

Tóm tắt
Chúng tôi muốn khuyến khích việc sử dụng các mã không định mức, đặc biệt là Mã hóa Mạng Tuyến tính Ngẫu nhiên (RLNC) thông qua phương pháp lấy mẫu theo yêu cầu thay vì lấy mẫu từ một tập mã cố định như trong các phương pháp DAS hiện hành như Celestia, SPAR hoặc Peer/Full DAS, xét từ góc độ hiệu quả lấy mẫu.
Tại sao nên sử dụng mã giá cố định?
Động lực ban đầu cho việc sử dụng mã hóa cho DAS là, trong điều kiện ẩn danh, việc lấy mẫu từ dữ liệu chưa mã hóa chỉ làm giảm xác suất âm tính giả (người xác minh kết luận rằng dữ liệu có sẵn mặc dù thực tế không có) một cách tuyến tính với số lượng mẫu được lấy là 1 - s/k đối với s mẫu được lấy từ k khối dữ liệu chưa mã hóa. Bây giờ, nếu chúng ta áp dụng mã RS (n,k) chẳng hạn, xác suất âm tính giả đối với s mẫu (không thay thế) giảm nhanh hơn (k-1/n)^s
Tăng hiệu quả lấy mẫu thông qua mã hóa không giới hạn tốc độ
Bằng cách sử dụng mã hóa tốc độ cố định, trình xác minh (máy khách nhẹ) tự giới hạn mình trong việc lấy mẫu từ một tập hợp n ký hiệu được mã hóa trước. Nhìn vào xác suất âm tính giả ở trên khi lấy mẫu từ dữ liệu được mã hóa tốc độ cố định, câu hỏi tự nhiên đặt ra là: tại sao không làm cho n càng lớn càng tốt để xác suất âm tính giả đủ thấp ngay cả với số lượng mẫu nhỏ? Có một số nhược điểm của điều này, bao gồm:
Các mã được sử dụng ở đây thường là các mã như mã RS, có những giới hạn vốn có về độ lớn của
ncũng như các tổ hợp(n,k)có thể có.Chi phí lưu trữ và tính toán tại phía nhà sản xuất dữ liệu sẽ vô tình tăng lên cùng với chi phí băng thông để phân tán dữ liệu lấy mẫu đến các nút lưu trữ, ví dụ như trong PeerDAS.
Một giải pháp tự nhiên cho vấn đề này là tạo ra các mẫu theo yêu cầu để ngăn chặn tình trạng tắc nghẽn trong lưu trữ và phân phối, điều này dẫn chúng ta đến việc xem xét các mã không tỷ lệ vì chúng có thể được coi là các mã phân tách khoảng cách tối đa (MDS) trong giới hạn đối với n lớn. RLNC là một ví dụ về mã không tỷ lệ như vậy, xây dựng các gói mã hóa bằng cách tạo ra các tổ hợp tuyến tính ngẫu nhiên của dữ liệu gốc.
Việc lấy mẫu theo yêu cầu từ một mã như RLNC cung cấp xác suất âm tính giả là (1/q)^s trong đó q biểu thị số lượng phần tử của trường cho các hệ số mã hóa. Mô tả đầy đủ về một giao thức như vậy được trình bày trong bài báo này: Từ lập chỉ mục đến mã hóa: Một Paradigm mới cho việc lấy mẫu khả dụng dữ liệu.
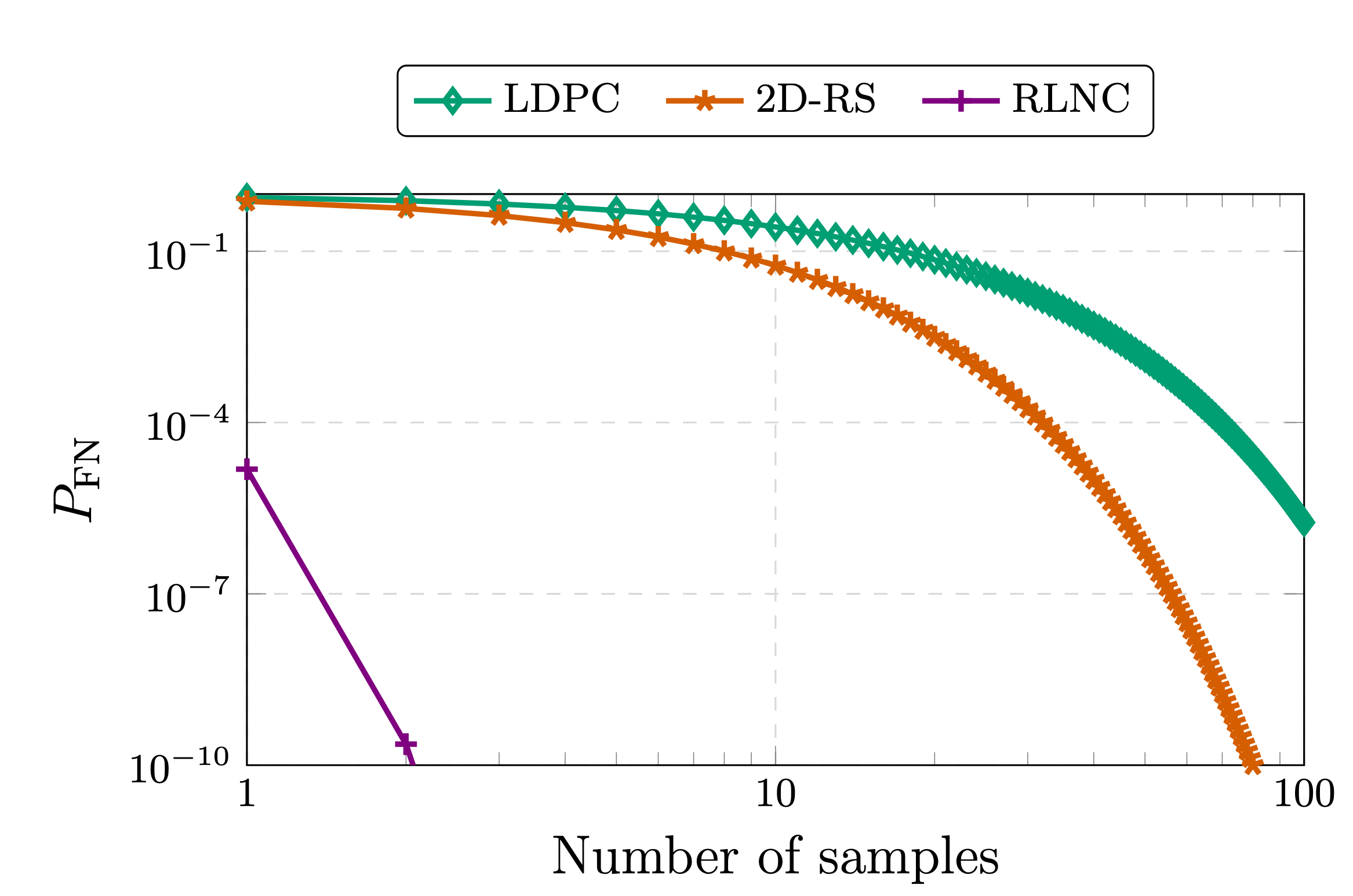
Xác suất âm tính giả (Không phát hiện được tính không thể giải mã của tải trọng cơ bản) khi lấy mẫu từ dữ liệu được mã hóa (xem [1],[2]).
Tiềm năng cho sự phi tập trung thực sự
Một nhược điểm khác của dữ liệu mã hóa tỷ lệ cố định là các mẫu được riêng lẻ hóa, tạo điều kiện cho các quy trình sửa chữa tốn kém. Ví dụ, đối với mã RS 1D, như được sử dụng trong PeerDAS, việc mất một ô dữ liệu duy nhất của một khối dữ liệu được mã hóa RS đòi hỏi phải tải xuống toàn bộ khối dữ liệu tương đương để tái tạo lại dữ liệu do đặc tính cục bộ kém của mã RS. Khi mã tensor được giới thiệu, tình hình sẽ được cải thiện, nhưng một mã không cấu trúc như RLNC cũng có thể cung cấp một phiên bản phân tán hơn của việc lưu trữ dữ liệu.
@Nashatyrev đã đề xuất một giao thức lưu ký phi tập trung sử dụng RLNC, cho thấy những đặc tính thuận lợi về băng thông sửa chữa cũng như chi phí phân phối và lưu trữ.
Tài liệu tham khảo
[1] Al-Bassam, Mustafa, et al. “Bằng chứng về gian lận và tính khả dụng của dữ liệu: Phát hiện các khối không hợp lệ trong các máy khách nhẹ.” Hội nghị quốc tế về mật mã tài chính và bảo mật dữ liệu . Berlin, Heidelberg: Springer Berlin Heidelberg, 2021.
[2] Yu, Mingchao, et al. “Cây Merkle mã hóa: Giải quyết các cuộc tấn công khả dụng dữ liệu trong chuỗi khối.” Hội nghị quốc tế về mật mã tài chính và bảo mật dữ liệu . Cham: Nhà xuất bản quốc tế Springer, 2020.





