

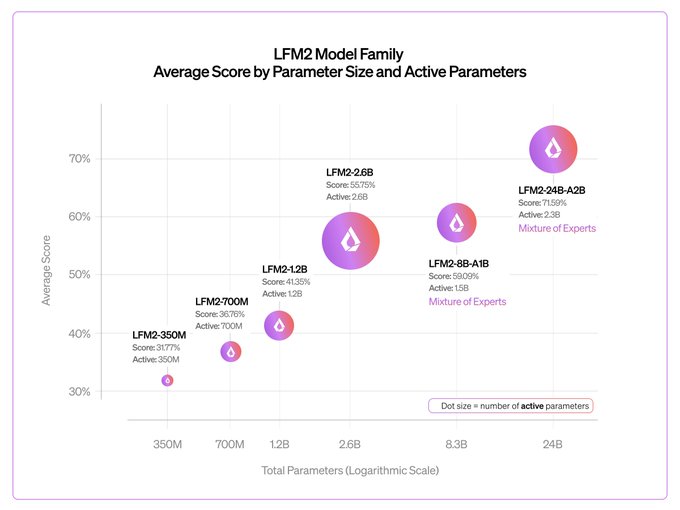
Điểm kiểm tra ban đầu của mô hình LFM2 lớn nhất của chúng tôi cho đến nay 🎉 Nó cho thấy khả năng mở rộng tốt và tốc độ suy luận cực nhanh so với gpt-oss-20b và Qwen3-30B-A3B Chúng tôi sẽ phát hành phiên bản LFM2.5 với nhiều dữ liệu huấn luyện trước và học tăng cường hơn trong vài tháng tới
Bài viết này được dịch máy
Xem bản gốc

Liquid AI
@liquidai
02-24
Today, we release our largest LFM2 model: LFM2-24B-A2B 🐘
> 24B total parameters
> 2.3B active per token
> Built on our hybrid, hardware-aware LFM2 architecture
It combines LFM2’s fast, memory-efficient design with a Mixture of Experts setup, so only 2.3B parameters activate
Từ Twitter
Tuyên bố từ chối trách nhiệm: Nội dung trên chỉ là ý kiến của tác giả, không đại diện cho bất kỳ lập trường nào của Followin, không nhằm mục đích và sẽ không được hiểu hay hiểu là lời khuyên đầu tư từ Followin.
Thích
Thêm vào Yêu thích
Bình luận
Chia sẻ
Nội dung liên quan




