
Bài viết này được dịch máy
Xem bản gốc
ByteDance đã từ bỏ mô hình chuyển văn bản thành video (có kịch bản), nó nhận biết ngữ cảnh, độ chân thực cao, tích hợp nhiều đoạn hội thoại có kịch bản sẵn... Các mô hình phương Tây là trình mô phỏng vật lý, trong khi mô hình này là đạo diễn AI thực thụ.
Các ràng buộc về tính toán buộc phải tối ưu hóa. Phương Tây có chip. Phương Đông có sự kiên trì (và dữ liệu).
Nó tạo ra video tốt hơn từ văn bản so với việc COMP dụng hình ảnh tham khảo/các mô hình khác, có lẽ là do ByteDance hiểu rõ mối LINK (Chainlink) ngữ nghĩa giữa ngôn ngữ và chuyển động hơn bất kỳ ai (sở hữu cả TikTok và Douyin).
Rất có thể ByteDance sẽ là công ty duy nhất tận dụng cả đào tạo tiếng Trung và tiếng Anh để tối ưu hóa hiệu quả của Token , vì vậy tôi rất lạc quan về sự phát triển mạnh mẽ của các công ty công nghệ hàng đầu Trung Quốc thông qua các áp lực đến từ mọi phía.
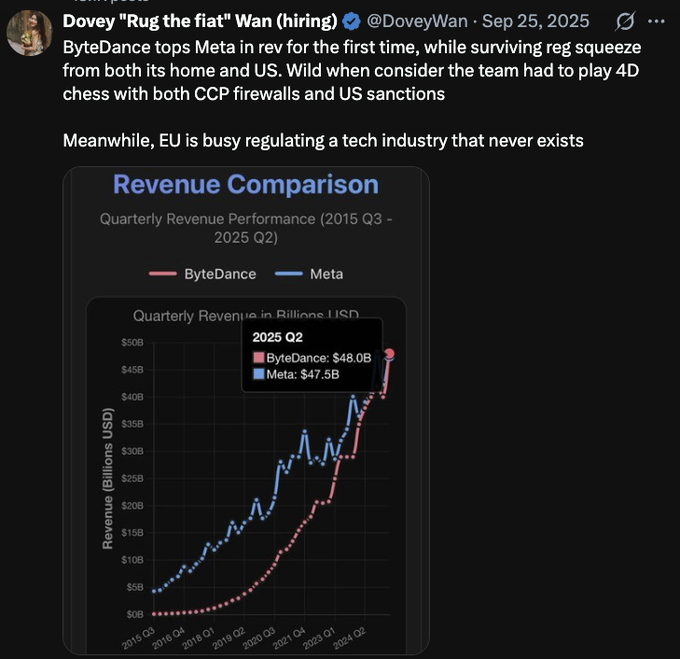
Thêm video do người dùng tạo, trình độ sản xuất phim và tối ưu hóa quy trình làm việc cực kỳ ấn tượng.
Dorksense
@Dork_sense
Seedance 2.0 from China will be the SOTA
This is AI
We are cooked.
• Native multi-shot storytelling from a single prompt (no more stitching scenes)
• Phoneme-level lip-sync in 8+ languages
• 30% faster generation than v1 via RayFlow optimization • 1080p cinematic quality,
Từ Twitter
Tuyên bố từ chối trách nhiệm: Nội dung trên chỉ là ý kiến của tác giả, không đại diện cho bất kỳ lập trường nào của Followin, không nhằm mục đích và sẽ không được hiểu hay hiểu là lời khuyên đầu tư từ Followin.
Thích
Thêm vào Yêu thích
Bình luận
Chia sẻ




