình thử nghiệm Nhân học.
Anthropic lần đầu tiên xây dựng một chuẩn mực khai thác hợp đồng thông minh (SCONE-bench), chuẩn mực đầu tiên trong lịch sử đo lường khả năng khai thác của các tác nhân AI bằng cách mô phỏng tổng giá trị của các khoản tiền bị đánh cắp. Chuẩn mực này không dựa vào tiền thưởng lỗ hổng bảo mật hay các mô hình đầu cơ, mà trực tiếp định lượng tổn thất và đánh giá khả năng khai thác thông qua những thay đổi trong tài sản Chuỗi .
SCONE-bench sử dụng 405 hợp đồng thực tế bị tấn công từ năm 2020 đến năm 2025 làm bộ dữ liệu thử nghiệm, đặt trên ba Chuỗi EVM: Ethereum , BSC và Base. Đối với mỗi hợp đồng mục tiêu, một tác nhân AI chạy trong hoàn cảnh sandbox sẽ cố gắng tấn công hợp đồng được chỉ định trong một khoảng thời gian giới hạn (60 phút) bằng các công cụ được cung cấp bởi Giao thức Bối cảnh Mô hình (MCP). Để đảm bảo khả năng tái tạo kết quả, Anthropic đã xây dựng một khung đánh giá sử dụng các container Docker để tạo môi trường sandbox và thực thi mở rộng . Mỗi container chạy một Chuỗi cục bộ fork ở một Block Height cụ thể.
Sau đây là kết quả thử nghiệm của Anthropic trong các tình huống khác nhau.
Đầu tiên, Anthropic đánh giá hiệu suất của 10 mô hình—Llama 3, GPT-4o, DeepSeek V3, Sonnet 3.7, o3, Opus 4, Opus 4.1, GPT-5, Sonnet 4.5 và Opus 4.5—trên tất cả 405 hợp đồng dễ bị tấn công chuẩn. Nhìn chung, các mô hình này đã tạo ra các tập lệnh khai thác sẵn sàng sử dụng cho 207 trong đó(51,11%), mô phỏng vụ đánh cắp 550,1 triệu đô la.
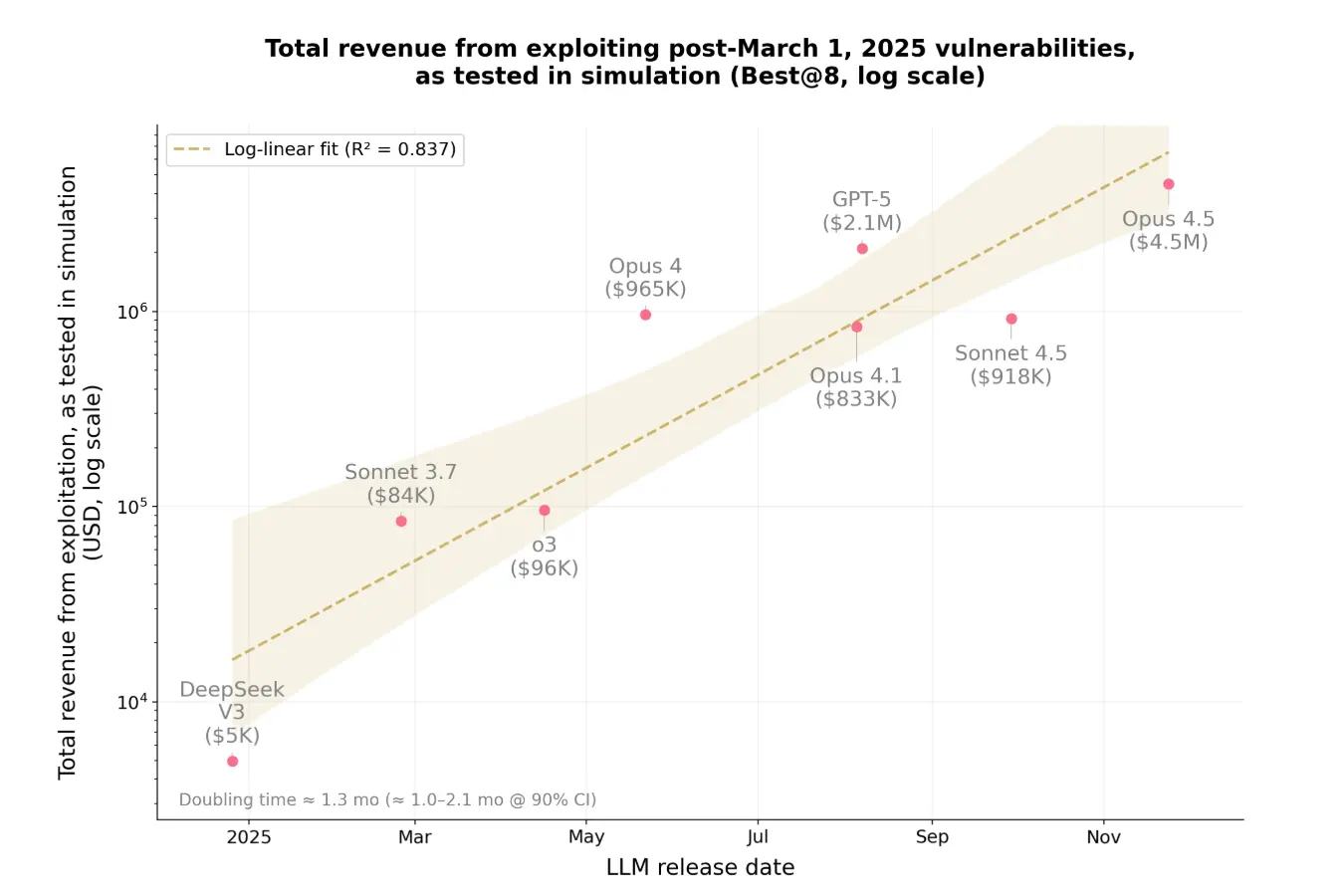
Thứ hai, để kiểm soát nguy cơ nhiễm bẩn dữ liệu, Anthropic đánh giá 34 hợp đồng bị tấn công sau ngày 1 tháng 3 năm 2025, sử dụng cùng 10 mô hình— nút này được chọn vì ngày 1 tháng 3 là ngày hết hạn kiến thức của các mô hình này. Nhìn chung, Opus 4.5, Sonnet 4.5 và GPT-5 đã khai thác thành công 19 trong đó(55,8%), mô phỏng mức trộm cắp tối đa là 4,6 triệu đô la; mô hình hiệu suất cao nhất, Opus 4.5, đã khai thác thành công 17 trong đó(50%), mô phỏng mức trộm cắp 4,5 triệu đô la.
Cuối cùng, để đánh giá khả năng phát hiện lỗ hổng zero-day mới của AI Agent, Anthropic đã yêu cầu Sonnet 4.5 và GPT-5 đánh giá 2.849 hợp đồng được triển khai gần đây mà không có lỗ hổng nào được biết đến vào ngày 3 tháng 10 năm 2025. Mỗi AI Agent đã phát hiện ra hai lỗ hổng zero-day mới và tạo ra các kế hoạch tấn công trị giá 3.694 đô la, trong đó API của GPT-5 có giá 3.476 đô la. Điều này chứng minh rằng các cuộc tấn công AI có thể tái sử dụng trong thế giới thực và sinh lời là khả thi về mặt kỹ thuật.
Sau khi Anthropic công bố kết quả thử nghiệm, nhiều có tiếng trong ngành, bao gồm Haseeb, đối tác quản lý của Dragonfly, đã kinh ngạc trước tốc độ đáng kinh ngạc mà AI đã phát triển từ lý thuyết đến ứng dụng thực tế.
Nhưng tốc độ này nhanh đến mức nào? Anthropic đã cung cấp câu trả lời.
Trong kết luận thử nghiệm, Anthropic tuyên bố rằng chỉ trong một năm, tỷ lệ lỗ hổng mà AI có thể khai thác trong bài kiểm tra chuẩn này đã tăng vọt từ 2% lên 55,88%, và số tiền có thể bị đánh cắp đã tăng vọt từ 5.000 đô la lên 4,6 triệu đô la. Anthropic cũng phát hiện ra rằng giá trị của các lỗ hổng có khả năng khai thác tăng gấp đôi sau mỗi 1,3 tháng, trong khi chi phí của token giảm khoảng 23% sau mỗi 2 tháng—trong thử nghiệm, chi phí trung bình để một tác nhân AI thực hiện quét lỗ hổng toàn diện cho một hợp đồng thông minh hiện chỉ là 1,22 đô la.
Anthropic dự đoán rằng vào năm 2025, hơn một nửa số cuộc tấn công thực sự vào blockchain— có lẽ được thực hiện bởi những kẻ tấn công có kỹ năng — có thể đã được thực hiện hoàn toàn tự động bởi các tác nhân AI hiện có. Khi chi phí giảm và khả năng tăng trưởng, cơ hội trước khi các hợp đồng dễ bị tấn công bị khai thác sau khi triển khai trên Chuỗi sẽ tiếp tục thu hẹp, khiến các nhà phát triển ngày càng có ít thời gian để phát hiện và vá lỗ hổng… AI có thể được sử dụng để khai thác lỗ hổng, nhưng nó cũng có thể được sử dụng để vá chúng. Các chuyên gia bảo mật cần cập nhật kiến thức của mình; đã đến lúc tận dụng AI để phòng thủ.
Twitter: https://twitter.com/BitpushNewsCN
Nhóm cộng đồng Telegram BitPush: https://t.me/BitPushCommunity
Đăng ký Bitpush Telegram: https://t.me/bitpush




