

Khi hệ sinh thái machine learning phi tập trung trưởng thành, có khả năng sẽ có sự phối hợp giữa các mạng máy tính và mạng thông minh khác nhau.
Được viết bởi: Sami Kassab, Messari
Biên dịch: BlockTurbo
Lĩnh vực trí tuệ nhân tạo tổng quát (AI) là điểm nóng không thể bàn cãi trong hai tuần qua, với các bản phát hành mới mang tính đột phá và các tích hợp tiên tiến đang xuất hiện. OpenAI đã phát hành mô hình GPT-4 rất được mong đợi, Midjourney đã phát hành mô hình V5 mới nhất và Stanford đã phát hành mô hình ngôn ngữ Alpaca 7B. Trong khi đó, Google đã triển khai AI tổng quát trên bộ Workspace của mình, Anthropic đã ra mắt trợ lý AI Claude và Microsoft đã tích hợp công cụ AI tổng quát mạnh mẽ của mình, Copilot, vào bộ Microsoft 365 của mình.
Tốc độ phát triển và áp dụng AI đang tăng nhanh khi các doanh nghiệp bắt đầu nhận ra giá trị của AI và tự động hóa cũng như nhu cầu áp dụng các công nghệ này để duy trì tính cạnh tranh trên thị trường.
Mặc dù quá trình phát triển AI dường như đang tiến triển thuận lợi, nhưng vẫn còn một số thách thức và nút thắt cơ bản cần được giải quyết. Khi ngày càng có nhiều doanh nghiệp và người tiêu dùng sử dụng AI, các nút thắt cổ chai về sức mạnh tính toán đang xuất hiện. Số lượng máy tính cần thiết cho các hệ thống AI đang tăng gấp đôi cứ sau vài tháng, trong khi việc cung cấp tài nguyên máy tính phải vật lộn để theo kịp. Ngoài ra, chi phí đào tạo các mô hình AI quy mô lớn tiếp tục tăng cao, tăng khoảng 3.100% mỗi năm trong thập kỷ qua.
Xu hướng tăng chi phí và yêu cầu tài nguyên cần thiết để phát triển và đào tạo các hệ thống AI tiên tiến đang dẫn đến việc tập trung hóa, chỉ những thực thể có ngân sách lớn mới có thể tiến hành nghiên cứu và sản xuất mô hình. Tuy nhiên, một số dự án dựa trên tiền điện tử đang xây dựng các giải pháp phi tập trung để giải quyết những vấn đề này bằng cách sử dụng mạng máy tính thông minh và máy tính mở.
Nguyên tắc cơ bản về Trí tuệ nhân tạo (AI) và Machine learning(ML)
Lĩnh vực AI có thể gây khó khăn, với các thuật ngữ kỹ thuật như học sâu, mạng lưới thần kinh và các mô hình cơ bản làm tăng thêm độ phức tạp của nó. Còn bây giờ, hãy đơn giản hóa các khái niệm này để dễ hiểu hơn.
- Trí tuệ nhân tạo là một nhánh của khoa học máy tính liên quan đến việc phát triển các thuật toán và mô hình cho phép máy tính thực hiện các nhiệm vụ đòi hỏi trí thông minh của con người, chẳng hạn như nhận thức, lý luận và ra quyết định;
- Machine learning(ML) là một tập hợp con của AI bao gồm các thuật toán đào tạo để nhận dạng các mẫu trong dữ liệu và đưa ra dự đoán dựa trên các mẫu đó;
- Học sâu là một loại ML liên quan đến việc sử dụng mạng thần kinh, bao gồm các lớp nút được kết nối với nhau hoạt động cùng nhau để phân tích dữ liệu đầu vào và tạo đầu ra.
Các mô hình cơ bản, chẳng hạn như ChatGPT và Dall-E, là các mô hình học sâu quy mô lớn được đào tạo trước trên một lượng lớn dữ liệu. Các mô hình này có thể tìm hiểu các mẫu và mối quan hệ trong dữ liệu, cho phép chúng tạo nội dung mới tương tự như dữ liệu đầu vào ban đầu. ChatGPT là mô hình ngôn ngữ để tạo văn bản ngôn ngữ tự nhiên, trong khi Dall-E là mô hình hình ảnh để tạo hình ảnh mới lạ.
Các vấn đề đối với ngành AI và ML
Những tiến bộ trong AI chủ yếu được thúc đẩy bởi ba yếu tố:
- Đổi mới thuật toán : Các nhà nghiên cứu không ngừng phát triển các thuật toán và kỹ thuật mới để cho phép các mô hình AI xử lý và phân tích dữ liệu hiệu quả và chính xác hơn.
- Dữ liệu : Các mô hình AI dựa vào các bộ dữ liệu lớn để thúc đẩy quá trình đào tạo của chúng, cho phép chúng học hỏi từ các mẫu và mối quan hệ trong dữ liệu.
- Tính toán : Các tính toán phức tạp cần thiết để đào tạo các mô hình AI đòi hỏi rất nhiều sức mạnh xử lý tính toán.
Tuy nhiên, có hai vấn đề chính cản trở sự phát triển của trí tuệ nhân tạo. Quay trở lại năm 2021, quyền truy cập dữ liệu là thách thức số một mà các công ty AI phải đối mặt trong quá trình phát triển AI của họ. Các vấn đề liên quan đến máy tính đã vượt qua dữ liệu như một thách thức vào năm ngoái, đặc biệt là do không thể truy cập tài nguyên máy tính theo yêu cầu do nhu cầu cao.
Vấn đề thứ hai liên quan đến sự kém hiệu quả của đổi mới thuật toán. Trong khi các nhà nghiên cứu tiếp tục thực hiện các cải tiến gia tăng cho các mô hình bằng cách xây dựng trên các mô hình trước đó, trí thông minh hoặc các mẫu được các mô hình này trích xuất luôn bị mất.
Hãy cùng tìm hiểu sâu hơn về những vấn đề này.
tắc nghẽn máy tính
Việc đào tạo các mô hình machine learning cơ bản cần nhiều tài nguyên, thường liên quan đến số lượng lớn GPU trong thời gian dài. Ví dụ: Stability.AI yêu cầu 4.000 GPU Nvidia A100 chạy trên đám mây của AWS để đào tạo các mô hình AI của họ, tiêu tốn hơn 50 triệu USD mỗi tháng. Mặt khác, GPT-3 của OpenAI tiêu tốn 12 triệu đô la để đào tạo bằng cách sử dụng 1.000 GPU Nvidia V100.
Các công ty AI thường phải đối mặt với hai lựa chọn: đầu tư vào phần cứng của riêng họ và hy sinh khả năng mở rộng, hoặc chọn một nhà cung cấp đám mây và trả nhiều tiền nhất. Trong khi các công ty lớn hơn có thể chi trả cho lựa chọn thứ hai, thì các công ty nhỏ hơn có thể không có được sự xa xỉ đó. Khi chi phí vốn tăng lên, các công ty khởi nghiệp buộc phải cắt giảm chi tiêu cho đám mây, ngay cả khi chi phí mở rộng cơ sở hạ tầng cho các nhà cung cấp đám mây lớn vẫn không đổi.
Chi phí tính toán cao của AI là một rào cản đáng kể đối với các nhà nghiên cứu và tổ chức theo đuổi những tiến bộ trong lĩnh vực này. Hiện tại, có một nhu cầu cấp thiết về một nền tảng điện toán không có máy chủ theo yêu cầu, giá cả phải chăng cho công việc ML không tồn tại trong thế giới điện toán truyền thống. May mắn thay, một số dự án tiền điện tử đang nghiên cứu phát triển các mạng máy tính machine learning phi tập trung có thể đáp ứng nhu cầu này.
Không hiệu quả và thiếu hợp tác
Ngày càng có nhiều hoạt động phát triển AI được thực hiện bí mật tại các công ty công nghệ lớn, không phải trong giới học thuật. Xu hướng này đã dẫn đến sự hợp tác ít hơn trong lĩnh vực này, với các công ty như OpenAI của Microsoft và DeepMind của Google cạnh tranh với nhau và giữ các mô hình của họ ở chế độ riêng tư.
Thiếu sự hợp tác dẫn đến không hiệu quả. Ví dụ: nếu một nhóm nghiên cứu độc lập muốn phát triển phiên bản GPT-4 của OpenAI mạnh mẽ hơn, họ sẽ cần phải đào tạo lại mô hình từ đầu, về cơ bản là học lại mọi thứ được đào tạo trên GPT-4. Xét rằng chỉ riêng chi phí đào tạo của GPT-3 đã lên tới 12 triệu đô la, điều này khiến các phòng nghiên cứu ML nhỏ hơn gặp bất lợi và đẩy tương lai phát triển AI vào tầm kiểm soát của các công ty công nghệ lớn.
Tuy nhiên, nếu các nhà nghiên cứu có thể xây dựng trên các mô hình hiện có thay vì bắt đầu từ đầu, do đó hạ thấp các rào cản gia nhập; nếu có một mạng lưới mở khuyến khích hợp tác, như một lớp điều phối mô hình do thị trường tự do quản lý, các nhà nghiên cứu có thể sử dụng các mô hình khác. đào tạo mô hình của họ? Dự án trí tuệ máy phi tập trung Bittensor xây dựng loại mạng này.
Mạng máy tính phi tập trung cho machine learning
Mạng máy tính phi tập trung kết nối các thực thể đang tìm kiếm tài nguyên máy tính với các hệ thống có sức mạnh tính toán dự phòng bằng cách khuyến khích đóng góp tài nguyên CPU và GPU vào mạng. Vì không có chi phí bổ sung cho các cá nhân hoặc tổ chức để cung cấp tài nguyên nhàn rỗi của họ, nên các mạng phi tập trung có thể đưa ra mức giá thấp hơn so với các nhà cung cấp tập trung.
Có hai loại mạng máy tính phi tập trung chính: mục đích chung và mục đích đặc biệt. Mạng máy tính đa năng hoạt động giống như một đám mây phi tập trung, cung cấp tài nguyên máy tính cho các ứng dụng khác nhau. Mặt khác, các mạng máy tính được xây dựng có mục đích được điều chỉnh cho các trường hợp sử dụng cụ thể. Ví dụ: mạng kết xuất là mạng máy tính chuyên dụng tập trung vào kết xuất khối lượng công việc.
Mặc dù hầu hết các khối lượng công việc điện toán ML có thể chạy trên các đám mây phi tập trung, nhưng một số khối lượng công việc phù hợp hơn với các mạng máy tính có mục đích cụ thể, như được mô tả bên dưới.
Khối lượng công việc điện toán machine learning

Machine learning có thể được chia thành bốn khối lượng công việc tính toán chính:
- Tiền xử lý dữ liệu : chuẩn bị dữ liệu thô và chuyển đổi dữ liệu đó thành định dạng có thể sử dụng được cho các mô hình ML, thường bao gồm các hoạt động như làm sạch và chuẩn hóa dữ liệu.
- Đào tạo : Các mô hình machine learning được đào tạo trên các tập dữ liệu lớn để tìm hiểu các mẫu và mối quan hệ trong dữ liệu. Trong quá trình đào tạo, các tham số và trọng số của mô hình được điều chỉnh để giảm thiểu lỗi.
- Tinh chỉnh : Các mô hình ML có thể được tối ưu hóa hơn nữa bằng cách sử dụng các bộ dữ liệu nhỏ hơn để cải thiện hiệu suất đối với các tác vụ cụ thể.
- Suy luận : Chạy mô hình được đào tạo và tinh chỉnh để đưa ra dự đoán nhằm đáp ứng các truy vấn của người dùng.
Khối lượng công việc tiền xử lý, tinh chỉnh và suy luận dữ liệu rất phù hợp để chạy trên các nền tảng đám mây phi tập trung như Akash, Cudos hoặc iExec. Tuy nhiên, mạng lưu trữ phi tập trung Filecoin đặc biệt phù hợp để xử lý trước dữ liệu do bản nâng cấp gần đây của nó, cho phép Máy ảo Filecoin (FVM). Bản nâng cấp FVM cho phép tính toán trên dữ liệu được lưu trữ trên mạng, cung cấp giải pháp hiệu quả hơn cho các thực thể đã sử dụng nó để lưu trữ dữ liệu.
Mạng máy tính chuyên dụng machine learning
Do hai thách thức xung quanh việc song song hóa và xác thực, phần đào tạo yêu cầu một mạng máy tính có mục đích đặc biệt.
Quá trình đào tạo các mô hình ML phụ thuộc vào trạng thái, có nghĩa là kết quả của phép tính phụ thuộc vào trạng thái hiện tại của phép tính, điều này khiến việc sử dụng các mạng GPU phân tán trở nên phức tạp hơn. Do đó, cần có một mạng cụ thể được thiết kế để đào tạo song song các mô hình ML.
Các vấn đề quan trọng hơn phải làm với xác nhận. Để xây dựng mạng đào tạo mô hình ML giảm thiểu độ tin cậy, mạng phải có cách xác minh công việc tính toán mà không lặp lại toàn bộ quá trình tính toán, điều này sẽ gây lãng phí thời gian và tài nguyên.
Gensyn
Gensyn là một mạng tính toán dành riêng cho ML đã tìm ra giải pháp cho các vấn đề xác thực và song song hóa của các mô hình đào tạo theo cách phân tán và phi tập trung. Giao thức sử dụng song song hóa để phân chia khối lượng công việc tính toán lớn hơn thành các tác vụ và đẩy chúng vào mạng một cách không đồng bộ. Để giải quyết vấn đề xác minh, Gensyn sử dụng bằng chứng học tập xác suất, giao thức xác định chính xác dựa trên biểu đồ và hệ thống khuyến khích dựa trên đặt cược và cắt giảm.
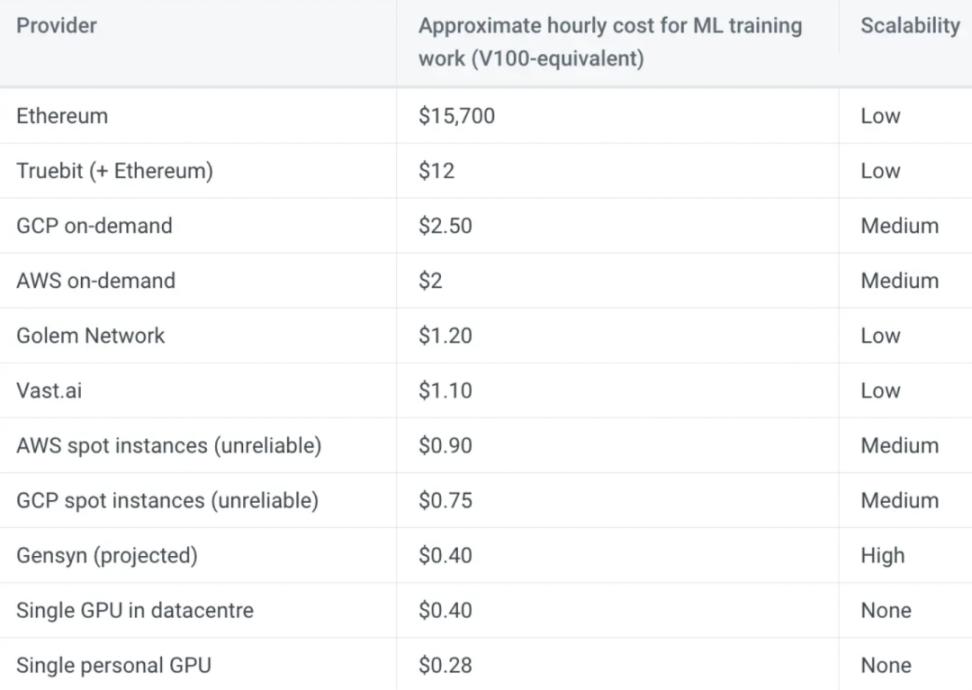
Mặc dù mạng Gensyn chưa hoạt động nhưng nhóm dự đoán chi phí mỗi giờ cho GPU tương đương V100 trên mạng của họ là khoảng 0,4 USD. Ước tính này dựa trên những người khai thác Ethereum kiếm được 0,20 đô la đến 0,35 đô la mỗi giờ bằng cách sử dụng các GPU tương tự trước khi Hợp nhất. Ngay cả khi ước tính này bị sai lệch 100%, chi phí điện toán của Gensyn vẫn sẽ thấp hơn đáng kể so với các dịch vụ theo yêu cầu do AWS và GCP cung cấp.
Cùng nhau
Together là một dự án ban đầu khác tập trung vào việc xây dựng mạng máy tính phi tập trung dành riêng cho machine learning. Khi bắt đầu dự án, Together bắt đầu tích hợp các tài nguyên điện toán học thuật chưa sử dụng từ nhiều tổ chức khác nhau như Đại học Stanford, ETH Zurich, Open Science Grid, Đại học Wisconsin-Madison và CrusoeCloud, dẫn đến tổng cộng hơn 200 PetaFLOP điện toán quyền lực. Mục tiêu cuối cùng của họ là tạo ra một thế giới nơi mọi người có thể đóng góp và hưởng lợi từ trí tuệ nhân tạo tiên tiến bằng cách tập hợp các tài nguyên máy tính toàn cầu.
Bittensor: Trí tuệ máy phi tập trung
Bittensor giải quyết sự thiếu hiệu quả trong machine learning đồng thời thay đổi cách cộng tác của các nhà nghiên cứu bằng cách sử dụng mã hóa đầu vào và đầu ra được tiêu chuẩn hóa để khuyến khích sản xuất tri thức trên các mạng nguồn mở nhằm kích hoạt khả năng tương tác của mô hình.
Trên Bittensor, những người khai thác được thưởng bằng tài sản gốc của mạng, TAO, vì đã cung cấp các dịch vụ thông minh cho mạng thông qua các mô hình ML độc đáo. Khi đào tạo các mô hình của họ trên mạng, những người khai thác trao đổi thông tin với những người khai thác khác, tăng tốc độ học tập của họ. Bằng cách đặt cược TAO, người dùng có thể sử dụng trí thông minh của toàn bộ mạng Bittensor và điều chỉnh các hoạt động của họ theo nhu cầu của họ, do đó hình thành thị trường thông minh P2P. Ngoài ra, các ứng dụng có thể được xây dựng trên lớp thông minh của mạng thông qua trình xác thực của mạng.
Bittensor hoạt động như thế nào
Bittensor là một giao thức P2P nguồn mở triển khai Mix-of-Experts (MoE) phi tập trung, một kỹ thuật ML kết hợp nhiều mô hình chuyên biệt cho các vấn đề khác nhau để tạo ra một mô hình tổng thể chính xác hơn. Điều này được thực hiện bằng cách đào tạo một mô hình định tuyến được gọi là lớp cổng, được đào tạo trên một tập hợp các mô hình chuyên gia để tìm hiểu cách định tuyến đầu vào một cách thông minh nhằm tạo ra đầu ra tối ưu. Để đạt được điều này, các trình xác nhận sẽ tự động hình thành các liên kết giữa các mô hình bổ sung lẫn nhau. Tính toán thưa thớt được sử dụng để giải quyết các tắc nghẽn về độ trễ.
Các ưu đãi của Bittensor thu hút các mô hình chuyên biệt vào hỗn hợp và đóng một vai trò thích hợp trong việc giải quyết các vấn đề lớn hơn do các bên liên quan xác định. Mỗi công cụ khai thác đại diện cho một mô hình duy nhất (mạng lưới thần kinh) và Bittensor hoạt động như một mô hình mô hình tự điều phối, được điều chỉnh bởi hệ thống thị trường thông minh không cần cấp phép.
Giao thức không phụ thuộc vào thuật toán, trình xác thực chỉ xác định các khóa và cho phép thị trường tìm khóa. Trí thông minh của những người khai thác là thành phần duy nhất được chia sẻ và đo lường, trong khi bản thân mô hình vẫn ở chế độ riêng tư, loại bỏ mọi sai lệch tiềm ẩn trong phép đo.
Người xác minh
Trên Bittensor, trình xác nhận hoạt động như một lớp cổng cho mô hình MoE của mạng, hoạt động như một API có thể đào tạo và cho phép phát triển các ứng dụng trên đầu mạng. Việc đặt cược của họ chi phối bối cảnh khuyến khích và xác định các vấn đề mà người khai thác giải quyết. Người xác thực hiểu giá trị mà công cụ khai thác cung cấp để thưởng cho họ tương ứng và đạt được sự đồng thuận về thứ hạng của họ. Những người khai thác được xếp hạng cao hơn sẽ nhận được phần thưởng khối lạm phát cao hơn.
Người xác thực cũng được khuyến khích khám phá và đánh giá các mô hình một cách trung thực và hiệu quả, khi họ kiếm được trái phiếu từ những người khai thác được xếp hạng hàng đầu và nhận được một phần phần thưởng trong tương lai. Điều này tạo ra một cơ chế hiệu quả mà theo đó những người khai thác "ràng buộc" bản thân họ với thứ hạng của họ về mặt kinh tế. Cơ chế đồng thuận của giao thức được thiết kế để chống lại sự thông đồng lên đến 50% cổ phần mạng, khiến cho việc xếp hạng cao các công cụ khai thác của chính mình là không khả thi về mặt tài chính.
thợ mỏ
Những người khai thác trên mạng được đào tạo và suy luận, họ trao đổi thông tin có chọn lọc với các đồng nghiệp dựa trên chuyên môn của họ và cập nhật trọng số của mô hình cho phù hợp. Khi trao đổi tin nhắn, những người khai thác ưu tiên các yêu cầu của trình xác thực theo cổ phần của họ. Hiện tại có 3523 thợ mỏ trực tuyến.
Việc trao đổi thông tin giữa những người khai thác trên mạng Bittensor cho phép tạo ra các mô hình AI mạnh mẽ hơn, vì những người khai thác có thể tận dụng kiến thức chuyên môn của các đồng nghiệp để cải thiện các mô hình của riêng họ. Điều này về cơ bản mang lại khả năng kết hợp cho không gian AI, nơi các mô hình ML khác nhau có thể được kết nối để tạo ra các hệ thống AI phức tạp hơn.
trí thông minh tổng hợp
Bittensor giải quyết vấn đề khuyến khích không hiệu quả thông qua thị trường mới, để đạt được hiệu quả tổng hợp trí thông minh của máy móc, từ đó nâng cao hiệu quả đào tạo ML. Mạng cho phép các cá nhân đóng góp vào mô hình cơ bản và kiếm tiền từ công việc của họ, bất kể quy mô hoặc lĩnh vực đóng góp của họ. Điều này tương tự như cách internet đã đóng góp vào thị trường ngách khả thi về mặt kinh tế và trao quyền cho các cá nhân trên các nền tảng nội dung như YouTube. Về cơ bản, Bittensor cam kết biến trí thông minh của máy thành hàng hóa, trở thành Internet của AI.
tóm tắt
Khi hệ sinh thái machine learning phi tập trung trưởng thành, có khả năng sẽ có sự phối hợp giữa các mạng máy tính và mạng thông minh khác nhau. Ví dụ: Gensyn và Together có thể được sử dụng làm lớp điều phối phần cứng của hệ sinh thái AI và Bittensor có thể được sử dụng làm lớp điều phối thông minh.
Về phía cung, những công ty khai thác tiền điện tử công khai lớn trước đây đã khai thác ETH đã thể hiện sự quan tâm lớn đến việc đóng góp tài nguyên cho mạng máy tính phi tập trung. Ví dụ: Akash đã nhận được các cam kết cung cấp 1 triệu GPU từ các công ty khai thác lớn trước khi phát hành GPU mạng của họ. Ngoài ra, Foundry, một trong những công cụ khai thác bitcoin tư nhân lớn hơn, đã khai thác trên Bittensor.
Các nhóm đằng sau các dự án được thảo luận trong báo cáo này không chỉ xây dựng các mạng dựa trên tiền điện tử để quảng cáo rầm rộ, mà còn là các nhóm gồm các nhà nghiên cứu và kỹ sư AI đã nhận ra tiềm năng của tiền điện tử để giải quyết các vấn đề trong ngành của họ.
Bằng cách cải thiện hiệu quả đào tạo, tập hợp các nguồn lực và tạo cơ hội cho nhiều người hơn đóng góp vào các mô hình AI quy mô lớn, các mạng ML phi tập trung có thể đẩy nhanh quá trình phát triển AI và cho phép chúng tôi mở khóa trí tuệ nhân tạo nói chung nhanh hơn trong tương lai.



