

上週五晚上 Kimi 更新了他們的深度研究能力,收到測試資格之後昨天深度使用了一天。
發現 Kimi 深度研究在內容豐富度、準確性和邏輯嚴謹性上都非常能打。
下面是詳細的介紹👇


與其他近期類似產品不同,月之暗面這個深度研究是他們自己訓練的基於端到端自主強化學習技術訓練的Agent 模型。
而且他們會開源基礎的預訓練模型和後面經過強化學習的模型,這個太值得期待了。
在HLE (Humanity’s Last Exam) 和紅杉的 Agent 測試上 kimi 深度研究模型都取得了不錯的成績。
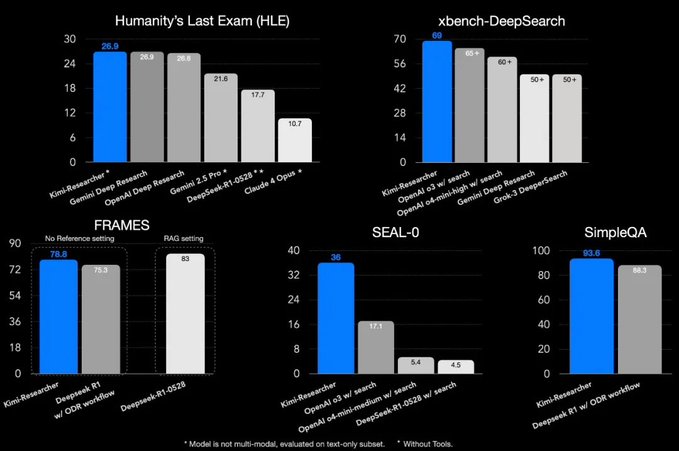
我最近一直在思考這類產出深度研究報告的產品或者模型,他的核心考核指標是什麼?
感覺大家關注的主要是其信源的質量、信息的覆蓋度以及邏輯的嚴謹性,剛好 Kimi 深度研究在兩個方面的優化上保證了這幾個指標。
他對於信息有自主甄別能力,他會自己規劃幾十個搜索關鍵詞和閱讀上百個網頁,然後找出可信度靠前的內容進行引用。
基本上每篇生成的研究報告都會超過一萬字,我有個測試有 2.2 萬字。
當然 LLM 不可能完全避免幻覺,他們也通過文中內嵌、高亮跳轉、原文溯源這幾個方式讓用戶自己進行判斷。
測試1:Labubu 爆火原因分析
他會先進行簡單的搜索詢問需要分析的細節是什麼
先會整體大致搜索所有的內容,然後得出一個籠統的結論之後會開始分別搜索每個部分的內容
先搜了粉絲經濟,然後是爆火的原因,之後他發現進一輪爆火的原因可能跟在海外的傳播有關係,然後就開始搜索
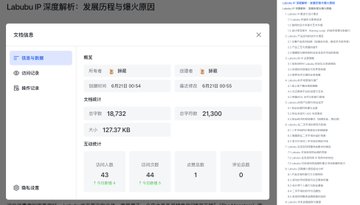
我看了一下字數居然有接近 1.9 萬字,從目錄看就能看到整個報告邏輯鏈條非常完整,涵蓋了 IP 設計、產品演變、運營推廣策略、粉絲經濟等多個方面。
先描述了 Labubu 這個 IP 的設計理念,然後是產品的迭代和演變,說完 IP 設計之後才說基於 IP 的運營策略,這個時候有了前面的背景信息之後閱讀者才能更好的理解為什麼這樣運營這個 IP。
在說完營銷推廣之後,作為有一定金融屬性的產品,自然而然的就會延伸到粉絲經濟和二手市場上。
這裡的分析和內容檢索非常強,從泡泡瑪特自己的運營和啟動,到最後粉絲自發的生產 UGC 內容都有提及,特別是最重要的娃衣。
然後在所有的信息都說完之後他終於開始總結爆火的原因,包含了上面說的所有的內容,IP、設計師、市場營銷和二手市場炒作共同促成了 Labubu 的爆火。



經過上面的內容結果可以看到 kimi 深度研究不只是信息的堆砌。
而是通過邏輯鏈條把信息都放在了該放的地方,說明他能自主形成分析框架。
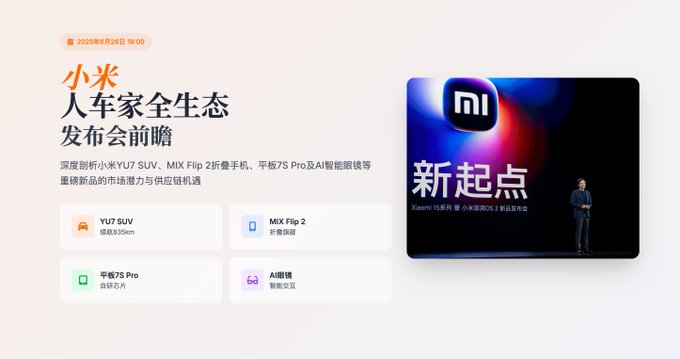
測試2:小米26號發佈會內容檢索及分析
接下來我們看一下他的搜索準確性和他的數據處理能力。
由於我是個 mi boy 並且小米馬上會在 26 號開可能是他們今年最重要的一次發佈會,基本上很多信息都看到過了,於是就用這個主題進行檢索,這樣可以減小我自己核實信息的壓力。
提示詞:整理並搜索小米 2025 年 6 月 26 日發佈會內容,為不同產品打標籤,併為每條傳聞打出 可信度百分比,把即將發佈的產品預估規格與競品對比,輸出雷達圖或熱力表,結合往年同期銷量、宏觀消費指數、渠道備貨傳聞,給出保守 / 基準 / 激進三種銷量區間,並解釋關鍵假設,列出最可能受益的 10 家 A-股或港股供應鏈公司(附業務關聯理由、過去 30 日股價表現),並按高-中-低敏感度分級。
我這個問題已經相當離譜了,Kimi 深度研究除了要找到對應信息以外還要找到競品信息,還要找到往年同類產品的信息,還得基於這些數據和信息進行合理的預測,最後還得檢索相關的供應鏈上市公司。
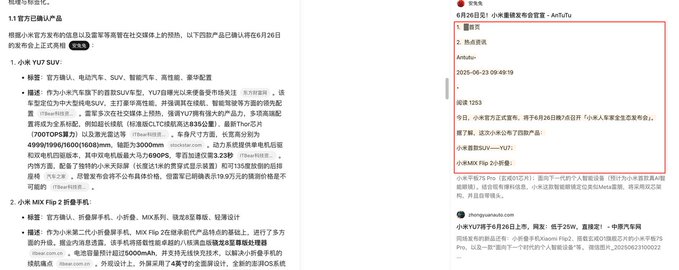
報告總字數依然達到了近 1.7 萬字。
同時通過目錄我們可以看到基本上我們提到的要求他都已經輸出了對應內容。
沒有行業上類似產品常見的在複雜問題和長上下文上偷懶的問題。
他先是羅列了一下即將發佈的主要產品信息,還按可信度做了區分。
有個很好的設計點是,點擊引用來源的時候,被引用的數據會直接高亮顯示,方便用戶核對,這個非常貼心。
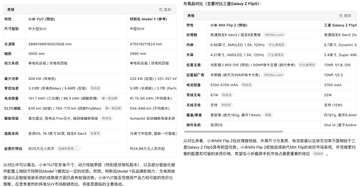
這裡座艙系統小米 YU 7 使用驍龍 8 Gen3 這個數據很關鍵,因為很少有目前沒有汽車在車機上使用手機芯片,而且這個信息是這幾天才發佈的,可以看到 Kimi 在內容檢索上的準確性和時效性非常高。
接下來銷量預測這裡除了給出每一個預測級別的原因外,還給出了對應的銷量的關鍵假設因素,幫助閱讀者進行判斷。
複雜數據檢索的全面性、準確性和數據分析上 Kimi 這個深度研究真的很厲害。


注入美學,讓專業報告“活”起來
再強大的功能,如果不能被輕鬆理解和使用,價值也將大打折扣。Kimi的交付物在“好用”和“好看”上做到了統一。
除了生成文檔之外,kimi 也會同步生成一份研究報告的可視化網頁。
Kimi 的這個可視化網頁不是其他同類產品那種信息和報告完全不成比例的玩具,他們的內容非常詳細,基本上大綱裡面有的網頁都有。
而且左側還有對應的大綱方便切換到具體的內容。
而且整個網頁排版清晰,符合當代用戶的審美習慣。思維導圖、結構化列表等形式,讓複雜信息一目瞭然。
圖表這裡每個都可以自由拖動和放大縮小,解決了通過圖表組件生成的圖表內容不適合預覽的問題。
他們也不是一套模板吃到底,每個網頁AI 都會根據自己檢索到的信息生成符合對應品牌的主題色和設計風格,比如小米這裡的橙色。
在素材的嵌入上,也不會隨便找圖,基本上都跟當前描述的內容相關,甚至我在調研 Plaud ai 這個硬件產品的時候他在頭圖位置放了一個硬件的展示視頻!
比如小米這個網頁競品對比這裡的高亮色和右邊卡片裡面通過黃色和綠色背景色和圖表兩個層面來表現優劣勢,非常直觀,極大提升了信息獲取效率。



測試和介紹到這裡就結束了。
雖然都是深度研究,Kimi 這個基於強化學習的模型還是展現出了跟使用常見模型通過提示詞和工具使用上非常不同的結果傾向,讓我們看到了複雜檢索任務不依賴大 Prompt 工程的的強大之處。
期待 Kimi 即將開源的預訓練與 RL 權重,應該能造福非常多有類似功能的產品。
來自推特
免責聲明:以上內容僅為作者觀點,不代表Followin的任何立場,不構成與Followin相關的任何投資建議。
喜歡
收藏
評論
分享




