Tên gốc: ZPU: The Zero-Knowledge Processing Unit
Tác giả gốc: Ingonyama
Nguồn gốc: trung bình
Biên soạn bởi Kate, Marsbit
Tóm lại:
Trong blog này, chúng tôi đề xuất Zero-Knowledge Processing Unit (ZPU), một accelerator phần cứng có thể lập trình đa năng được thiết kế để giải quyết các yêu cầu mới nổi về xử lý không kiến thức.
Chúng tôi sẽ giới thiệu về kiến trúc ZPU và những cân nhắc về thiết kế. Chúng tôi giải thích các lựa chọn thiết kế đằng sau các bộ phận khác nhau của hệ sinh thái ZPU: ISA, luồng dữ liệu, bộ nhớ và linh kiện xử lý (PE) bên trong. Cuối cùng, chúng tôi so sánh ZK và crypto đồng dạng hoàn toàn (FHE) với các kiến trúc ASIC hiện đại.
giới thiệu
Sự tăng trưởng nhanh chóng của các ứng dụng dựa trên dữ liệu và nhu cầu tăng trưởng về quyền riêng tư đã dẫn đến sự gia tăng quan tâm đến các giao thức crypto để bảo vệ thông tin nhạy cảm. Trong số các giao thức này, Bằng chứng không tri thức(ZKP) nổi bật như một công cụ mạnh mẽ để đảm bảo tính toàn vẹn và quyền riêng tư trong tính toán. ZKP cho phép một bên chứng minh tính hợp lệ của một tuyên bố với bên kia mà không cần tiết lộ bất kỳ thông tin bổ sung nào. Tính chất này đã dẫn đến việc áp dụng rộng rãi ZKP trong nhiều ứng dụng tập trung vào quyền riêng tư, bao gồm công nghệ blockchain, giải pháp điện toán đám mây an toàn và dịch vụ gia công có thể xác minh.
Tuy nhiên, việc áp dụng ZKP vào các ứng dụng thực tế đang phải đối mặt với một thách thức đáng kể: chi phí hiệu suất liên quan đến việc tạo bằng chứng. Thuật toán ZKP thường bao gồm các phép toán phức tạp trên các số nguyên rất lớn, chẳng hạn như phép tính đa thức lớn trên đường cong elip và phép nhân vô hướng nhiều lần. Hơn nữa, các thuật toán mật mã liên tục phát triển và các chương trình mới, hiệu quả hơn đang được phát triển với tốc độ nhanh chóng. Kết quả là, accelerator phần cứng hiện tại khó có thể theo kịp các nguyên hàm crypto khác nhau và các thuật toán crypto luôn thay đổi.
Trong blog này, chúng tôi đề xuất Zero-Knowledge Processing Unit (ZPU), một accelerator phần cứng đa chức năng mới được thiết kế để giải quyết các yêu cầu mới nổi về xử lý không kiến thức. ZPU được xây dựng trên kiến trúc tập lệnh (ISA) hỗ trợ khả năng lập trình, cho phép nó thích ứng với các thuật toán crypto phát triển nhanh chóng. ZPU có mạng lưới kết nối linh kiện xử lý (PE) với khả năng hỗ trợ riêng cho phép tính số học mô-đun-đun từ lớn. Cấu trúc cốt lõi của PE được lấy cảm hứng từ công cụ tích lũy nhân (MAC), một thành phần xử lý cơ bản trong xử lý tín hiệu số (DSP) và các hệ thống máy tính khác. Các toán tử của PE sử dụng phép tính số học mô-đun, với các thành phần cốt lõi được thiết kế riêng để hỗ trợ các phép toán phổ biến trong thuật toán ZK, chẳng hạn như phép toán bướm NTT và phép cộng điểm trên đường cong elip cho phép nhân đa số.
Kiến trúc bộ hướng dẫn
Kiến trúc ZPU có mạng lưới linh kiện xử lý (PE) được kết nối với nhau, được xác định bởi kiến trúc bộ lệnh (ISA), như thể hiện trong Hình 1 bên dưới. Chúng tôi chọn kiến trúc này để thích ứng với hoàn cảnh thay đổi của các giao thức không kiến thức.
Phương pháp ISA cho phép ZPU duy trì tính linh hoạt, thích ứng với những thay đổi trong thuật toán ZK và hỗ trợ nhiều loại nguyên hàm crypto. Ngoài ra, việc sử dụng ISA thay vì phần cứng cố định cho phép cải tiến liên tục phần mềm sau khi sản xuất, đảm bảo ZPU vẫn phù hợp và hiệu quả ngay cả khi có những tiến bộ mới xuất hiện trong lĩnh vực này.
ISA là một tập hợp các lệnh mà bộ xử lý có thể thực thi. Nó hoạt động như một giao diện giữa phần cứng và phần mềm, xác định cách phần mềm tương tác với phần cứng. Bằng cách thiết kế ZPU với ISA tùy chỉnh, chúng ta có thể tối ưu hóa nó cho các yêu cầu cụ thể của nhiệm vụ xử lý ZK, chẳng hạn như số học từ lớn, crypto đường cong elip và các hoạt động mật mã phức tạp khác.
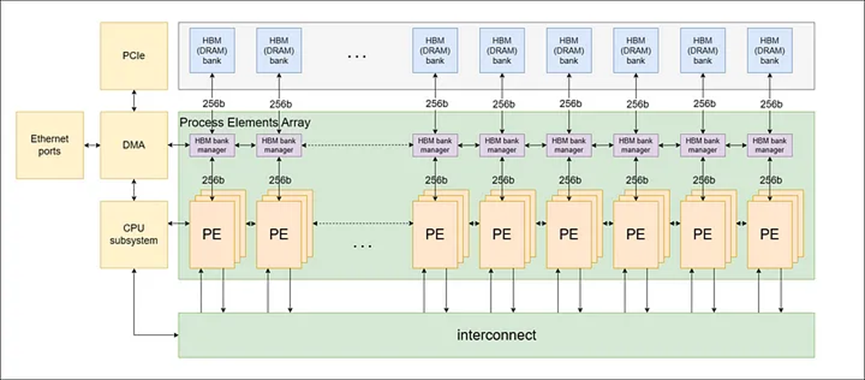
Hình 1: Cấu trúc mạng PE
Linh kiện lõi PE
Mỗi PE được thiết kế với lõi trong đó gồm bộ nhân, bộ cộng và bộ trừ dạng mô-đun, như thể hiện trong Hình 2. Các thành phần cốt lõi này được lấy cảm hứng từ linh kiện xử lý cơ bản của xử lý tín hiệu số (DSP) và các hệ thống máy tính khác, đó là công cụ nhân-tích lũy (MAC). Công cụ MAC thực hiện hiệu quả các phép tính nhân-tích lũy, bao gồm việc nhân hai số và cộng tích vào một số tích lũy.
Cấu trúc cốt lõi của PE được thiết kế riêng cho các phép toán phổ biến trong ZK, chẳng hạn như phép cộng điểm đường cong elip cho phép nhân đa số và phép toán bướm NTT cho phép biến đổi lý thuyết số (NTT). Các phép toán bướm bao gồm phép cộng, phép trừ và phép nhân, tất cả đều được thực hiện theo các phép toán mô-đun. Hoạt động này có tên như vậy là do đồ thị luồng tính toán có hình dạng giống con bướm, rất phù hợp với các thành phần phần cứng cốt lõi của PE vì chúng triển khai các phép tính bướm gốc thông qua các lệnh bướm chuyên dụng.
Ngoài ra, mỗi PE chứa một số đơn vị bộ nhớ chuyên dụng, bao gồm:
1. Phòng chờ đến: Bộ nhớ dùng để lưu trữ dữ liệu đến PE.
2. Phòng chờ khởi hành: Bộ nhớ dùng để lưu trữ dữ liệu khởi hành từ PE.
3. Bộ nhớ tạm cho các toán hạng A, B và C: Ba bộ nhớ riêng biệt được sử dụng để lưu trữ các kết quả trung gian.
4. Mở rộng bộ nhớ: Bộ nhớ đa năng để xử lý nhiều yêu cầu thuật toán khác nhau, chẳng hạn như tổng hợp thùng cho phép nhân đa số (MSM).
5. Bộ nhớ chương trình: bộ nhớ dùng để lưu trữ hàng đợi lệnh.
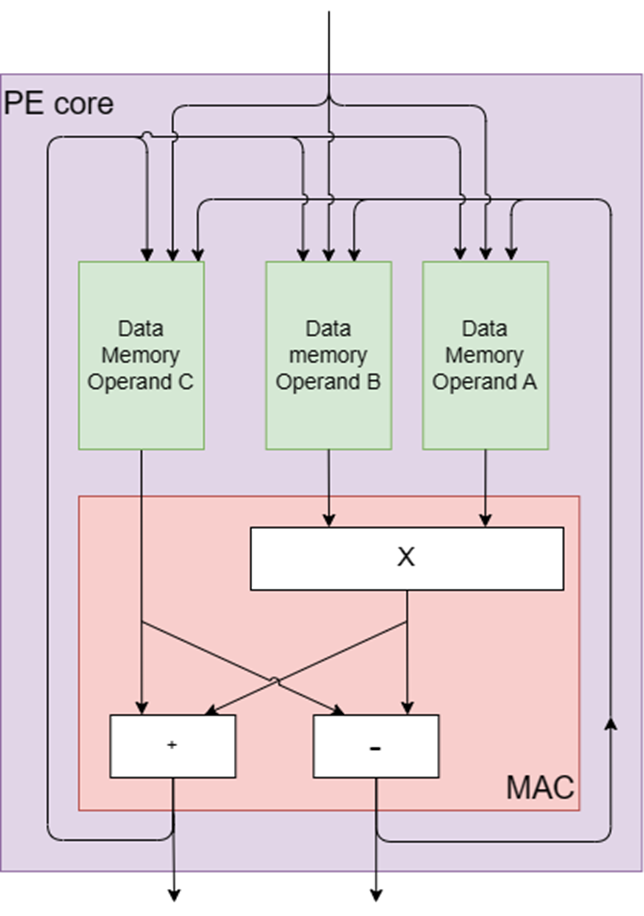
Hình 2: Các thành phần cốt lõi của PE
Chiều rộng bit PE
PE hỗ trợ số học mô-đun từ lớn (lên đến 256 bit). Sự đánh đổi giữa hỗ trợ gốc có độ rộng cao và độ rộng thấp trong PE bắt nguồn từ nhu cầu cân bằng hiệu quả của các kích thước toán hạng khác nhau.
Khi PE có hỗ trợ gốc bit rộng cao, nó được tối ưu hóa để xử lý các kích thước toán hạng lớn mà không cần phải chia chúng thành các phần nhỏ hơn. Tuy nhiên, quá trình tối ưu hóa này lại làm giảm hiệu quả của các hoạt động có độ rộng bit nhỏ hơn vì các PE không được sử dụng hết. Mặt khác, khi PE có hỗ trợ gốc độ rộng bit thấp, nó được tối ưu hóa để xử lý các kích thước toán hạng nhỏ hiệu quả hơn. Tuy nhiên, quá trình tối ưu hóa này dẫn đến tình trạng kém hiệu quả khi xử lý các hoạt động có độ rộng bit lớn hơn, vì PE cần phải chia các toán hạng lớn hơn thành các phần nhỏ hơn và xử lý các phần này theo trình tự.
Thách thức là tìm ra sự cân bằng phù hợp giữa hỗ trợ gốc có độ rộng bit cao và thấp để đảm bảo xử lý hiệu quả trên nhiều kích thước toán hạng. Sự cân bằng này cần xem xét độ rộng bit phổ biến trong miền ứng dụng mục tiêu (tức là giao thức ZK) và cân nhắc ưu và nhược điểm của từng lựa chọn thiết kế. Trong trường hợp kiến trúc ZPU, độ dài từ 256 bit được chọn là sự cân bằng tốt.
Kết nối PE
Tất cả các PE được kết nối trong một vòng tròn và mỗi PE được kết nối trực tiếp với hai PE liền kề để tạo thành một mạng vòng tròn. Kết nối vòng này cho phép dữ liệu điều khiển được truyền đi hiệu quả giữa các PE khác nhau. Các PE cũng được kết nối thông qua cụm kết nối, một cơ chế giống như bộ chuyển số thùng cho phép kết nối trực tiếp giữa các PE khác nhau theo thời gian. Thiết lập này cho phép PE gửi và nhận thông tin từ tất cả các PE khác.
Các thành phần ngoại vi
Kiến trúc này cũng tích hợp bộ nhớ băng thông cao ngoài chip (HBM) để hỗ trợ dung lượng bộ nhớ cao và băng thông bộ nhớ lớn. Nhiều PE được nhóm lại với nhau để tạo thành một cụm PE và mỗi cụm PE được kết nối với một ngân hàng hoặc kênh HBM. Ngoài ra, một hệ thống CPU dựa trên ARM trên chip được tích hợp để quản lý hoạt động chung của hệ thống.
Đánh giá hiệu suất
Để đánh giá hiệu suất của ZPU, chúng tôi đã xem xét các hoạt động chính của thuật toán mà chúng tôi muốn đẩy nhanh. Chúng tôi chủ yếu nghiên cứu phép toán bướm NTT và phép toán cộng điểm đường cong elip (EC). Để đánh giá tổng thời gian tính toán của các hoạt động MSM và NTT, chúng tôi đã tính toán tổng số lệnh tính toán mà chúng yêu cầu và chia chúng cho tần số xung nhịp và số PE.
Các hoạt động của NTT butterfly được thực hiện ở mỗi chu kỳ xung nhịp. Đối với hoạt động cộng điểm đường cong elip là yếu tố chính trong phép nhân đa số (MSM), chúng tôi phân tích nó thành các lệnh cơ bản ở cấp độ máy có thể được thực thi trên một PE duy nhất. Sau đó, chúng tôi tính toán số chu kỳ xung nhịp cần thiết để hoàn tất thao tác này. Qua phân tích, chúng tôi xác định rằng mỗi phép toán cộng điểm đường cong elip có thể được thực hiện một lần sau mỗi 18 chu kỳ xung nhịp.
Những giả định này cung cấp cơ sở cho đánh giá hiệu suất của chúng tôi và có thể được điều chỉnh khi cần thiết để phản ánh các yêu cầu thuật toán hoặc khả năng phần cứng khác nhau.
Theo tính toán của chúng tôi, cấu hình với 72 PE chạy ở tần số 1,305 GHz của GPU là đủ để đạt hiệu suất của người chiến thắng hạng mục GPU trong hoạt động MSM của Zprize . Yrrid Software và Matter Labs đều đạt được thành tích này, đạt kết quả 2,52 giây cho mỗi lần phép tính MSM khi sử dụng GPU NVIDIA A40. Phép so sánh dựa trên các phép tính MSM điểm cơ sở cố định liên quan đến các số vô hướng 2²⁶ được chọn ngẫu nhiên từ trường vô hướng BLS 12-377, cũng như một tập hợp cố định các điểm đường cong elip từ đường cong G1 của BLS 12-377 và một tập hợp hữu hạn các vectơ đầu vào được lấy mẫu ngẫu nhiên từ các phần tử trường của trường vô hướng.
Dựa trên ước tính về diện tích PE của chúng tôi, một ASIC sử dụng quy trình 8nm, công nghệ quy trình tương tự được sử dụng trong GPU A40, có thể chứa khoảng 925 PE trong cùng diện tích 628 mm2 như GPU A40. Điều này có nghĩa là chúng ta đạt được hiệu suất cao hơn khoảng 13 lần so với GPU A40.
PipeZK là một accelerator đường ống hiệu quả được thiết kế để cải thiện hiệu suất tạo ra Bằng chứng không tri thức(ZKP), với lõi MSM và NTT chuyên dụng giúp tối ưu hóa quá trình xử lý phép nhân đa thức và phép tính đa thức lớn.
So với PipeZK, chúng tôi thấy rằng cấu hình chỉ có 17 PE chạy ở tần số PipeZK là 300 MHz là đủ để phù hợp với hiệu suất hoạt động MSM của PipeZK. PipeZK thực hiện các hoạt động MSM trên MSM có độ dài 2²⁰ trong đường cong BN128 ở tần số 300 MHz và mất 0,061 giây để hoàn tất. Hơn nữa, để phù hợp với hiệu suất hoạt động NTT của PipeZK, chạy NTT 2²⁰ phần tử gồm 256 phần tử bit trong 0,011 giây ở tần số 300MHz, chúng ta sẽ cần khoảng 4 PE chạy ở cùng tần số. Tổng cộng, để phù hợp với hiệu suất của PipeZK khi chạy MSM và NTT cùng lúc, chúng ta cần 21 PE.
Theo ước tính về diện tích của chúng tôi, một ASIC sử dụng quy trình 28nm (công nghệ quy trình tương tự được sử dụng trong PipeZK) có thể chứa khoảng 16 PE trong cùng diện tích 50,75 mm2 như chip PipeZK. Điều này có nghĩa là chúng tôi kém hiệu quả hơn một chút so với kiến trúc cố định của PipeZK (hiệu quả kém hơn khoảng 25%), nhưng vẫn hoàn toàn linh hoạt để phù hợp với các đường cong elip và giao thức ZK khác nhau.
Đơn vị xử lý vòng (RPU) là nỗ lực gần đây nhằm tăng tốc quá trình tính toán Học tập dựa trên vòng có lỗi (RLWE), đây là cơ sở cho nhiều kỹ thuật tăng cường bảo mật và quyền riêng tư như crypto đồng cấu và crypto hậu lượng tử.
So với RPU, các tính toán của chúng tôi cho thấy để phù hợp với hiệu suất của RPU trong cấu hình tối ưu của nó (128 ngân hàng và HPLE) khi tính toán 64K NTT gồm các phần tử 128 bit, chúng tôi sẽ cần khoảng 23 PE chạy ở tần số 1,68 GHz của RPU. Phân tích của chúng tôi cho thấy ASIC sử dụng cùng công nghệ quy trình 12nm như RPU có thể chứa khoảng 19,65 PE trong diện tích 20,5 mm² mà RPU chiếm giữ. Điều này có nghĩa là chúng ta kém hiệu quả hơn một chút so với RPU (kém hiệu quả hơn 15%) nhưng vẫn tương thích với các nguyên hàm khác ngoài NTT.
TREBUCHET là accelerator crypto đồng dạng hoàn toàn (FHE) sử dụng bộ xử lý vòng (RPU) làm khối trên chip. Các lát cắt cũng giúp quản lý bộ nhớ dễ dàng hơn bằng cách lên lịch dữ liệu gần với các phần tử tính toán. Các RPU được sao chép trên toàn bộ thiết bị, cho phép phần mềm giảm thiểu việc di chuyển dữ liệu và khai thác tính song song ở cấp độ dữ liệu.
Cả TREBUCHET và ZPU đều dựa trên kiến trúc ISA với các công cụ tính toán từ số học lớn hỗ trợ các từ rất dài (128 bit trở lên) theo số học mô- mô-đun. Tuy nhiên, giá trị gia tăng của ZPU so với RPU hoặc Trebuchet SoC là nó mở rộng phạm vi các vấn đề mà kiến trúc được thiết kế để giải quyết. Trong khi RPU và TREBUCHET tập trung chủ yếu vào NTT, ZPU hỗ trợ nhiều hàm nguyên thủy hơn như phép nhân đa vô hướng (MSM) và hàm băm hướng số học.
Tóm tắt
Đánh giá hiệu suất của chúng tôi cho thấy ZPU có thể ngang bằng hoặc thậm chí vượt trội hơn hiệu suất của các thiết kế ASIC hiện đại, đồng thời có khả năng phục hồi tốt hơn trước những thay đổi trong thuật toán ZK và các nguyên hàm crypto. Mặc dù có những sự đánh đổi cần cân nhắc, chẳng hạn như sự cân bằng giữa hỗ trợ bit độ rộng cao và bit độ rộng thấp trong PE, thiết kế của ZPU được tối ưu hóa cẩn thận để đảm bảo xử lý hiệu quả trên nhiều kích thước toán hạng. Đối với những ai quan tâm đến việc tìm hiểu thêm về ZPU hoặc khám phá khả năng hợp tác tiềm năng, vui lòng liên hệ với chúng tôi. Chúng tôi mong muốn được chia sẻ thêm thông tin cập nhật về tiến độ và những phát triển trong tương lai của dự án ZPU.
Cảm ơn Weikeng Chen đã đánh giá.