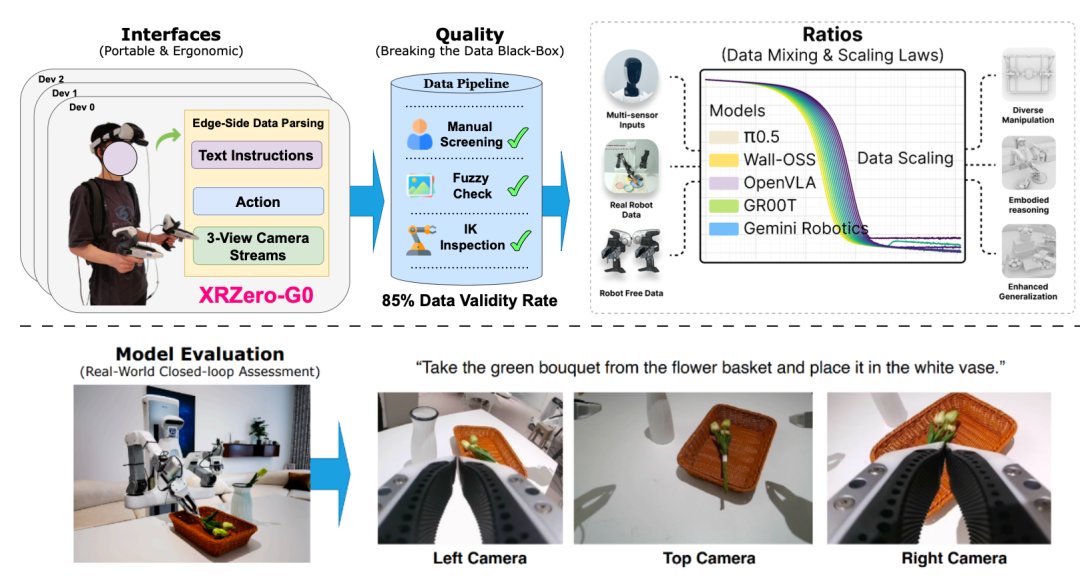
自變量機器人開源國內首個具身數採黑箱系統XRZero-G0。該項目整合無本體數據採集、質檢、訓練及真機評測的完整鏈路,配套2000多小時、覆蓋3000個任務的多模態數據集。核心方案為操作員佩戴VR設備和多個相機進行動作捕捉,現場無需機器人。系統通過三道安檢——三攝像頭視角、虛擬限位器IK驗證、真機回放——確保數據質量,數據有效率超85%。實驗顯示,採用10:1無本體與真機數據配比訓練,效果與500條純真機數據相當,採集成本降至原有二十分之一。該系統還支持零樣本跨本體遷移,解決機器人部署的本體差異問題。
文章作者、來源:雷峰網
最近具身行業被一個開源項目刷屏了。
最早只是小圈子裡傳“有人在社區開源了一整套具身數據集”。我抱著“看看熱鬧”的心態去看了看,越看越不對勁,這不是簡單的數據集,這是一整個無本體數採系統啊。
換句話說,別人開源的是"一段代碼",而這個開源的是一套全身無本體數採+質檢+訓練+真機評測的完整鏈路,還有2000多小時、覆蓋3000個任務的多模態無本體數據集,都完整打包放出來了。


論文地址:https://arxiv.org/abs/2604.13001
這在國內還是頭一遭,於是我深扒了扒對應的論文:
簡單來說,XRZero-G0 這篇論文做了兩件事,第一是撬開了機器人數採的"黑箱",手把手演示瞭如何超低成本採集一套高質量數據。第二,手把手教你怎麼數據訓練。
先說第一點,數據採集。之前大家可能聽說過“具身行業採數據又難又貴”,甚至有人拋出暴論,說具身發展慢,都是被數採拖累了。
你看大模型,吃的是文本,互聯網上到處都是。機器人吃的是物理數據,每一條都得真金白銀去採。 而且過去採數據,行業裡有三個大坑,貴、髒、不可複用,這也構成了具身數據層的"不可能三角"。

XRZero-G0論文裡,給了一個巧妙的解法,核心就一句話:人戴著設備去幹活,現場不需要機器人。
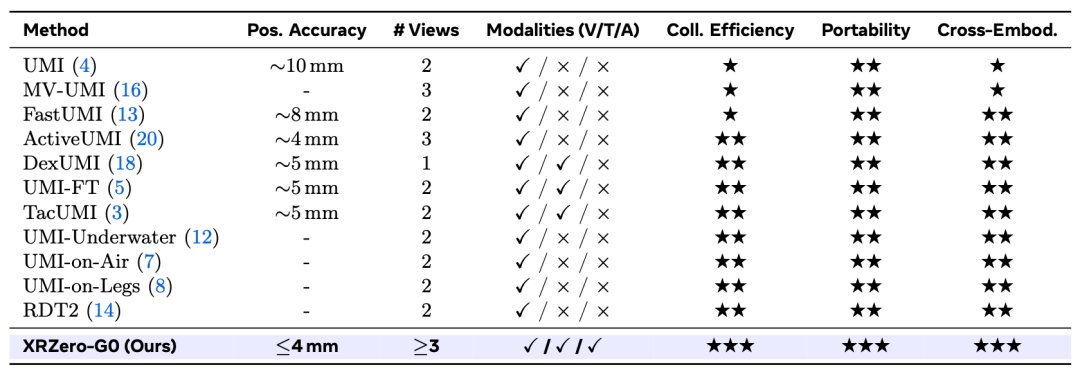
這條路其實有人走過(比如UMI範式),但以前這種方式有個致命的毛病,採回來的數據像個"黑箱",你不知道真機到底能不能跑通。而XRZero-G0這次通過三道"安檢",把黑箱變成了透明的白盒。
第一道安檢:三個攝像頭。
過去數採手持設備只有單視角或雙視角,這種有個缺點,雙手一交叉,或者物體被手臂擋住,數據當場報廢。XRZero-G0 的做法很直接:給操作員戴上PICO VR 頭顯,頭頂一個全局相機,左右手腕各掛一個相機。
這三路視角加上六自由度位姿信息,加上揹包邊緣計算做時空對齊,精度直接≤4 毫米,不管你怎麼轉身、俯身、走動,遮擋和漂移問題都不會發生。
第二道安檢:裝一個虛擬限位器。
大家知道人的關節靈活,能做瑜伽,但機器人不行。之前遙操作的時候,我做了一個機器人做不出的動作,結果電機燒了。XRZero-G0 很聰明,引入自動逆運動學(IK)驗證,過濾掉超出關節極限的動作。
第三道安檢:真機回放。
前兩道篩完,系統還會隨機抽一部分數據,直接丟給真實的雙臂機器人做"開環回放"。只有機器人順利把任務做完,這批數據才算入庫。
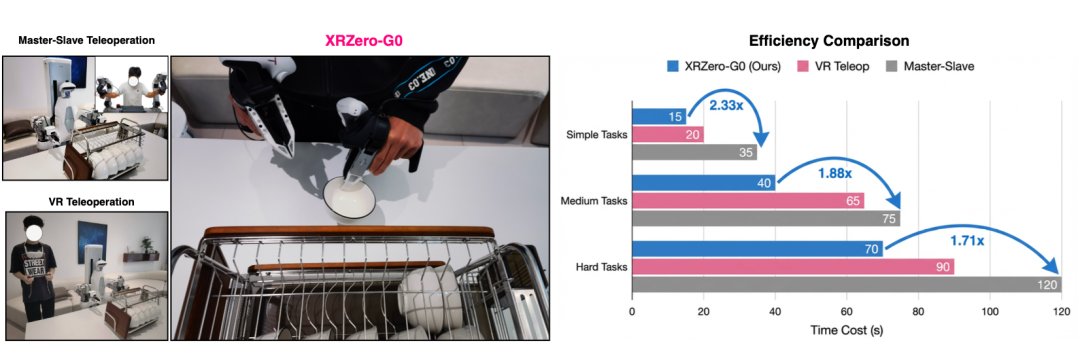
三層漏斗篩下來,入庫數據的有效率被拉昇到了 85% 以上,可用性跟真機數據一樣,採集速度還更快。
看論文裡數據,簡單任務從 35 秒壓縮到 15 秒,提速 2.33 倍;複雜任務也能快 1.71 倍。峰值採集速度達到 93.2 條軌跡每小時。這不比真機香?
但以上只是教會了"怎麼更好的採集數據",XRZero-G0 論文裡更關鍵的是教大家"怎麼訓"數據。
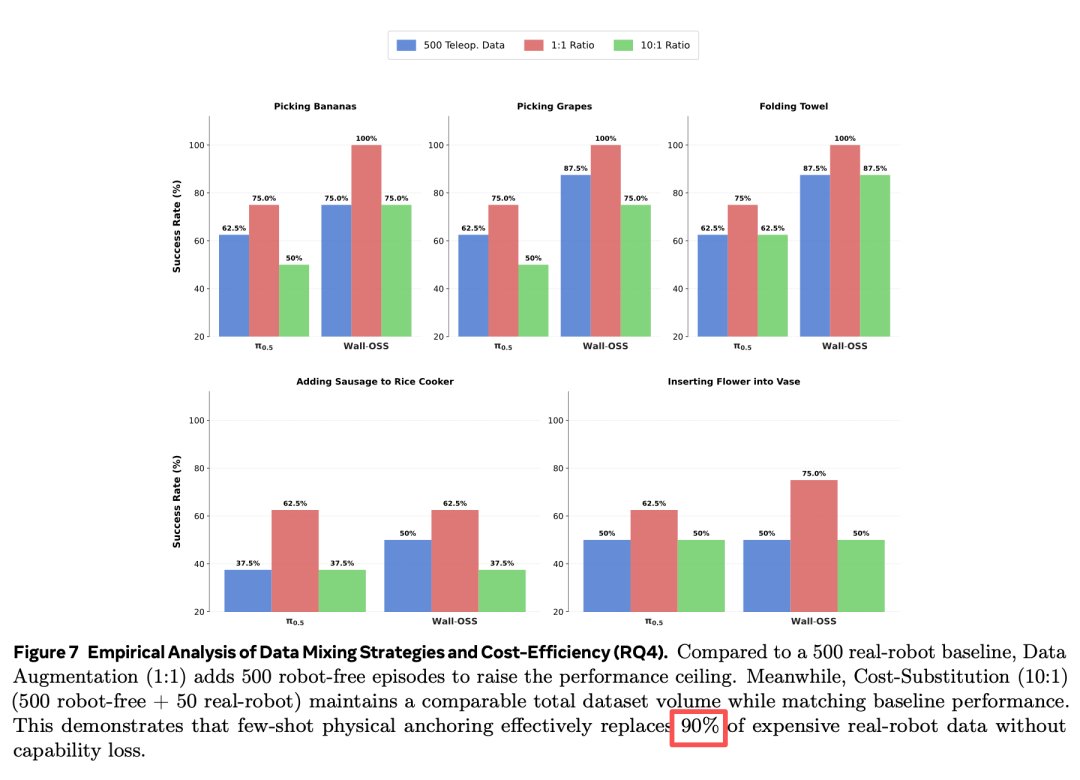
具身訓練裡,大家都知道要把"便宜無本體數據"和"昂貴真機數據"混在一起用,但比例怎麼配?以前全靠煉丹。
XRZero-G0 團隊做了一件特別紮實的事,系統性窮舉實驗,最終發現了一個"黃金比例"。
在這之前,他們對比了三套方案:
▪ 500 條純真機數據(基線)
▪ 500 條真機+500 條無本體(1:1)
▪ 50 條真機+500 條無本體(10:1)
結果出乎意料:10:1 的方案,成功率跟 500 條純真機基線持平,甚至更高。 說人話就是:你把真機數據用量砍掉 90%,總成本壓到傳統方式的二十分之一,訓出來的模型一樣聰明。20 倍的成本效率躍升。
論文解釋了這背後的原因,叫"少樣本物理錨定效應"。
還沒完,這套數據訓出來的模型,還能做到"零樣本"跨本體遷移。
前面說了,傳統真機遙操作,最怕本體遷移。桌子高了十公分,或者換一臺機器人,直接崩。但 XRZero-G0 是揹包式的,操作員走來走去,採集過程中視角、高度、光照天然充滿了動態變化。這種豐富的"噪聲",反而讓模型練就了極強的魯棒性。
論文展示了非常震撼的細節:把這套混合數據訓出來的模型,扔到 EX001 和 CX001 上,沒有見過真機數據,直接部署, 結果插花、疊毛巾、裝香腸都沒問題。

簡單聊聊XRZero-G0 讀後感,這篇論文核心就是把"怎麼低成本採數據"和"怎麼高效用數據"兩件事,像說明書一樣,掰開揉碎了給從業者看。
大家都能感知到,具身行業正從"拼Demo"轉向"拼數據"。但該如何堆時長,行業是缺乏共識和方向的。XRZero-G0把"更方便地採數據"、"找到完美的數據配比",進而到最終實現"零樣本跨本體遷移"這一整條鏈路,都教給行業了。
這種工程化的工作,不是某一個高校實驗室或者明星學者能單槍匹馬完成的,它必須是一支既懂學術又懂產業的產業界團隊。
XRZero-G0 背後的公司,是自變量機器人(X-Square Robot)。
要理解自變量為啥能做XRZero-G0,看他們的路徑選擇就知道,公司從Day One就選端到端大模型,同時探索VLA、WM、WUM三條路線。圈內人都懂,這種路線沒有紮實Infra能力根本跑不通,所以早期的從WALL-OSS,到XRZero-G0,自變量一直在建和Infra有關的基礎設施。
這條路雖然難,但是正確。看資本就知道了,自變量不到兩年9輪融資,估值過百億,字節、美團、阿里、小米四家大廠都在股東名單。
至於XRZero-G0全量開源的原因,更簡單粗暴了。
具身的"ChatGPT時刻"不可能靠一家公司憋出來。當高校、中小團隊、個人開發者都能用XRZero-G0這套標準化工具鏈批量產數據時,全行業的數據飛輪才真正開始轉動,那時候自變量的護城河,就建起來了。
文末附上 XRZero-G0 的GitHub主頁,建議大家去玩玩看:
https://github.com/X-Square-Robot/XRZero-G0