


[Giới thiệu] Âm lượng thật điên rồ! Groq, mô hình lớn nhanh nhất thế giới, trở nên phổ biến chỉ sau một đêm và có thể tạo ra gần 500 token mỗi giây. Phản ứng nhanh như vậy đều là do LPU tự phát triển.
Khi tôi thức dậy, mô hình Groq có thể tạo ra 500 mã thông báo mỗi giây đã tràn ngập toàn bộ mạng.
Nó có thể được gọi là "LLM nhanh nhất thế giới"!
Để so sánh, ChatGPT-3.5 chỉ tạo ra 40 mã thông báo mỗi giây.
Một số cư dân mạng đã so sánh nó với GPT-4 và Gemini để xem họ mất bao lâu để hoàn thành một vấn đề gỡ lỗi mã đơn giản.
Không ngờ Groq lại hoàn toàn đè bẹp cả hai, với tốc độ đầu ra nhanh gấp 10 lần Gemini và nhanh hơn 18 lần so với GPT-4. (Nhưng xét về chất lượng câu trả lời, Gemini tốt hơn.)
Điều quan trọng nhất là bất cứ ai cũng có thể sử dụng nó miễn phí!
Vào trang chủ Groq, hiện tại có 2 mẫu bạn có thể lựa chọn là Mixtral8x7B-32k và Llama 270B-4k.
Địa chỉ: https://groq.com/
Đồng thời, Groq API cũng được cung cấp cho các nhà phát triển và hoàn toàn tương thích với OpenAI API.
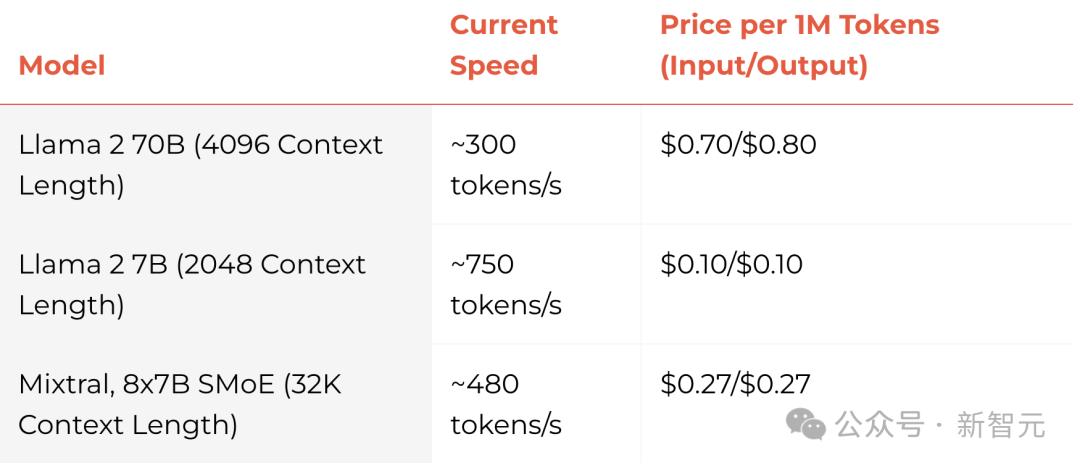
Mixtral 8x7B SMoE có thể đạt 480 token/S và giá 1 triệu token là 0,27 ĐÔ LA. Trong trường hợp cực đoan, Llama2 7B thậm chí có thể đạt được 750 token/S.
Hiện tại, họ cũng cung cấp bản dùng thử miễn phí 1 triệu token.
Groq bỗng trở nên phổ biến, người đóng góp lớn nhất đằng sau nó không phải là GPU mà là LPU - đơn vị xử lý ngôn ngữ tự phát triển.
Một thẻ duy nhất chỉ có 230 MB bộ nhớ và đô la. Trong nhiệm vụ LLM, LPU nhanh hơn 10 lần so với hiệu suất GPU của NVIDIA.

Trong một bài kiểm tra điểm chuẩn cách đây không lâu, Llama 2 70B chạy trên công cụ suy luận Groq LPU đã trực tiếp đứng đầu danh sách và hiệu suất suy luận LLM của nó nhanh hơn 18 lần so với các nhà cung cấp đám mây hàng đầu.
Cuộc biểu tình của cư dân mạng
Tốc độ phát điện nhanh như tên lửa của Groq khiến nhiều người sửng sốt.
Cư dân mạng đã phát hành bản demo của riêng họ.
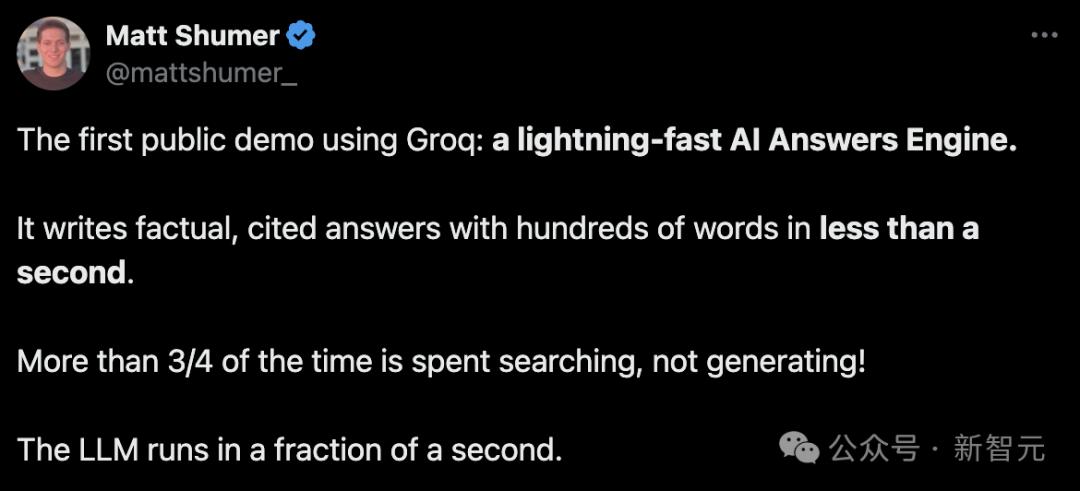
Tạo hàng trăm từ chứa câu trả lời thực tế kèm theo dấu ngoặc kép trong chưa đầy một giây.
Trên thực tế, tìm kiếm chiếm hơn 3/4 thời gian xử lý chứ không phải việc tạo nội dung!
Đối với cùng một lời nhắc "Tạo một kế hoạch tập thể dục đơn giản", Groq và ChatGPT đã cùng nhau phản hồi với tốc độ khác nhau.

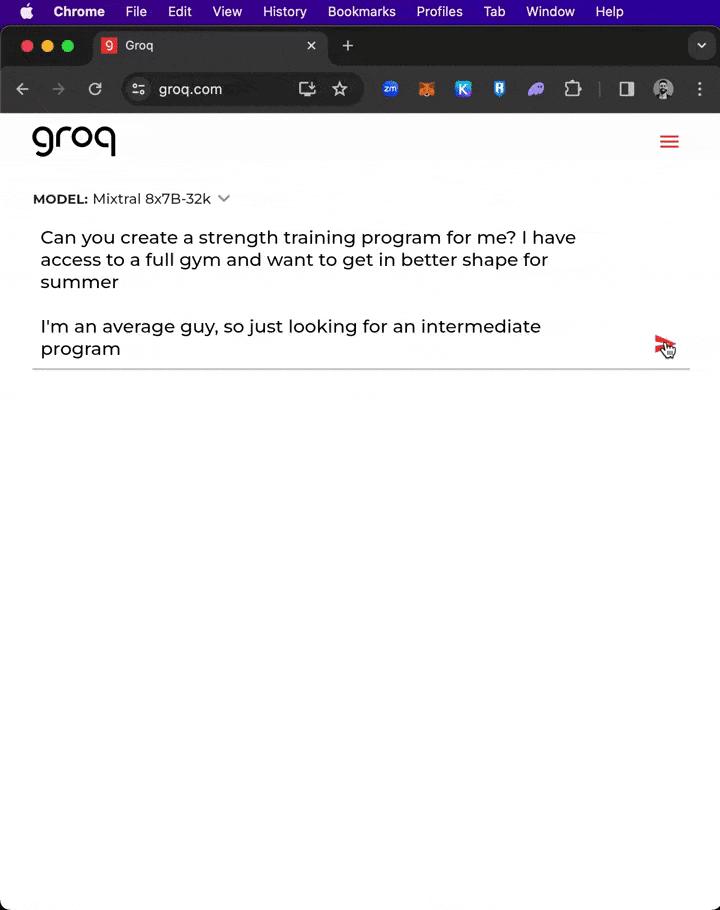
Đối diện lời nhắc "khổng lồ" hơn 300 từ, Groq đã tạo dàn ý sơ bộ và kế hoạch viết cho một bài báo trong vòng chưa đầy một giây!

Groq thực hiện đầy đủ cuộc đối thoại AI theo thời gian thực từ xa. Chạy Llama 70B trên phần cứng GroqInc và sau đó đưa nó vào Whisper, hầu như không có độ trễ.
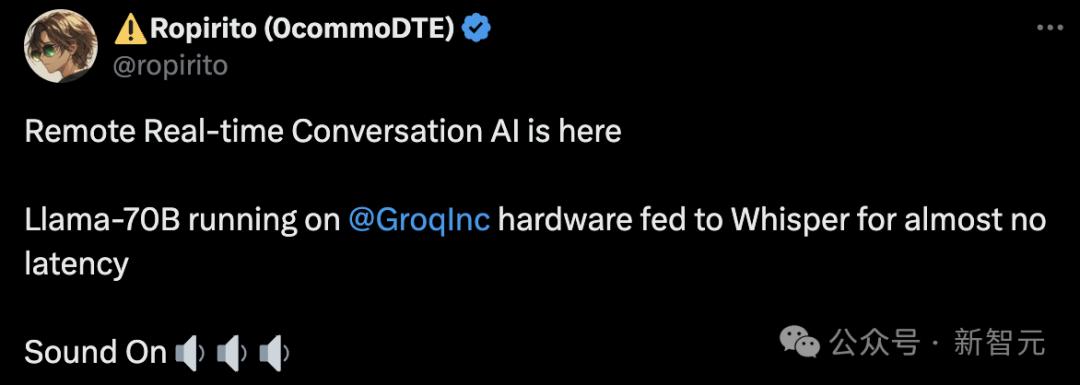
GPU không còn tồn tại?
Lý do tại sao mô hình Groq có khả năng phản hồi nhanh như vậy là do công ty đằng sau nó, Groq (cùng tên), đã phát triển một phần cứng độc đáo có tên là LPU.
Không, GPU truyền thống.

Nói tóm lại, Groq đã tự phát triển một loại đơn vị xử lý mới gọi là Bộ xử lý dòng Tensor (TSP) và định nghĩa nó là "Bộ xử lý ngôn ngữ" hay LPU.
Nó là bộ xử lý song song được thiết kế đặc biệt để kết xuất đồ họa và chứa hàng trăm lõi, có thể mang lại hiệu suất ổn định cho các phép tính AI.

Địa chỉ giấy: https://wow.groq.com/wp-content/uploads/2024/02/GroqISCAPaper2022_ASoftwareDefinedTensorStreamingMultiprocessorForLargeScaleMachineLearning.pdf
Cụ thể, LPU hoạt động rất khác so với GPU.
Nó sử dụng kiến trúc Máy tính tập lệnh tạm thời, nghĩa là nó không cần tải dữ liệu từ bộ nhớ thường xuyên như GPU sử dụng bộ nhớ băng thông cao (HBM).
Tính năng này không chỉ giúp tránh tình trạng thiếu HBM mà còn giảm chi phí một cách hiệu quả.
Thiết kế này cho phép tận dụng hiệu quả mọi chu kỳ xung nhịp, do đó đảm bảo độ trễ và thông lượng ổn định.
Về mặt hiệu quả sử dụng năng lượng, LPU cũng cho thấy những ưu điểm của mình. Bằng cách giảm chi phí quản lý đa luồng và tránh sử dụng không đúng mức các tài nguyên cốt lõi, LPU có thể đạt được hiệu suất tính toán cao hơn trên mỗi watt.
Hiện tại, Groq hỗ trợ nhiều khung phát triển máy học để suy luận mô hình, bao gồm PyTorch, TensorFlow và ONNX. Tuy nhiên, việc sử dụng công cụ suy luận LPU để đào tạo ML không được hỗ trợ.
Một số cư dân mạng thậm chí còn cho rằng: "LPU của Groq nhanh vượt qua GPU của NVIDIA trong việc xử lý các yêu cầu và phản hồi".

Không giống như GPU Nvidia dựa vào truyền dữ liệu tốc độ cao, LPU của Groq không sử dụng bộ nhớ băng thông cao (HBM) trong hệ thống của nó.
Nó sử dụng SRAM, nhanh hơn khoảng 20 lần so với bộ nhớ mà GPU sử dụng.
Do lượng dữ liệu cần thiết cho tính toán suy luận AI nhỏ hơn nhiều so với lượng dữ liệu dành cho đào tạo mô hình, do đó LPU của Groq tiết kiệm năng lượng hơn.
Nó đọc ít dữ liệu hơn từ bộ nhớ ngoài và tiêu thụ ít năng lượng hơn GPU của Nvidia khi thực hiện nhiệm vụ suy luận.
LPU không có yêu cầu cực cao về tốc độ lưu trữ như GPU.
Nếu LPU của Groq được sử dụng trong các tình huống xử lý AI thì có thể không cần phải định cấu hình các giải pháp lưu trữ đặc biệt cho GPU Nvidia.

Thiết kế chip cải tiến của Groq cho phép liên kết liền mạch nhiều TSP, tránh các tắc nghẽn phổ biến trong cụm GPU và cải thiện đáng kể mở rộng.
Điều này có nghĩa là khi nhiều LPU được thêm vào, hiệu suất có thể được mở rộng tuyến tính, đơn giản hóa các yêu cầu phần cứng cho các mô hình AI quy mô lớn và giúp các nhà phát triển mở rộng ứng dụng dễ dàng hơn mà không cần xây dựng lại hệ thống.

Groq tuyên bố rằng công nghệ của họ có thể thay thế nhân vật của GPU trong nhiệm vụ suy luận thông qua các chip và phần mềm mạnh mẽ.
Biểu đồ so sánh thông số kỹ thuật cụ thể được cư dân mạng thực hiện.
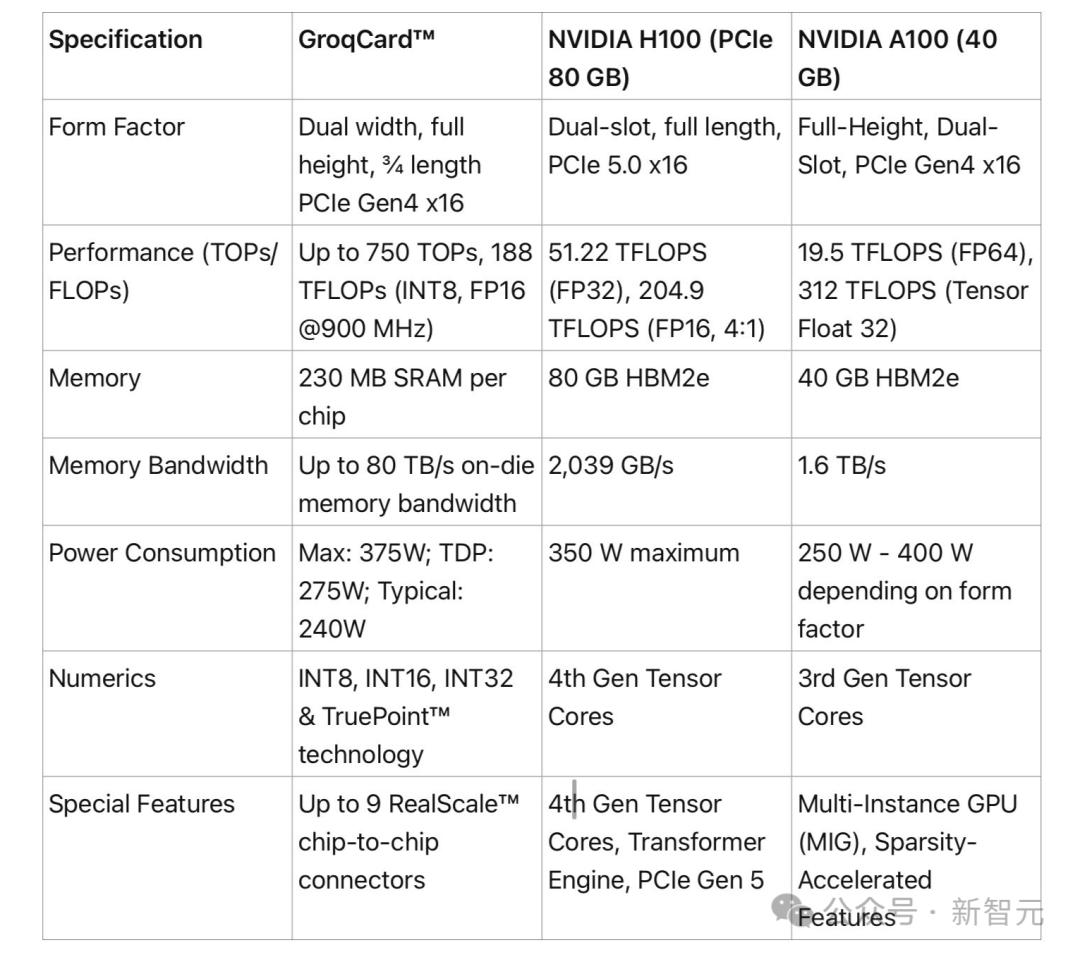
Tất cả điều này có nghĩa là gì?
Đối với các nhà phát triển, điều này có nghĩa là hiệu suất có thể được dự đoán và tối ưu hóa chính xác, điều này rất quan trọng đối với các ứng dụng AI thời gian thực.
Đối với các dịch vụ ứng dụng AI trong tương lai, LPU có thể mang lại những cải tiến hiệu suất rất lớn so với GPU!
Xét thấy A100 và H100 đang thiếu nguồn cung như vậy, việc có phần cứng thay thế hiệu suất cao như vậy là một lợi thế rất lớn cho các công ty khởi nghiệp.
Hiện tại, OpenAI đang tìm kiếm nguồn tài trợ trị giá 7 nghìn tỷ ĐÔ LA từ các chính phủ và nhà đầu tư toàn cầu để phát triển chip của riêng mình và giải quyết vấn đề thiếu tỷ lệ băm khi mở rộng sản phẩm của mình.

Thông lượng gấp 2 lần, tốc độ phản hồi chỉ 0,8 giây
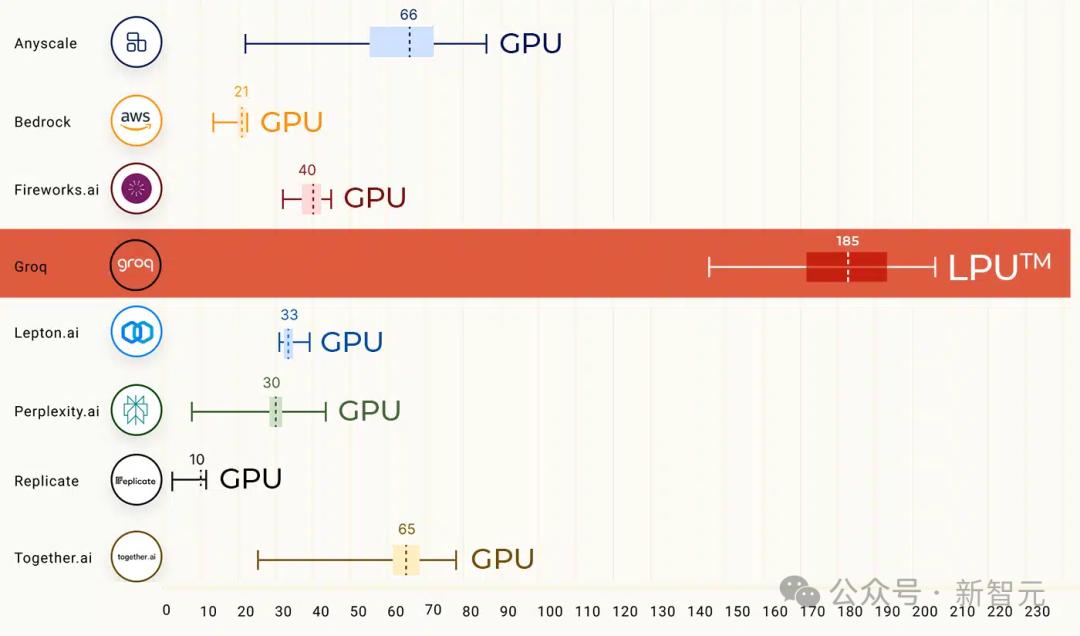
Cách đây một thời gian, trong bài kiểm tra điểm chuẩn LLM của ArtificialAnalysis.ai, giải pháp của Groq đã đánh bại 8 chỉ báo hiệu suất chính.
Trong đó bao gồm độ trễ so với thông lượng, thông lượng theo thời gian, tổng thời gian phản hồi và phương sai thông lượng.
Ở góc phần tư màu xanh lá cây ở góc dưới bên phải, Groq đạt được kết quả tốt nhất.
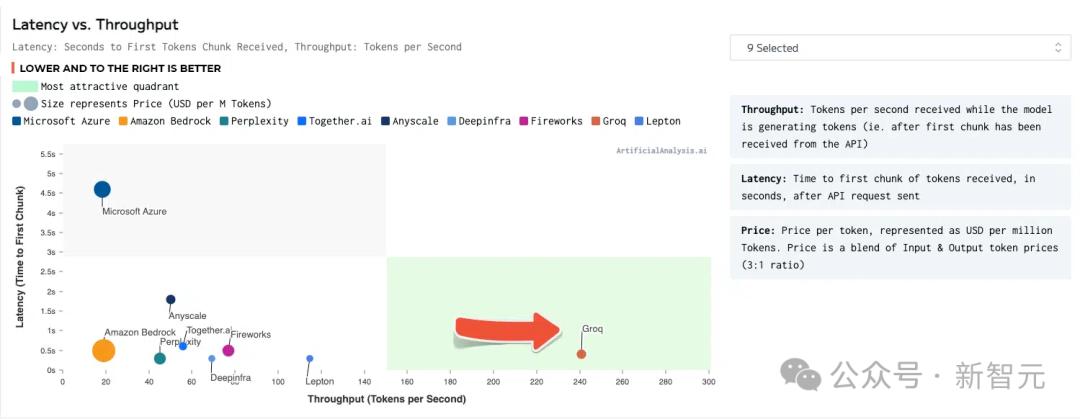
Nguồn: ArtificialAnalysis.ai
Llama 2 70B có hiệu suất tốt nhất trên công cụ suy luận Groq LPU, đạt thông lượng 241 token mỗi giây, cao hơn gấp đôi so với các nhà sản xuất lớn khác.
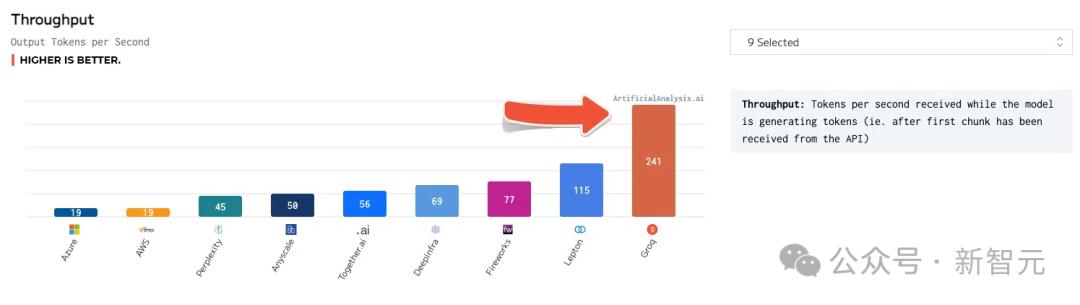
tổng thời gian phản hồi
Thời gian phản hồi của Groq cũng thấp nhất, chỉ 0,8 giây cho đầu ra sau khi nhận được 100 token.
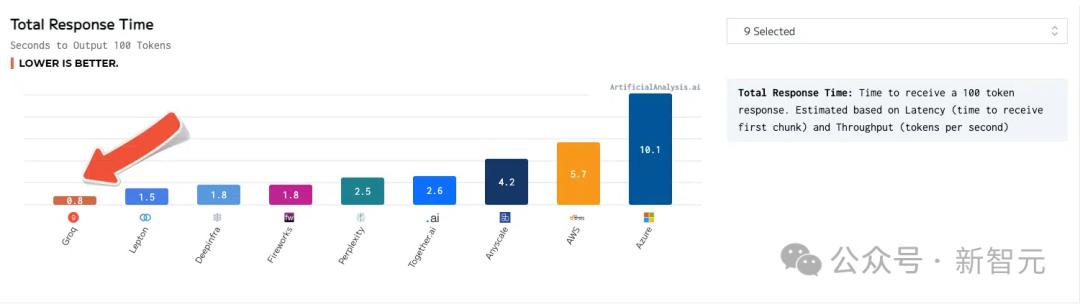
Ngoài ra, Groq đã chạy một số điểm chuẩn nội bộ và có thể đạt 300 mã thông báo mỗi giây, một lần nữa thiết lập tiêu chuẩn tốc độ mới.
Giám đốc điều hành Groq Jonathan Ross từng nói: “Groq tồn tại để loại bỏ những người ‘có và không có’ và giúp mọi người trong cộng đồng trí tuệ nhân tạo phát triển. "Suy luận là chìa khóa để đạt được mục tiêu này, vì tốc độ là chìa khóa để biến ý tưởng của nhà phát triển thành giải pháp kinh doanh và chuyển đổi ứng dụng."

Một thẻ có giá 20.000 USD và có bộ nhớ 230MB.
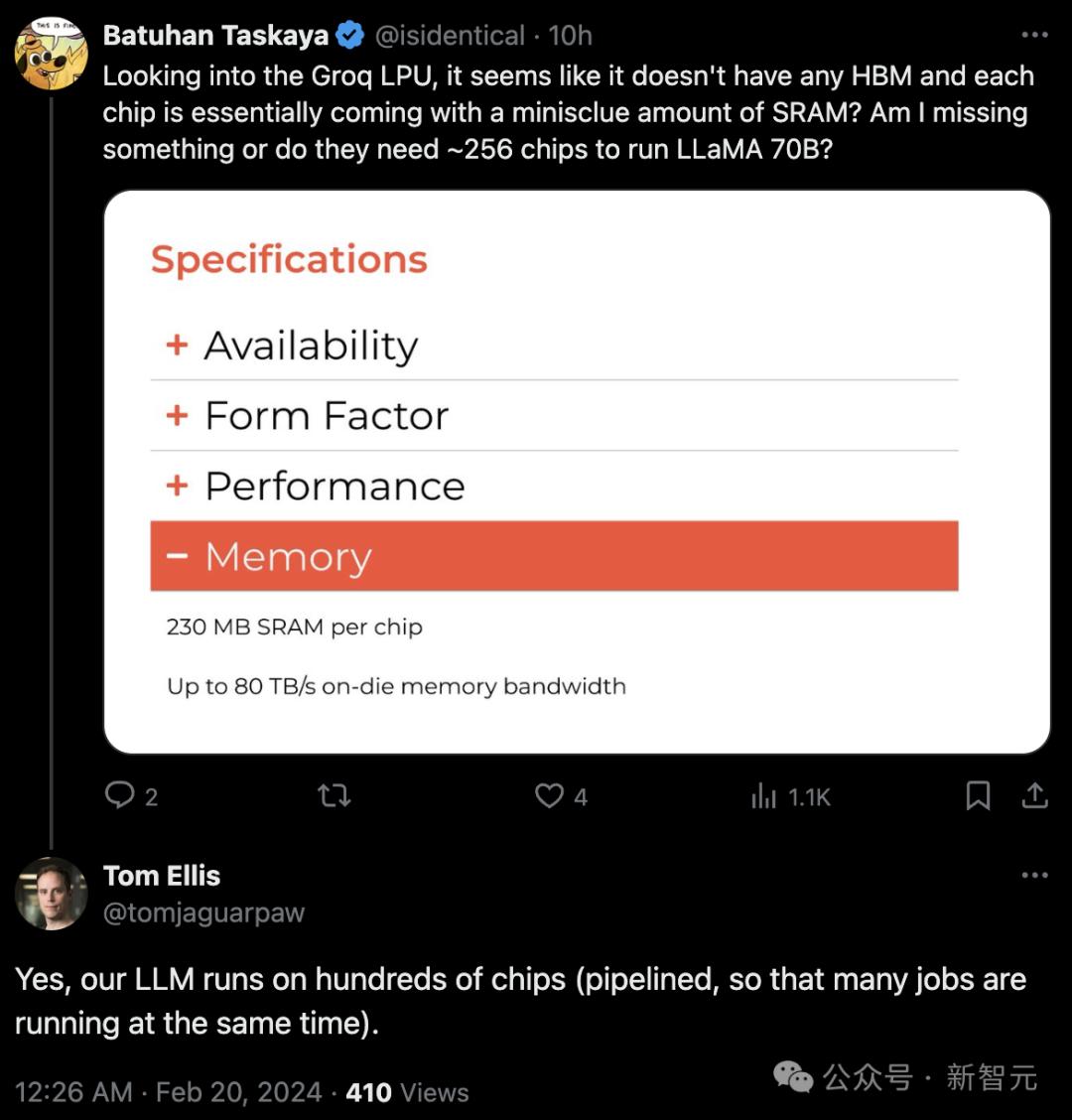
Chắc hẳn bạn đã nhận thấy trước đó rằng thẻ LPU chỉ có 230 MB bộ nhớ.

Và giá là $ 20,000+.

Theo The Next Platform, trong thử nghiệm trên, Groq thực sự đã sử dụng 576 GroqChip để đạt được khả năng suy luận Llama 2 70B.

Nói chung, GroqRack được trang bị 9 nút , 8 nút trong đó chịu trách nhiệm thực hiện nhiệm vụ tính toán và 1 nút còn lại được sử dụng làm bản sao lưu. Nhưng lần này, tất cả chín nút đều được sử dụng cho công việc tính toán.

Cư dân mạng cho rằng vấn đề chính mà Groq LPU gặp phải là họ hoàn toàn không được trang bị bộ nhớ băng thông cao (HBM) mà chỉ được trang bị một phần nhỏ (230MiB) bộ nhớ truy cập ngẫu nhiên tĩnh tốc độ cực cao (SRAM) SRAM nhanh hơn HBM3 gấp 20 lần.
Điều này có nghĩa là để hỗ trợ chạy một mô hình AI duy nhất, bạn cần định cấu hình khoảng 256 LPU, tương đương với 4 giá đỡ máy chủ được tải đầy đủ. Mỗi giá có thể chứa 8 đơn vị LPU và mỗi đơn vị chứa 8 LPU.
Để so sánh, bạn chỉ cần một H200 (mật độ tương đương 1/4 giá máy chủ) để chạy các mô hình này khá hiệu quả.
Cấu hình này có thể hoạt động tốt nếu bạn chỉ cần chạy một mô hình duy nhất và có lượng lớn. Tuy nhiên, cấu hình này không còn phù hợp khi nhiều mô hình cần chạy đồng thời, đặc biệt khi cần lượng lớn tinh chỉnh mô hình hoặc các hoạt động LoRA cấp cao.
Ngoài ra, đối với các tình huống cần triển khai cục bộ, ưu điểm của cấu hình Groq LPU này là không rõ ràng, vì ưu điểm chính của nó là khả năng tập trung nhiều người dùng để sử dụng cùng một mô hình.
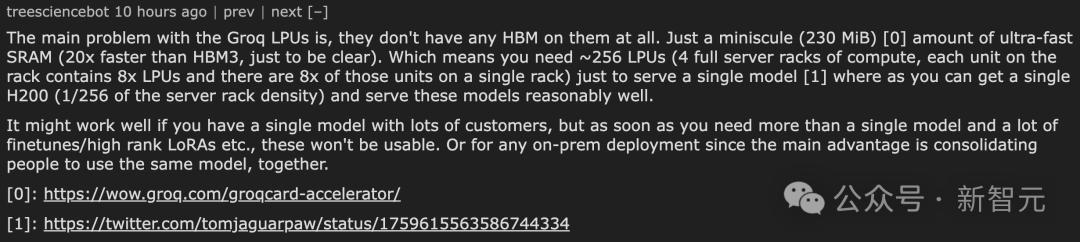
Một cư dân mạng khác cho biết: "Groq LPU dường như không có bất kỳ HBM nào và về cơ bản mỗi chip đều đi kèm một lượng nhỏ SRAM? Điều đó có nghĩa là họ cần khoảng 256 chip để chạy Llama 70B?"
Thật bất ngờ, tôi nhận được phản hồi chính thức : Có, LLM của chúng tôi chạy trên hàng trăm con chip.
Những người khác đã đưa ra phản đối về giá của thẻ LPU, "Điều này chẳng phải sẽ khiến sản phẩm của bạn đắt hơn H100 một cách nực cười sao?"

Musk Grok, cách phát âm giống nhau nhưng từ khác nhau
Cách đây một thời gian, Groq đã thu hút rất nhiều sự chú ý sau khi công bố kết quả benchmark.
Lần này, Groq, mô hình AI mới nhất, một lần nữa gây bão trên mạng xã hội với khả năng phản hồi nhanh và công nghệ mới có thể thay thế GPU.
Tuy nhiên, công ty đứng sau Groq không phải là ngôi sao mới sau kỷ nguyên người mẫu lớn.
Nó được thành lập vào năm 2016 và đăng ký trực tiếp tên Groq.

Giám đốc điều hành và đồng sáng lập Jonathan Ross là nhân viên của Google trước khi thành lập Groq.
Trong một dự án 20%, anh đã thiết kế và triển khai các thành phần cốt lõi của chip TPU thế hệ đầu tiên, sau này trở thành Bộ xử lý Tensor của Google (TPU).
Sau đó, Ross tham gia đội ngũ đánh giá nhanh của Google X Labs (giai đoạn ban đầu của dự án "Moonshot Factory" nổi tiếng) để thiết kế và nuôi dưỡng các Bet (đơn vị) mới cho công ty mẹ của Google là Alphabet.

Có lẽ hầu hết mọi người đều bối rối trước tên gọi các mẫu xe Grok và Groq của Musk.

Trên thực tế, đã có một tình tiết cố gắng thuyết phục Musk sử dụng cái tên này.
Tháng 11 năm ngoái, khi mô hình AI cùng tên của Musk là Grok (đánh vần khác) bắt đầu gây được sự chú ý, đội ngũ phát triển của Groq đã đăng một blog hài hước yêu cầu Musk chọn một cái tên khác:
Chúng tôi hiểu lý do tại sao bạn sẽ thích tên của chúng tôi. Bạn có sở thích về những thứ nhanh chóng (như tên lửa, hyperloop, tên công ty một chữ cái) và công cụ suy luận Groq LPU của chúng tôi là cách nhanh nhất để chạy LLM và các ứng dụng AI tổng hợp khác. Nhưng chúng tôi vẫn phải yêu cầu bạn đổi tên nhanh chóng.

Tuy nhiên, Musk không phản hồi về sự giống nhau về tên gọi của hai mẫu xe.
Tham khảo:
https://x.com/JayScambler/status/1759372542530261154?s=20
https://x.com/gabor/status/1759662691688587706?s=20
https://x.com/GroqInc/status/1759622931057934404?s=20
Bài viết này đến từ tài khoản công khai WeChat "Xin Zhiyuan" (ID: AI_era) , biên tập viên: Tao Zi buồn ngủ quá, và 36 Krypton được xuất bản với sự cho phép.





