Có một cách tốt hơn nhiều để hình dung bài viết này (với các hình ảnh động giải thích một số khái niệm và kết quả đánh giá hiệu năng một cách trực quan hơn). Nếu bạn thích, hãy xem tại: Binary Trie Group-Depth Benchmark — Narrower Than Expected
S1 – Tóm tắt điều hành
Cấu trúc dữ liệu trie nhị phân đang được xem xét trong bản dự thảo giao thức Ethereum như một giải pháp thay thế cho cây trạng thái trong tương lai. Chưa có triển khai trie nhị phân nào được đánh giá hiệu năng ở quy mô lớn – cả về độ sâu nhóm hay bất cứ khía cạnh nào khác. Với quá trình chuyển đổi này trong lộ trình phát triển, việc đánh giá các đặc tính hiệu năng là điều kiện tiên quyết để xây dựng nguyên mẫu một cách có cơ sở. Việc triển khai geth ( EIP-7864 ) cung cấp tham số --bintrie.groupdepth để kiểm soát cách các cấp độ nhị phân được đóng gói vào các nút trên đĩa; nghiên cứu này đánh giá hiệu năng tám cấu hình để xác định thiết lập tối ưu.
Tóm lại: Điểm tối ưu là GD-5 hoặc GD-6, tùy thuộc vào khối lượng công việc. GD-5 vượt trội hơn GD-4 về ghi dữ liệu với hiệu suất cao hơn 7% (6,94 so với 6,47 Mgas/s, p < 1e-9). GD-6 dẫn đầu về đọc dữ liệu (6,39 Mgas/s) và khối lượng công việc hỗn hợp (+19% so với GD-4, p < 1e-3). GD-7 xác nhận hiệu suất giảm dần sau GD-6.
Những gì chúng tôi đã thử nghiệm
Tám cấu hình độ sâu nhóm (GD-1 đến GD-8) trên các cơ sở dữ liệu 360 GB giống hệt nhau với khoảng 400 triệu mục trạng thái. Năm loại điểm chuẩn – hai loại tổng hợp (SLOAD/SSTORE thô) và ba loại khối lượng công việc hợp đồng ERC20 – mỗi loại được chạy 9 lần theo giao thức bộ nhớ đệm lạnh. Tất cả các kết quả đều sử dụng giá trị trung vị với kiểm định ý nghĩa Mann-Whitney U.
Những gì chúng tôi tìm thấy
- Các kết quả đọc xác nhận trực giác (Mục 4): Cây rộng hơn đọc nhanh hơn. GD-8 đạt được thông lượng đọc gấp hơn hai lần so với GD-1 (5,59 so với 2,65 Mgas/s). GD-6 đạt thông lượng đọc cao nhất (6,39 Mgas/s), tiếp theo là GD-5 (6,11) và GD-7 (6,04). GD-3 đến GD-8 có thông lượng dao động từ 5,2 đến 6,4 Mgas/s.
- Các phép ghi cho thấy một điểm tối ưu sắc nét hơn (Mục 5): GD-5 là quán quân về tốc độ ghi với 629 ms (6,94 Mgas/s) – nhanh hơn 7% so với GD-4 (678 ms, 6,47 Mgas/s) và nhanh hơn 55% so với GD-8 (982 ms, 4,47 Mgas/s). Điểm uốn của tốc độ ghi nằm giữa GD-5 và GD-6 (tỷ lệ băm/đọc vượt qua 1,0).
- Kích thước nút đạt đến giới hạn khối Pebble ở GD-7 (Mục 5): Mỗi nút GD-7 được tuần tự hóa thành ~4 KB (128 × 32 byte) – chính xác là kích thước khối Pebble. Dưới giới hạn này (GD-6: ~2 KB), mỗi nút nằm gọn trong một khối. Trên giới hạn này, các thao tác đọc có thể yêu cầu hai khối cho mỗi nút. Các bài kiểm tra hiệu năng NVMe của Gary Rong cho thấy các thao tác đọc ngẫu nhiên 8 KB có độ trễ cao hơn 54% so với 4 KB ở QD=1 (77,8 so với 50,6 µs). Mức phạt I/O trên mỗi nút này tích lũy trên ~37 nút đường dẫn, giải thích tại sao các thao tác đọc GD-7 chậm hơn GD-6 mặc dù đường dẫn ngắn hơn.
- Điểm tối ưu là GD-5 hoặc GD-6 (Mục 6): GD-5 vượt trội hơn GD-4 7% về ghi dữ liệu, trong khi GD-6 dẫn đầu về đọc dữ liệu (+5% so với GD-5) và khối lượng công việc hỗn hợp (+19% so với GD-4). GD-7 xác nhận điểm uốn – kém hơn GD-6 trên tất cả các bài kiểm tra hiệu năng. Vì Ethereum chủ yếu là các tác vụ đọc, GD-6 có thể là lựa chọn mặc định được ưu tiên.
Cách đọc bài viết này
- Phần 2 (Kiến thức nền) đề cập đến khái niệm cây trie nhị phân và độ sâu nhóm.
- Mục 3 (Phương pháp luận) trình bày chi tiết về thiết lập tiêu chuẩn so sánh.
- Các phần 4–6 trình bày kết quả theo một mạch truyện: đọc, viết, rồi đến sự đánh đổi.
- Phần 7 (Các mô hình) xem xét các quan sát xuyên suốt.
- Mục 8 (Kết luận) đưa ra khuyến nghị kép và các câu hỏi mở.
Không có nhiều thời gian? Hãy bắt đầu với Phần 4 “ERC20 Reads: Nơi chiều sâu đóng vai trò quan trọng” – đây là phần mà sự khác biệt về chiều sâu giữa các nhóm trở nên rõ ràng nhất và là tiền đề cho phần phân tích còn lại.

S2 – Bối cảnh
Cây nhị phân (Binary Trie) là gì?
EIP-7864 đề xuất thay thế cây trie Merkle Patricia (MPT) của Ethereum bằng cây trie nhị phân. Cây trie nhị phân hợp nhất cây trie tài khoản và tất cả các cây trie lưu trữ thành một cây duy nhất, sử dụng SHA-256 để băm thay vì Keccak-256, và lưu trữ các gốc 32 byte ánh xạ tới các nhóm 256 giá trị. Thiết kế này đơn giản hóa việc tạo chứng thực cho các máy khách không trạng thái và cho phép tạo bằng chứng hiệu quả hơn.
Việc chuyển đổi từ MPT sang trie nhị phân là một trong những thay đổi quan trọng nhất đối với lớp trạng thái của Ethereum. Đặc điểm hiệu năng của cấu trúc mới sẽ ảnh hưởng trực tiếp đến thời gian xử lý khối, tốc độ đồng bộ hóa và kinh tế của trình xác thực.
Độ sâu nhóm là gì?
Cấu trúc trie luôn là nhị phân ở cấp độ cơ bản – mỗi nút bên trong có chính xác hai nút con (bên trái cho bit 0, bên phải cho bit 1). Độ sâu nhóm kiểm soát số lượng cấp độ nhị phân được gộp vào một nút duy nhất trên đĩa . Ở GD-N, mỗi nút được lưu trữ bao gồm một cây con nhị phân N cấp, vì vậy nó có vẻ như có 2^N nút con khi nhìn từ bên ngoài:
- GD-1: 1 cấp độ nhị phân trên mỗi nút → 2 con trỏ con, 256 nút trên đường dẫn đến nút lá
- GD-2: 2 cấp nhị phân trên mỗi nút → 4 con trỏ con, 128 nút trên đường dẫn
- GD-3: 3 cấp độ nhị phân trên mỗi nút → 8 con trỏ con, ~86 nút trên đường dẫn
- GD-4: 4 cấp nhị phân trên mỗi nút → 16 con trỏ con, 64 nút trên đường dẫn
- GD-5: 5 cấp độ nhị phân trên mỗi nút → 32 con trỏ con, ~52 nút trên đường dẫn
- GD-6: 6 cấp độ nhị phân trên mỗi nút → 64 con trỏ con, ~43 nút trên đường dẫn
- GD-7: 7 cấp độ nhị phân trên mỗi nút → 128 con trỏ con, ~37 nút trên đường dẫn
- GD-8: 8 cấp nhị phân trên mỗi nút → 256 con trỏ con, 32 nút trên đường dẫn
Hãy hình dung nó giống như mã bưu điện: GD-1 đọc địa chỉ của bạn từng chữ số một (256 bước), trong khi GD-8 đọc 8 chữ số cùng một lúc (32 bước). Ít bước hơn có nghĩa là ít lần đọc dữ liệu hơn – nhưng mỗi “nút được nhóm lại” sẽ lớn hơn và tốn kém hơn để cập nhật, bởi vì cây con nhị phân bên trong nó phải được băm lại.
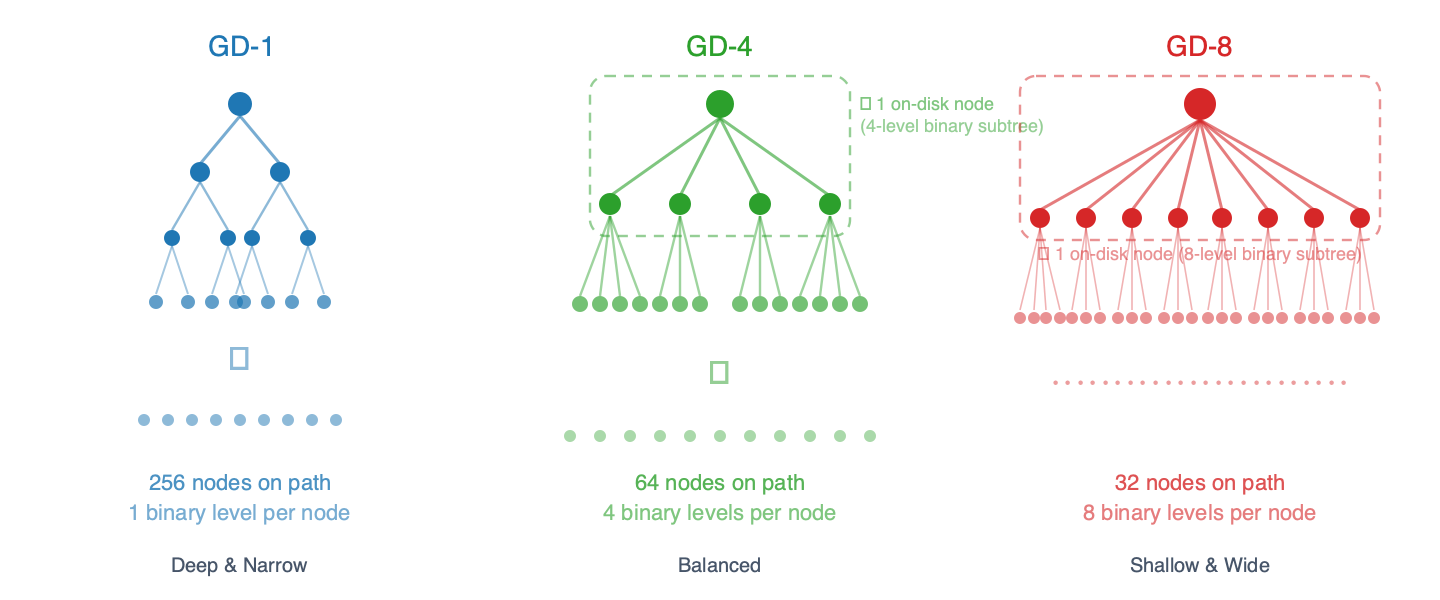
Hình 1 – Cấu trúc cây ở các độ sâu nhóm khác nhau. Mỗi nút gói gọn N cấp độ nhị phân bên trong, làm giảm số lượng nút trên đĩa trên đường dẫn đến nút lá.
Về lý thuyết, sự đánh đổi khá đơn giản: thao tác đọc được lợi từ cây nông (ít thao tác I/O đĩa hơn để đến được nút lá), trong khi thao tác ghi bị thiệt hại từ các nút rộng (nhiều hàm băm nội bộ hơn khi một nút được sửa đổi). Câu hỏi đặt ra là điểm giao nhau nằm ở đâu.
S3 – Phương pháp luận
Bản tóm tắt
Thiết lập tiêu chuẩn
| Tham số | Giá trị |
|---|---|
| Máy móc | Máy ảo QEMU – 8 vCPU, 30 GB RAM, 3.9 TB SSD, Ubuntu 24.04 LTS |
| Cơ sở dữ liệu | ~360 GB, ~400 triệu tài khoản + khe lưu trữ |
| Cấu hình | GD-1, GD-2, GD-3, GD-4, GD-5, GD-6, GD-7, GD-8 (Pebble, công cụ lưu trữ cây LSM được geth sử dụng, kích thước khối 4KB) |
| Giao thức | Bộ nhớ đệm nguội (bộ nhớ đệm trang hệ điều hành đã bị xóa + bộ nhớ đệm Pebble = 0 giữa các lần chạy) |
| Chạy | 10 lần đo hiệu năng cho mỗi cấu hình; lần chạy 1 bị loại trừ (do nhiệt dư) |
| Mục tiêu khí đốt | 100 triệu khí đốt mỗi khối |
Phương pháp thống kê
- Giá trị trung vị của khối trên mỗi lần chạy được tổng hợp từ 9 lần chạy được giữ lại.
- Kiểm định Mann-Whitney U để so sánh từng cặp (phi tham số)
- Kích thước hiệu ứng được báo cáo dưới dạng phần trăm khác biệt so với mức cơ sở (GD-1)
- Hệ số biến thiên (CV%) để đánh giá tính nhất quán
Phân loại chuẩn
a) Các bài kiểm tra hiệu năng tổng hợp – sstore_variants (ghi) và sload_benchmark (đọc). Chúng sử dụng ủy quyền EIP-7702 với các khe lưu trữ tuần tự. Các khóa được đánh số tuần tự, gây ra hiện tượng chia sẻ tiền tố lớn trong cây trie.
b) Các bài kiểm tra hiệu năng ERC20 – balanceof (đọc), approve (ghi) và mixed . Chúng sử dụng mã hợp đồng ERC-20 thực tế. Khóa lưu trữ là các hàm băm keccak của các địa chỉ ngẫu nhiên, tạo ra các mẫu truy cập phân bố đồng đều trên cây trie.
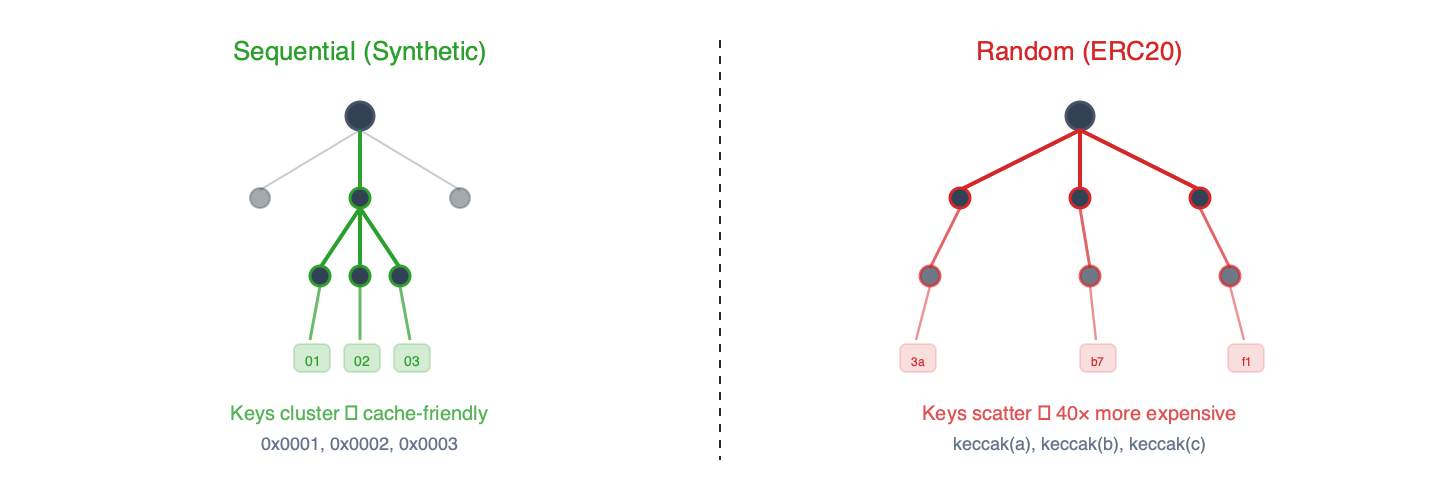
Hình 2 – Các khóa tuần tự chia sẻ tiền tố trie và được hưởng lợi từ bộ nhớ đệm. Các khóa băm Keccak phân tán đồng đều, buộc phải đọc dữ liệu mới ở mọi cấp độ.
Ghi chú về bố cục khối
Công cụ kiểm tra hiệu năng gửi tất cả các giao dịch benchmark đến mempool của geth cùng một lúc (trong vòng < 1 giây). Sau đó, trình khai thác ở chế độ phát triển của geth ( dev.period=10 ) xử lý các giao dịch tuần tự từ pool này trong khoảng thời gian xây dựng khối 10 giây – khi hết thời gian, nó sẽ khai thác bất cứ thứ gì nó đã xử lý được. Điểm nghẽn là thời gian thực hiện thao tác trie, chứ không phải dung lượng gas: mỗi giao dịch phê duyệt ERC20 chỉ sử dụng khoảng 4,4 triệu gas (giới hạn gas khối 100 triệu có thể chứa khoảng 22 giao dịch), nhưng các thao tác trie (duyệt, cập nhật, băm, cam kết) tiêu tốn gần như toàn bộ thời gian cho chỉ 1 giao dịch trên các cấu hình chậm hơn. Các giao dịch thiết lập (chuyển ETH đơn giản) xử lý 7 giao dịch trong 77ms, xác nhận rằng chi phí trie – chứ không phải chi phí giao dịch – là yếu tố giới hạn.
Với việc loại bỏ các gói tin lạnh đã được xác minh (Giai đoạn 3), tất cả các cấu hình hiện xử lý 1 giao dịch/khối (số giao dịch trung bình = 1). Giải thích về mặt cơ chế vẫn hợp lệ – khoảng dev.period 10 giây hoạt động như một ngân sách thời gian, và chi phí hoạt động của cây trie quyết định số lượng giao dịch có thể chứa. Mgas/s (thông lượng) là chỉ số so sánh chính xác vì nó chuẩn hóa mọi sự khác biệt về gas giữa các cấu hình. Khi hiển thị mili giây thô, nó phản ánh thời gian xử lý khối thực tế cho thành phần khối của cấu hình đó.
S4 – Màn I: Đọc để xác nhận trực giác
ERC20 Reads: Nơi chiều sâu tạo nên sự khác biệt
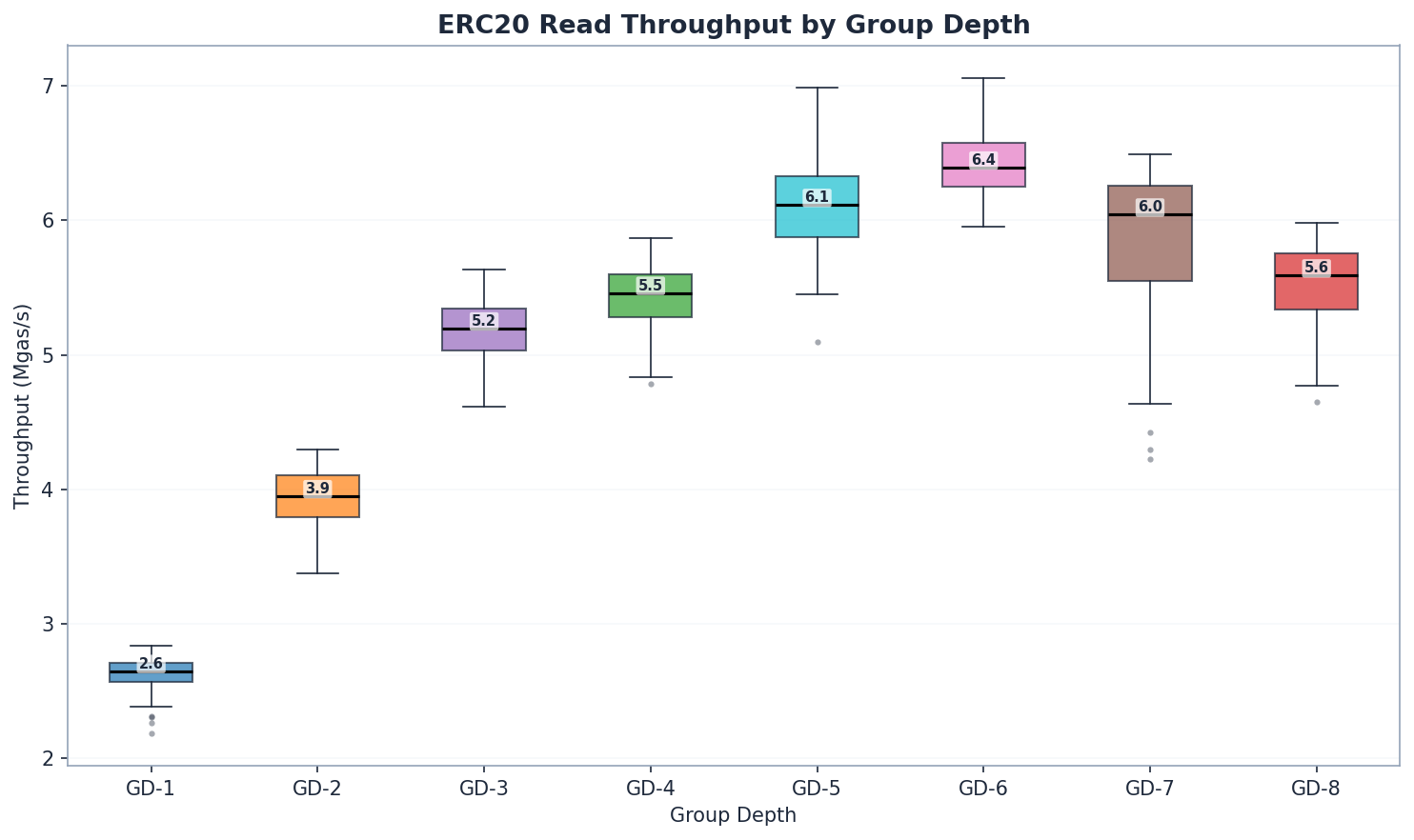
| GD | trạng thái_đọc (ms) | tổng cộng (ms) | Mgas/s | so với GD-1 (Mgas/s) |
|---|---|---|---|---|
| 1 | 5.878 | 6.284 | 2,65 | cơ sở |
| 2 | 3.840 | 4.231 | 3,95 | +49% |
| 3 | 2.866 | 3.213 | 5.20 | +96% |
| 4 | 2.677 | 3.067 | 5,46 | +106% |
| 5 | 2.370 | 2.733 | 6.11 | +131% |
| 6 | 2.248 | 2.623 | 6,39 | +141% |
| 7 | 2.339 | 2.693 | 6.04 | +128% |
| 8 | 2.598 | 2.977 | 5,59 | +111% |
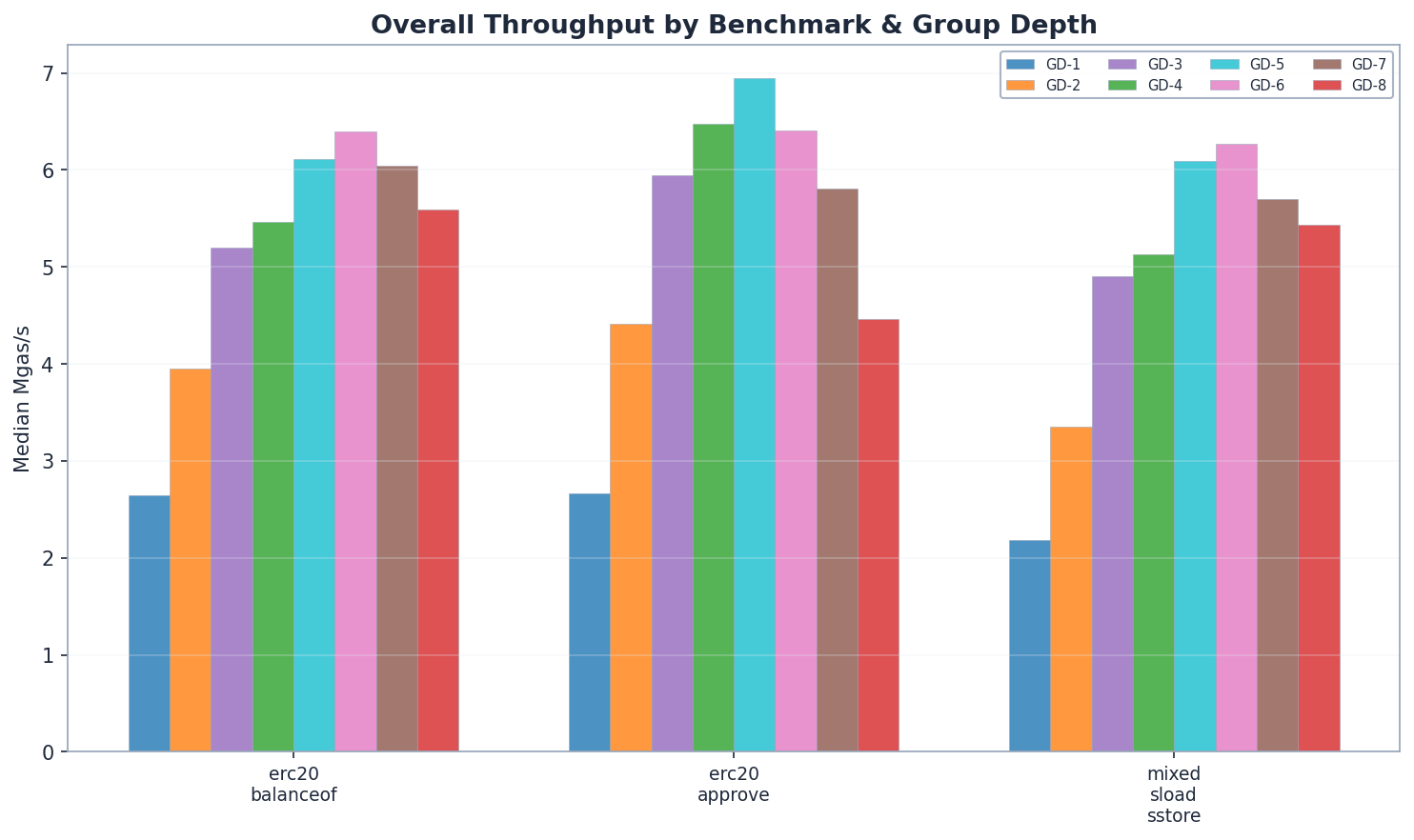
Tốc độ đọc tăng khoảng 2,4 lần từ GD-1 đến GD-6. GD-6 đạt tốc độ đọc cao nhất (6,39 Mgas/s), tiếp theo là GD-5 (6,11) và GD-7 (6,04). Hiệu suất đọc tăng dần từ GD-1 đến GD-6 trước khi giảm dần – GD-4 (5,46) vượt trội hơn GD-3 (5,20) như dự đoán do đường dẫn ngắn hơn. GD-7 và GD-8 cho thấy hiệu quả giảm dần khi các nút trở nên đủ lớn để bù đắp cho các đường dẫn ngắn hơn.
Tại sao lại có sự khác biệt lớn so với kiến trúc tổng hợp? Keccak phân tán các khóa đồng đều, buộc phải duyệt toàn bộ từ gốc đến lá. GD-1 phải duyệt qua 256 cấp độ; GD-8 chỉ cần 32 cấp độ. Mỗi cấp độ đều là một thao tác tìm kiếm trên đĩa tiềm năng. Truy cập ngẫu nhiên làm lộ ra toàn bộ nhược điểm về độ sâu.
GD-3 (3.213 ms, 5,20 Mgas/s) và GD-4 (3.067 ms, 5,46 Mgas/s) có hiệu suất đọc khá sát nhau, với GD-4 nhỉnh hơn một chút như dự kiến do đường dẫn ngắn hơn (64 so với ~86 nút). Việc tuần tự hóa nút nhỏ hơn của GD-3 (~256 byte so với ~512 byte của GD-4) tương tác thuận lợi với kích thước khối 4KB của Pebble, giữ cho cả hai nằm trong phạm vi 5% mặc dù hình dạng cây rất khác nhau. Sự tương tác kích thước khối của Pebble vẫn đáng được nghiên cứu thêm (Câu hỏi mở #3 ).
Chi phí trên mỗi khe: đọc tổng hợp tốn khoảng 0,02 ms/khe. Đọc ERC20 tốn khoảng 0,4–1,0 ms/khe (được tính bằng state_read_ms / storage_slots_read trên mỗi khối) – mức phạt gấp 40 lần so với các mẫu truy cập ngẫu nhiên.
Tỷ lệ 40x này phù hợp với các phép đo NVMe thô: Các bài kiểm tra hiệu năng đọc trang đĩa của Gary Rong cho thấy tốc độ đọc ngẫu nhiên 4KB là 77 MB/s so với tốc độ đọc tuần tự là 3.306 MB/s (43x), xác nhận rằng sự suy giảm hiệu năng chủ yếu là do các kiểu truy cập I/O chứ không phải do chi phí hoạt động của Pebble.
Vì sao truy cập ngẫu nhiên là tiêu chuẩn cơ bản, chứ không phải ngoại lệ. Cây trie nhị phân hợp nhất tất cả các tài khoản và bộ nhớ vào một cây duy nhất. Mỗi khóa – dù là số dư tài khoản, vị trí lưu trữ hay khối mã – đều được băm bằng SHA256 vào không gian khóa 256 bit. Các vị trí lưu trữ của một hợp đồng duy nhất nằm rải rác trên các đường dẫn cây hoàn toàn khác nhau. Điều này làm cho truy cập ngẫu nhiên trở thành mô hình truy cập cơ bản của cây trie nhị phân, chứ không phải là trường hợp bất thường. Các điểm chuẩn tuần tự tổng hợp đại diện cho trường hợp tốt nhất không thực tế, không thể xảy ra trong một triển khai cây trie thống nhất.
Cho đến nay, băng thông rộng hơn thì tốt hơn – nhưng chỉ đến một mức độ nhất định. GD-6 dẫn đầu về tốc độ đọc, trong khi GD-7 và GD-8 cho thấy hiệu quả giảm dần. Sau đó, chúng tôi đã thử nghiệm tốc độ ghi.
S5 – Màn II: Điều Bất Ngờ Viết
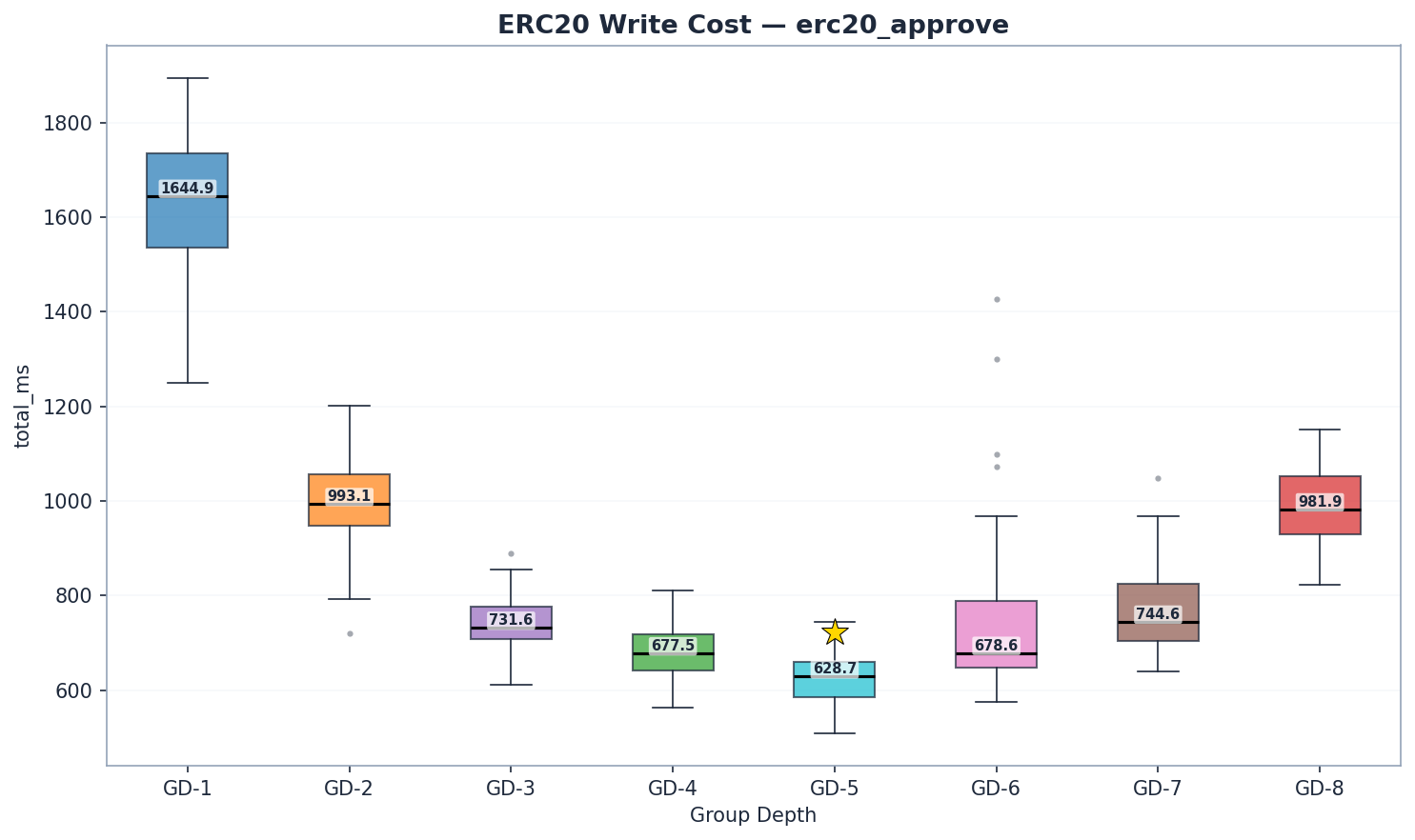
Đây là phát hiện quan trọng nhất trong nghiên cứu này.
| GD | trạng thái đã đọc | trie_updates | làm | Tổng cộng | Mgas/s |
|---|---|---|---|---|---|
| 1 | 812 | 691 | 77 | 1.645 | 2,67 |
| 2 | 483 | 393 | 61 | 993 | 4,42 |
| 3 | 349 | 287 | 44 | 732 | 5,95 |
| 4 | 313 | 254 | 53 | 678 | 6,47 |
| 5 | 271 | 242 | 57 | 629 | 6,94 |
| 6 | 272 | 283 | 76 | 679 | 6,41 |
| 7 | 264 | 328 | 103 | 745 | 5,81 |
| 8 | 313 | 433 | 158 | 982 | 4,47 |
trie_updates = state_hash_ms (AccountHashes + AccountUpdates + StorageUpdates) — bao gồm toàn bộ giai đoạn thay đổi và băm lại cấu trúc trie, không chỉ là băm. Tất cả các cấu hình đều chạy với giao thức bộ nhớ đệm lạnh đã được xác minh (bộ nhớ đệm trang của hệ điều hành bị xóa giữa các lần chạy). Các giá trị CV của Giai đoạn 3 hầu hết nhỏ hơn 10% trên Mgas/s, xác nhận các phép đo đáng tin cậy.
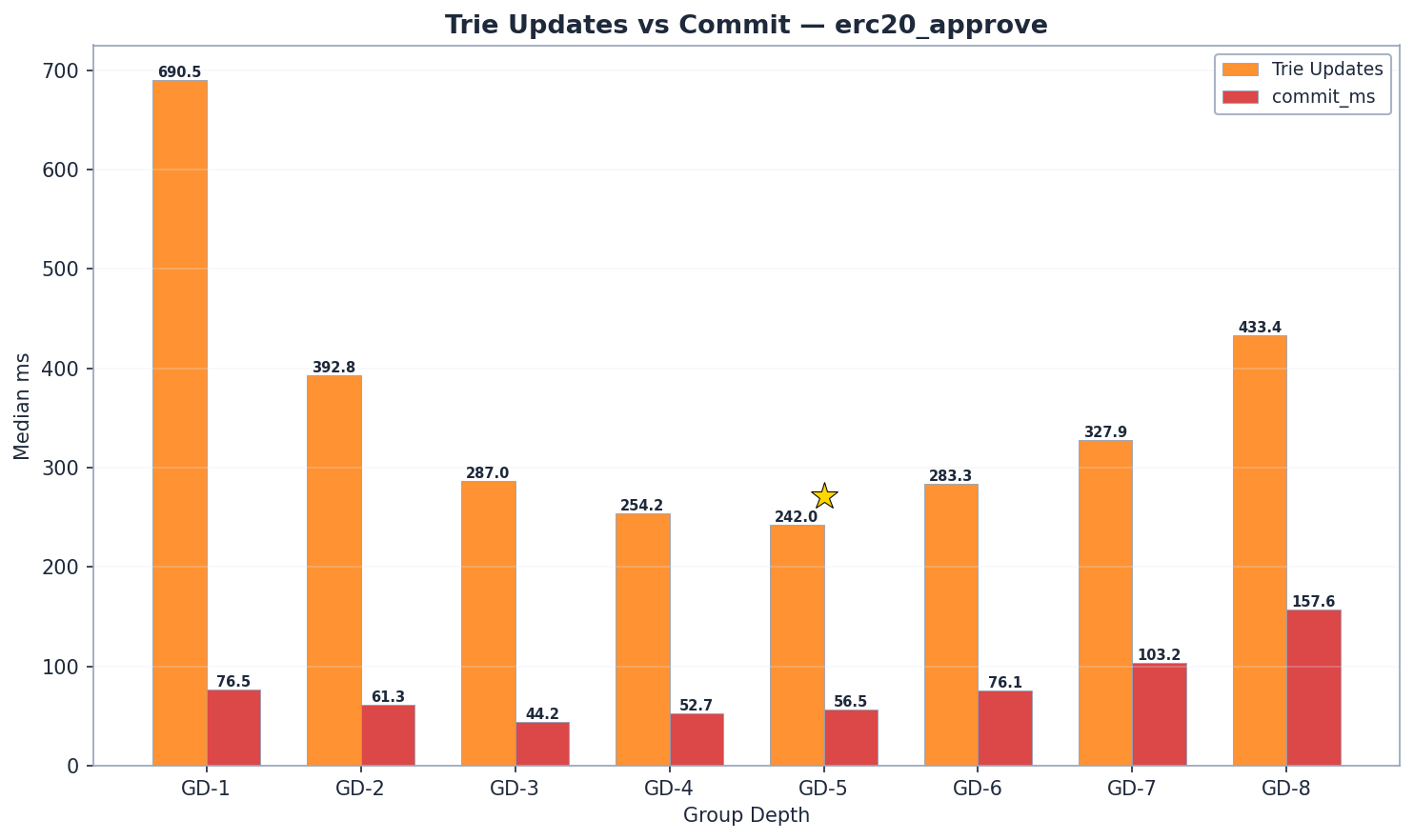
GD-5 là quán quân về tốc độ viết. 6,94 Mgas/s – nhanh hơn 7% so với GD-4 (6,47 Mgas/s, p < 1e-9) và nhanh hơn 55% so với GD-8 (4,47 Mgas/s). GD-6 (6,41 Mgas/s) xếp thứ 3, sát nút GD-4. GD-7 (5,81 Mgas/s) khẳng định sự cải thiện tiếp tục vượt qua GD-6.
Sự phân bổ các thành phần cho thấy rõ điều đó:
- Tốc độ đọc: GD-5 (271 ms) nhanh hơn 13% so với GD-4 (313 ms). GD-6 (272 ms) tương đương với GD-5, và GD-7 (264 ms) là máy đọc nhanh nhất – nhưng tốc độ tính bằng ms phải được kết hợp với Mgas/s để so sánh công bằng vì lượng khí trên mỗi khối có thể khác nhau.
- Các cập nhật thử nghiệm: GD-5 (242 ms) thấp hơn 5% so với GD-4 (254 ms). GD-6 tăng nhẹ lên 283 ms (+17% so với GD-5), không phải là sự sụt giảm đột ngột như dữ liệu cũ đã chỉ ra. GD-7 (328 ms) và GD-8 (433 ms) xác nhận điểm uốn tiếp tục.
- Cam kết: GD-5 (57 ms) cao hơn một chút so với GD-4 (53 ms). GD-6 (76 ms, tăng 33% so với GD-5) và GD-7 (103 ms) cho thấy sự gia tăng vừa phải. Điểm nghẽn thực sự của cam kết nằm ở GD-8 (158 ms) do ~8 KB nút x 32 nút đường dẫn = ~256 KB tuần tự hóa mỗi lần ghi.
Điểm uốn của quá trình ghi nằm giữa GD-5 và GD-6: tỷ lệ chi phí băm/đọc vượt qua 1,0 tại GD-6 (283/272 = 1,04), có nghĩa là việc cập nhật cây trie bắt đầu vượt quá chi phí đọc. Xét theo Mgas/s, GD-5 (6,94) dẫn trước GD-4 (6,47) 7% và GD-6 (6,41) 8%.
Tại sao? Cây con bên trong
Mỗi nút trie ở độ sâu nhóm g chứa một cây con nhị phân bên trong với 2^g - 1 2 g − 1 nút phải được băm lại mỗi khi ghi.
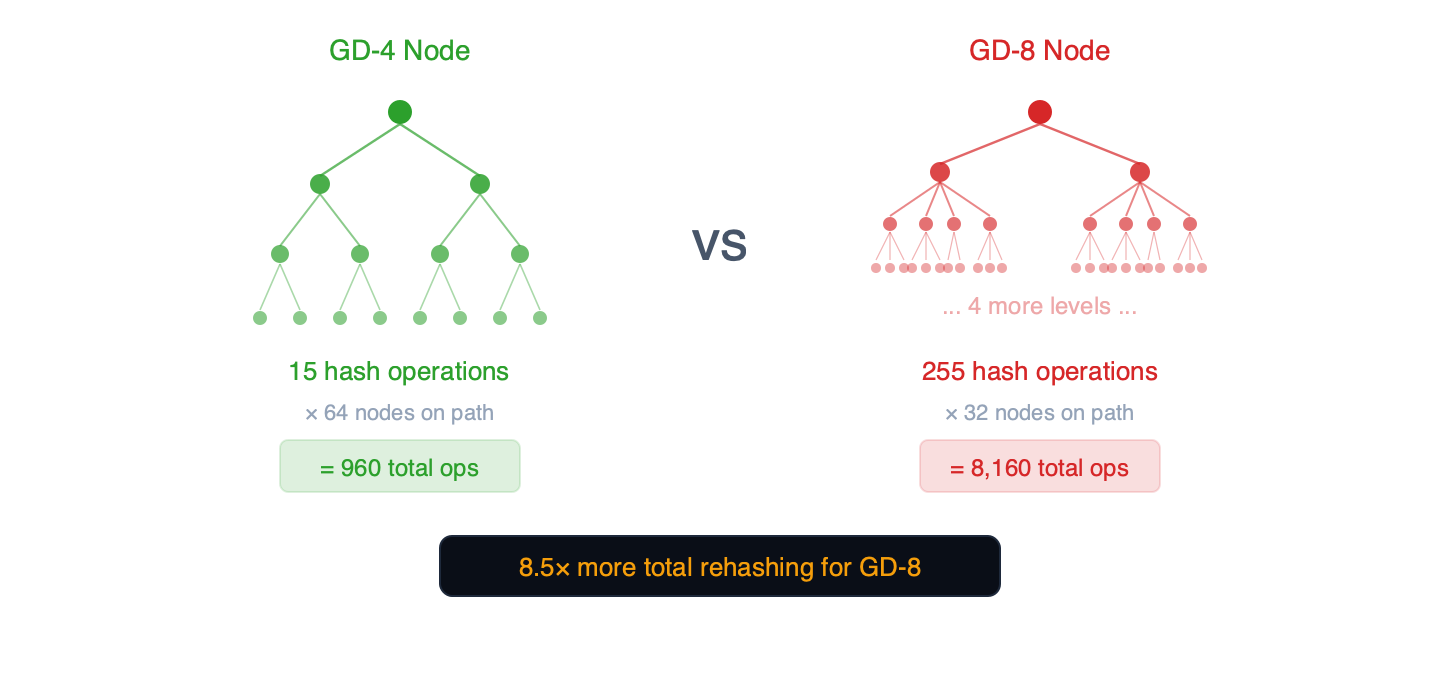
Hình 3 – Mỗi nút trie chứa một cây con nhị phân bên trong. Các nút càng rộng thì số lượng phép băm trên mỗi lần ghi càng tăng theo cấp số nhân.
- Nút GD-4: 15 thao tác băm nội bộ x 64 nút trên đường dẫn = tổng cộng 960 thao tác.
- Nút GD-5: 31 thao tác băm nội bộ x ~52 nút trên đường dẫn = ~1.612 tổng số thao tác
- Nút GD-8: 255 phép toán băm nội bộ x 32 nút trên đường dẫn = tổng cộng 8.160 phép toán.
GD-5 tìm thấy điểm tối ưu cho việc ghi dữ liệu: đường dẫn của nó ngắn hơn 19% so với GD-4 (~52 so với 64 nút), và 31 thao tác nội bộ của mỗi nút vẫn có thể quản lý được. Ở GD-6 (63 nút nội bộ trên mỗi nút), chi phí băm lại tăng lên vừa phải – 283 ms so với 242 ms của GD-5 (+17%). GD-7 (băm 328 ms, cam kết 103 ms) xác nhận điểm uốn tiếp tục vượt qua GD-6. Điểm uốn của việc ghi dữ liệu nằm giữa GD-5 và GD-6, nơi tỷ lệ băm/đọc vượt qua 1.0.
Lưu ý: Tỷ lệ 17× (255 so với 15 thao tác băm nội bộ) là giới hạn trên lý thuyết từ cấu trúc dữ liệu. Các thử nghiệm của chúng tôi hỗ trợ cơ chế này: chi phí cập nhật cây trie GD-8 cao hơn 1,71 lần so với GD-4 (433ms so với 254ms), phù hợp với việc ghi ngẫu nhiên sửa đổi một phần cây con nội bộ của mỗi nút. Việc triển khai geth là nguồn đáng tin cậy cho thuật toán băm lại chính xác.
Kích thước tuần tự hóa nút
Mỗi nút trie lưu trữ tối đa 2^N con trỏ con (mỗi con trỏ 32 byte). Một nút GD-4: 16 × 32 = ~512 byte . Một nút GD-7: 128 × 32 = ~4 KB – chính xác bằng kích thước khối Pebble. Một nút GD-8: 256 × 32 = ~8 KB . Sự khác biệt về kích thước có tác động dây chuyền:
- Giới hạn khối Pebble: Các nút GD-6 (~2 KB) nằm gọn trong một khối Pebble 4 KB duy nhất. Các nút GD-7 (~4 KB) chiếm hết toàn bộ khối – với chi phí xử lý khóa, chúng có thể trải rộng trên hai khối, tiềm ẩn nguy cơ làm tăng gấp đôi I/O cho mỗi lần truy xuất nút. Điều này phần nào giải thích hiện tượng đảo ngược đọc của GD-7: mặc dù có ít hơn 14% nút đường dẫn so với GD-6 (37 so với 43), GD-7 đọc tổng cộng ~148 KB mỗi lần tra cứu (37 × 4 KB) so với ~86 KB của GD-6 (43 × 2 KB).
- Hiệu quả bộ nhớ đệm Pebble: Số lượng nút GD-8 có thể chứa trong một ngân sách bộ nhớ đệm nhất định ít hơn.
- Hiện tượng khuếch đại ghi: Các nút được tuần tự hóa lớn hơn làm tăng chi phí nén LSM.
- Chi phí cam kết: Mức phạt cam kết 198% (158ms so với 53ms) một phần phản ánh việc tuần tự hóa lượng dữ liệu gấp 16 lần cho mỗi nút được sửa đổi.

Hình 4 – Đối với các thao tác đọc, chỉ có việc duyệt xuống là quan trọng (ưu tiên GD-8). Đối với các thao tác ghi, việc băm lại và cam kết chiếm ưu thế (ưu tiên GD-4). Đọc = Chỉ Bước 1. Ghi = Bước 1 + 2 + 3.
S6 – Màn III: Sự đánh đổi
Phán quyết
| Tiêu chí | GD-4 | GD-5 | GD-6 | GD-7 | GD-8 |
|---|---|---|---|---|---|
| Lượt đọc (Mgas/s) | 5,46 | 6.11 | 6,39 | 6.04 | 5,59 |
| Ghi (Mgas/s) | 6,47 | 6,94 | 6,41 | 5,81 | 4,47 |
| Hỗn hợp (Mgas/s) | 5.13 | 6.09 | 6,27 | 5,87 | 5,43 |
| Chiến thắng hạng mục | 0/3 | 1/3 | 2/3 | 0/3 | 0/3 |
GD-6 vượt trội hơn về đọc và xử lý hỗn hợp; GD-5 vượt trội hơn về ghi. GD-5 dẫn trước GD-4 7% về ghi (p < 1e -9). GD-6 dẫn trước GD-5 5% về đọc và GD-4 19% về xử lý hỗn hợp (p < 1e - 3). GD-7 đã vượt qua điểm uốn – kém hơn GD-6 trên cả ba bài kiểm tra. Vì khối lượng công việc của Ethereum chủ yếu là đọc, GD-6 có thể là lựa chọn mặc định được ưu tiên, trong khi GD-5 tối ưu cho các kịch bản chủ yếu là ghi.
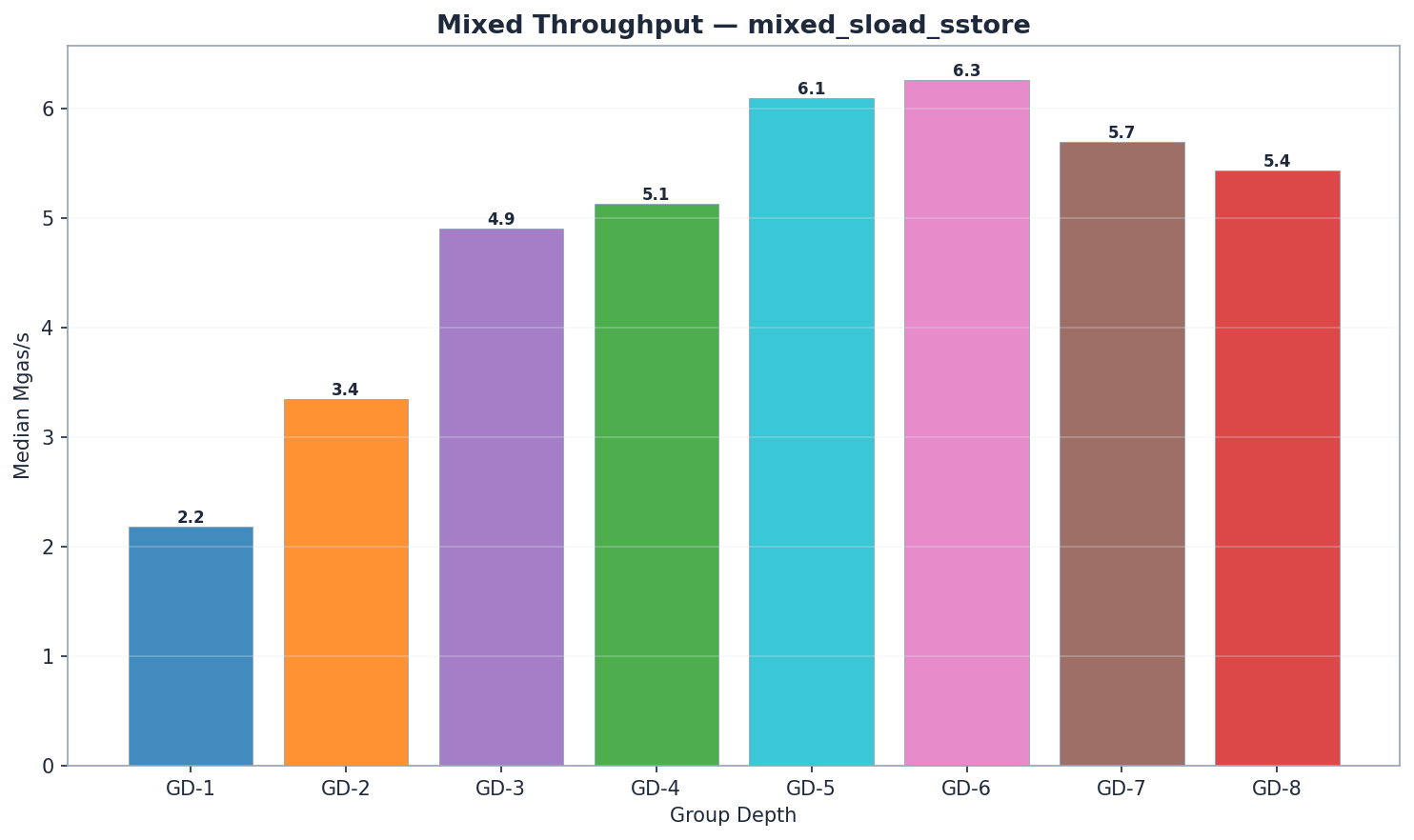
Khối lượng công việc hỗn hợp
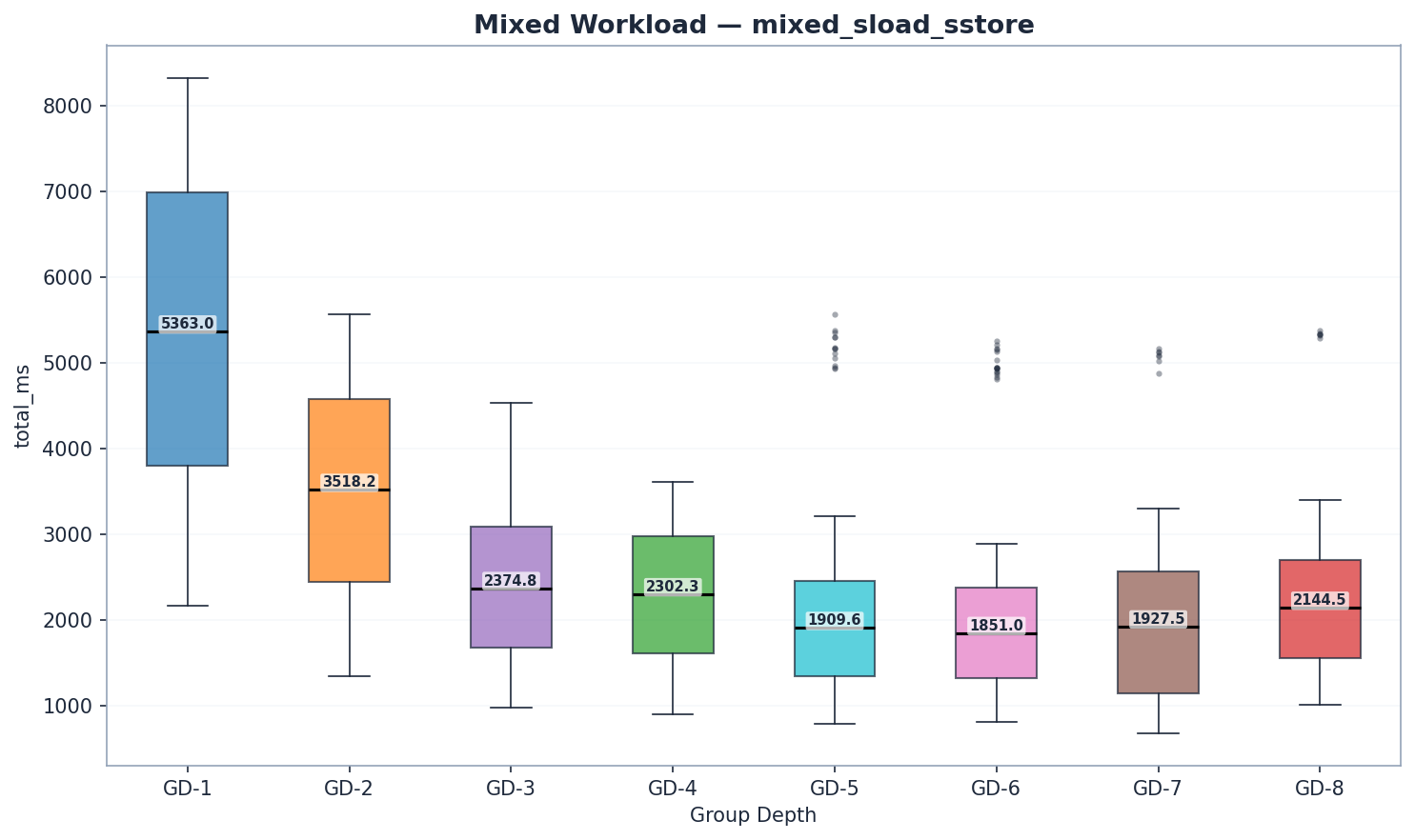
| GD | trạng thái đã đọc | trie_updates | làm | tổng_ms | Mgas/s |
|---|---|---|---|---|---|
| 1 | 4.711 | 345 | 53 | 5.363 | 2.18 |
| 2 | 3.003 | 217 | 44 | 3.518 | 3,35 |
| 3 | 1.981 | 145 | 39 | 2.375 | 4,90 |
| 4 | 1.893 | 138 | 43 | 2.302 | 5.13 |
| 5 | 1.512 | 124 | 48 | 1.910 | 6.09 |
| 6 | 1.440 | 141 | 54 | 1.851 | 6,27 |
| 7 | 1.055 | 218 | 73 | 1.529 | 5,87 |
| 8 | 1.612 | 221 | 87 | 2.145 | 5,43 |
Cấu hình benchmark hỗn hợp của GD-7 xử lý ít giao dịch hơn trên mỗi khối (8,84 triệu so với ~11,80 triệu gas). Giá trị Mgas/s được chuẩn hóa để bù đắp sự khác biệt này, do đó việc so sánh thông lượng vẫn hợp lệ. Giá trị ms thô cho cấu hình hỗn hợp của GD-7 không thể so sánh trực tiếp với các cấu hình khác.
GD-6 dẫn đầu về khối lượng công việc hỗn hợp với tốc độ 6,27 Mgas/s, theo sát là GD-5 (6,09 Mgas/s, +3%). Cả hai đều vượt trội hơn GD-4 (5,13 Mgas/s) từ 19–22%. Lợi thế về đọc của GD-6 (1.440 ms state_read so với 1.512 ms của GD-5) bù đắp cho thời gian cập nhật trie (141 ms so với 124 ms) và thời gian cam kết (54 ms so với 48 ms) cao hơn một chút. GD-7 (5,87 Mgas/s) chậm hơn GD-6 6%, xác nhận điểm uốn. Lưu ý: GD-7 sử dụng 8,84M gas/block cho khối lượng công việc hỗn hợp so với 11,80M cho tất cả các loại khác; Mgas/s mới là chỉ số so sánh hợp lệ, không phải ms thô.
Câu hỏi mở: Độ sâu nhóm tối ưu cuối cùng phụ thuộc vào tỷ lệ đọc/ghi của các khối Ethereum thực tế. Mặc dù việc đọc trạng thái rõ ràng chiếm ưu thế về thời gian xử lý khối trong các thử nghiệm của chúng tôi, nhưng tỷ lệ phân chia chính xác trên mạng chính chưa được đo lường một cách có hệ thống. Một phân tích lịch sử về các mô hình truy cập đọc so với ghi trên mạng chính sẽ cung cấp thêm thông tin cho khuyến nghị này.
Phân tích thành phần cho thấy một mô hình quen thuộc:
- Về tốc độ đọc: GD-7 có thời gian đọc thô thấp nhất (1.055 ms), nhưng ở mức khí/khối thấp hơn. Xét theo Mgas/s, GD-6 (6,27) dẫn đầu. GD-5 (1.512 ms) và GD-6 (1.440 ms) có hiệu suất đọc tốt hơn GD-4 (1.893 ms).
- Cập nhật Trie: GD-5 dẫn đầu (124 ms), tiếp theo là GD-4 (138 ms) và GD-6 (141 ms). GD-7 (218 ms) và GD-8 (221 ms) tụt lại phía sau do các cây con bên trong lớn hơn.
- Cam kết: GD-3 thắng (39 ms), tiếp theo là GD-4 (43 ms) và GD-5 (48 ms). GD-7 (73 ms) và GD-8 (87 ms) cho thấy hình phạt tuần tự hóa của các nút rộng hơn.
S7 – Các mẫu cắt ngang
Thời gian trôi đi đâu?
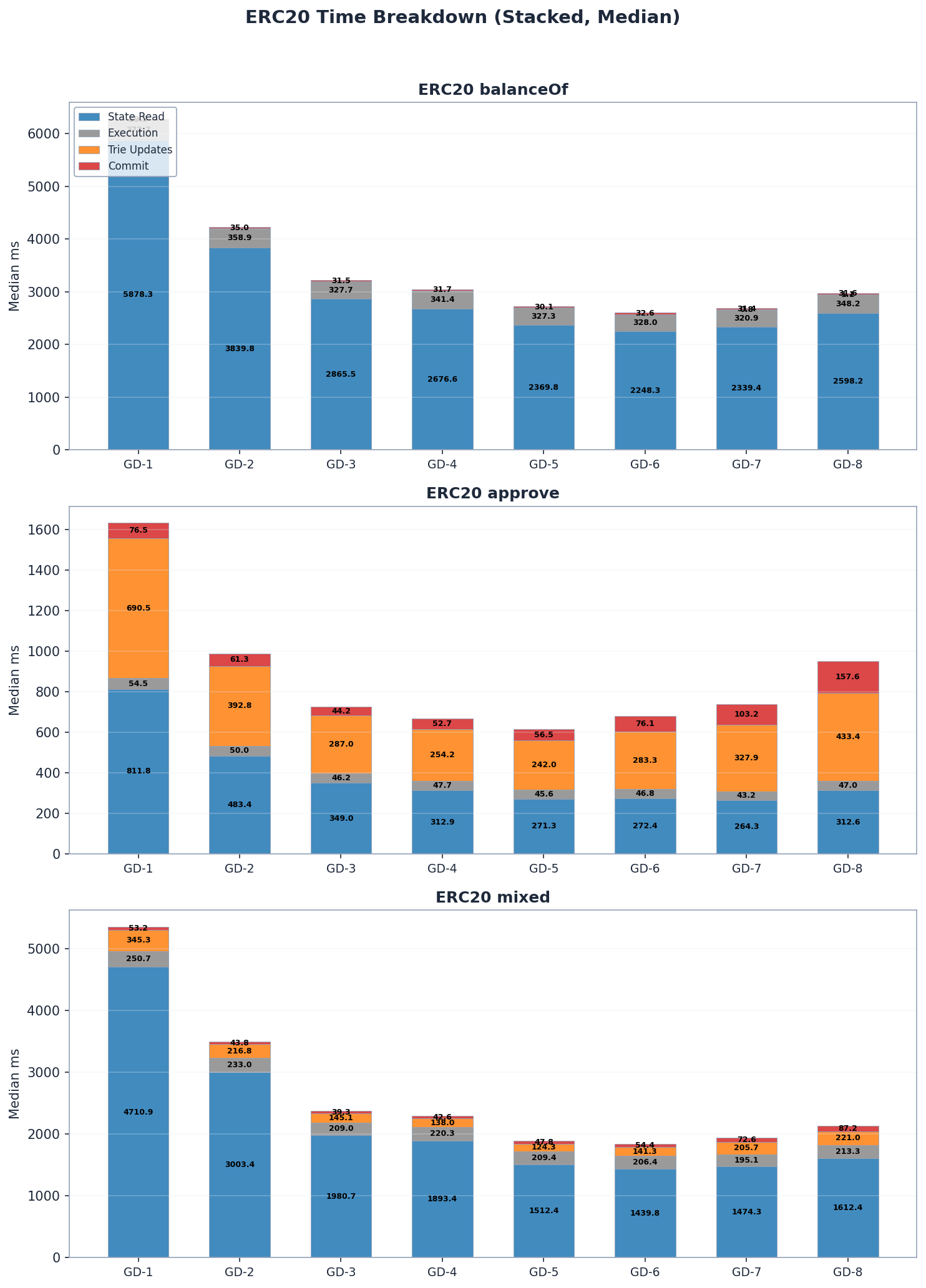
Việc đọc trạng thái chiếm ưu thế trong thời gian xử lý khối ERC20 trên tất cả các cấu hình độ sâu nhóm, chiếm từ 50–85% tổng thời gian. Chi phí cập nhật và cam kết cây trie là không đáng kể đối với các bài kiểm tra chỉ đọc (balanceOf) nhưng trở thành thành phần chi phí chiếm ưu thế đối với các thao tác ghi (approve) – đặc biệt là ở độ sâu nhóm cao hơn, nơi việc băm lại cây con nội bộ tốn kém nhất.
Tổng thông lượng
Bối cảnh phần cứng: Đặc điểm I/O của NVMe
Các bài kiểm tra hiệu năng đọc trang ổ đĩa do Gary Rong thực hiện trên NVMe (Samsung 990 Pro) cung cấp bối cảnh phần cứng để giải thích kết quả của chúng tôi:
- Đọc ngẫu nhiên so với đọc tuần tự: Đọc ngẫu nhiên 4KB = 77 MB/s (50,6 µs) so với 3.306 MB/s đọc tuần tự – chênh lệch gấp 43 lần, gần bằng mức phạt 40 lần trên mỗi khe cắm của chúng ta.
- Kích thước trang rất quan trọng: Việc đọc ngẫu nhiên 16KB đạt được thông lượng gấp 2,3 lần so với 4KB (174 so với 77 MB/giây) với độ trễ chỉ gấp 1,8 lần. Độ sâu nhóm lớn hơn tạo ra các nút lớn hơn, có thể hưởng lợi từ kích thước khối Pebble lớn hơn.
- Độ sâu hàng đợi có tính đột phá: Từ QD=1 đến QD=8, thông lượng ngẫu nhiên 4KB được cải thiện gấp 8,7 lần (từ 77 lên 673 MB/s). EVM song song có thể khai thác tối đa tiềm năng này, thu hẹp sự khác biệt về độ trễ đọc giữa các cấu hình.
- Tốc độ tăng độ trễ dưới mức tuyến tính: từ 4KB lên 64KB = dung lượng dữ liệu gấp 16 lần, nhưng độ trễ chỉ tăng 2,3 lần (từ 50,6 lên 117,3 µs). Khả năng xử lý song song bên trong của NVMe giúp các yêu cầu I/O lớn hơn hoạt động hiệu quả hơn đáng kể.
Các phép đo này sử dụng phương pháp đọc trang trực tiếp, bỏ qua bộ nhớ đệm của hệ thống tập tin – tương tự như giao thức bộ nhớ đệm lạnh của chúng tôi. Phần cứng đo hiệu năng (Samsung 990 Pro) khác với ổ đĩa ảo của máy ảo QEMU, vì vậy các con số tuyệt đối sẽ không khớp, nhưng tỷ lệ này cho thấy các đặc điểm cơ bản của NVMe liên quan đến việc tối ưu hóa độ sâu nhóm.
S8 – Kết luận
Khuyến nghị: GD-5 hoặc GD-6 (Tùy thuộc vào khối lượng công việc)
Độ sâu tối ưu là GD-5 hoặc GD-6 , tùy thuộc vào cấu hình khối lượng công việc:
- Khối lượng công việc đọc nhiều/hỗn hợp (khuyến nghị mặc định): GD-6. Hiệu suất đọc tốt hơn GD-5 5% (6,39 so với 6,11 Mgas/s) và khối lượng công việc hỗn hợp tốt hơn 3% (6,27 so với 6,09 Mgas/s). Vì Ethereum có khối lượng công việc đọc nhiều, nên GD-6 là lựa chọn mặc định được ưu tiên.
- Khối lượng công việc ghi dữ liệu lớn: GD-5. Hiệu suất ghi cao hơn 7% so với GD-4 (6,94 so với 6,47 Mgas/s) và cao hơn 8% so với GD-6 (6,94 so với 6,41 Mgas/s).
- GD-7 xác nhận điểm uốn. Tệ hơn GD-6 trên cả ba bài kiểm tra (đọc -5%, ghi -9%, hỗn hợp -6%), chứng minh rằng điểm tối ưu là GD-5 hoặc GD-6.
Khuyến nghị này dựa trên cơ chế ba bước chi phối mọi thao tác truy cập trạng thái trong cây trie nhị phân:
- Phương pháp đào ngang – đi xuống từ gốc đến lá. Chi phí tỷ lệ thuận với độ sâu của cây. Ưu tiên những cây có tán rộng hơn (GD-8: 32 tầng so với GD-5: ~52 tầng so với GD-4: 64 tầng).
- Rehash – tính toán lại cây con bên trong của mỗi nút trên đường dẫn trở về gốc. Chi phí tỷ lệ thuận với 2^g - 1 2 g − 1 trên mỗi nút. Ưu tiên các cây hẹp hơn (GD-4: 15 thao tác/nút, GD-5: 31 thao tác/nút, GD-8: 255 thao tác/nút).
- Commit – thực hiện việc tuần tự hóa và ghi các nút đã sửa đổi vào đĩa. Chi phí tỷ lệ thuận với kích thước nút. Ưu tiên các cây có kích thước nhỏ hơn.
GD-5 tìm ra điểm tối thiểu của sự đánh đổi giữa thời gian duyệt và thời gian băm lại cho các thao tác ghi. Đường dẫn của nó ngắn hơn 19% so với GD-4 (~52 so với 64 nút), và 31 thao tác nội bộ của mỗi nút vẫn có thể quản lý được. Ở GD-6, chi phí băm lại tăng lên vừa phải – 283 ms so với 242 ms của GD-5 (+17%) – nhưng các thao tác đọc và khối lượng công việc hỗn hợp vẫn được cải thiện. Điểm uốn cụ thể cho thao tác ghi nằm giữa GD-5 và GD-6 (tỷ lệ băm/đọc vượt qua 1.0), trong khi các thao tác đọc đạt đỉnh điểm ở GD-6.
Năm mô hình chung cho mọi độ sâu nhóm
Mẫu 1: Việc đọc trạng thái chiếm ưu thế. 50–85% thời gian xử lý khối được dành cho việc đọc trạng thái từ đĩa, bất kể độ sâu nhóm hay loại chuẩn.
state_read_msbao gồm việc tra cứu tài khoản và mã trong cây trie thống nhất, chứ không chỉ là việc đọc vị trí lưu trữ.
Mẫu 2: Truy cập ngẫu nhiên tốn kém hơn khoảng 40 lần mỗi khe. Khóa băm Keccak (ERC20) có chi phí 0,4–1,0 ms/khe so với 0,02 ms/khe đối với truy cập tuần tự (tổng hợp). Sự khác biệt này là do lỗi bộ nhớ cache khối Pebble trên các khóa phân tán Keccak.
Các bài kiểm tra hiệu năng đọc trang NVMe độc lập xác nhận rằng sự khác biệt giữa I/O ngẫu nhiên và I/O tuần tự giải thích gần như toàn bộ sự suy giảm hiệu năng này (xem Phần 7 Bối cảnh phần cứng để biết thêm chi tiết).
Mẫu 3: Tỷ lệ truy cập bộ nhớ cache ổn định ở mức ~37–39%. Mặc dù độ sâu nhóm tăng lên, tỷ lệ truy cập bộ nhớ cache lưu trữ không bao giờ vượt quá ~39% đối với các tác vụ băm Keccak. Không gian khóa 256 bit quá thưa thớt để có thể tái sử dụng bộ nhớ cache một cách hiệu quả ngoài các nút trie cấp cao được chia sẻ.
Mẫu 4: Việc cập nhật cây trie là không đáng kể đối với các thao tác đọc, nhưng lại chiếm ưu thế đối với các thao tác ghi. balanceOf (chỉ đọc): trie_updates < 1,3 ms. approve (đọc + ghi): trie_updates lên đến 691 ms (GD-1). Sự bất đối xứng này có nghĩa là sự đánh đổi về độ rộng nút chỉ quan trọng đối với khối lượng công việc ghi.
Mẫu 5: CV giữa các lần chạy chủ yếu nhỏ hơn < 10% trên Mgas/s. Giai đoạn 3 đã xác minh việc loại bỏ bộ nhớ đệm lạnh (hơn 120 lần thành công, 0 lần thất bại) tạo ra kết quả có thể tái tạo trên tất cả tám cấu hình. Sự cải thiện so với các giai đoạn trước đó chứng minh tính hiệu quả của phương pháp bộ nhớ đệm lạnh.
Câu hỏi mở
Tương tác giữa kích thước khối Pebble. Tất cả các thử nghiệm đều sử dụng khối 4KB. Các bài kiểm tra hiệu năng đọc trang NVMe cho thấy việc đọc ngẫu nhiên 16KB đạt được thông lượng gấp 2,3 lần so với đọc 4KB (174 so với 77 MB/s) với độ trễ chỉ gấp 1,8 lần (89,7 so với 50,6 µs). Các khối Pebble lớn hơn có thể mang lại lợi ích đáng kể cho các nhóm có độ sâu lớn hơn với các nút được tuần tự hóa vượt quá 4KB.
Xử lý khối đồng thời. Các bài kiểm tra hiệu năng này xử lý các khối theo trình tự. Các công cụ thực thi song song có thể phân bổ việc cập nhật cây trie trên các lõi, giảm thiểu chi phí băm lại trên mỗi nút đối với độ sâu nhóm lớn hơn. Các bài kiểm tra hiệu năng về độ sâu hàng đợi NVMe cho thấy QD=8 cải thiện thông lượng ngẫu nhiên 4KB lên 8,7 lần so với QD=1 (673 so với 77 MB/s). Nếu việc thực thi song song làm tăng độ sâu hàng đợi I/O hiệu quả, sự khác biệt về độ trễ đọc giữa các độ sâu nhóm có thể giảm đáng kể.
Các bài kiểm tra hiệu năng được thực hiện trên khung execution-specs của Ethereum. Phương pháp luận, dữ liệu thô và các kịch bản tái tạo có sẵn trong kho lưu trữ execution-specs .