

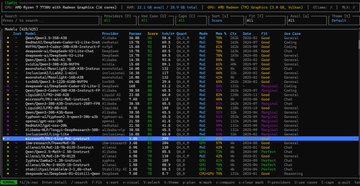
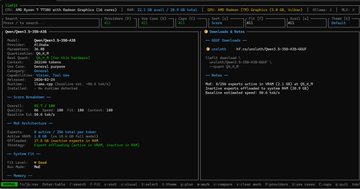
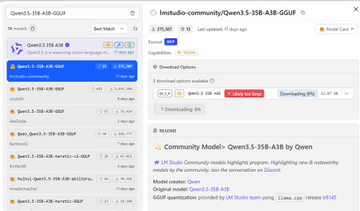
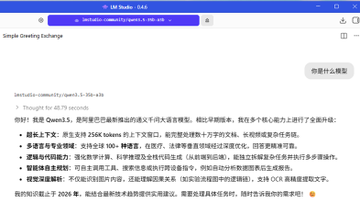
本地運行小龍蝦最好的還是基於Ryzen 7 處理器的Windows Mini PC - 因為我們還可以在本地運行Qwen 3模型! 環境:Windows 11 pro, AMD Ryzen 7 7730U with Radeon graphics 16 cores, 32G RAM 1) PowerShell Admin下,安裝scoop Set-ExecutionPolicy -ExecutionPolicy RemoteSigned -Scope CurrentUser Invoke-RestMethod -Uri get.scoop.sh | Invoke-Expression 2) 用 scoop 安裝 llmfit scoop install llmfit 3) 運行 llmfit,找到最適合該電腦的開源本地大模型 Qwen3.5-35B-A3B(MoE架構,總35B參數但只激活3B),推理效率極高,加載時需要全部權重。 Q3_K_M ≈ 16-17GB(16GB RAM) Q4_K_M ≈ 21-22GB(32GB RAM) 4)安裝 LM Studio(Windows版) lmstudio.ai 下載後直接雙擊安裝 5) 運行 lmstudio , 搜索 Qwen3.5-35B-A3B 選擇:Qwen3.5-35B-A3B-GGUF 版本 下載:Q3_K_M Q4_K_M 6)選擇下面的參數,啟動你下載的模型: Context Length:16384 後面覺得穩再拉32768 GPU Offload:直接拉到 40 如果加載失敗就退到35 CPU Thread Pool Size:拉到 16 Evaluation Batch Size:改成 512 Max Concurrent Predictions:保持 4 Unified KV Cache:保持 開啟 Offload KV Cache to GPU Memory:保持開啟 Number of Experts:保持 8 Number of layers for which to force MoE weights onto CPU:改成 0 不讓MoE層回CPU,全GPU加速 Flash Attention 開啟 Keep Model in Memory 開啟 Try mmap 開啟 RoPE Auto Remember settings:勾上,下次一鍵加載 點 Load Model,第一次加載會花1-3分鐘(全offload要搬運大文件),耐心等。加載成功後直接聊天測試。 Tips: BIOS裡iGPU共享內存設到8GB,速度還能再擠一點。 開始聊天!100% 本地化的LLM,安全,放心。

Kenny.eth
@_0xKenny
03-10
新购龙虾🦞小主机 - Windows Mini PC,甚至可以跑轻量级本地小模型。
放在家里平时帮我处理的大部分网站访问需求,定期缴纳各种费用、查询邮件等等,全部用OpenClaw自动化。
GMKtec M5 Ultra Gaming Mini PC Ryzen 7 7730U (Upgraded 7430U/ 5825U), 32GB RAM 512GB SSD Dual NIC LAN 2.5GbE Desktop




來自推特
免責聲明:以上內容僅為作者觀點,不代表Followin的任何立場,不構成與Followin相關的任何投資建議。
喜歡
收藏
評論
分享





