這篇文章還有更好的視覺化方式(使用動態圖表,可以更清晰地解釋一些概念和基準測試結果)。如果您喜歡這種方式,請查看: Binary Trie Group-Depth Benchmark — 比預期更窄
S1 – 執行摘要
二元樹是以太坊協議的初步構想,旨在取代未來的狀態樹。目前,尚未有任何二元樹實現進行大規模基準測試——無論是群組深度還是其他任何方面。鑑於此轉型已列入路線圖,評估效能特徵是進行合理原型設計的前提。 Geth 實作( EIP-7864 )提供了一個 ` --bintrie.groupdepth參數,用於控制二元樹層級在磁碟節點中的打包方式;本研究對八種配置進行了基準測試,以確定最佳設定。
結論:最佳選擇是 GD-5 或 GD-6,取決於工作負載。 GD-5 的寫入效能比 GD-4 高 7%(6.94 Mgas/s 對 6.47 Mgas/s, p < 1e-9)。 GD-6 在讀取效能(6.39 Mgas/s)和混合工作負載(比 GD-4 高 19%,p < 1e-3)方面領先。 GD-7 證實性能在 GD-6 之後開始下降。
我們測試了
在包含約 4 億個狀態條目的 360 GB 資料庫上,使用了八種組深度配置(GD-1 至 GD-8)。五種基準測試類型——兩種合成測試(原始 SLOAD/SSTORE)和三種 ERC20 合約工作負載——每種類型在冷緩存協議下運行 9 次。所有結果均使用中位數,並採用Mann-Whitney U檢定進行顯著性檢定。
我們發現了什麼
- 讀取結果證實了直覺(第 4 節):樹越寬,讀取速度越快。 GD-8 的讀取吞吐量是 GD-1 的兩倍以上(5.59 Mgas/s 對比 2.65 Mgas/s)。 GD-6 的讀取吞吐量最高(6.39 Mgas/s),其次是 GD-5(6.11 Mgas/s)和 GD-7(6.04 Mgas/s)。 GD-3 到 GD-8 的吞吐量範圍在 5.2 到 6.4 Mgas/s 之間。
- 寫入性能展現出更明顯的優化(第 5 節):GD-5 以 629 毫秒(6.94 Mgas/s)的寫入速度位居榜首,比 GD-4(678 毫秒,6.47 Mgas/s)快 7%,比 GD-8(982 毫秒,4.47 Mgas/s)快 55%。寫入效能的拐點位於 GD-5 和 GD-6 之間(雜湊/讀取比率超過 1.0)。
- 節點大小在 GD-7 時達到 Pebble 區塊大小的邊界(第 5 節):每個 GD-7 節點序列化後約為 4 KB(128 × 32 位元組)-恰好是 Pebble 區塊大小。低於此邊界(GD-6:約 2 KB)時,每個節點都包含在一個區塊內。高於此邊界時,每個節點的讀取操作可能需要兩個區塊。 Gary Rong 的 NVMe 基準測試表明,在 QD=1 時,隨機讀取 8 KB 的資料比讀取 4 KB 的資料延遲高出 54%(77.8 微秒 vs 50.6 微秒)。這種每個節點的 I/O 開銷會在約 37 個路徑節點上累積,這解釋了為什麼 GD-7 的讀取速度比 GD-6 慢,儘管路徑更短。
- 最佳方案是 GD-5 或 GD-6 (第 6 節):GD-5 在寫入效能上比 GD-4 高出 7%,而 GD-6 在讀取效能(比 GD-5 高出 5%)和混合工作負載效能(比 GD-4 高出 19%)方面更勝一籌。 GD-7 證實了這一拐點——在所有基準測試中均遜於 GD-6。由於以太幣的讀取操作較多,因此 GD-6 可能是更合適的預設方案。
如何閱讀這篇文章
- 第 2 節(背景)介紹了二元樹和群體深度概念。
- 第 3 節(方法論)詳細介紹了基準測試設定。
- 第 4-6 節以敘事弧線呈現結果:閱讀、寫作,然後是權衡。
- 第 7 節(模式)探討了交叉觀察結果。
- 第 8 節(結論)提出了雙重建議和未解決的問題。
時間不夠?那就從第 4 部分「ERC20 閱讀:深度至關重要」開始——在這一部分,群體深度差異最為明顯,並為其餘的分析奠定了基礎。

S2 – 背景
什麼是二元樹?
EIP-7864 提議用二進位 trie 樹替換以太坊的 Merkle Patricia trie 樹(MPT)。二元 trie 樹將帳戶 trie 樹和所有儲存 trie 樹合併成一棵樹,使用 SHA-256 雜湊演算法取代 Keccak-256 雜湊演算法,並儲存映射到 256 個值的 32 位元組樹幹。這種設計簡化了無狀態客戶端的見證生成,並實現了更有效率的證明。
從 MPT 到二元樹的過渡是以太坊狀態層最重要的變化之一。新結構的性能特徵將直接影響區塊處理時間、同步速度和驗證者的經濟效益。
什麼是群組深度?
trie 樹在根本層面上總是二元樹-每個內部節點剛好有兩個子節點(左子節點對應位元 0,右子節點對應位元 1)。群組深度控制單一磁碟節點中包含多少個二元樹層級。在 GD-N 演算法中,每個儲存的節點封裝了一個 N 層二元樹子樹,因此從外部觀察,它看起來有 2^N 個子節點:
- GD-1:每個節點 1 個二進位等級 → 2 個子指針,到葉子節點的路徑上有 256 個節點
- GD-2:每個節點 2 個二進位等級 → 4 個子指針,路徑上有 128 個節點
- GD-3:每個節點 3 個二進位等級 → 8 個子指針,路徑上約 86 個節點
- GD-4:每個節點 4 個二進位等級 → 16 個子指針,路徑上 64 節點
- GD-5:每個節點 5 個二進位等級 → 32 個子指針,路徑上約 52 個節點
- GD-6:每個節點 6 個二進位等級 → 64 個子指針,路徑上約 43 個節點
- GD-7:每個節點 7 個二進位等級 → 128 個子指針,路徑上約 37 個節點
- GD-8:每個節點 8 個二進位等級 → 256 個子指針,路徑上 32 個節點
你可以把它想像成郵遞區號:GD-1 每次讀取地址一位數字(256 步),而 GD-8 一次讀取 8 位數字(32 步)。步數越少,磁碟讀取次數就越少——但每個「捆綁節點」都更大,更新成本也更高,因為其內部的二進位子樹必須重新雜湊。
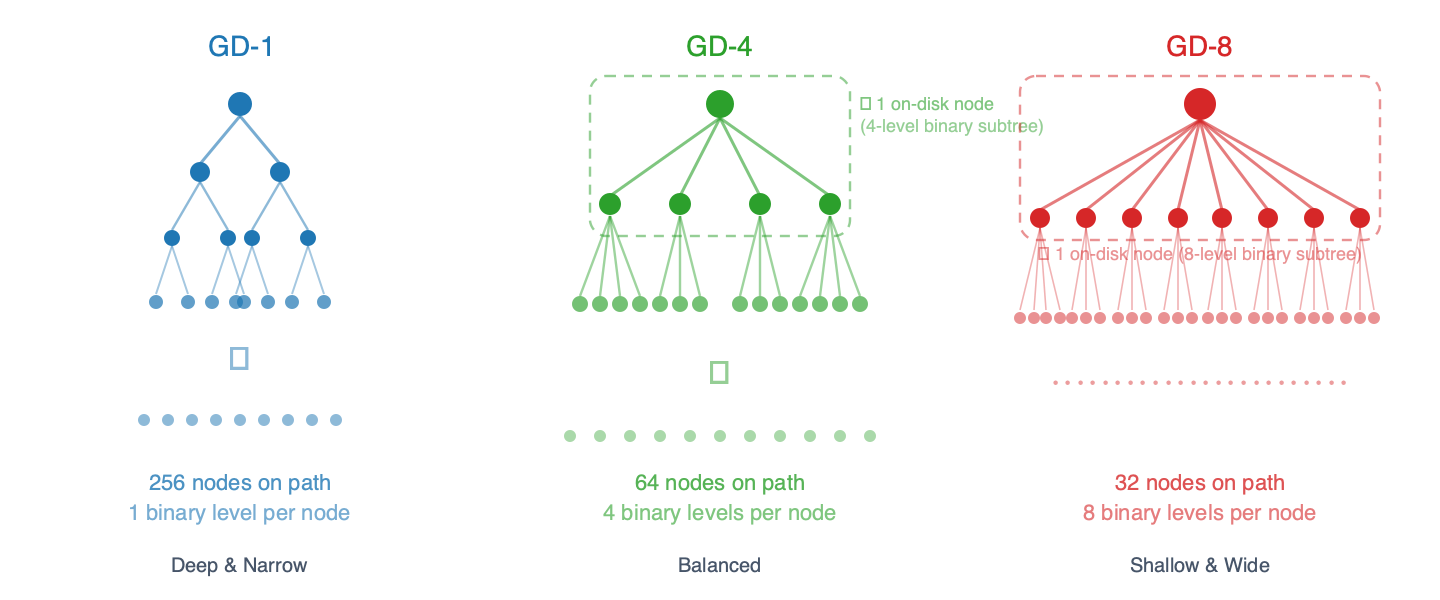
圖 1 – 不同分組深度下的樹狀結構。每個節點內部捆綁了 N 個二進位層級,從而減少了到達葉節點的路徑上的磁碟節點數量。
理論上,這種權衡很簡單:讀取操作受益於淺樹結構(到達葉節點所需的磁碟 I/O 操作更少),而寫入操作則受制於寬節點結構(節點修改時需要更多的內部雜湊運算)。問題在於,這種權衡的臨界點在哪裡。
S3 – 方法論
概括
基準測試設置
| 範圍 | 價值 |
|---|---|
| 機器 | QEMU 虛擬機 – 8 個虛擬 CPU,30 GB 內存,3.9 TB 固態硬碟,Ubuntu 24.04 LTS |
| 資料庫 | 約 360 GB,約 4 億個帳戶 + 儲存槽位 |
| 配置 | GD-1、GD-2、GD-3、GD-4、GD-5、GD-6、GD-7、GD-8(Pebble,geth 使用的 LSM 樹儲存引擎,4KB 區塊大小) |
| 協定 | 冷緩存(作業系統頁面快取已清除 + Pebble 快取=0,運行間) |
| 跑 | 每個基準測試每個配置運行 10 次;排除運行 1(殘留溫度) |
| 氣體目標 | 每個方塊含1億氣體 |
統計方法
- 9 次保留運行的每次運行區塊中位數匯總
- 用於成對比較的曼-惠特尼U檢定(非參數檢定)
- 效應量以與基線(GD-1)的百分比差異表示。
- 一致性評估的變異係數 (CV%)
基準分類
a) 綜合基準測試sstore_variants (寫入)和sload_benchmark (讀取)。這些測試使用 EIP-7702 委託機制,並採用順序儲存槽。鍵值按數字順序排列,導致 trie 樹中存在大量的前綴共用。
b) ERC20 基準測試balanceof (讀取)、 approve (寫入)和mixed 。這些測試使用真實的 ERC-20 合約代碼。儲存金鑰是隨機位址的 Keccak 雜湊值,從而在 trie 樹中產生均勻分佈的存取模式。
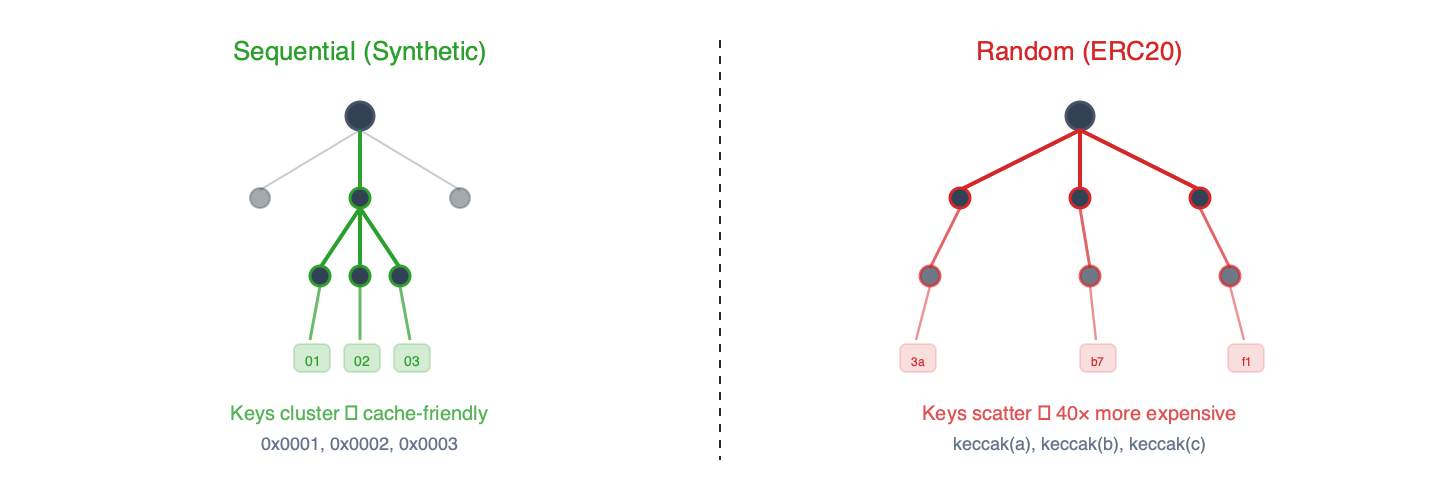
圖 2 – 順序鍵共享 trie 樹前綴,並受益於快取。 Keccak 哈希鍵均勻分佈,導致每一層都進行冷讀取。
區塊組成說明
執行規範測試框架會將所有基準測試交易一次傳送到 Geth 的記憶體池(在 1秒內)。 Geth 的開發模式礦工( dev.period=10 )隨後會在 10 秒的區塊建立視窗內按順序處理來自該記憶體池的交易——當計時器到期時,它會挖出所有已處理的交易。瓶頸在於 trie 樹的運行時間,而非 gas 容量:每個 ERC20 認證交易僅消耗約 4.4M gas(1 億 gas 的區塊 gas 上限大約可以容納 22 筆交易),但在速度較慢的配置下,trie 樹操作(遍歷、更新、哈希、提交)幾乎會消耗整個交易時間,即使是整個交易時間也是如此。設定交易(簡單的 ETH 轉帳)在 77 毫秒內處理 7 筆交易,證實了 trie 樹的成本——而非交易開銷——才是限制因素。
經過驗證的冷緩存移除(第三階段),所有配置現在每個區塊處理 1 筆交易(中位數 tx_count=1)。機制解釋仍然有效——10 秒的dev.period作為時間預算,而 trie 樹操作成本決定了可以容納多少筆交易。 Mgas /s(吞吐量)是正確的比較指標,因為它消除了不同配置之間的 gas 差異。如果顯示的是原始毫秒數,則反映的是該配置區塊組成所需的實際區塊處理時間。
S4 – 第一幕:閱讀證實直覺
ERC20 讀法:深度至關重要
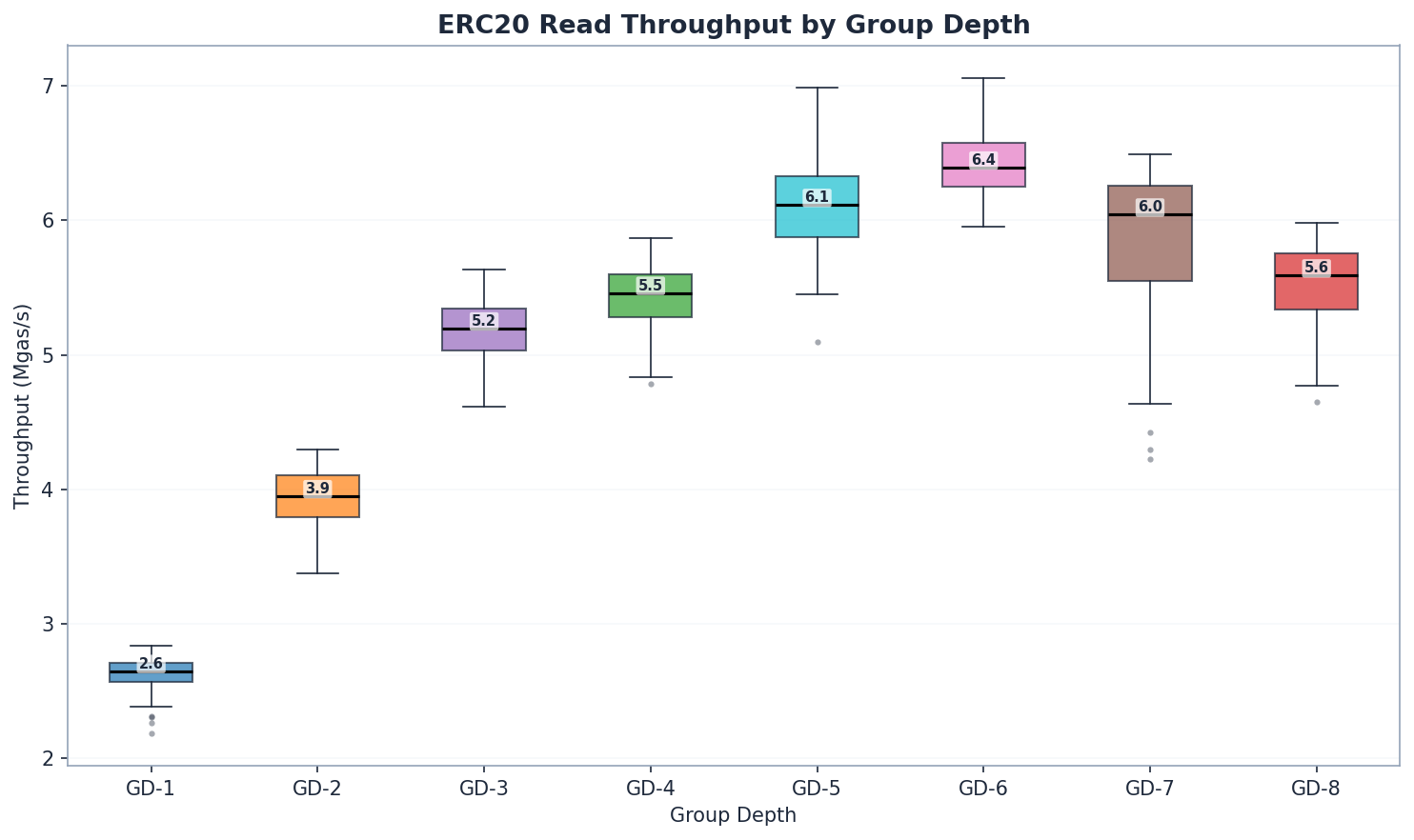
| GD | 狀態讀取(毫秒) | 總計(毫秒) | 兆氣體/秒 | 與 GD-1 (Mgas/s) 相比 |
|---|---|---|---|---|
| 1 | 5,878 | 6,284 | 2.65 | 基線 |
| 2 | 3,840 | 4,231 | 3.95 | +49% |
| 3 | 2,866 | 3,213 | 5.20 | +96% |
| 4 | 2,677 | 3,067 | 5.46 | +106% |
| 5 | 2,370 | 2,733 | 6.11 | +131% |
| 6 | 2,248 | 2,623 | 6.39 | +141% |
| 7 | 2,339 | 2,693 | 6.04 | +128% |
| 8 | 2,598 | 2,977 | 5.59 | +111% |
GD-1 到 GD-6 的讀取吞吐量提升了約 2.4 倍。 GD -6 的讀取吞吐量最高 (6.39 Mgas/s),其次是 GD-5 (6.11) 和 GD-7 (6.04)。讀取效能從 GD-1 到 GD-6 單調遞增,之後逐漸下降-如預期,由於路徑較短,GD-4 (5.46) 的效能優於 GD-3 (5.20)。隨著節點規模增加到足以抵銷路徑縮短帶來的優勢,GD-7 和 GD-8 的效能提升逐漸遞減。
為什麼與合成密鑰存在如此巨大的差異? Keccak 密鑰均勻分佈,迫使從根到葉進行完整遍歷。 GD-1 需要向下遍歷 256 層;而 GD-8 只需 32 層。每一層都可能導致磁碟尋道。隨機存取會暴露出完整的深度開銷。
GD-3(3213毫秒,5.20兆位元組/秒)和GD-4(3067毫秒,5.46兆位元組/秒)在讀取效能上非常接近,GD-4由於其路徑更短(64個節點對比約86個節點)而略勝一籌,這與預期相符。 GD-3較小的節點序列化大小(約256位元組對比GD-4的約512位元組)與Pebble的4KB區塊大小相輔相成,使得儘管樹形差異很大,兩者的效能差距仍保持在5%以內。 Pebble塊大小的影響機制仍值得進一步研究(開放性問題#3 )。
每個插槽的成本:合成讀取的成本約為 0.02 毫秒/插槽。 ERC20 讀取的成本約為 0.4–1.0 毫秒/插槽(計算方法為 state_read_ms / 儲存槽位_讀取每個區塊)-隨機存取模式的成本是其 40 倍。
這個 40 倍的比率與 NVMe 的原始測量結果一致: Gary Rong 的磁碟頁面讀取基準測試顯示,隨機 4KB 讀取速度為 77 MB/s,而順序讀取速度為 3,306 MB/s(43 倍),這證實了效能損失主要由 I/O 存取權而非 Pebble 開銷模式。
為什麼隨機存取是基準而非例外?二元樹將所有帳戶和儲存統一到一個樹中。每個按鍵——無論是帳戶餘額、儲存槽位還是程式碼區塊——都會經過 SHA256 雜湊處理,產生 256 位元金鑰空間。單一合約的儲存槽位分佈在完全不同的樹路徑上。這使得隨機存取成為二元樹的基本存取模式,而非特殊情況。合成的順序基準測試代表了不切實際的最佳情況,在統一的樹部署中不可能出現。
目前來看,寬度越大越好——但也存在一定的限制。 GD-6 在讀取效能方面領先,而 GD-7 和 GD-8 的效能提升則逐漸遞減。接下來,我們測試了寫入效能。
S5 – 第二幕:寫作的驚喜
這是研究最重要的發現。
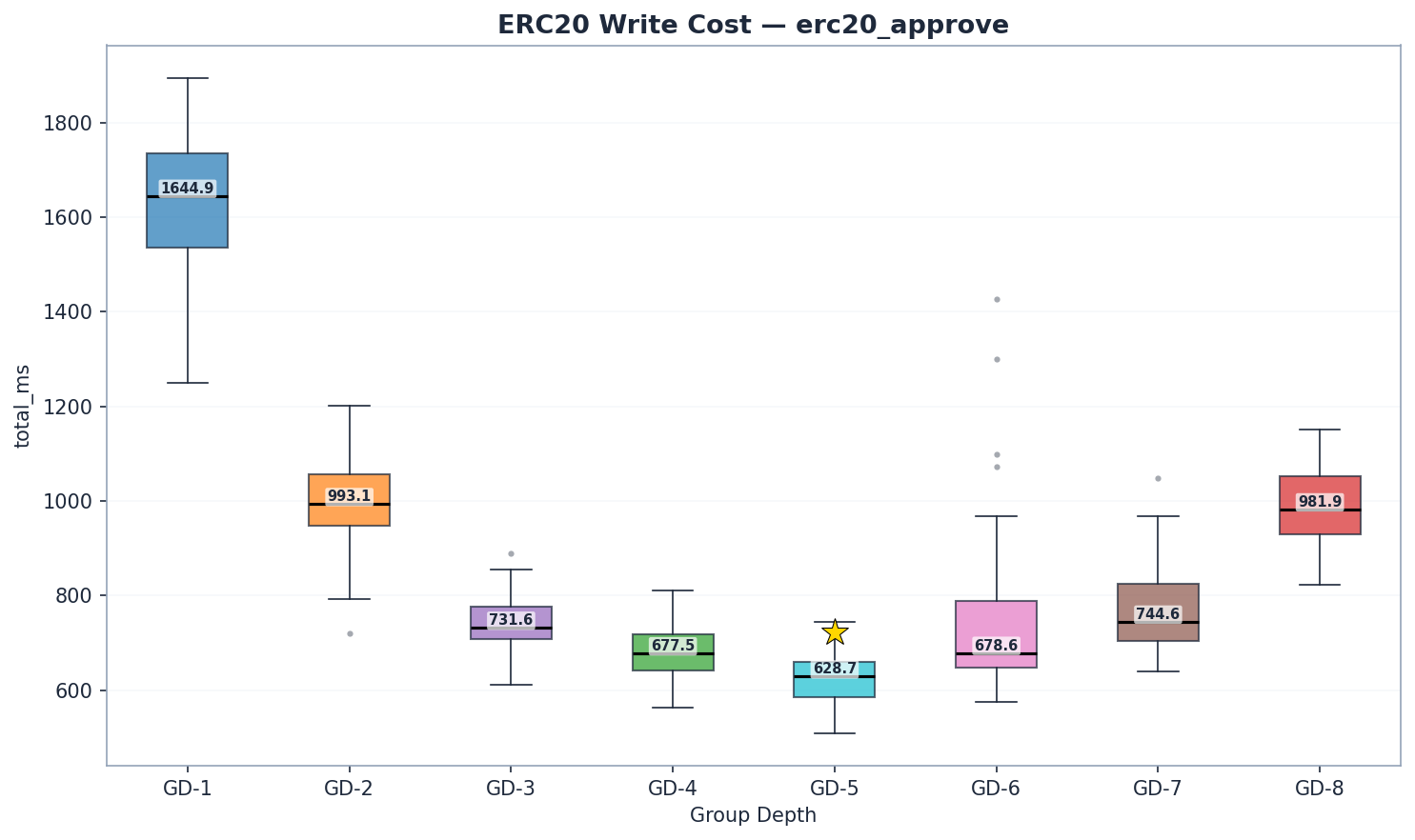
| GD | 狀態讀取 | trie_updates | 犯罪 | 全部的 | 兆氣體/秒 |
|---|---|---|---|---|---|
| 1 | 812 | 691 | 77 | 1,645 | 2.67 |
| 2 | 483 | 393 | 61 | 993 | 4.42 |
| 3 | 349 | 287 | 44 | 732 | 5.95 |
| 4 | 313 | 254 | 53 | 678 | 6.47 |
| 5 | 271 | 242 | 57 | 629 | 6.94 |
| 6 | 272 | 283 | 76 | 679 | 6.41 |
| 7 | 264 | 328 | 103 | 745 | 5.81 |
| 8 | 313 | 433 | 158 | 982 | 4.47 |
trie_updates = state_hash_ms (AccountHashes + AccountUpdates + StorageUpdates) — 涵蓋了完整的 trie 樹變異和重哈希階段,而不僅僅是哈希操作。所有配置均使用經過驗證的冷緩存協定運行(作業系統頁面快取會在運行之間清除)。第三階段的變異係數 (CV) 在 Mgas/s 上大多小於10 %,證實了測量結果的可靠性。
GD-5 是最佳配方,氣體流量為 6.94 Mgas/s,比 GD-4(6.47 Mgas/s, p < 1e-9)快 7%,比 GD-8(4.47 Mgas/s)快 55%。 GD-6(6.41 Mgas/s)排名第三,緊追在 GD-4 之後。 GD-7(5.81 Mgas/s)證實了氣體流量的拐點在 GD-6 之後仍在繼續。
組件分解圖說明了一切:
- 讀取速度: GD-5 (271 毫秒) 比 GD-4 (313 毫秒) 快 13%。 GD-6 (272 毫秒) 與 GD-5 相當,而 GD-7 (264 毫秒) 是速度最快的讀取器-但原始的毫秒數必須與百萬氣體/秒 (Mgas/s) 結合才能進行公平的比較,因為每個模組的氣體量可能有所不同。
- Trie 更新: GD-5 (242 ms) 比 GD-4 (254 ms)低 5% 。 GD-6 略微上升至 283 ms(比 GD-5 高 17%),並未像早期數據所顯示的那樣急劇上升。 GD-7 (328 ms) 和 GD-8 (433 ms) 證實了拐點仍在持續。
- 提交: GD-5 (57 毫秒) 略高於 GD-4 (53 毫秒)。 GD-6 (76 毫秒,比 GD-5 增加 33%) 和 GD-7 (103 毫秒) 的提交時間略有增加。真正的提交時間斷崖出現在 GD-8 (158 毫秒),這是因為每次寫入需要序列化約 256 KB 的數據,而每個節點約有 8 KB x 32 個路徑節點。
寫入拐點位於 GD-5 和 GD-6 之間:雜湊/讀取成本比在 GD-6 處超過 1.0 (283/272 = 1.04),這表示 trie 更新開始超過讀取成本。以 Mgas/s 計算,GD-5 (6.94) 比 GD-4 (6.47) 高 7%,比 GD-6 (6.41) 高 8%。
為什麼?內部子樹
每個深度為g的trie 節點都包含一個內部二叉樹,該二叉子樹有2^g - 1 2 g − 1 個節點,每次寫入時都必須重新哈希。
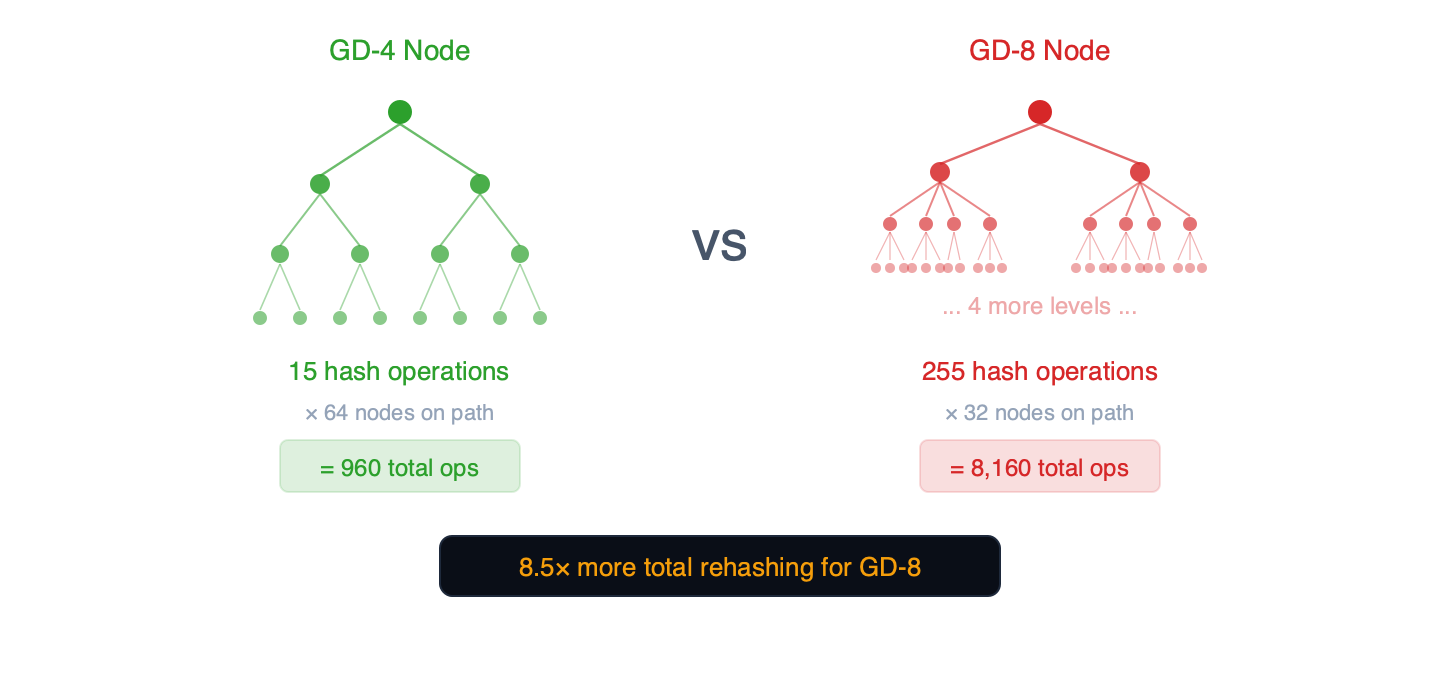
圖 3 – 每個 trie 節點都包含一個內部二元樹。節點越寬,每次寫入所需的哈希運算量就呈指數級增長。
- GD-4 節點: 15 次內部雜湊操作 x 路徑上的 64 個節點 =總共 960 次操作
- GD-5 節點: 31 次內部雜湊操作 x 路徑上的約 52 個節點 =約 1,612 次總操作
- GD-8 節點: 255 次內部雜湊操作 x 路徑上的 32 個節點 =總計 8,160 次操作
GD-5 找到了寫入效能的最佳平衡點:其路徑比 GD-4 短 19%(約 52 個節點對比 64 個節點),且每個節點的 31 次內部操作仍然可控。在 GD-6(每個節點 63 個內部節點)時,重新雜湊的成本略有上升——283 毫秒對比 GD-5 的 242 毫秒(+17%)。 GD-7(雜湊 328 毫秒,提交 103 毫秒)證實了拐點在 GD-6 之後仍在繼續。寫入效能的拐點位於 GD-5 和 GD-6 之間,此時雜湊/讀取比率超過 1.0。
註: 17 倍的比例(255 次內部雜湊操作對比 15 次內部雜湊操作)是此資料結構的理論上限。我們的基準測試支援此機制:GD-8 trie 樹的更新成本是 GD-4 的 1.71 倍(433 毫秒對比 254 毫秒),這與隨機寫入操作修改每個節點內部子樹的一部分相符。 geth 實作是重哈希演算法的權威來源。
節點序列化大小
每個 trie 節點最多可儲存 2^N 個子指標(每個指標 32 位元組)。 GD-4 節點:16 × 32 =約 512 位元組。 GD-7 節點:128 × 32 =約 4 KB-剛好是 Pebble 的區塊大小。 GD-8 節點:256 × 32 =約 8 KB 。大小差異會產生連鎖反應:
- Pebble 資料塊邊界: GD-6 節點(約 2 KB)可以容納在一個 4 KB 的 Pebble 資料塊內。 GD-7 節點(約 4 KB)則幾乎佔滿整個資料區塊-加上金鑰開銷,它們可能跨越兩個資料區塊,導致每次節點讀取的 I/O 量翻倍。這部分解釋了 GD-7 讀取操作的逆向:儘管路徑節點比 GD-6 少 14%(37 個節點對 43 個節點),但 GD-7 每次查找的總讀取量約為 148 KB(37 × 4 KB),而 GD-6 每次查找的總讀取量約為 86 KB(43 22 KB)。
- Pebble快取效率:在給定的快取預算內,可容納的GD-8節點數量較少
- 寫入放大:較大的串列節點會增加 LSM 壓縮開銷。
- 提交成本: 198% 的提交懲罰(158 毫秒對比 53 毫秒)部分反映了每個修改節點需要序列化的資料量是原來的 16 倍。

圖 4 – 對於讀取操作,只有向下遍歷才重要(有利於 GD-8)。對於寫入操作,重新雜湊和提交操作占主導地位(有利於 GD-4)。讀取操作 = 僅步驟 1。寫入操作 = 步驟 1 + 2 + 3。
S6 – 第三幕:權衡取捨
判決
| 標準 | GD-4 | GD-5 | GD-6 | GD-7 | GD-8 |
|---|---|---|---|---|---|
| 讀取量(兆加侖/秒) | 5.46 | 6.11 | 6.39 | 6.04 | 5.59 |
| 寫入量(兆氣體/秒) | 6.47 | 6.94 | 6.41 | 5.81 | 4.47 |
| 混合氣(兆氣體/秒) | 5.13 | 6.09 | 6.27 | 5.87 | 5.43 |
| 類別獲獎 | 0/3 | 1/3 | 2/3 | 0/3 | 0/3 |
GD-6 在讀取和混合效能測試中均勝出;GD-5 在寫入效能測試中勝出。 GD -5 的寫入效能比 GD-4 高出 7%( p < 1e-9)。 GD-6 的讀取效能比 GD-5 高出 5%,混合效能比 GD-4 高出 19%(p < 1e - 3)。 GD-7 的表現已過拐點,在所有三個基準測試中均遜於 GD-6。由於以太坊工作負載以讀取為主,因此 GD-6 可能是更佳的預設選擇,而 GD-5 則更適合寫入為主的場景。
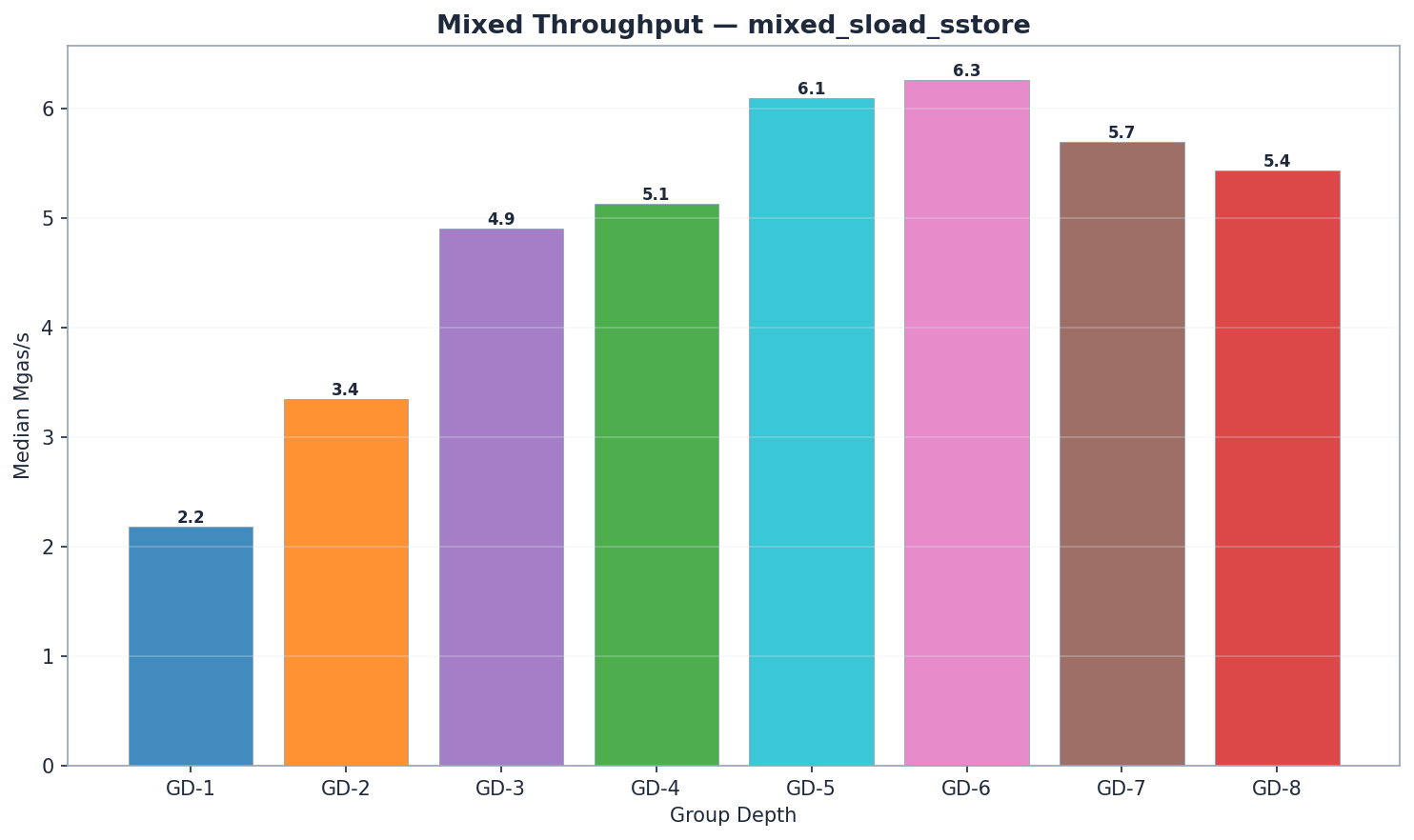
混合工作負載
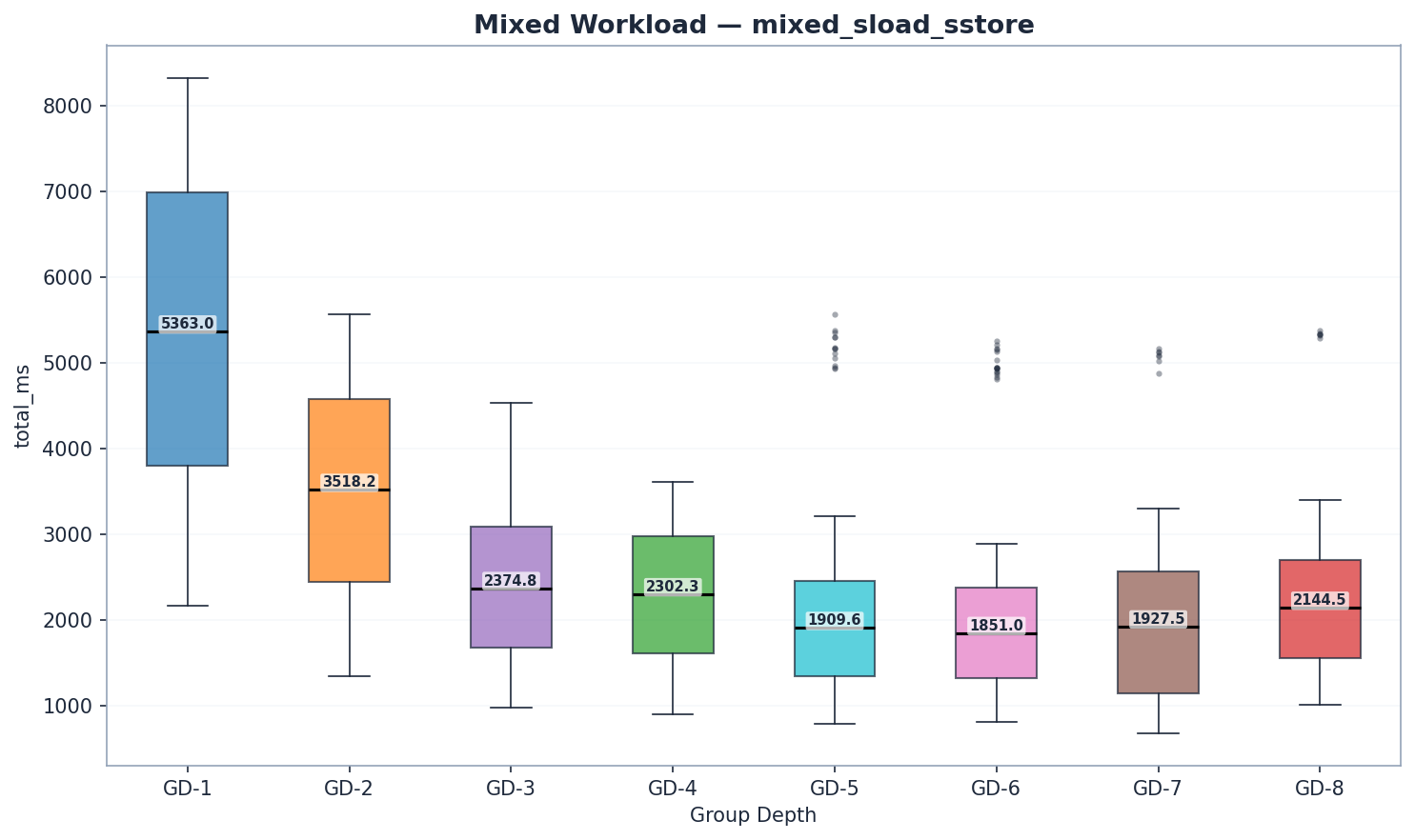
| GD | 狀態讀取 | trie_updates | 犯罪 | 總毫秒數 | 兆氣體/秒 |
|---|---|---|---|---|---|
| 1 | 4,711 | 345 | 53 | 5,363 | 2.18 |
| 2 | 3,003 | 217 | 44 | 3,518 | 3.35 |
| 3 | 1,981 | 145 | 39 | 2,375 | 4.90 |
| 4 | 1,893 | 138 | 43 | 2,302 | 5.13 |
| 5 | 1,512 | 124 | 48 | 1,910 | 6.09 |
| 6 | 1,440 | 141 | 54 | 1,851 | 6.27 |
| 7 | 1,055 | 218 | 73 | 1,529 | 5.87 |
| 8 | 1,612 | 221 | 87 | 2,145 | 5.43 |
GD-7 的混合基準測試每個區塊處理的交易量較少(884 萬 vs 約 1,180 萬 gas)。 Mgas/s 已針對此差異進行了標準化,因此吞吐量比較仍然有效。 GD-7 混合基準測試的原始毫秒值無法與其他配置直接比較。
GD-6 在混合工作負載下以 6.27 Mgas/s 的效能領先,緊隨其後的是 GD-5(6.09 Mgas/s,提升 3%)。兩者均比 GD-4(5.13 Mgas/s)高出 19% 至 22%。 GD-6 的讀取優勢(state_read 為 1,440 毫秒,而 GD-5 為 1,512 毫秒)彌補了其略高的 trie 更新時間(141 毫秒 vs 124 毫秒)和提交時間(54 毫秒 vs 48 毫秒)。 GD-7(5.87 Mgas/s)落後 GD-6 6%,證實了性能拐點的存在。注意:GD-7 的混合工作負載下每個區塊使用 8.84M gas,而其他所有模型均為 11.80M;比較時應使用 Mgas/s,而非原始毫秒數。
未解決的問題:最佳分組深度最終取決於以太坊實際區塊的讀寫比例。雖然在我們的基準測試中,狀態讀取明顯佔據區塊處理時間的大部分,但主網的特定讀寫比例尚未得到系統測量。主網讀寫存取模式的歷史分析將有助於進一步完善這項建議。
組件分解揭示了熟悉的模式:
- 讀取效能: GD-7 的原始讀取時間最短(1055 毫秒),但每塊氣體消耗量較低。以氣體消耗量(百萬氣體/秒)計算,GD-6 (6.27) 領先。 GD-5 (1512 毫秒) 和 GD-6 (1440 毫秒) 的讀取效能優於 GD-4 (1893 毫秒)。
- Trie樹更新: GD-5領先(124毫秒),其次是GD-4(138毫秒)和GD-6(141毫秒)。由於內部子樹較大,GD-7(218毫秒)和GD-8(221毫秒)落後。
- 提交結果: GD-3 勝出(39 毫秒),GD-4(43 毫秒)和 GD-5(48 毫秒)緊追在後。 GD-7(73 毫秒)和 GD-8(87 毫秒)則顯示了更寬節點的序列化開銷。
S7 – 交叉切割圖案
時間都去哪了?
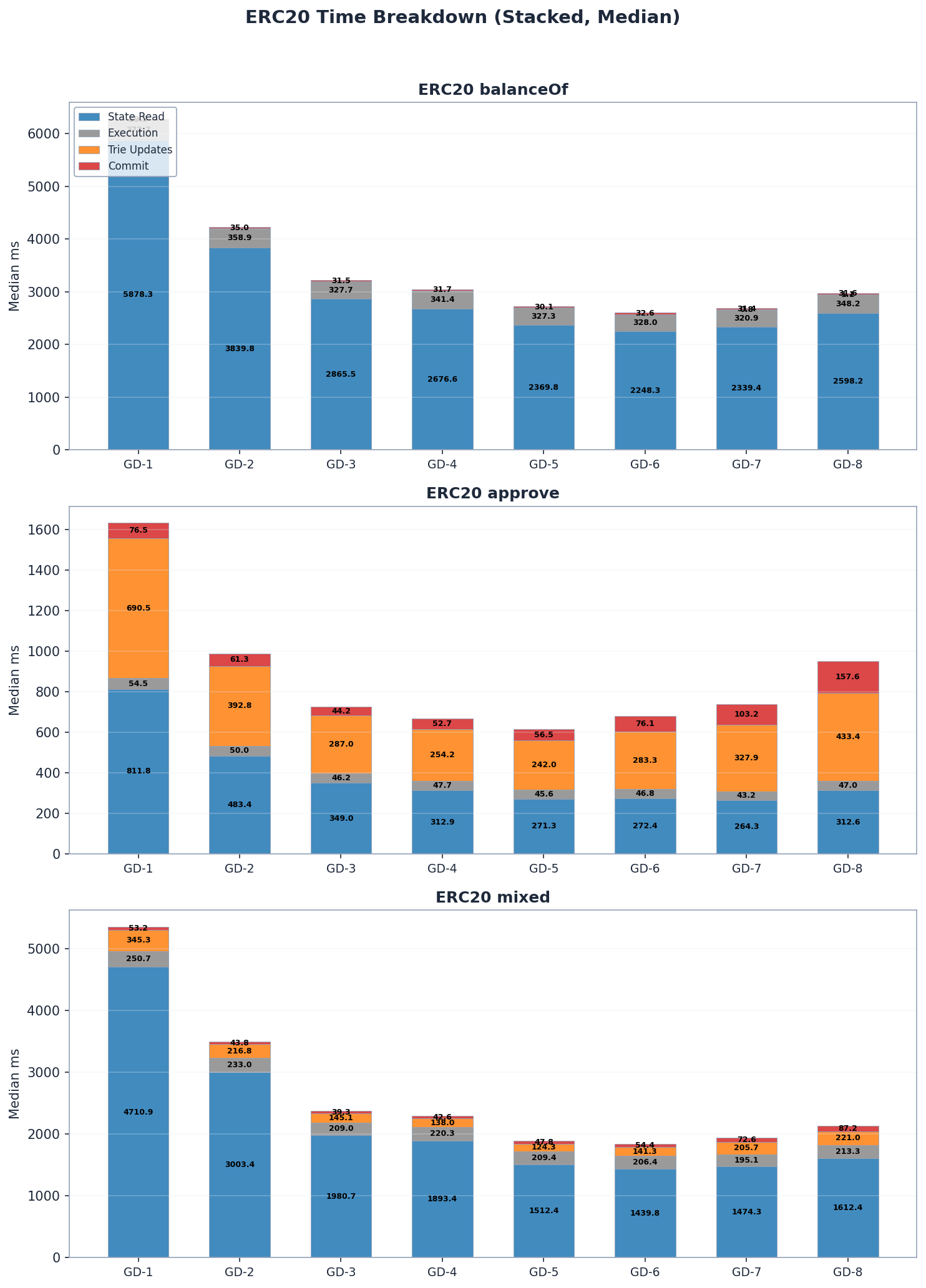
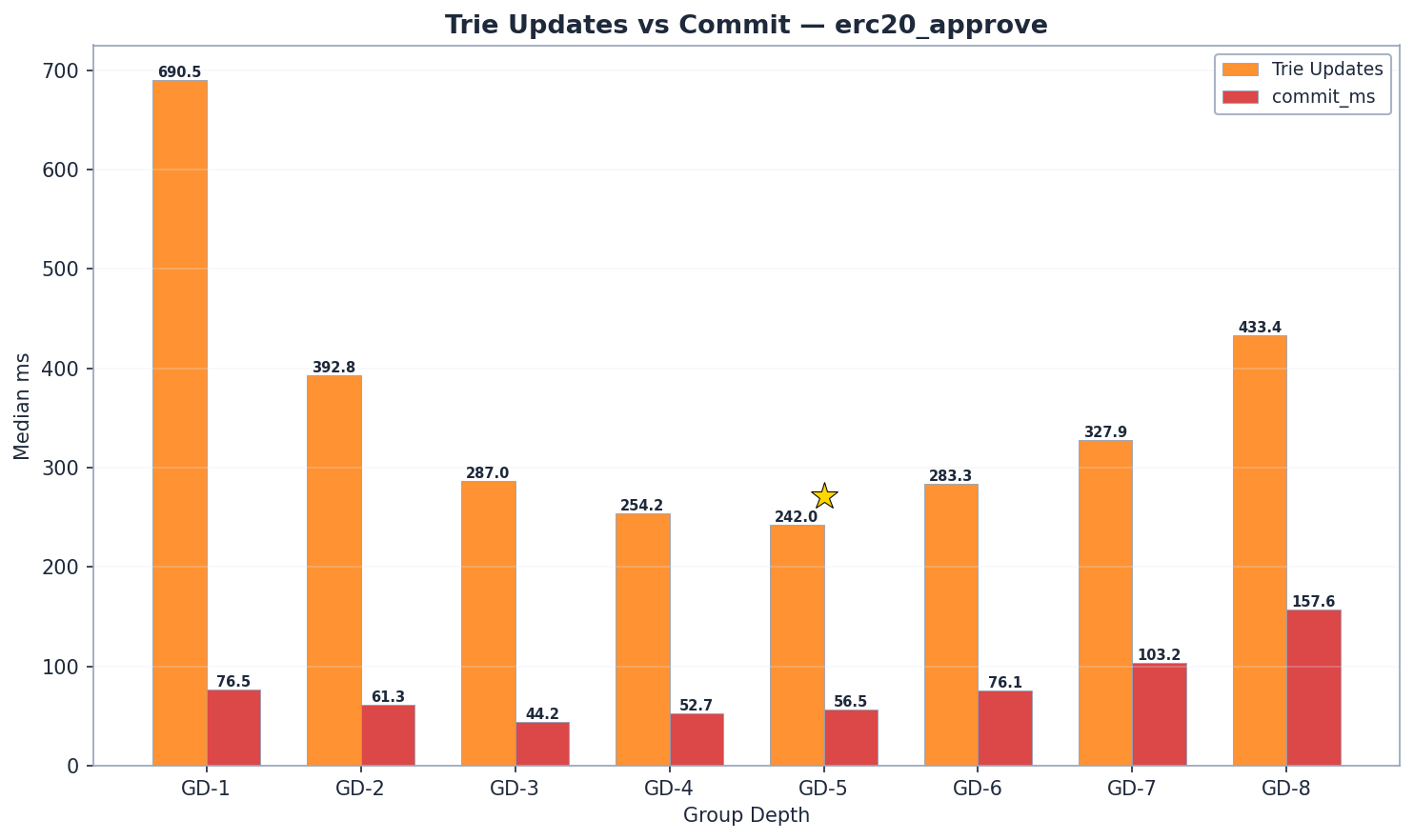
在所有群組深度配置中,狀態讀取都佔了 ERC20 區塊處理時間的大部分,佔總時間的 50% 到 85%。對於唯讀基準測試(balanceOf),trie 更新和提交的成本可以忽略不計,但對於寫入操作(approve),它們卻成為主要的成本組成部分——尤其是在群組深度較高的情況下,內部子樹重哈希的成本最高。
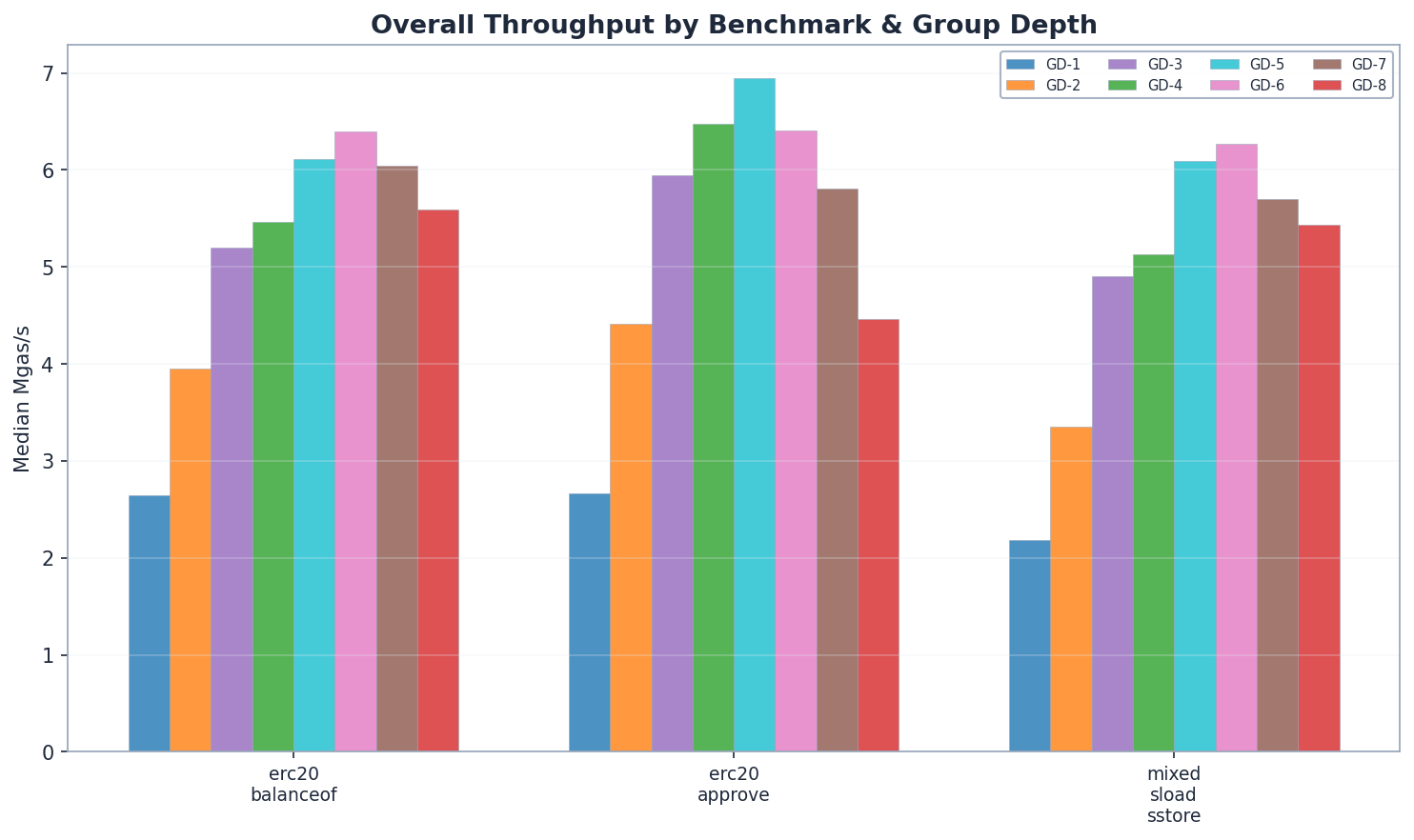
總體吞吐量
硬體環境:NVMe I/O 特性
Gary Rong 在 NVMe(三星 990 Pro)上進行的磁碟頁面讀取基準測試為解釋我們的結果提供了硬體背景:
- 隨機讀取與順序讀取: 4KB 隨機讀取 = 77 MB/s (50.6 µs) 與 3,306 MB/s 順序讀取 - 相差 43 倍,與我們每個插槽 40 倍的懲罰非常接近。
- 頁面大小至關重要:隨機讀取 16KB 資料時,吞吐量是讀取 4KB 資料時的 2.3 倍(174 MB/s 對比 77 MB/s),而延遲僅為 1.8 倍。更大的分組深度會產生更大的節點,這些節點可以從更大的 Pebble 區塊大小中受益。
- 佇列深度至關重要:從 QD=1 到 QD=8,隨機 4KB 吞吐量提升了 8.7 倍(從 77 MB/s 提升至 673 MB/s)。並行 EVM 可以進一步提升效能,縮小不同配置之間的讀取延遲差異。
- 延遲成長呈現亞線性趨勢:資料量從 4KB 成長到 64KB,成長了 16 倍,但延遲僅成長了 2.3 倍(從 50.6 微秒成長到 117.3 微秒)。 NVMe 的內部並行性意味著更大的 I/O 請求效率會顯著提高。
這些測量採用直接讀取頁面的方式,繞過檔案系統快取——類似於我們的冷緩存協定。基準測試硬體(三星 990 Pro)與我們的 QEMU 虛擬機器的虛擬磁碟不同,因此絕對值不會完全一致,但這些比率揭示了與群組深度最佳化相關的 NVMe 基本特性。
S8 – 結論
建議:GD-5 或 GD-6(視工作量而定)
最佳深度為GD-5或GD-6 ,視工作負載情況而定:
- 讀取密集型/混合型工作負載(預設建議):GD-6。讀取效能比 GD-5 高 5%(6.39 Mgas/s 對 6.11 Mgas/s),混合型工作負載高 3%(6.27 Mgas/s 對 6.09 Mgas/s)。由於以太坊是讀取密集型應用,因此 GD-6 是首選的預設配置。
- 寫入密集型工作負載:GD-5 的寫入速度比 GD-4 高 7%(6.94 對 6.47 Mgas/s),比 GD-6 高 8%(6.94 對 6.41 Mgas/s)。
- GD-7 證實了性能拐點。在所有三個基準測試中,GD-7 的效能均遜於 GD-6(讀取效能下降 5%,寫入效能下降 9%,混合效能下降 6%),這驗證了 GD-5 或 GD-6 才是最佳選擇。
該建議基於一個三步驟機制,控制著二元樹中的每個狀態存取:
- 橫切-從樹根往下到樹葉。成本與樹的深度成正比。有利於較寬的樹(GD-8:32 層 vs GD-5:約 52 層 vs GD-4:64 層)。
- 重新哈希-重新計算返回根節點路徑上每個節點的內部子樹。成本與每個節點的2^g - 1 2 g − 1成正比。有利於較窄的樹(GD-4:15 次操作/節點,GD-5:31 次操作/節點,GD-8:255 次操作/節點)。
- 提交操作-將修改後的節點序列化並寫入磁碟。成本與節點大小成正比。有利於較窄的樹狀結構。
GD-5 在寫入操作中找到了遍歷次數與重哈希次數權衡的最小值。它的路徑比 GD-4 短 19%(約 52 個節點對比 64 個節點),每個節點的 31 次內部操作仍然可控。在 GD-6 中,重哈希成本略有上升——從 GD-5 的 242 毫秒上升到 283 毫秒(+17%)——但讀取和混合工作負載的效能仍然有所提升。寫入效能的拐點位於 GD-5 和 GD-6 之間(雜湊/讀取比率超過 1.0),而讀取效能在 GD-6 達到峰值。
適用於所有分組深度的五種模式
模式 1:狀態讀取占主導地位。無論群組深度或基準測試類型為何,50%–85% 的區塊處理時間都用於從磁碟讀取狀態。 state_read_ms 包括統一 trie 樹中的帳戶和代碼查找,
state_read_ms不僅僅是儲存槽讀取。
模式 2:隨機存取的成本約為順序存取的 40 倍。 Keccak哈希密鑰(ERC20)的成本為 0.4–1.0 毫秒/槽,而順序存取(綜合測試)的成本為 0.02 毫秒/槽。這種差距是由 Pebble 區塊快取未命中 Keccak 分散金鑰造成的。
獨立的 NVMe 頁面讀取基準測試證實,隨機 I/O 與順序 I/O 幾乎可以解釋所有這些效能損失(詳情請參閱第 7 節硬體上下文)。
模式 3:快取命中率穩定在 37%–39% 左右。儘管群組深度增加,但對於 keccak 哈希工作負載,儲存快取命中率從未超過 39%。 256 位元鍵空間過於稀疏,除了共享的上層 trie 節點之外,無法實現有意義的快取重用。
模式 4:Trie 更新對於讀取操作來說可以忽略不計,而對於寫入操作來說則佔主導地位。 balanceOf (純讀取):trie 更新時間< 1.3 毫秒。 approve(讀取 + 寫入):trie 更新時間最高可達 691 毫秒(GD-1)。這種不對稱性意味著節點寬度權衡僅在寫入工作負載下才重要。
模式 5:Mgas/s 的運行間變異係數大多小於10 %。第三階段驗證的冷緩存投放(120 多次成功,0 次失敗)在所有八種配置下均產生了可複現的結果。與前幾個階段相比的改進驗證了冷緩存方法的有效性。
未解決的問題
Pebble 資料塊大小交互作用。所有測試均使用 4KB 資料塊。 NVMe 頁面讀取基準測試表明,隨機 16KB 讀取的吞吐量是 4KB 讀取的 2.3 倍(174 MB/s 對比 77 MB/s),而延遲僅為 1.8 倍(89.7 µs 對比 50.6 µs)。更大的 Pebble 資料塊可以顯著提升序列化節點超過 4KB 的更寬分組深度。
並發塊處理。這些基準測試會依序處理資料塊。並行執行引擎可以將 trie 樹更新分攤到各個核心上,從而降低更深組深度所帶來的每個節點重新哈希的開銷。 NVMe 佇列深度基準測試表明,QD=8 比 QD=1 的隨機 4KB 吞吐量提高了 8.7 倍(673 MB/s 對比 77 MB/s)。如果並行執行增加了有效 I/O 佇列深度,則不同組深度之間的讀取延遲差異可能會顯著縮小。
基準測試在以太坊執行規範框架上運行。方法論、原始資料和可複現腳本可在執行規範儲存庫中找到。