

Tác giả: Dmytro Zakharov
Lời cảm ơn
Công trình này dựa trên nghiên cứu mà tôi đã thực hiện khi làm việc tại bộ phận nghiên cứu của Blockstream . Xin cảm ơn sự hỗ trợ và cơ hội được nghiên cứu chủ đề này của tất cả mọi người.
Tôi xin gửi lời cảm ơn đặc biệt đến Jonas Nikc vì đã xem xét kỹ lưỡng bài viết này và đưa ra những gợi ý rất hữu ích; và đến Mykyta Redko vì đã chỉ ra một số lỗi quan trọng trong phần giải thích.
giới thiệu
Việc công bố bài báo mới nhất đội ngũ Google Quantum AI đã làm dấy lên các cuộc thảo luận về thời điểm ra mắt "máy tính lượng tử an toàn về mặt mật mã (CRQC)" đầu tiên (thẳng thắn mà nói, ở một số nơi, điều này thậm chí đã trở thành một sự hoảng loạn). Quan điểm rất khác nhau, nhưng dường như mọi người đều đồng ý về một điểm: chúng ta cần chuyển sang các thuật toán an toàn lượng tử càng sớm càng tốt.
Tất nhiên, điều này là cần thiết đối với lượng lớn giao thức hiện đang được sử dụng; đặc biệt, trong Bitcoin(và không gian blockchain rộng hơn), bước đầu tiên tự nhiên là xây dựng một lược đồ chữ ký điện tử an toàn hậu lượng tử (PQ). Tuy nhiên, ngay cả bước đầu tiên này cũng gây ra nhiều tranh cãi: có nhiều lược đồ PQ thay thế, nhưng tất cả đều (a) kém hơn đáng kể so với cấu trúc “logarit phân tán (DL)” trên một chỉ báo nhất định (ít nhất là 16 lần); và (b) các giả định bảo mật cơ bản thường ít được nghiên cứu hơn (so với các phiên bản tiền lượng tử).
Hiện nay, chữ ký PQ chủ yếu được chia thành hai loại: dựa trên hàm băm và dựa trên mạng lưới . Blockstream đã thực hiện nhiều phân tích và nghiên cứu về mật mã dựa trên hàm băm: ví dụ, bài viết " Xem xét các lược đồ chữ ký dựa trên hàm băm cho Bitcoin " của Jonas Nick và Mikhail Kudinov, và lược đồ SHRIMPS do Jonas Nick đề xuất. Giờ là lúc để nghiên cứu xây dựng dựa trên mạng lưới!
Lời nhắc quan trọng
Chúng tôi lưu ý rằng cũng có những cấu trúc dựa trên mã, nhưng khóa công khai và chữ ký của chúng quá lớn: ví dụ, kích thước khóa công khai nhỏ nhất của LESS, một ứng cử viên (trước đây) quan trọng của NIST, là 13,9KB. Tuy nhiên, hiện tại, dường như đây không phải là một lựa chọn khả thi cho Bitcoin.
Chủ đề của bài viết này
Như đã đề cập trước đó, chúng tôi sẵn sàng phân tích các ý tưởng cơ bản đằng sau các lược đồ chữ ký dựa trên mạng lưới. Cụ thể, sau khi đọc bài viết này, người đọc sẽ có được sự hiểu biết vững chắc về một kỹ thuật quan trọng được gọi là "Fiat- Shamir có hủy bỏ "(còn được gọi là " lấy mẫu từ chối "), được sử dụng trong Dilithium và, ví dụ, nhiều hệ thống chứng minh dựa trên mạng lưới (xem " Chứng minh tích dựa trên mạng lưới "). Điều đáng ngạc nhiên là kỹ thuật này rất giống với việc xây dựng các chữ ký Schnorr truyền thống dựa trên giả định logarit rời rạc. Trong bài viết này, chúng tôi sẽ cung cấp một bộ công cụ cơ bản để giúp người đọc hiểu các lược đồ dựa trên mạng lưới, hy vọng sẽ giúp họ dễ dàng hơn khi bước vào lĩnh vực mật mã học này.
Cụ thể hơn, trong bài viết này, chúng ta sẽ bắt đầu với bài báo nổi tiếng " Chữ ký mạng không có cửa sập " để hiểu cấu trúc do tác giả Lyubashevsky đề xuất; bài báo này có lẽ là bài báo có ảnh hưởng nhất trong toàn bộ lĩnh vực mật mã mạng.
Giới thiệu cơ bản về lưới
lưới
Trước tiên, tôi xin giới thiệu đối tượng nghiên cứu của chúng tôi. Chúng tôi định nghĩa một "lưới" $m$ chiều $\Lambda \subseteq \mathbb{R}^d$ là tất cả các tổ hợp tuyến tính nguyên của một tập hợp các vectơ tuyến tính độc lập $\mathbf{b}_1,\dots,\mathbf{b}_m$ trên $ \ mathbb{R}^d$ (không gian thực d chiều), tức là:
$$
\begin{equation*}
\Lambda \triangleq \left{ \sum_{i=1}^m \lambda_i\mathbf{b}_i: \lambda_1,\dots,\lambda_m \in \mathbb{Z} \right}.
\end{equation*}
$$
Để hiểu điều này một cách trực quan hơn, đây là một ví dụ cụ thể: Hình ảnh bên dưới là một mạng lưới hai chiều (m=d=2).
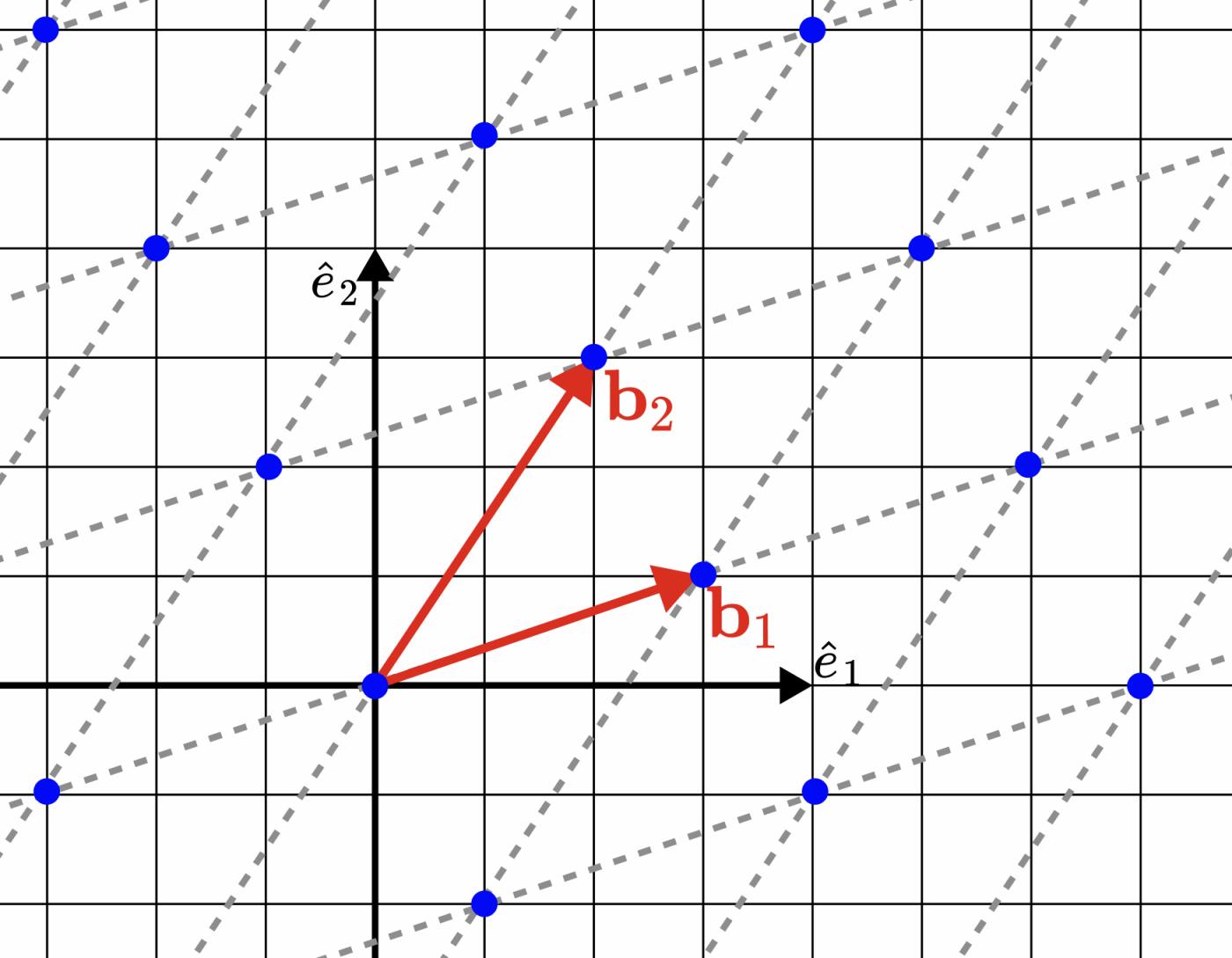
Hình 1. Một ví dụ về lưới hai chiều được tạo bởi các vectơ $b_1 = (3, 1)$ và $b_2 = (2, 3)$. Lưới $\Lambda$ thu được là một tập hợp các chấm màu xanh lam.
Khi lần đọc định nghĩa này, tôi không khỏi tự hỏi, "Một định nghĩa đơn giản như vậy thì có thể cung cấp thông tin hữu ích gì?" Tuy nhiên, từ rất lâu trước khi các nhà mật mã học nhận thấy rằng mạng lưới là nền tảng của nhiều bài toán khó tính toán, chúng đã được chứng minh là hữu ích về mặt toán học, ít nhất là từ thế kỷ 18. Trên thực tế, mạng lưới xuất hiện một cách tự nhiên trong nhiều lĩnh vực, chẳng hạn như lý thuyết số và bài toán xếp hình cầu (cả hai đều ít nhiều liên quan đến mật mã dựa trên mạng lưới và mật mã dựa trên mã).
Ghi chú:
Đôi khi tôi nghe thấy câu nói, "Mạng lưới còn quá non nớt so với mật mã dựa trên hàm băm." Tuy nhiên, đây là một quan niệm sai lầm, vì mạng lưới đã được sử dụng và nghiên cứu từ rất lâu trước khi các hàm băm được phát minh (khoảng năm 1950). :) Tuy nhiên, mạng lưới sở hữu cấu trúc đại số phong phú hơn các hàm băm. Mặc dù điều này có thể dẫn đến các giao thức mật mã tiên tiến hơn (ví dụ: chữ ký đa chữ ký hoặc SNARK), chúng ta vẫn phải thận trọng về tính bảo mật của chúng.
Bài toán mạng lưới trong mật mã học
Mật mã dựa trên mạng lưới xoay quanh một tập hợp các giả định có thể được quy giản thành việc giải các bài toán trên mạng lưới $\lambda$. Những bài toán này, đến lượt mình, hiện được cho rằng là bất khả giải ngay cả bởi máy tính lượng tử. Có rất nhiều giả định như vậy, bao gồm: Bài toán vectơ ngắn nhất ( SVP ), Bài toán vectơ gần nhất ( CVP ), Giải mã khoảng cách hữu hạn ( BDD ), Bài toán đẳng cấu mạng lưới ( LIP ), Bài toán vectơ ngắn nhất xác định ( GapSVP ), v.v.
Trong bài viết này, chúng ta chỉ giới thiệu một trong đó những giả định.
Bài toán vectơ ngắn nhất (xấp xỉ) ($\gamma$-SVP) nhằm mục đích tìm một vectơ "rất ngắn" trên lưới $\Lambda$. Chúng ta có thể (tương đối dễ dàng) chứng minh rằng $\Lambda$ chứa vectơ ngắn nhất này (tức là tồn tại $\mathbf{u} \in \Lambda$ sao cho $|\mathbf{u}|=\min_{\mathbf{v} \in \Lambda}|\mathbf{v}|$, có độ dài được ký hiệu là $\lambda_1(\Lambda)$. Tuy nhiên, việc tìm ra một vectơ như vậy được cho rằng một bài toán khó ngay cả đối với máy tính lượng tử. Chúng ta gọi bài toán này là " SVP ".
Tuy nhiên, việc phát triển một giao thức thực tế dựa trên bài toán SVP "trần" này gần như là không thể. Do đó, chúng tôi nới lỏng các yêu cầu: giả sử chúng ta chấp nhận các vectơ có chuẩn nhỏ hơn $\gamma\lambda_1(\Lambda)$, thì chỉ cần hệ số $\gamma>1$. Có thể chứng minh rằng bài toán được sửa đổi như vậy vẫn đủ khó ngay cả với các hệ số lớn, chẳng hạn như $\gamma=\mathsf{poly}(\sqrt{d})$. Bài toán được sửa đổi này được gọi là "$\gamma$ -SVP ". (Ghi chú của người dịch: Chuẩn là một hàm ánh xạ các vectơ trong không gian vectơ đến các số thực. Nói cách khác, mỗi chuẩn tương ứng với một cách xác định độ dài của một vectơ; giá trị chuẩn có thể được hiểu là độ dài.)
Vấn đề này có thể được minh họa bằng sơ đồ sau.
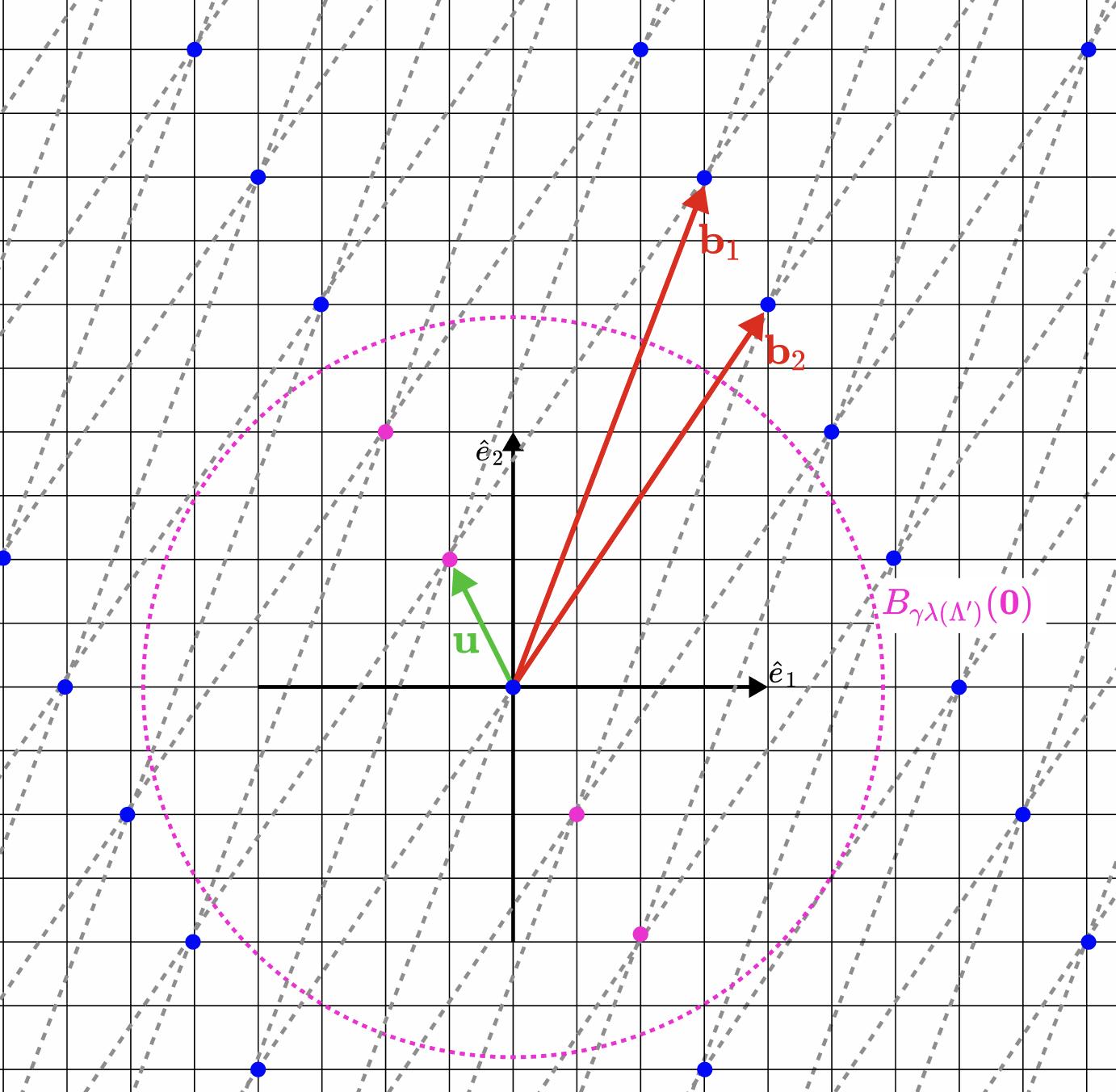
* Hình 2. Giải thích về $\gamma$ -SVP . Giả sử lưới $\Lambda'$ được tạo bởi các vectơ $\mathbf{b}_1=(3,8)$ và $\mathbf{b}_2=(4,6)$ (ngẫu nhiên, nó là một lưới con của lưới $\Lambda$ được định nghĩa trong Hình 1 ở trên). Hai vectơ ngắn nhất của nó là $\mathbf{u}=(-1,2)$ và $-\mathbf{u}$, cả hai đều có độ dài $\lambda_1(\Lambda')=\sqrt{5}$. Trong phiên bản gần đúng này của $\gamma$ -SVP , $\gamma$ xấp xỉ bằng 2,61 , vì vậy chúng ta chỉ cần tìm các vectơ có độ dài ngắn hơn $\sqrt{34}$ (các phạm vi này được đánh dấu bằng các vòng tròn màu tím trong hình). Ví dụ, độ dài của $\mathbf{u}'=(2,-4)$ là $\sqrt{20}$. Đây là nghiệm cho SVP xấp xỉ, nhưng không phải là nghiệm cho SVP chuẩn.
giải pháp số nguyên ngắn
Mặc dù các hệ mật mã có thể được xây dựng trực tiếp dựa trên giả thuyết mạng lưới (như Hawk đã làm), nhưng nói chung chúng ta sử dụng một giả thuyết thay thế (có thể quy về giả thuyết mạng lưới). Các ví dụ nổi tiếng nhất là " Giải pháp số nguyên ngắn ( SIS )" và " Học tập với sai số ( LWE )". Trong bài viết này, chúng ta sẽ chỉ thảo luận về giải pháp SIS.
Giả sử ta có một phương trình tuyến tính $\mathbf{Ax}=0$, trong đó$\mathbf{A} \in \mathbb{Z} q^{n \times m}$ (A$ là ma trận số nguyên có kích thước $n \times m$). Việc tìm nghiệm của phương trình này rất dễ (ví dụ, bằng phương pháp khử Gauss). Tuy nhiên, giả sử ta cũng yêu cầu nghiệm của $\mathbf{x} \in \mathbb{Z}^m$ phải "ngắn", tức là $|\mathbf{x}| {\infty} < \beta$ (trong đó$|\mathbf{x}| {\infty} := \min {i \in [m]}|x_i|$ là chuẩn $\ell^{\infty}$ của $\mathbf{x}$), và $\beta \ll q$. Điều này trở thành một trường hợp của bài toán tìm lời giải số nguyên ngắn, được ký hiệu là $\mathsf{SIS}_{q,n,m,\beta}$; và, với các giá trị $q,n,m,\beta$ được lựa chọn cẩn thận, việc giải bài toán này cực kỳ khó khăn ngay cả đối với máy tính lượng tử.
(Ghi chú của người dịch: Vì một lý do nào đó, định nghĩa chuẩn $\ell^{\infty}$ được tác giả sử dụng ở đây dường như khác với định nghĩa thông thường, vốn lấy giá trị lớn nhất của các phần tử, do đó yêu cầu giải pháp số nguyên ngắn gọn là giá trị của vectơ trong bất kỳ chiều nào đều nhỏ hơn $\beta$.)
Bài tập 1. Chứng minh rằng miễn là $m>\frac{n\log q}{\log(1+\beta)}$, thì $\mathsf{SIS}_{q,n,m,\beta}$ có nghiệm.
Hơn nữa, chúng ta sử dụng $S_{\eta}$ để chỉ tập hợp các vectơ "ngắn", tức là:
$$
\begin{equation*}
S_{\eta} := {\mathbf{x} \in \mathbb{Z}^n: |\mathbf{x}|_{\infty} \leq \eta}.
\end{equation*}
$$
SIS không lần
Một điều chỉnh quan trọng đối với giả định này là xem xét phiên bản không lần của cùng một phương trình: $\mathbf{Ax}=\mathbf{t}$. Sự điều chỉnh này cho phép chúng ta xem xét các giả thuyết xác định thay vì các giả thuyết tìm kiếm. Cụ thể, chúng ta đưa ra giả thuyết " Giải pháp số nguyên ngắn không đồng nhất ( ISSIS )", cho rằng việc phân biệt giữa hai phân bố $D_0$ và $D_1$ là một vấn đề khó khăn về mặt tính toán:
- $D_0$: Một mẫu được chọn ngẫu nhiên từ $\mathbb{Z}_q^{n \times m} \times \mathbb{Z}_q^n$.
- $D_1$: Lấy mẫu ngẫu nhiên $A \gets_R \mathbb{Z} q^{n \times m}$, lấy mẫu một vectơ ngắn $\mathbf{s} \in \mathbb{Z}^m$ (tức là $|\mathbf{s}| {\infty} < \delta$), tính $\mathbf{t} \gets \mathbf{As}$, và sau đó xuất ra bộ $(\mathbf{A}, \mathbf{t})$.
Chúng ta có thể chứng minh rằng ISIS tương đương với SIS khi $\beta$ và $\delta$ cơ bản có mối liên hệ thích hợp. Giả thiết này cho phép chúng ta phát triển phương pháp tạo khóa sau:
- Private key là một ma trận $\mathbf{S} \in S_{\eta}^{m \times k}$, bao gồm các phần tử ngắn.
- Khóa công khai là $\mathbf{T} := \mathbf{AS}$, trong đó$\mathbf{A} \in \mathbb{Z}_q^{n \times m}$ được lấy mẫu ngẫu nhiên.
Bài tập 2. Chứng minh rằng bài toán khôi phục private key từ khóa công khai tương đương với việc giải ISIS (giả sử $k=\mathsf{poly}(n)$).
Mối quan hệ với vụ việc
Có thể bạn đang nghĩ: Thế còn lưới thì sao? Điều này có liên quan gì đến lưới? Một lời giải thích phù hợp với bài đăng trên blog này là: đối với các trường hợp của $\mathsf{SIS}_{q,n,m,\beta}$ của ma trận $\mathbf{A}$, một lưới có thể được định nghĩa như sau:
$$
\begin{equation*}
\Lambda_A^{\perp} = {\mathbf{z} \in \mathbb{Z}^m: \mathbf{Az} = 0 ; (\text{mod} ; q)}.
\end{equation*}
$$
Nhận định : Giải $\mathsf{SIS}_{q,n,m,\beta}$ tương đương với việc giải $\gamma$ -SVP dưới $\gamma$ thích hợp. Điều này có thể thấy từ định nghĩa của $\Lambda_A^{\perp}$: bất kỳ vectơ nào trong lưới này đều là nghiệm của $\mathbf{A}\mathbf{x}=0$; nếu chúng ta muốn giải SVP của lưới này, về cơ bản chúng ta đang tìm kiếm các nghiệm nguyên ngắn cho phương trình này, điều này chính xác là những gì SIS yêu cầu.
Fiat-Shamir Transform with Dừng giữa chừng
động lực
Chúng ta đã thấy rằng giả thiết dựa trên lưới cho phép ta xây dựng một ánh xạ một chiều $\mathbf{S} \mapsto \mathbf{AS}$ cho một ma trận $\mathbf{A}$ và một ma trận “ngắn” $\mathbf{S}$. Điều này phần nào tương tự như ánh xạ $s \mapsto a^s$ là một chiều trong một nhóm cyclic $\mathbb{G}=\langle a \rangle$, với điều kiện giả thiết về logarit rời rạc được thỏa mãn. Điều này dẫn chúng ta đến câu hỏi sau:
Liệu chúng ta có thể "tái tạo" giao thức chữ ký Schnorr bằng cách thay thế phép ánh xạ nhân nhóm $s \mapsto a^s$ bằng $\mathbf{S} \mapsto \mathbf{A}\mathbf{S}$ không?
Có thể chứng minh rằng câu trả lời là có! Tuy nhiên, mọi chuyện không đơn giản như vậy, đó chính là nguồn gốc của tiền tố "với dừng giữa chừng". Trong phần này, chúng ta sẽ xem cách biến ý tưởng này thành hiện thực.
Kế hoạch chữ ký Schnorr
Không cần dài dòng nữa, chúng ta hãy cùng xem lại cách thức hoạt động của chữ ký Schnorr. Mô tả một lược đồ chữ ký có nghĩa là định nghĩa ba quy trình sau:
- $\mathsf{KeyGen}(1^{\lambda}) \to (\mathsf{pk}, \mathsf{sk})$ : Tạo một cặp khóa;
- $\mathsf{Sign}(\mathsf{sk},\mu) \to \mathsf{sig}$: Ký thông điệp $\mu$ bằng private keysk , từ đó tạo ra chữ ký sig ;
- $\mathsf{Verify}(\mathsf{pk},\mu,\mathsf{sig}) \to {0,1}$: Xác minh chữ ký sig dựa trên khóa công khai pk và thông điệp $\mu$.
Chữ ký Schnorr được cho là lược đồ chữ ký thanh lịch, hiệu quả và đơn giản nhất dựa trên giả định logarit rời rạc, và hiện đang được sử dụng rộng rãi trong Bitcoin . Tuy nhiên, tốt nhất nên bắt đầu với giao thức xác thực Schnorr . Cụ thể, giả sử có một nhóm có bậc q $\mathbb{G}$, được tạo bởi $g \in \mathbb{G}$; sau đó, để chứng minh rằng người ký biết private key $\alpha$ tương ứng với khóa công khai $h \in \mathbb{G}$ ( trong đó $g^{\alpha}=h$), người đó tham gia vào giao thức tương tác sau:

* Hình 3. Giao thức nhận dạng danh tính Schnorr, dựa trên cặp khóa $(\alpha,h)$ ( trong đó$h=g^{\alpha}$*)
(Ghi chú của người dịch: Quá trình tương tác như sau: người ký chọn một số ngẫu nhiên r và gửi giá trị tương ứng a trong nhóm cho người xác minh; người xác minh chọn một số ngẫu nhiên e và gửi cho người ký; người ký sử dụng r, e và private key để tính toán z và đưa kết quả cho người xác minh.)
Phép biến đổi Fiat-Shamir cho phép người ký tránh tương tác với người xác minh bằng cách suy ra $e$ bằng cách sử dụng hàm băm $\mathsf{H}: \mathbb{G}^2 \to \mathbb{Z}_q$. Cụ thể, người ký tính toán giá trị thử thách $e \gets \mathsf{H}(h,a)$, tạo ra "bằng chứng" $(e,z)$. Cuối cùng, để phát triển một lược đồ chữ ký , thông điệp $\mu$ cũng có thể được bao gồm trong quá trình suy ra giá trị thử thách $e$. Do đó, $\mathsf{Sign}(h,\mu)$ trông như thế này:
- Xây dựng cam kết $g^r$ cho hệ số che giấu ngẫu nhiên $r \gets_R \mathbb{Z}_q$, tương tự như giao thức nhận dạng danh tính ở trên;
- Tính giá trị thử thách: $e \gets \mathsf{H}(\mu,a)$ ;
- Tính giá trị vô hướng $z = r + \alpha e$, giá trị này che giấu giá trị bí mật $\alpha$; xuất $(e, z)$ dưới dạng chữ ký.
Cuối cùng, người xác minh kiểm tra chữ ký $(h,\mu,\sigma)$ bằng $e=_?\mathsf{H}(\mu, g^zh^{-e})$.
Lần thử #1: Chữ ký Schnorr với ký tự "格"
Vì chúng ta đã phát hiện ra rằng $\mathbf{S} \mapsto \mathbf{AS}$ trông rất giống với lớp tiền lượng tử $\alpha \mapsto g^{\alpha}$, hãy thử trực tiếp đưa ánh xạ một chiều này vào giao thức nhận dạng danh tính Schnorr, như thể hiện trong Hình 4. Theo hướng suy nghĩ đã đề cập trước đó, nỗ lực này là bước đầu tiên tự nhiên (chúng ta củng cố r , a và e để phép nhân ma trận trở nên có ý nghĩa):
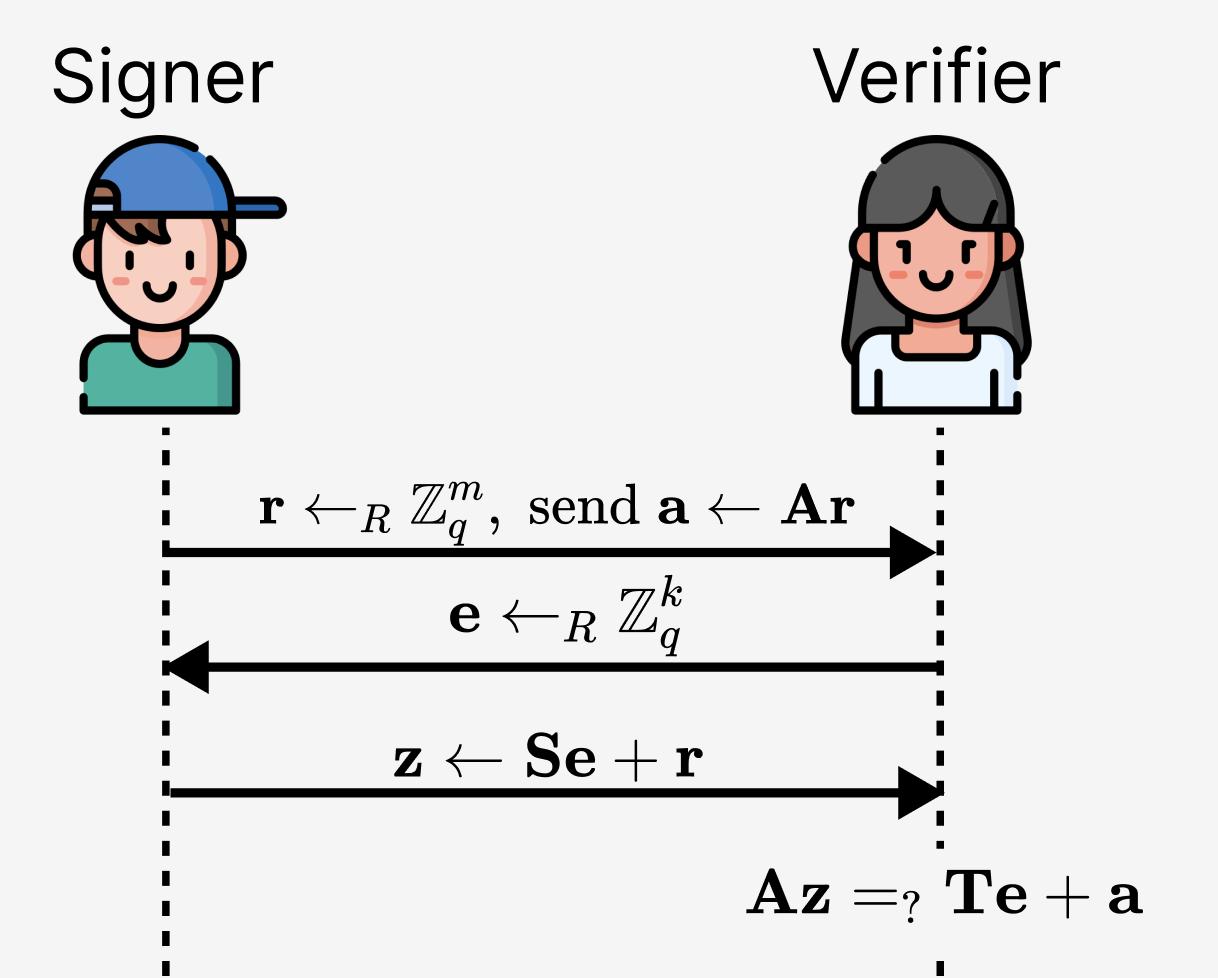
Hình 4. Nỗ lực lần đối với giao thức nhận dạng danh tính Schnorr “lưới”, với cặp khóa là $(\mathbf{S},\mathbf{T})$ ($\mathbf{T}=\mathbf{AS}$, trong đó$\mathbf{T} \in \mathbb{Z}_q^{n \times k}$, $\mathbf{A} \in \mathbb{Z}_q^{n \times m}$, và $\mathbf{S} \in \mathbb{Z}_q^{m \times k}$).
Trước tiên, liệu phương án này có chính xác về mặt hình thức không? Hãy thay thế mọi thứ vào phương trình kiểm chứng và xem:
$$
\begin{equation*}
\mathbf{Az} = \mathbf{A}(\mathbf{S}\mathbf{e}+\mathbf{r}) = (\mathbf{AS})\mathbf{e}+(\mathbf{A}\mathbf{r}) = \mathbf{Te}+\mathbf{a}.
\end{equation*}
$$
Do đó, về mặt hình thức, kế hoạch này là đúng. Nhưng liệu nó có đáng tin cậy? Chắc chắn là không. Có rất nhiều cách mà kế hoạch này có thể thất bại. Ví dụ:
- Cho $\mathbf{a} \in \mathbb{Z}_q$, ta dễ dàng tìm được r từ phương trình cam kết $\mathbf{a}=\mathbf{Ar}$. Thực tế, đây chỉ đơn giản là giải một phương trình tuyến tính trên $\mathbb{Z}_q$.
- Ngay cả khi giả sử cam kết 'a' bị ràng buộc, vẫn có thể tìm được một 'z' thỏa mãn phương trình $\mathbf{Az}=\mathbf{Te}+\mathbf{a}$, ngay cả khi không biết private keyS. Một lần nữa, điều này chỉ đơn giản là giải một phương trình tuyến tính sau khi có được bất kỳ ' e' nào .
Dường như chúng ta đang bế tắc ở điểm này.
Thử cách #2: Thu nhỏ mọi thứ
Lưu ý rằng "Thử nghiệm #1" không an toàn vì chúng ta có thể dễ dàng ngụy tạoz và dễ dàng lấy được a từ r . Điều này là do chúng chỉ đơn giản là các nghiệm tùy ý của hệ phương trình tuyến tính tương ứng. Như chúng ta đã thấy trong giả thuyết SIS , chúng ta cần cả z và r phải "ngắn" để đảm bảo độ tin cậy của giao thức này. Do đó, thử nghiệm lần nhằm mục đích đạt được điều đó. Chúng ta sẽ lấy mẫu ngẫu nhiên r từ một số phân phối ngắn $\chi^m$ (hãy tưởng tượng có một số phân phối xác suất $\chi$ trên $\mathbb{Z} q$ mà chuẩn của một giá trị được lấy mẫu bị giới hạn ở một $\varepsilon \in \mathbb{Z} {>0}$ nhỏ ). Việc làm cho z (và $\mathbf{r}+\mathbf{Se}$) ngắn hơn sẽ khó hơn: mặc dù r hiện đã ngắn, chúng ta cũng cần đảm bảo rằng Se cũng ngắn. Kết quả là, vì S đã là một giá trị nhỏ, chúng ta cần đảm bảo rằng e vừa ngắn vừa có một tập hợp các giá trị có thể đủ lớn. Cụ thể, chúng ta sẽ lấy mẫu từ tập hợp $B_{\kappa}$:
$$
\begin{equation*}
B_{\kappa} := {\mathbf{x} \in \mathbb{Z}_q^k: x_i \in {0,\pm 1} ; \text{và số lượng x_i khác 0 là $\kappa$}}.
\end{equation*}
$$
Thành thật mà nói, tập hợp này xuất hiện một cách đột ngột (giống như nhiều thứ khác trong mật mã dựa trên mạng lưới). Lý do sử dụng tập hợp này có lẽ như sau:
- Chúng ta muốn tập hợp các giá trị thử thách đủ lớn; tập hợp này thỏa mãn điều kiện này (xem Bài tập 3 bên dưới);
- Chúng ta muốn tất cả các phần tử trong tập hợp các giá trị thử thách này đều đủ nhỏ; điều này rõ ràng cũng đúng, bởi vì với mọi $\mathbf{e} \in B_{\kappa}$, ta có $|\mathbf{e}|_{\infty}=1$;
- Lý tưởng nhất, chúng ta muốn việc triển khai hàm băm cho $B_{\kappa}$ càng đơn giản càng tốt: điều này cũng đúng vì các phần tử trong $B_{\kappa}$ có thể được xem như một chuỗi tam phân.
Bài tập 3. Chứng minh hai tính chất của tập hợp các giá trị thử thách $B_{\kappa}$: (a) $#B_{\kappa}=2^{\kappa}\binom{k}{\kappa}$ (tức là tập hợp này rất lớn); (b) với bất kỳ $\mathbf{S} \in S_{\eta}^{m \times k}$, ta có $|\mathbf{Se}|_{2} \leq \eta\kappa\sqrt{m}$, trong đó$|\cdot|_2$ biểu thị chuẩn Euclidean (tức là ta có một giới hạn tốt cho giá trị chuẩn của Se cần được đưa vào tính toán z ).
Bây giờ, vì e và r đều ngắn, nên z cũng ngắn. Do đó, để ngăn chặn kẻ thù gửi các giá trị e và r lớn, chúng ta cần kiểm tra xem $|\mathbf{z}| 2$ có đủ nhỏ hay không (tức là nhỏ hơn một ngưỡng nhất định $\tau$; bạn có thể hiểu điều này là $\tau:=\max {\mathbf{e} \in B_{\kappa}}|\mathbf{Se}| 2 + \mathbb{E} {\mathbf{r} \sim \chi^m}[|\mathbf{r}|_2]$, nhưng điều này không liên quan đến mức độ thảo luận hiện tại của chúng ta).
Với những điều chỉnh này, lần thử lần của chúng tôi trông như thế này:
Hình 5. Lần thử lần đối với giao thức nhận dạng danh tính Schnorr “lưới”, với cặp khóa $(\mathbf{S},\mathbf{T})$ ($\mathbf{T}=\mathbf{AS}$, trong đó$\mathbf{T} \in \mathbb{Z}_q^{n \times k}$, $\mathbf{A} \in \mathbb{Z}_q^{n \times m}$ và $\mathbf{S} \in \mathbb{Z}_q^{m \times k}$).
Giải pháp này có đúng không? Đúng, vì lý do tương tự như "Cách thử số 1".
Liệu nó có đáng tin cậy không? Ừm, hãy cùng xem xét một vài cuộc tấn công "đơn giản":
- Liệu ta có thể tìm được r ngắn hơn sao cho $\mathbf{Ar}=\mathbf{a}$? Điều này tương đương với việc giải ISIS, và do đó dường như không khả thi về mặt tính toán.
- Liệu ta có thể tìm được z ngắn hơn sao cho $\mathbf{Az}=\mathbf{Te}+\mathbf{a}$ không? (Tức là, không cần biết S ). Đây lại là một ví dụ về bài toán ISIS, cũng rất khó giải.
Vậy... giờ chúng ta có thể khẳng định kế hoạch này đáng tin cậy rồi chứ?
KHÔNG! :- (
Tuy nhiên, trong đó lẽ ở đây khá tinh tế và sẽ dễ phát hiện hơn trong quá trình chứng minh tính bảo mật. Dưới đây là một giải thích đơn giản: tóm lại, toàn bộ mục đích của việc tính toán z là để "che giấu" giá trị bí mật S đằng sau nó. Nhưng liệu ta có thể nói rằng z và S độc lập với nhau không? Không nhất thiết.
Ghi chú:
Nếu bạn đang cố gắng nhớ lại bằng chứng bảo mật của chữ ký Schnorr, lời giải thích sau đây có thể hữu ích hơn: Hãy nhớ rằng bằng chứng của EUF-CMA (ngụy tạo tồn tại dưới tấn công bằng văn bản rõ được chọn) bao gồm hai phần: (a) mô phỏng một người ký trung thực; và (b) sử dụng "định lý fork nhánh" để trích xuất giá trị bí mật đằng sau nó. Trong Hình 5 , hoàn toàn không rõ cách thực hiện (a): cụ thể là lấy mẫu z ở đâu. Ngay cả khi chúng ta biết phân bố của z , nó có thể phụ thuộc vào S , điều này sẽ gây ra vấn đề trong quá trình mô phỏng.
Vì lý do này, chúng ta cần làm cho z và S độc lập với nhau. Nhưng làm thế nào để thực hiện điều đó? Có thể chứng minh rằng ý tưởng sau đây sẽ hữu ích:
Khi tạo cặp ứng viên $(\mathbf{e},\mathbf{z})$, trước tiên hãy kiểm tra xem z thu được có "đủ tốt" hay không. Nếu không, hãy loại bỏ nó và lặp lại quá trình ký.
Đây là lý do tại sao mô hình này được gọi là "lấy mẫu từ chối" hoặc "biến đổi Fiat-Shamir có dừng giữa chừng ": nếu chúng ta không hài lòng với các giá trị được tạo ra, chúng ta dừng giữa chừng quá trình ký tên. Nhưng điều gì tạo nên "đủ tốt" cho z ? Để làm điều này, chúng ta chọn một phân phối $\chi$ cụ thể tạo ra một số thuộc tính hữu ích, và sau đó xem khi nào khoảng cách thống kê giữa z và S là không đáng kể.
Phân phối Gaussian rời rạc
Nếu bạn cho rằng việc lựa chọn không gian giá trị thử thách $B_{\kappa}$ là tùy ý, thì tôi sẽ nói rằng đây chính xác là điều mà tôi cho là hoàn toàn tùy ý khi mới bắt đầu tìm hiểu về chữ ký điện tử dựa trên mạng lưới. Giới thiệu một phân bố Gauss $\Lambda \subseteq \mathbb{R}^m$ trên mạng lưới $\Lambda \subseteq \mathbb{R}^m$, với tham số độ rộng (độ lệch chuẩn) là $\sigma \in \mathbb{R} {>0}$ và giá trị trung bình là $\mathbf{v} \in \mathbb{R}^m$, như sau:
$$
\begin{equation*}
D {\mathbf{v},\sigma,\Lambda}^m(\mathbf{z}) := \rho_{\mathbf{v},\sigma}^m(\mathbf{z})/\rho_{\mathbf{v},\sigma}^m(\Lambda) ; \text{trong đó} ; \rho_{\mathbf{v},\sigma}^m(\mathbf{z}) := \exp(-|\mathbf{z}-\mathbf{v}|_2^2/2\sigma^2).
\end{equation*}
$$
(Ghi chú của người dịch: "Phân phối Gauss" tương đương với "phân phối chuẩn".)
Ở đây, chúng ta sẽ sử dụng ký hiệu không chính xác, dùng $\rho_{\sigma}^m(\Omega)=\sum_{\mathbf{w} \in \Omega}\rho_{\sigma}^m(\mathbf{w})$ để biểu diễn phân bố trên một tập rời rạc $\Omega \subseteq \mathbb{R}^m$. Chúng ta bỏ qua $\Lambda$ và $\mathbf{v}$ trong chỉ số khi chúng lần lượt bằng $\Lambda=\mathbb{Z}^m$ và $\mathbf{v}=0$.
Định nghĩa này có lẽ cần một vài giải thích. Ý tưởng chính ở đây là chúng ta muốn xác suất mỗi điểm z xuất hiện trên lưới $\Lambda$ tỷ lệ thuận với $\exp(-|\mathbf{z}-\mathbf{v}| 2^2/2\sigma^2)$. Để chuyển đổi điều này thành một phân phối xác suất hiệu quả, chúng ta cần chia tất cả các xác suất cho một hằng số chuẩn hóa $\sum {\mathbf{w} \in \Lambda}\exp(-|\mathbf{w}-\mathbf{v}|_2^2/2\sigma^2)$.
Về nguyên tắc, nó được gọi là "Phân phối Gauss rời rạc " chính xác là vì nó rất giống với phân phối Gauss liên tục (mật độ của chúng là $e^{-|\mathbf{z}-\mathbf{v}|^2/2\sigma^2}/\int_{\mathbb{R}^m}e^{-|\mathbf{z}-\mathbf{v}|^2/2\sigma^2}\text{d}\mathbf{z}$; trong phân phối liên tục, tích phân ở mẫu số rất dễ tính). Hơn nữa, nếu bạn đã từng thấy hình dạng của phân phối này, bạn sẽ ngay lập tức nhận ra nó là một phân phối Gauss đa biến chuẩn:
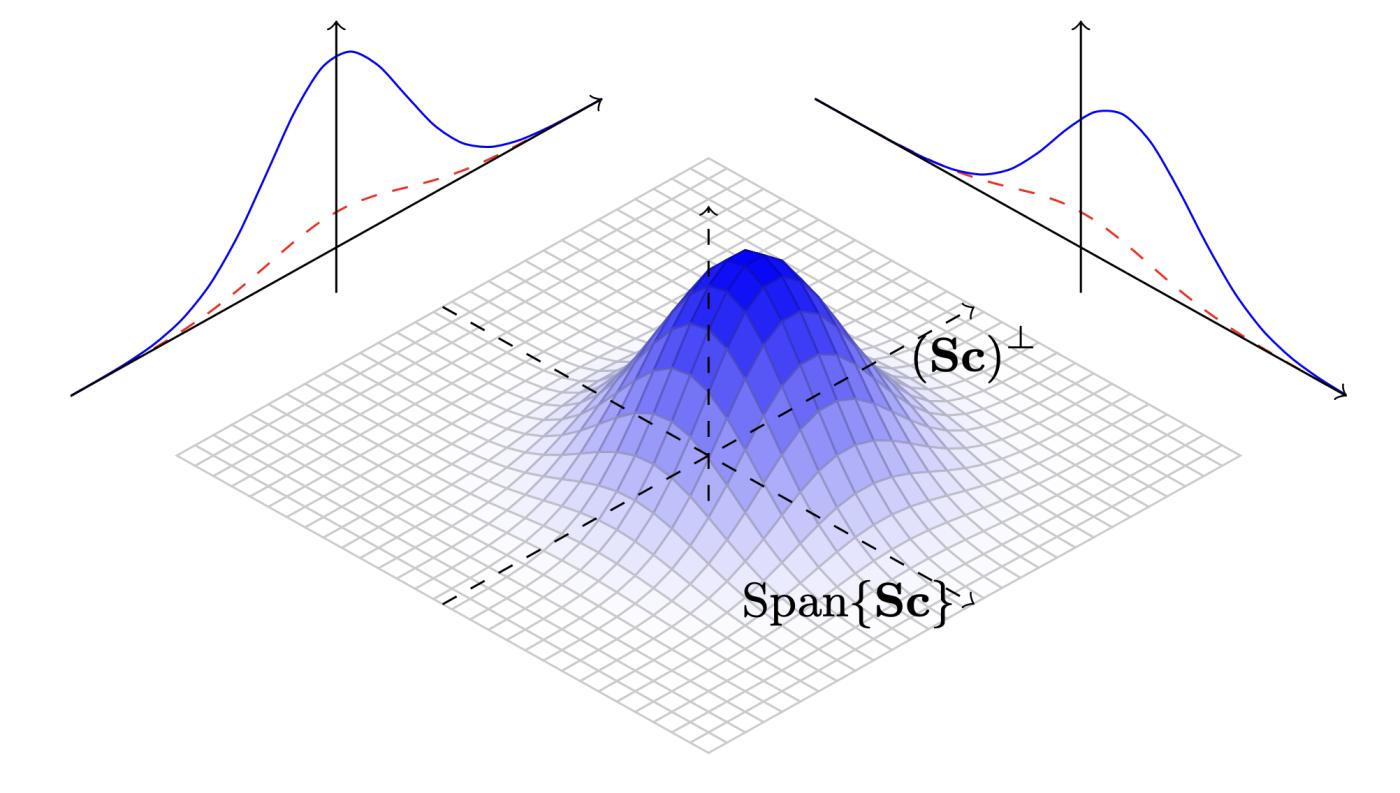
Hình 6. Phân bố Gaussian rời rạc 2D. Hình ảnh từ bài báo " Dấu hiệu mạng lưới và Gaussian hai đỉnh " của Ducas, Durmus, Lepoint và Lyubashevsky.
Tại sao lại sử dụng phân phối Gauss rời rạc?
Tôi cho rằng câu trả lời cho câu hỏi "tại sao lại chọn phân phối cụ thể này" cũng tương tự như việc hỏi tại sao phân phối Gaussian liên tục được sử dụng trong thống kê. Đó là một lựa chọn tự nhiên vì nó có những đặc tính tốt trong nhiều phép toán khác nhau (ví dụ: nó có thể thực hiện biến đổi Fourier và phép chập; tổng của các phân phối Gaussian rời rạc về mặt thống kê gần với một phân phối Gaussian rời rạc duy nhất, v.v.).
Tuy nhiên, trong bài toán của chúng ta (làm cho z và S độc lập về mặt xác suất), chúng ta cần hai thuộc tính của phân phối Gauss rời rạc.
Thuộc tính (A) ( Xác suất lấy mẫu một vectơ ngắn từ $D_{\sigma}^m$ là cực kỳ cao ). Đối với bất kỳ $\beta>1$ nào, ta có:
$$
\begin{equation*}
\text{Pr}[|\mathbf{z}| 2>\beta\sigma\sqrt{m} ; | ; \mathbf{z} \gets_R D {\sigma}^m] < \beta^me^{m(1-\beta^2)/2}.
\end{equation*}
$$
* Thuộc tính (B) ( Tỷ lệ giữa phân phối Gaussian trung tâm và phân phối Gaussian không trung tâm hầu như luôn bị chặn*) Đối với bất kỳ $\mathbf{v} \in \mathbb{Z}^m$, miễn là $\sigma=\alpha|\mathbf{v}|$, ta có:
$$
\begin{equation }
\text{Pr}[D_{\sigma}^m(\mathbf{z})/D_{\mathbf{v},\sigma}^m(\mathbf{z}) < e^{12/\alpha+1/(2\alpha^2)} ; | ; \mathbf{z} \gets_R D_{\sigma}^m] > 1 - 2^{-100}.
\end{equation }
$$
Việc chứng minh cả hai tính chất đều đòi hỏi lượng lớn. Ví dụ, hãy xem Chương 4 trong bài báo gốc của Lyubashevsky . Chúng ta sẽ ký hiệu hằng số "kỳ diệu" này là $e^{12/\alpha+1/(2\alpha^2)}$.
Bài tập 4. Giả sử $\alpha>1$, phạm vi có thể có của $M_{\alpha}$ là gì?
Mặc dù tôi cho rằngtính chất (A) khá trực quan (chúng ta sẽ sử dụng nó trên $\beta$ hơi lớn hơn 1.0), bạn vẫn có thể thắc mắc tại sao chúng ta cần tính chất (B) ? Phần tiếp theo sẽ giải thích điều đó.
Lấy mẫu từ chối
Bây giờ, giả sử $\chi^m := D_{\sigma}^m$ trong Hình 6. Vậy z được phân bố như thế nào? Vì $\mathbf{z}=\mathbf{Se}+\mathbf{r}$, và $\mathbf{r} \sim D_{\sigma}^m$ là một phân bố Gaussian rời rạc ở trung tâm, nên z sẽ là một phân bố Gaussian "có độ lệch" $D_{\mathbf{Se},\sigma}^m$ với một vectơ bù nhỏ là Se .
Đây là lúc đặc điểm truyền thống phát huy tác dụng: Sự phân bố của z phụ thuộc vào một độ lệch nhỏ Se ; do đó, bằng cách quan sát nhiều giá trị z sử dụng cùng một S , kẻ thù có thể thu thập thông tin về S.
Giá như ta có thể loại bỏ được độ lệch này... Thì định lý sau đây sẽ giúp ta giải quyết vấn đề:
Bổ đề. Cho $f$ và $g$ là hai phân phối xác suất, với tập hợp tất cả các giá trị có thể có (miền hỗ trợ) được ký hiệu là $\Omega$. Với mọi $\mathbb{R}_{\geq 1}$, $f(z) \leq Mg(z)$. Khi đó, phân phối sau (gọi là $\widetilde{f}$) giống với phân phối $f$:
- Lấy mẫu ngẫu nhiên $z \gets_R g$ .
- Xuất ra $z$ với xác suất $f(z)/Mg(z)$, nếu không thì quay lại bước 1.
Về cơ bản, ý tưởng đằng sau bổ đề này là nếu $f$ là "phân phối mục tiêu" của chúng ta và $g$ là "phân phối thực", thì miễn là có sự bất đẳng thức tốt giữa các điểm trong $f$ và $g$, chúng ta có thể mô hình hóa phân phối của $f$ bằng cách loại bỏ một số mẫu từ $g$ với xác suất độc lập với các giá trị được lấy mẫu.
Quá trình này có hình ảnh minh họa trực quan tốt như hình dưới đây (tương tự như Hình 7 , lấy từ bài báo BLISS, một hình minh họa thực sự xuất sắc). Giả sử rằng $f$ và $g$ thỏa mãn bất đẳng thức trong bổ đề, thì $Mg$ sẽ cao hơn $f$. Khi đó, lấy mẫu loại bỏ được hình thành trong hai bước: đầu tiên, chọn một điểm từ $Mg$; sau đó, nếu nó thấp hơn $f$, thì chấp nhận nó.
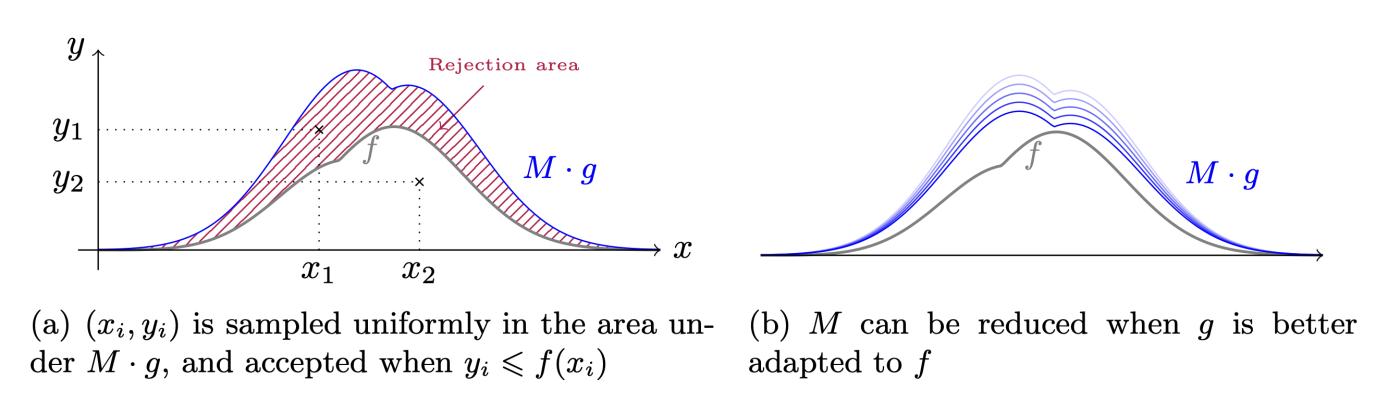
Hình 7. Minh họa quy trình lấy mẫu loại bỏ. Hình ảnh từ bài báo " Dấu hiệu mạng lưới và phân bố Gauss lưỡng cực " của Ducas, Durmus, Lepoint và Lyubashevsky.
Bổ đề này có gợi nhớ đến điều gì không? Kỹ thuật quan trọng là áp dụng bổ đề này như sau:
- Phân phối mục tiêu $f$ của chúng ta là một phân phối Gaussian rời rạc không thiên vị $D_{\sigma}^m$.
- Phân phối “thực” của chúng ta $g$ là một phân phối Gaussian lệch $D_{\mathbf{Se},\sigma}^m$.
Chúng ta có thể áp dụng bổ đề này không? Tính chất (B) là chìa khóa: chúng ta có một hằng số kỳ diệu $M_{\alpha}$ sao cho $D_{\sigma}^m(\mathbf{z}) \leq M_{\alpha}D_{\mathbf{Se},\sigma}^m$ đúng với xác suất rất cao! (Hơn nữa, chúng ta có thể dễ dàng xác nhận $\alpha$ từ thực tế là $|\mathbf{Se}|_2 \leq \eta\kappa\sqrt{m}$: xem Bài tập 3 ).
cảnh báo
Thà cẩn thận còn hơn hối tiếc, bổ đề phải được điều chỉnh sao cho bất đẳng thức $f(z) \leq Mg(z)$ xảy ra với xác suất rất lớn là $1-\varepsilon$. Sau đó, ta có thể chứng minh rằng, trong trường hợp này, khoảng cách thống kê giữa phân phối $\widetilde{f}$ và phân phối $f$ sẽ là $\varepsilon/M$.
Lần thử thứ 3: Chữ ký của Lyubashevsky
Cuối cùng, để sửa lỗi trong Hình 2 , chúng ta chỉ chấp nhận $(\mathbf{e},\mathbf{z})$ với xác suất $D_{\sigma}^m(\mathbf{z})/M_{\alpha}D_{\mathbf{Se},\sigma}(\mathbf{z})$. Điều này sửa toàn bộ lỗi, như thể hiện trong hình dưới đây.
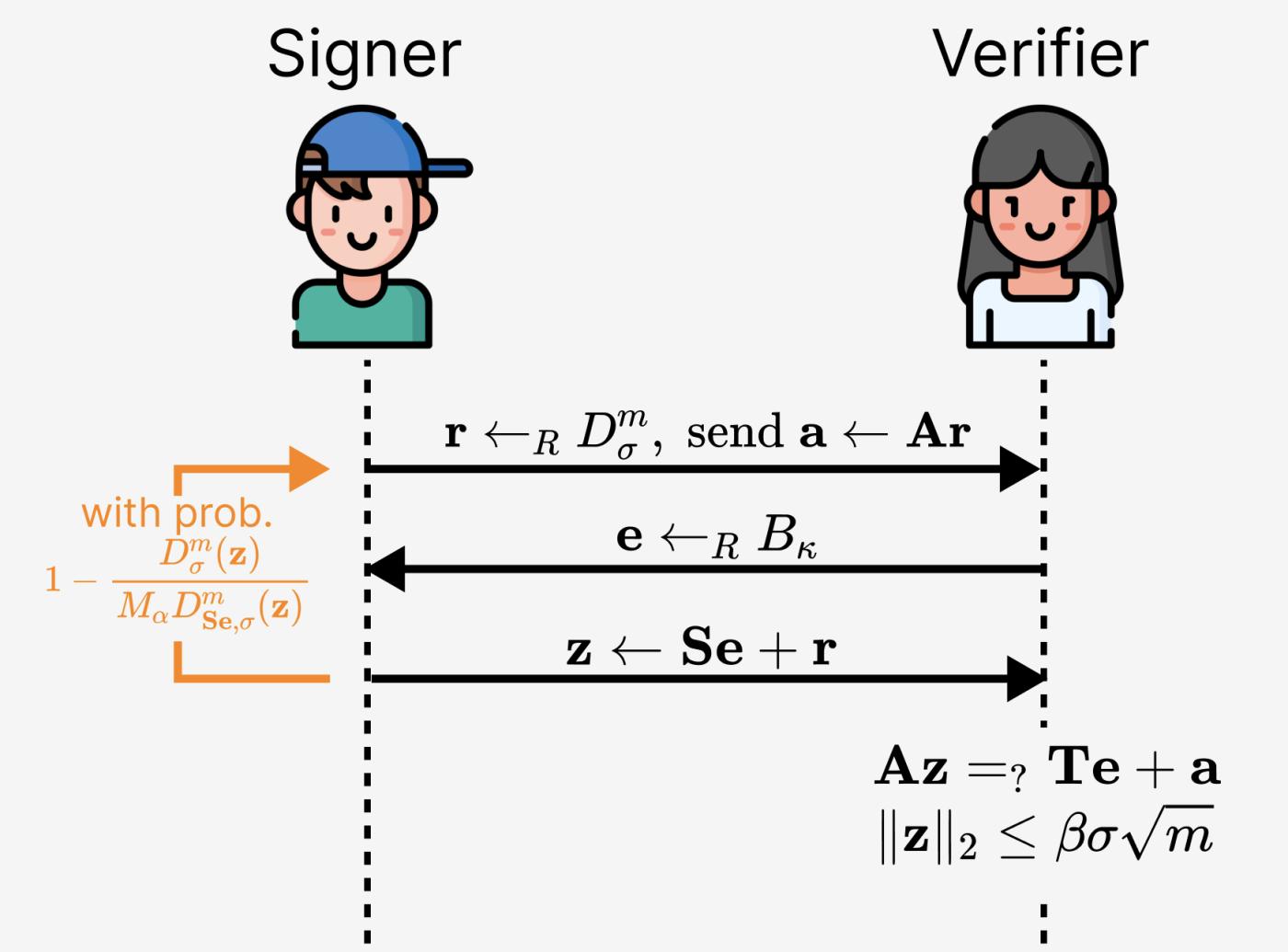
Hình 8. Sửa chữa giao thức Schnorr dựa trên mạng lưới (về cơ bản là một giải pháp ban đầu từ bài báo của Lyubashevsky).
Khung chứng nhận an toàn*
Ghi chú:
Phần sau đây là tùy chọn.
Tóm lại, để chứng minh rằng một lược đồ chữ ký là an toàn, chúng ta cần (a) mô phỏng một người ký trung thực; và (b) sử dụng bổ đề fork để tìm ra lời giải cho các trường hợp của một số bài toán khó về mặt tính toán.
Bước (a) là một ứng dụng đơn giản của bổ đề lấy mẫu loại bỏ: thay vì lấy mẫu trực tiếp $\mathbf{r} \gets_R D_{\sigma}^m$, tính giá trị thử thách $\mathbf{e} \gets \mathsf{H}(A\mathbf{r}, \mu) \in B_{\kappa}$, và xuất ra ứng viên $(\mathbf{e}, \mathbf{z}:=\mathbf{Se}+\mathbf{r})$, trước tiên chúng ta lấy mẫu $\mathbf{z} \gets_R D_{\sigma}^m$ và $\mathbf{e} \gets_R B_{\kappa}$, và lập trình lại oracle ngẫu nhiên thành $\mathsf{H}(\mathbf{Az}-\mathbf{Te},\mu) \gets \mathbf{e}$. .
Bước (b) giả định rằng kẻ thù có thể xuất ra một chữ ký hợp lệ $(\mathbf{z},\mathbf{e})$ với xác suất không nhỏ là $\delta$. Theo bổ đề fork, TA có thể xuất ra một chữ ký hợp lệ khác $(\mathbf{z}^*,\mathbf{e}^*)$ với xác suất $\propto \delta^2$. Hơn nữa, tính ngẫu nhiên cơ bản là như nhau, tức là:
$$
\begin{equation*}
\mathbf{Az} - \mathbf{Te} = \mathbf{Az}^*-\mathbf{Te}^*.
\end{equation*}
$$
Sử dụng thực tế $\mathbf{T}=\mathbf{AS}$, ta có thể thu được
$$
\begin{equation*}
\mathbf{A}((\mathbf{z}-\mathbf{z}^*)+\mathbf{S}(\mathbf{e}^*-\mathbf{e})) = 0,
\end{equation*}
$$
Trong đó,$(\mathbf{z}-\mathbf{z}^*)+\mathbf{S}(\mathbf{e}^*-\mathbf{e})$ là một nghiệm rút gọn cho phương trình tuyến tính $\mathbf{Ax}=0$. Do đó, chúng ta xây dựng một phép quy giản diễn giải chữ ký như là việc giải một trường hợp SIS xấp xỉ.
hiệu suất
Thẳng thắn mà nói, phương án nêu trên rất kém hiệu quả. Với các thông số được đề xuất trong bài báo gốc, kích thước chữ ký là 19,9KB, trong khi kích thước khóa công khai là 128KB. Tuy nhiên, ý tưởng trình bày ở trên có thể được tối ưu hóa theo nhiều cách. Cụ thể:
Hầu hết các chữ ký không sử dụng $\mathbb{Z}_q$, mà thay vào đó sử dụng vành $\mathcal{R}_q := \mathbb{Z}_q[X]/(X^d+1)$, trong đó$d$ là lũy thừa của 2. Lý do tại sao vành này hiệu quả nằm ngoài phạm vi bài viết này.
Có thể chọn một phân phối khác ngoài phân phối Gaussian rời rạc. Ví dụ, lược đồ chữ ký BLISS đề xuất phân phối Gaussian hai đỉnh, trong khi các khía cạnh khác gần như giống hệt với cấu trúc trên. Kích thước chữ ký thu được là 5,6KB và kích thước khóa công khai là 7KB. Tuy nhiên, lược đồ này đã được chứng minh là không an toàn trước các cuộc tấn công kênh phụ.
Nếu ta thay đổi phân phối Gauss rời rạc thành phân phối đều, ta sẽ có sơ đồ Dilithium . Tuy nhiên, người ta kỳ vọng rằng phương pháp lấy mẫu loại bỏ sẽ khá khác biệt (theo một nghĩa nào đó, được đơn giản hóa).
Bước tiếp theo
Trong bài báo này, chúng tôi phân tích một mô hình quan trọng của các lược đồ chữ ký điện tử dựa trên mạng lưới: phép biến đổi Fiat-Shamir có dừng giữa chừng. Mặc dù nó xuất hiện trong nhiều cấu trúc (và được sử dụng ngầm trong hầu hết các bài báo), nhưng có một mô hình khác được gọi là " băm và ký", đây là điều kiện tiên quyết để hiểu Falcon và Hawk . Các lược đồ này trực tiếp sử dụng mạng lưới và hợp đồng: đầu tiên, thông điệp $\mu$ được băm thành một điểm trên $\mathbb{Z}^{2n}$, và sau đó điểm này được biến đổi bằng cách sử dụng một số đặc điểm hình học bí mật của mạng lưới (trong Hawk , private key là vectơ cơ sở ngắn B của mạng lưới cụ thể, và khóa công khai là dạng bình phương của nó $\mathbf{B}^{\top}\mathbf{B}$; trong Falcon, khóa công khai là cơ sở của mạng lưới, và private key là cơ sở của mạng lưới trực giao của nó).
Những hướng đi này tiếp tục thu hút sự chú ý từ cả giới học thuật và công nghiệp, và điều đó hoàn toàn có lý. Chúng tôi đang tích cực nghiên cứu những ý tưởng này, và các bài đăng trên blog trong tương lai sẽ đề cập lại chúng.
(qua)


