

Thuật toán chi tiêu chung thất bại thảm hại trong thử nghiệm ngoài mẫu mới.
Thuật toán chi tiêu đồng thời, nền tảng của phân tích pháp y blockchain, thể hiện hành vi trong các thí nghiệm được kiểm soát gây ra những lo ngại nghiêm trọng về độ tin cậy của nó. Cụ thể, nó phát hiện cấu trúc và tín hiệu ở những nơi không hề tồn tại và cho thấy sự thiếu chính xác đáng báo động nói chung.
Điều này có ý nghĩa quan trọng không chỉ đối với việc phân tích pháp y blockchain mà còn đối với toàn bộ hệ sinh thái pháp lý và tuân thủ tài sản kỹ thuật số. Phương pháp phán đoán đơn lẻ này là nền tảng của các công ty dịch vụ phân tích pháp y và tuân thủ lớn nhất trong ngành và hỗ trợ nhiều vụ kiện pháp lý trên toàn thế giới. Trong thử nghiệm ngoài mẫu đầu tiên về hiệu suất của phương pháp phán đoán này, chúng tôi tin rằng kết quả cho thấy những hạn chế đáng kể.
Việc một kỹ thuật được công bố lần đầu vào năm 2013 và được các cơ quan thực thi pháp luật sử dụng rộng rãi kể từ đó lại chỉ được kiểm chứng độ chính xác công khai vào năm 2025 và trên một tập dữ liệu mẫu rất nhỏ đã là điều đáng lo ngại.
Điều đáng chú ý là một kỹ thuật được công bố lần đầu vào năm 2013 và được các cơ quan thực thi pháp luật sử dụng rộng rãi trong những năm tiếp theo lại chỉ có kết quả kiểm định độ chính xác công khai đầu tiên được công bố vào năm 2025, trên một tập dữ liệu tương đối nhỏ. Hơn nữa, việc so sánh kết quả ngoài mẫu của chúng tôi với các nghiên cứu trong mẫu trước đó cho thấy các dấu hiệu phù hợp với hiện tượng quá khớp dữ liệu. Điều này cho thấy các phương pháp kiểm định có thể cần được cải thiện trong toàn ngành, vì người dùng và nhà cung cấp dịch vụ có thể không xác thực đầy đủ các công cụ của họ hoặc có thể thu được kết quả khác biệt đáng kể.
Đây là những tuyên bố có cơ sở. Sau đây là kế hoạch của chúng tôi để chứng minh chúng:
- Hãy giải thích ngắn gọn sự khác biệt giữa kiểm thử trong mẫu và kiểm thử ngoài mẫu.
- Trình bày một sơ đồ đơn giản mà chúng tôi đã phát triển để xây dựng dữ liệu kiểm thử ngoài mẫu.
- Tóm tắt kết quả thử nghiệm của chúng tôi so với các kết quả mẫu trước đó.
- Bình luận về những tác động
Bài báo chi tiết với đầy đủ dữ liệu có thể được tìm thấy tại đây .
Công trình này dựa trên nghiên cứu trước đây của chúng tôi cho thấy rằng Coinjoin đã trở nên phổ biến trên Bitcoin kể từ năm 2009 , điều này đã dẫn chúng tôi đến việc đệ trình một bản kiến nghị với tư cách là bên thứ ba (Amicus Brief) lập luận rằng thuật toán đồng chi tiêu cần được kiểm tra nghiêm ngặt hơn trước khi được trình bày trước tòa án như một phương pháp pháp y với tỷ lệ sai sót tối thiểu, như đã xảy ra trong vụ US v Sterlingov .
Sau đó, chúng tôi đã phát triển kỹ thuật chuyển đổi các giao dịch ZK Mixer thành giao dịch Coinjoin , tạo điều kiện cho nghiên cứu này.
Chúng tôi xem đây như một bài tập khoa học nhằm đánh giá một thuật toán phân loại, tương tự như các thử nghiệm mô hình khác. Điều chúng tôi không lường trước được là lại tìm thấy sự khác biệt rõ rệt như vậy về hiệu suất ngoài mẫu.
Giả thuyết ban đầu của chúng tôi là độ tin cậy của phương pháp phán đoán nhanh sẽ hỗ trợ các yêu cầu cung cấp thông tin từ các cơ quan thực thi pháp luật đối với các doanh nghiệp trung gian như các sàn giao dịch, và kết quả sẽ đủ để đáp ứng các yêu cầu về lệnh khám xét và các quy trình pháp lý tương tự dựa trên "căn cứ hợp lý".
Chúng tôi cũng dự đoán sẽ tìm thấy mức độ tin cậy cần có bằng chứng xác thực để đáp ứng các tiêu chuẩn pháp lý khắt khe hơn. Tuy nhiên, chúng tôi rất ngạc nhiên khi thấy tỷ lệ sai sót dường như chỉ là những phỏng đoán thiếu cơ sở và không nên được sử dụng để hỗ trợ bất kỳ hoạt động thực thi pháp luật nào.
Đây chỉ là một nghiên cứu đơn lẻ và chúng tôi không khẳng định các đặc điểm hiệu suất này có thể khái quát hóa cho tất cả các trường hợp hoặc nhất thiết là cho các trường hợp quan trọng nhất.
Một nghiên cứu sử dụng một phương pháp cụ thể để kiểm tra dữ liệu ngoài mẫu không làm cho kỹ thuật đó trở nên vô giá trị. Tuy nhiên, nó cho thấy cần phải kiểm tra nghiêm ngặt hơn và xem xét lại cách hệ thống pháp luật đánh giá phân tích dữ liệu blockchain.
Ngay cả khi bỏ qua những phát hiện cụ thể của chúng tôi, việc các cuộc thử nghiệm toàn diện kiểu này chỉ xuất hiện hơn một thập kỷ sau khi các cơ quan thực thi pháp luật bắt đầu sử dụng chúng là một vấn đề đáng lo ngại.
Kiểm tra trong mẫu so với kiểm tra ngoài mẫu
Khi phát triển mô hình cho bất kỳ nhiệm vụ nào, người ta phải bắt đầu với dữ liệu. Đối với mô hình phân loại — mô hình gán nhãn cho các điểm dữ liệu đầu vào — dữ liệu này phải bao gồm một tập hợp các điểm đầu vào với các nhãn có thể xác định được một cách độc lập và khách quan.
Hãy tưởng tượng bạn xây dựng một mô hình nhận ảnh chân dung làm đầu vào và cho ra màu tóc của đối tượng. Để huấn luyện và đánh giá mô hình, bạn cần một quy trình để dán nhãn màu tóc cho mỗi bức ảnh. Bạn sẽ cần dữ liệu "chuẩn vàng" với độ chính xác dán nhãn 100%.
Nếu bạn huấn luyện mô hình của mình trên 100 bức ảnh và sau đó kiểm tra hiệu suất trên chính 100 bức ảnh đó, thì đây được gọi là kiểm thử "trong mẫu".
Nếu bạn sử dụng cùng một mô hình đó và thử nghiệm trên 100 bức ảnh khác nhau — những bức ảnh chưa từng được công bố trước đây, trong đó ai đó đã dán nhãn màu tóc chính xác — đó là thử nghiệm “ngoài mẫu”.
Nhìn chung, chúng ta kỳ vọng hiệu năng ngoài mẫu sẽ kém hơn hiệu năng trong mẫu. Một kỹ sư so sánh hai mô hình với tổng cộng 200 bức ảnh được gắn nhãn thường sẽ:
- Huấn luyện mỗi mô hình trên 100 bức ảnh được chọn ngẫu nhiên.
- Đánh giá hiệu suất trên 100 bức ảnh còn lại.
- Lặp lại thao tác này 100 lần.
- So sánh hiệu năng trung bình ngoài mẫu của hai mô hình.
Mối lo ngại tiềm ẩn trong quy trình này là việc huấn luyện và kiểm tra quá mức trên cùng một tập dữ liệu có thể dẫn đến hiện tượng "quá khớp" (overfitting).
Mô hình có thể nhận diện những đặc điểm không mong muốn như màu áo, màu mắt, chủng tộc hoặc các đặc điểm khác có trong dữ liệu của đối tượng.
Điều quan trọng là, kiểu quá khớp dữ liệu và sai lệch mô hình do đó gây ra không đòi hỏi bất kỳ sự thiên vị hay nỗ lực có ý thức nào từ phía các kỹ sư.
Nếu tất cả những người tóc vàng trong tập dữ liệu của bạn đều có mắt xanh, bạn không thể xác định liệu mô hình đã học cách phát hiện tóc vàng hay mắt xanh.
Nếu mọi người tóc vàng đều là nam giới, có ria mép, hoặc có một số đặc điểm nhận dạng khác, thì mô hình có thể bị thiên vị mà không cần các kỹ sư mắc bất kỳ lỗi nào.
Tương tự, nếu một công ty chỉ có 200 bức ảnh và dành nhiều năm để xây dựng mô hình, thì không có thử nghiệm nào được thực hiện đúng cách theo kiểu “thử nghiệm ngoài mẫu”. Các kỹ sư đưa ra quyết định dựa trên hiệu suất được đo lường thông qua quy trình trên, mà quy trình này vẫn dựa vào chính 200 bức ảnh đó.
Giờ hãy thử tưởng tượng với 200.000 bức ảnh, hàng trăm kỹ sư và một thập kỷ xây dựng mô hình. Lúc này, có vẻ như tất cả các công cụ đều phụ thuộc vào các đặc điểm trong tập dữ liệu mà con người không thể phát hiện ra nhưng máy tính lại liên tục nhận diện được.
Đối với ảnh chụp, điều này hoàn toàn khả thi vì nguồn cung cấp ảnh đã được dán nhãn gần như vô hạn.
Điều tương tự cũng đúng với hầu hết các mẫu ADN, dấu vân tay và nhiều đối tượng pháp y khác vì bạn luôn có thể thu thập thêm dữ liệu. Đối với súng đo tốc độ bằng radar, bạn có thể dễ dàng tiến hành các thí nghiệm mới. Dữ liệu thử nghiệm rất phong phú trong những trường hợp này.
Nhưng nếu mô hình của bạn nghiên cứu một căn bệnh cực kỳ hiếm gặp, quá trình giao phối của gấu trúc, nhật thực hoặc thời tiết khắc nghiệt thì sao?
Việc thu thập thêm dữ liệu trong những trường hợp như vậy không hề dễ dàng.
Những thử nghiệm đầu tiên về Thuyết Tương đối Tổng quát đòi hỏi phải chờ đợi các loại nhật thực cụ thể. Sau đó, các nhà vật lý đã dành hàng thập kỷ để thiết kế các thử nghiệm tốt hơn, đáng tin cậy hơn và có thể lặp lại hơn về lý thuyết này. Thiết kế thử nghiệm thông minh là một thành phần cốt lõi của khoa học.
Phương pháp phân tích chi tiêu đồng thời thường được sử dụng để phân tích các dịch vụ blockchain bất hợp pháp, nơi mà nhãn chỉ có sẵn sau khi chính phủ đã bắt giữ hoặc tịch thu mã phần mềm, máy chủ hoặc nhật ký. Điều này tạo ra một tập dữ liệu hạn chế, nơi mà nhiều năm làm việc có thể được thực hiện với cùng một tập hợp mẫu nhỏ, khiến bất kỳ phân tích nào cũng thực chất chỉ là kiểm thử trong mẫu.
Điều này hoàn toàn khác với xét nghiệm ADN, trong đó kỹ thuật dùng để kết tội tội phạm có thể được kiểm tra ngoài mẫu bằng cách sử dụng mẫu máu từ bất kỳ nguồn nào.
Công trình nghiên cứu này của chúng tôi nhằm mục đích thiết kế các bài kiểm tra ngoài mẫu mạnh mẽ hơn cho trường hợp đầy thách thức này. Chúng tôi thừa nhận phương pháp của mình không hoàn hảo và có những sự thỏa hiệp và hạn chế.
Tuy nhiên, một phương án khác là giới hạn nghiên cứu chỉ trong phạm vi các dịch vụ do cơ quan thực thi pháp luật quản lý, điều này về cơ bản là một bài tập thiếu tính khoa học.
Làm sao có thể xác định xem các công cụ có hiệu quả đối với những tên tội phạm vẫn đang lẩn trốn — những kẻ mà lực lượng thực thi pháp luật đang tích cực truy đuổi — nếu việc thử nghiệm chỉ có thể diễn ra sau khi bắt giữ?
Sự kết hợp đồng nhất — Sự đồng cấu bộ trộn ZK
Công việc của chúng tôi được xây dựng dựa trên phương pháp chuyển đổi dữ liệu ZK Mixer trên Ethereum thành dạng mã hóa Coinjoin tương tự Bitcoin. Điều này được trình bày chi tiết trong một bài báo mà chúng tôi vừa công bố, cung cấp các định nghĩa và thuật toán cẩn thận, chỉ rõ cách chuyển đổi giữa ZK Mixer và Coinjoin. Để biết thêm chi tiết, vui lòng tham khảo bài báo đó. Ở đây, chúng tôi phác thảo quy trình một cách đủ để bạn hiểu rõ.
Một Coinjoin có nhiều đầu vào và nhiều đầu ra. Giả sử hiện tại tổng đầu vào bằng tổng đầu ra. Chúng ta có thể chuyển đổi điều này thành một chuỗi các giao dịch trộn bằng cách đưa tất cả các đầu vào vào một địa chỉ chung duy nhất và sau đó phân phối tất cả các đầu ra từ địa chỉ đó. Đây là cách một bộ trộn hoạt động.
Với các máy trộn thực tế, chúng ta không kỳ vọng vào mô hình "đổ đầy và rút hết" với số dư bằng không, sau đó tăng cao, rồi lại trở về không. Thay vào đó, chúng ta kỳ vọng số dư ổn định bên trong máy trộn sẽ vượt xa bất kỳ giao dịch riêng lẻ nào.
Điều này có thể đạt được bằng cách kết hợp các thao tác này lại với nhau theo kiểu xen kẽ.
Nếu Coinjoin đầu tiên chỉ rút 10% số dư, hãy chuyển 90% còn lại vào “Coinjoin” tiếp theo và lặp lại. Chuỗi Coinjoin theo cách này, trong đó các khoản tiền gửi và rút riêng lẻ nhỏ hơn số dư được chuyển giữa các vòng, là cách các dịch vụ trộn tiền dựa trên Coinjoin hoạt động.
Quá trình ánh xạ ngược giờ đây đã trở nên rõ ràng.
Chia tất cả các giao dịch ZK Mixer thành các nhóm gồm các giao dịch liên tiếp cùng phía. Có 7 lần nạp tiền liên tiếp mà không có lần rút tiền nào không? Nếu có, đó sẽ tạo thành một lô gồm 7 giao dịch.
Bốn lần rút tiền liên tiếp mà không có tiền gửi? Lại thêm một đợt nữa.
Sau đó, tạo các Coinjoin từ các cặp liên tiếp của các lô này, đồng thời giữ nguyên số dư còn lại.
Đó là toàn bộ quy trình.
Quy trình này khá đơn giản. Coinjoin hoạt động bằng cách chuyển tiền đồng thời giữa hai nhóm lớn riêng biệt, sao cho tất cả các khoản đầu ra đều được lấy từ tất cả các khoản đầu vào. Việc thực hiện chuỗi này nhiều lần có nghĩa là tất cả các khoản đầu ra đều bắt nguồn từ một tập hợp đầu vào lớn và khác biệt đến mức không thể dễ dàng xác định trách nhiệm riêng lẻ cho từng khoản đầu vào. Điều này giúp trộn lẫn tiền một cách hiệu quả trong quá trình thực hiện Coinjoin.
Các công ty ZK Mixer thể hiện điều này một cách rõ ràng bằng cách gộp chung tiền vào một tài khoản chung.
Việc vận hành loại dịch vụ này theo cách thủ công tương đối đơn giản.
Sự phức tạp về mặt kỹ thuật nằm ở việc đảm bảo một số sự kết hợp nhất định của các yếu tố sau:
- Các hồ sơ bị tiêu hủy nhanh đến mức không chính phủ nào có thể khôi phục lại được;
- Mức độ ẩn danh đủ cao giúp ngăn chặn việc xác định nguồn gốc hoạt động của dịch vụ; và
- Các hồ sơ hiện có không đủ để liên kết đầu vào với đầu ra.
Ý tưởng đằng sau ZK Mixers là chỉ dựa vào hồ sơ công khai là không đủ để truy tìm thông tin đáng tin cậy và không có nhà điều hành nào sở hữu thông tin đặc quyền. Điều này đòi hỏi sự tinh vi về mặt kỹ thuật. Tuy nhiên, cần lưu ý hai điều.
Thứ nhất, thông tin cần thiết để giải mã danh tính người dùng là hoàn toàn có thể. Hệ thống này là "ZK" (zero-knowledge), nghĩa là thông tin công khai chứa bằng chứng quyền sở hữu nhưng không tiết lộ bất cứ điều gì về khoản tiền gửi đến. Tuy nhiên, nếu bạn biết máy tính nào đã tạo ra những bằng chứng đó và vị trí của chúng trước khi gửi để rút tiền, thì việc giải mã danh tính là có thể. Các bằng chứng này là bằng chứng không tiết lộ thông tin (zero-knowledge), nhưng thông tin đó vẫn tồn tại trong vũ trụ.
Thứ hai, một đơn vị điều hành trung tâm đặt tại một địa điểm an toàn sẽ hoạt động hiệu quả ngay cả khi không ai có thể truy cập hoặc buộc tiết lộ hồ sơ. Chúng ta chỉ đo lường các hồ sơ công khai, chứ không phải toàn bộ thông tin trong "hệ thống" nói chung.
Truy tìm nguồn gốc là một quá trình tái tạo thông tin từ các nguồn công khai. Trong khuôn khổ này, các kỹ thuật đó cung cấp khả năng che giấu tương đương.
Kết quả kiểm tra
Như đã thảo luận ở trên, nhìn chung chúng ta kỳ vọng hiệu năng ngoài mẫu sẽ kém hơn hiệu năng trong mẫu.
Tuy nhiên, chúng ta cũng quan tâm đến sự khác biệt giữa hiệu năng ngoài mẫu và hiệu năng trong mẫu.
Nếu ta quan sát thấy mô hình không bao giờ mắc một loại lỗi nhất định nào đó trong tập dữ liệu mẫu nhưng lại thường xuyên mắc lỗi đó ngoài tập dữ liệu mẫu, ta có lý do để nghi ngờ hiện tượng quá khớp (overfitting).
Ví dụ, nếu một mô hình không bao giờ bỏ sót tóc vàng trong tập dữ liệu huấn luyện nhưng lại không hoạt động tốt hơn so với việc đoán ngẫu nhiên ngoài tập dữ liệu huấn luyện, chúng ta có thể xem xét màu mắt, giới tính, râu, trang phục, chủng tộc hoặc các yếu tố thiên vị khác có thể có trong dữ liệu huấn luyện. Bản thân hành vi đó cung cấp một manh mối tuyệt vời cho thấy có vấn đề, ngay cả khi tỷ lệ lỗi không xác định được vấn đề là gì.
Những gì chúng tôi nhận thấy với thuật toán chi tiêu chung không chỉ là hiệu suất kém hơn khi kiểm tra ngoài mẫu, mà còn là hiệu suất kém hơn đáng kể. Hơn nữa, chúng tôi phát hiện ra rằng một loại lỗi nhất định — "lỗi dương tính giả" trong đó thuật toán phân loại sai một địa chỉ là nằm trong một cụm — gần như không xuất hiện trong mẫu nhưng lại xuất hiện với tỷ lệ đôi khi vượt quá 50% khi kiểm tra ngoài mẫu.
Ít nhất, những kết quả này cho thấy cần phải thử nghiệm phương pháp phỏng đoán này nhiều hơn nữa. Kết quả của chúng tôi cũng chứng minh rằng trong một số điều kiện nhất định, phương pháp phỏng đoán này bộc lộ những hạn chế đáng kể.
Trong mẫu
Chainalysis, nhà cung cấp lâu đời nhất và lớn nhất các công cụ được xây dựng dựa trên thuật toán đồng chi tiêu, đã trích dẫn một nghiên cứu duy nhất kiểm tra ba dịch vụ bất hợp pháp bị phát hiện và đo lường “tỷ lệ dương tính giả” (FPR) và “tỷ lệ âm tính giả” (FNR) cho mỗi dịch vụ. “Dương tính giả” được định nghĩa ở trên, và “âm tính giả” đề cập đến các trường hợp địa chỉ đáng lẽ phải được đưa vào một cụm lại bị loại khỏi cụm đó.
Nghiên cứu đó — vốn được ca ngợi như một bằng chứng về độ chính xác — đã đưa ra các kết quả sau:
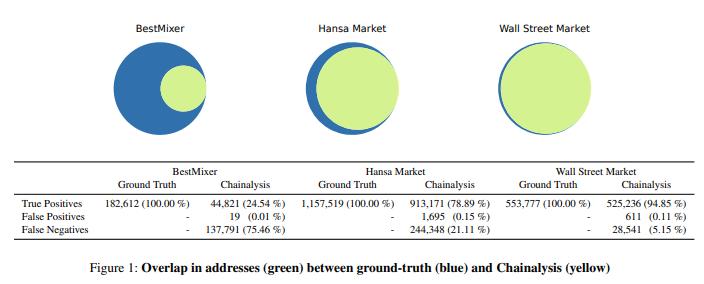
Tỷ lệ dương tính giả (FPR) gần như bằng 0 trong mọi trường hợp, trong khi tỷ lệ âm tính giả (FNR) thay đổi: 5%, 21% hoặc 75%. Điều này cho thấy khả năng xảy ra vấn đề quá khớp dữ liệu vì thuật toán phỏng đoán thường xuyên mắc một loại lỗi và hiếm khi mắc loại lỗi khác.
Người ta thường kỳ vọng một công cụ hoạt động tốt sẽ gặp lỗi với tần suất tương tự nhau ở cả hai chiều — không nhất thiết là tỷ lệ 1:1, nhưng chắc chắn không phải là 7.250:1 như trường hợp của BestMixer.
Điều đáng chú ý là một tỷ lệ lỗi tiến gần đến 0 trong khi tỷ lệ lỗi khác đạt tới 75%. Mô hình này cho thấy các kỹ sư có thể đã tối ưu hóa chủ yếu để giảm thiểu tỷ lệ lỗi dương tính giả (FPR).
Trước khi kết luận "tỷ lệ dương tính giả thấp là chấp nhận được", hãy nhận ra rằng việc tinh chỉnh mô hình để đạt tỷ lệ dương tính giả gần bằng 0 có thể vô tình gây ra hiện tượng quá khớp hoặc các vấn đề khác biểu hiện dưới dạng hiệu suất khác nhau trên các tập dữ liệu khác nhau.
Việc giảm tỷ lệ sai sót dương tính giả (FPR) xuống 0 đối với bộ dò tóc vàng có thể dẫn đến một mô hình dựa vào màu mắt, chủng tộc hoặc các yếu tố khác. Cũng như mọi mô hình hóa khác, cách khắc phục vấn đề này là kiểm tra bằng dữ liệu chưa từng thấy trước đây và xem xét lại các giả định.
Ngoài mẫu
Để thu thập dữ liệu ngoài mẫu, chúng tôi đã kiểm tra 10 trường hợp Tornado Cash trên Ethereum, bao gồm 4 token ERC-20 khác nhau. Chi tiết đầy đủ về tiêu chí lựa chọn và ứng dụng thuật toán heuristic của chúng tôi được cung cấp trong bài báo. Dưới đây là FPR và FNR từ các thử nghiệm của chúng tôi:
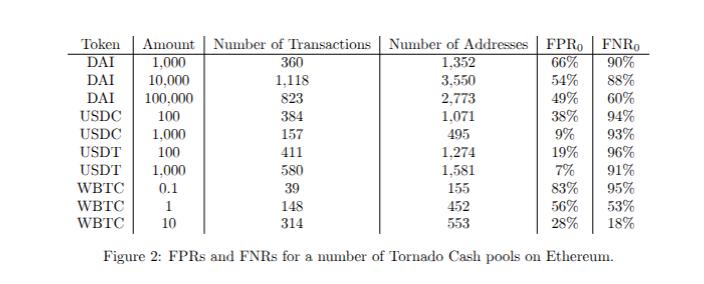
Chúng tôi nhận thấy tỷ lệ dương tính giả (FPR) nằm trong khoảng từ 7% đến 83% và tỷ lệ âm tính giả (FNR) từ 18% đến 96%. Đúng như dự đoán, các kết quả này tệ hơn so với kết quả trong mẫu. Chúng cũng cho thấy những hạn chế đáng kể về hiệu suất.
Đối với một máy trộn (loại nhỏ nhất mà chúng tôi đã kiểm tra), chúng tôi nhận thấy FPR là 83% và FNR là 95%. Kết quả này rất tệ, và một công cụ thể hiện các đặc tính hiệu suất như vậy không chỉ không phù hợp cho ứng dụng pháp y, mà còn không hơn gì một phỏng đoán thiếu chính xác.
Tình hình sẽ còn tệ hơn.
Quy trình của chúng tôi tạo ra các giao dịch giống Bitcoin, trong đó có một cụm lớn duy nhất — Tornado Cash — và mọi địa chỉ khác là một cụm gồm 1 địa chỉ. Chúng tôi có thể xác minh điều này vì chúng tôi có thể đọc mã Tornado Cash và chúng tôi đã viết phần mềm dịch. Trong mọi trường hợp, cụm lớn nhất phải là cụm trộn và lý tưởng nhất là chỉ nên chứa các địa chỉ trộn. Lý tưởng nhất là không có cụm nào khác nên chứa địa chỉ trộn.
Dưới đây là kích thước cụm (màu xanh lam) và số lượng địa chỉ dịch vụ trong cụm (màu đỏ) cho 100 cụm lớn nhất được xác định từ 10.000 phiên bản DAI Tornado Cash:
Điều này dễ dàng nhận thấy ngay lập tức rằng:
- Hầu hết các địa chỉ dịch vụ đều nằm trong các cụm lớn nhất.
- Các cụm đó thường chứa nhiều địa chỉ không thuộc dịch vụ.
- Có một phần đuôi dài gồm các cụm địa chỉ nhỏ không phải là các địa chỉ đơn lẻ.
- Địa chỉ dịch vụ được phân bổ rải rác trong nhiều cụm máy chủ đó.
Đây không phải là một thất bại hoàn toàn vì thuật toán phỏng đoán ít nhất cũng phát hiện ra được điều gì đó liên quan đến một dịch vụ. Tuy nhiên, thuật toán này đang trộn lẫn địa chỉ dịch vụ với địa chỉ không phải dịch vụ, và nó xác định nhiều dịch vụ trong khi đáng lẽ chỉ nên tìm thấy một.
Phần mềm cũng đang xác định các mẫu liên quan đến dịch vụ, mặc dù không hoàn hảo. Điều này cho thấy thuật toán phỏng đoán có thể hoạt động tốt trong một số ngữ cảnh nhưng bị hạn chế về khả năng áp dụng tổng quát.
Chúng tôi chắc chắn không khẳng định phương pháp phỏng đoán này tạo ra kết quả ngẫu nhiên vì có cấu trúc có thể quan sát được liên quan đến câu trả lời đúng. Nhưng nó chỉ hữu ích khi việc phát hiện cụm lớn nhất, nơi một nửa số địa chỉ chứa trong đó thuộc về dịch vụ, hiệu quả hơn so với việc chỉ đoán mò.
Hãy nhớ rằng, tỷ lệ dương tính giả 50% không giống như tung đồng xu trong nhiệm vụ này vì có nhiều hơn 2 kết quả có thể xảy ra. Tuy nhiên, nó thể hiện hiệu suất đáng lo ngại đối với một công cụ pháp y được thiết kế để sử dụng tại tòa án và được chấp nhận làm bằng chứng.
Bài báo này cung cấp các kết quả đó cho tất cả 10 bộ trộn. Đối với tất cả các bộ trộn DAI mà chúng tôi đã kiểm tra, đây là tỷ lệ phần trăm của mỗi cụm được xác định bao gồm các địa chỉ Tornado Cash:
Mỗi màu sắc đại diện cho một máy trộn khác nhau, với 100 cụm lớn nhất được trình bày từ trái sang phải. Những chi tiết này chỉ là thứ yếu so với kết quả chính. Kết quả lý tưởng sẽ là một giá trị 100% duy nhất ở bên trái cho mỗi màu và sau đó là tất cả các giá trị bằng không.
Thay vào đó, chúng tôi quan sát thấy sự phân bố tỷ lệ chủ yếu nằm trong khoảng từ 20% đến 80% trên 100 cụm cho mỗi bộ trộn. Thuật toán phỏng đoán này không đáp ứng được các tiêu chuẩn hiệu suất mong đợi trong các thử nghiệm này.
Trong bài báo này, chúng tôi trình bày chính xác định nghĩa về thành công và sau đó đưa ra dữ liệu cho thấy rõ ràng rằng không có ví dụ nào trong số những ví dụ được xem xét đáp ứng được định nghĩa đó.
So sánh
Việc tìm thấy tỷ lệ dương tính giả (FPR) gần bằng 0 cùng với tỷ lệ âm tính giả (FNR) lớn hơn đáng kể trong mẫu cho thấy hiện tượng quá khớp dữ liệu. Phân tích ngoài mẫu của chúng tôi chứng minh rằng tỷ lệ FPR thấp không thể khái quát hóa cho ít nhất một số tập dữ liệu mới. Điều này cung cấp bằng chứng thống kê phù hợp với hiện tượng quá khớp dữ liệu.
Để làm rõ điều này, chúng ta hãy quay lại với ví dụ về việc nhận biết màu tóc.
Một kỹ sư cung cấp một chiếc hộp đen, tuyên bố nó có khả năng nhận diện tóc vàng trong ảnh. Nghiên cứu của họ cho thấy rằng khi thiết bị báo hiệu "có tóc vàng", thì thực tế có tóc vàng trong ảnh đến 99,9%.
Tuy nhiên, khi sử dụng cùng một hộp đen đó với ảnh những người tóc vàng được chọn từ các ví dụ của chính kỹ sư, nó thường không xác định chính xác màu tóc. Khi nó nói "tóc vàng", thì luôn đúng. Nhưng khi bạn cung cấp ảnh người tóc vàng, kết quả thường không chính xác, lúc đó bạn có thể đã nghi ngờ có điều gì đó không ổn với công cụ này.
Sau đó, bạn thử nghiệm trên ảnh của chính mình và thấy rằng nó thường xuyên cho kết quả không chính xác ở cả hai chiều — khoảng một nửa số lần thử.
Bạn có thể rút ra kết luận gì về hộp đen? Có lẽ bạn đang sử dụng nó không đúng cách.
Có lẽ người kỹ sư đã nhầm lẫn.
Có lẽ người kỹ sư thiếu chuyên môn cần thiết.
Hoặc có thể những bức ảnh của bạn khác biệt đáng kể so với những gì mà kỹ sư đó đã được đào tạo.
Có nhiều lời giải thích khả thi.
Kết luận quan trọng là không có lời giải thích nào trong số này cho thấy hộp đen phù hợp với mục đích sử dụng ban đầu của nó.
Cuộc thảo luận
Chúng tôi đã phát triển một phương pháp mới để kiểm tra thuật toán chi tiêu đồng thời, phương pháp này tổng hợp các tập dữ liệu giao dịch tương tự Bitcoin, trong đó các giao dịch chi tiêu đồng thời là khả thi, từ dữ liệu ZK Mixer trên Ethereum. Chúng tôi thừa nhận đây không phải là bài kiểm tra ngoài mẫu lý tưởng cho thuật toán này. Bài kiểm tra lý tưởng sẽ yêu cầu dữ liệu được gắn thẻ hoàn hảo cho một dịch vụ bất hợp pháp thực sự trên Bitcoin mà chưa được công khai. Cách duy nhất để đạt được điều này là vận hành một dịch vụ như vậy và công bố kết quả kiểm tra trước khi cơ quan thực thi pháp luật can thiệp và tịch thu mã phần mềm, nhật ký và máy chủ.
Liệu một bài kiểm tra như vậy có tốt hơn không?
Một thử nghiệm như vậy sẽ không yêu cầu phép đẳng cấu của chúng ta, sẽ có ít bước hơn và sẽ mô phỏng sát hơn trải nghiệm thực tế khi sử dụng thuật toán chi tiêu chung để nghiên cứu một bộ trộn mới.
Tuy nhiên, điều này đòi hỏi nhóm thử nghiệm phải vận hành một dịch vụ bất hợp pháp, công khai thừa nhận điều đó và công bố dữ liệu tạo điều kiện thuận lợi cho việc bắt giữ họ.
Mặc dù về mặt lý thuyết, ai đó có thể công bố những tác phẩm như vậy một cách ẩn danh, nhưng điều này đòi hỏi đồng thời phải thừa nhận những tội danh có thể bị phạt tù dài hạn, công bố bằng chứng đủ để kết tội và thách thức các phương pháp thực thi pháp luật.
Phương pháp của chúng tôi chỉ giải quyết yếu tố thứ ba, vốn đã khá khó khăn trong thực tế.
Nếu phương pháp kiểm tra duy nhất được chấp nhận yêu cầu người kiểm tra phải thừa nhận hành vi phạm tội và công bố bằng chứng phạm tội, thì việc kiểm tra nghiêm ngặt sẽ trở nên không khả thi. Việc bác bỏ tiền đề của chúng tôi mà không đề xuất phương pháp kiểm tra thay thế là không mang tính xây dựng. Cách tiếp cận của chúng tôi được thực hiện một cách thiện chí, hợp lý và mang lại kết quả có ý nghĩa.
Nó có hoàn hảo không? Không.
Liệu chúng ta có mong đợi việc từ bỏ ngay lập tức phương pháp tính toán chi tiêu chung? Tất nhiên là không.
Chúng tôi không mong muốn và cũng không tin rằng đó là kết quả thích hợp.
Tuy nhiên, kết quả nghiên cứu của chúng tôi cho thấy độ tin cậy của nhiều kỹ thuật phân tích pháp y blockchain có thể đã bị đánh giá quá cao trong một thời gian dài.
Phần lớn hoạt động vận động và tuân thủ công nghệ blockchain được xây dựng dựa trên tuyên bố rằng các công cụ phân tích bổ sung có thể giải quyết các thách thức về tuân thủ của web3. Thật khó để coi trọng những tuyên bố như vậy khi các công cụ cơ bản chỉ được kiểm tra một cách hạn chế, nghiêm túc, kỹ lưỡng hoặc mang tính khoa học.
Việc thử nghiệm các công cụ giúp các nhà sản xuất công cụ cải tiến . Việc cho rằng các công cụ hoạt động tốt mà không qua thử nghiệm khoa học đúng cách thường dẫn đến kết quả không tốt . Đây không phải là những tuyên bố gây tranh cãi kể từ trước thời kỳ Khai sáng .
Không ai tiến hành thử nghiệm dù theo phương pháp mù đôi vì:
- Phương pháp này sẽ rất khó khăn;
- Nếu có thể, các đối tượng nghiên cứu rất có thể sẽ chết;
- Việc tiến hành các thử nghiệm không mù đôi một cách thuyết phục là hoàn toàn khả thi; và
- Rõ ràng là dù tốt hơn nhiều so với việc không có dù.
Nguyên tắc chi tiêu chung không phù hợp với khuôn mẫu đó.
Việc xét nghiệm đúng cách là cần thiết, đặc biệt khi kết quả dương tính giả có thể dẫn đến việc giam giữ oan sai, đảo ngược mối lo ngại về việc thử nghiệm dù từ "xét nghiệm có thể giết người" thành "việc không xét nghiệm có thể giam giữ những người vô tội".
Những gì chúng tôi trình bày là một nghiên cứu sáng tạo, chặt chẽ và quan trọng là mang tính khoa học, chứng minh rằng phương pháp tính toán chi tiêu chung có những hạn chế đáng kể trong các điều kiện không hoàn toàn khác biệt so với trường hợp sử dụng phổ biến và nổi bật nhất của nó: điều tra các dịch vụ bất hợp pháp mới dựa trên blockchain.
Nghiên cứu này chứng minh rằng có những điều kiện hợp lý mà trong đó thuật toán phỏng đoán không hoạt động hiệu quả. Điều này, tự nó, đủ để đặt ra câu hỏi về các điều kiện mà trong đó thuật toán phỏng đoán nên và không nên được sử dụng, được chấp nhận tại tòa án, được dựa vào để xin lệnh khám xét, hoặc được sử dụng trong nhiều ứng dụng phổ biến khác của thuật toán phỏng đoán chi tiêu chung và các công cụ được xây dựng dựa trên nó.
Chúng tôi hy vọng điều này sẽ mở ra một giai đoạn thảo luận mang tính xây dựng về độ tin cậy của nhiều kỹ thuật. Chúng tôi hy vọng nó sẽ định hướng lĩnh vực này theo hướng các tiêu chuẩn nghiêm ngặt hơn và, quan trọng nhất, các quy trình thiết lập tiêu chuẩn nhất quán với phần còn lại của ngành pháp y.
Bài viết "Co-spend Heuristic Hallucinations" ban đầu được đăng trên ChainArgos trên Medium, nơi mọi người đang tiếp tục cuộc thảo luận bằng cách nêu bật và phản hồi về câu chuyện này.






