

By Lawrence Lee
1. Introduction
Hyperliquid can be said to be the biggest highlight of the recent crypto market besides AI and Meme. Its strategy of not accepting VC investment, distributing 70% of tokens to the community and returning all income to platform users has attracted market attention. Its strategy of directly repurchasing HYPE with its income has made HYPE's circulating market value quickly surpass UNI and rank among the top 25 cryptocurrencies. It has also caused its platform business data to soar across the board.
This article aims to describe the current status of Hyperliquid’s development, analyze its economic model, and analyze the current valuation of HYPE, in order to give an answer to the question “Is HYPE expensive?”
This article is the author's interim thinking as of the time of publication. It may change in the future, and the views are highly subjective. There may also be errors in facts, data, and reasoning logic. Criticism and further discussion from colleagues and readers are welcome, but this article does not constitute any investment advice.
A considerable part of the content in this article refers to the Hyperliquid research report released by ASXN in September. This is also the most comprehensive and in-depth Hyperliquid research report I have ever read. If readers want to know more about the details of Hyperliquid's mechanism, they can refer to this research report.
The following is the main text.
2. Hyperliquid’s business overview
Hyperliquid's current business mainly consists of two parts: derivatives exchange and spot exchange. They also plan to launch a universal EVM - HyperEVM in the future.
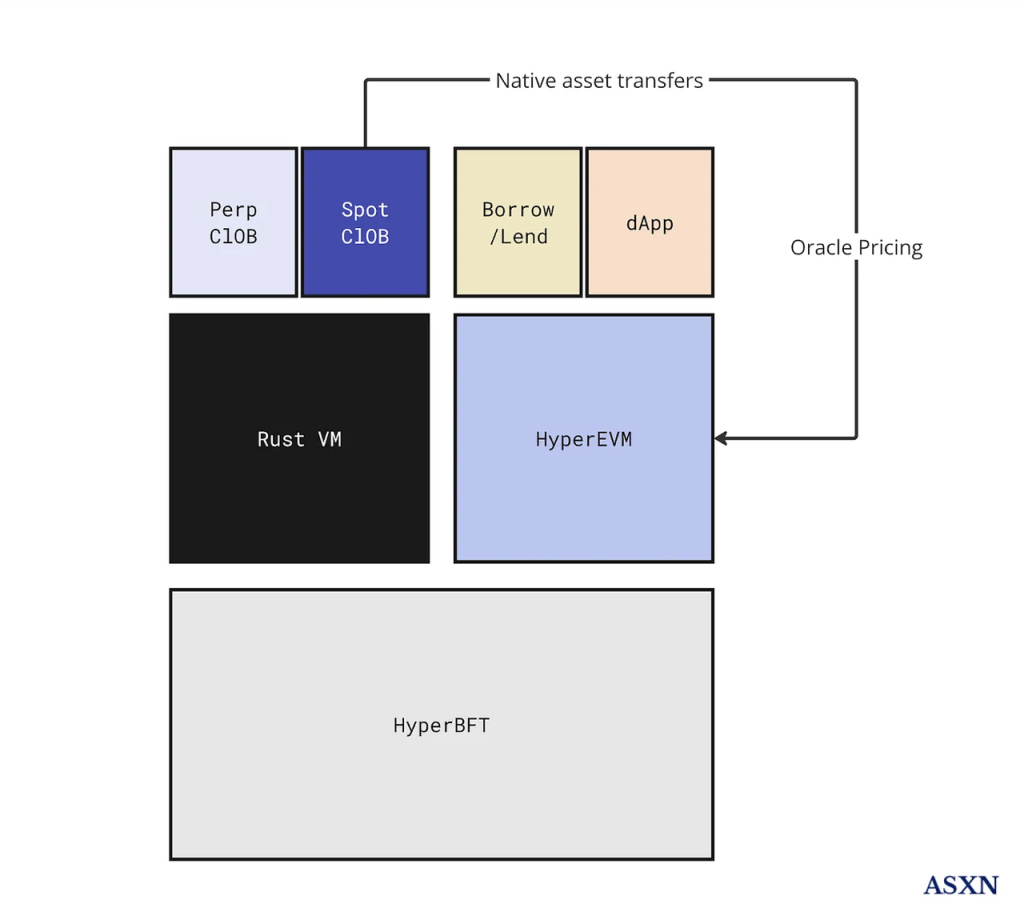
Hyperliquid Architecture Source: ASXN
2.1 Derivatives Exchanges
The derivatives exchange is Hyperliquid's first product to be launched. It is Hyperliquid's flagship product and plays a core role in its entire product ecosystem.
In terms of the core product mechanism of derivatives, Hyperliquid did not adopt other innovative product logics (such as GMX, SNX, etc.) due to the on-chain performance bottleneck. Instead, it still chose the Central Limit Order Book (CLOB), which is the most widely used mechanism by various exchanges around the world and is also the most familiar mechanism to all trading users and market makers, and worked hard on performance.
The decentralized derivatives exchange they built runs on Hyperliquid L1, a PoS chain consisting of HyperBFT as the consensus layer and RustVM as the execution layer.
HyperBFT is a consensus algorithm modified by the Hyperliquid team based on LibraBFT developed by the former Meta blockchain team. It can support up to 2 million TPS. With the powerful performance support of the underlying layer, Hyperliquid has put the core components of derivatives exchanges such as order books and clearing houses on the chain, and finally formed its decentralized derivatives exchange architecture.
For end users, the experience of Hyperliquid is almost identical to that of centralized exchanges such as Binance, not only in terms of trading experience and product structure, but also in terms of transaction fees and discount rules. The only difference from centralized exchanges is that Hyperliquid does not require KYC.
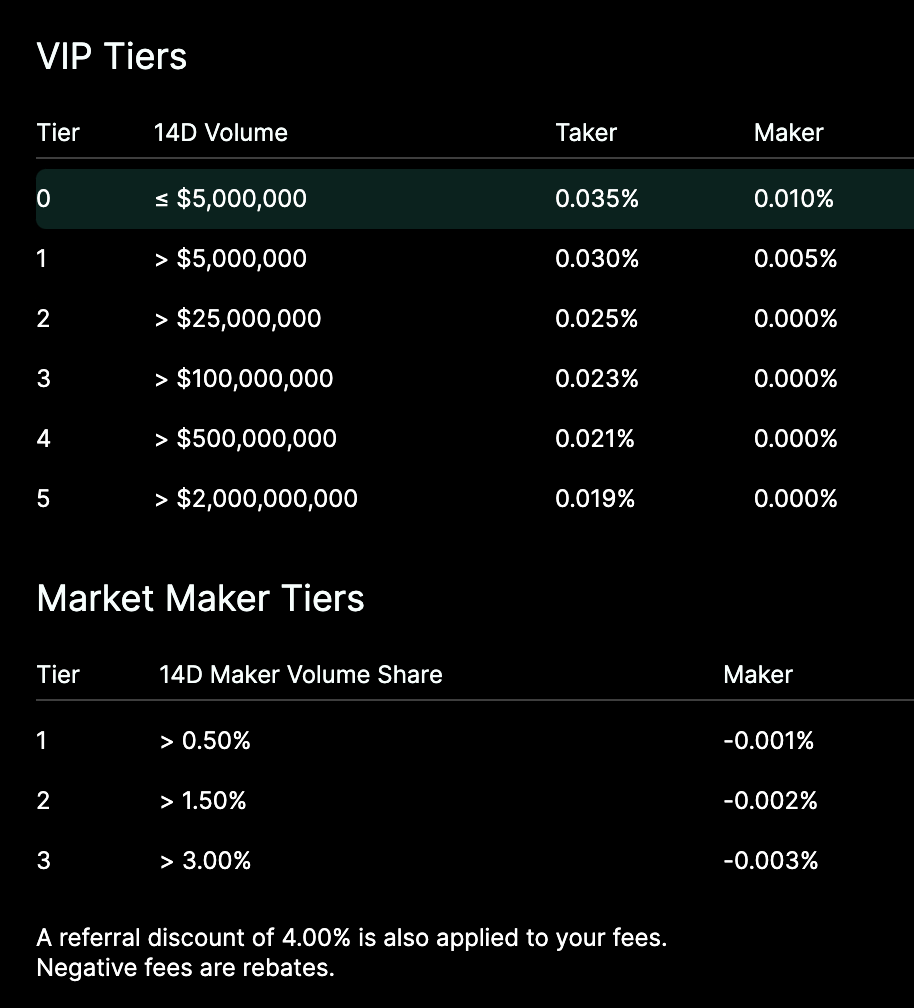
Hyperliquid’s Fee Structure
In addition to trading products, Hyperliquid has provided the Vault function since the beginning of the product. Vault is similar to the "copy order" in centralized exchanges. Everyone can invest funds in any Vault, which will be invested by the Vault manager. 10% of the profits will be allocated to the Vault manager. At the same time, in order to maintain consistency of interests, the manager needs to ensure that he holds at least 5% of the Vault.
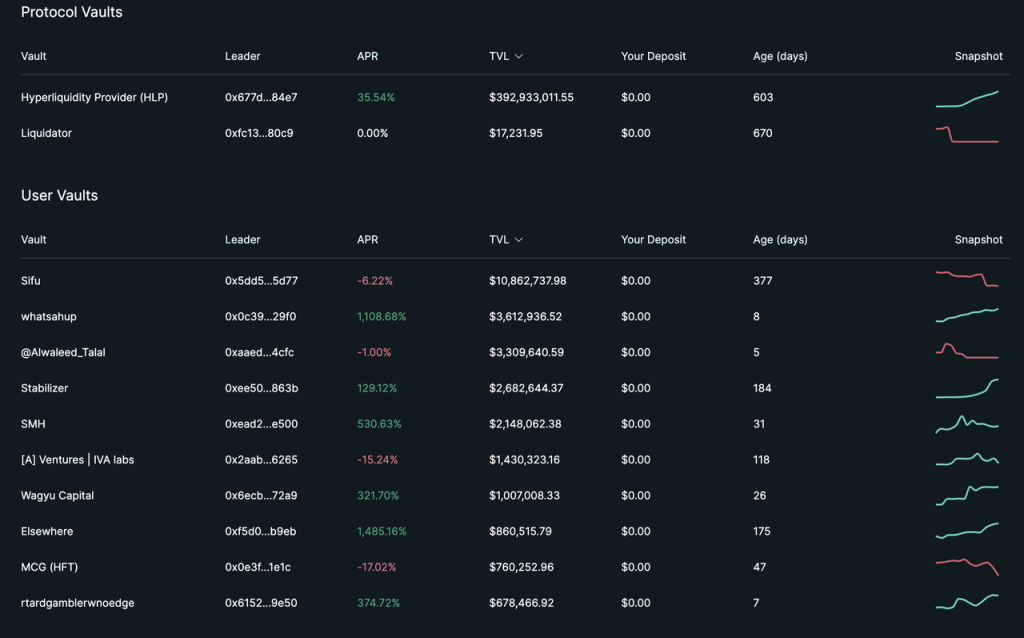
Source: hyperliquid official website
However, judging from the current TVL, 95% of the TVL is in the official Vault HLP.
Unlike general Vaults, HLP is an official Vault and actually acts as the counterparty for many transactions on the platform, so HLP can obtain a portion of the platform's various fees (transaction fees, funding fees, and clearing fees). From this perspective, HLP is relatively similar to GMX's GLP, with the difference being that GLP acts as the counterparty for all transactions on the platform, and its strategy is passive and public, while HLP's strategy is non-public, and the counterparty of a user's transaction may be HLP or other users, and HLP's strategy can be adjusted at any time.
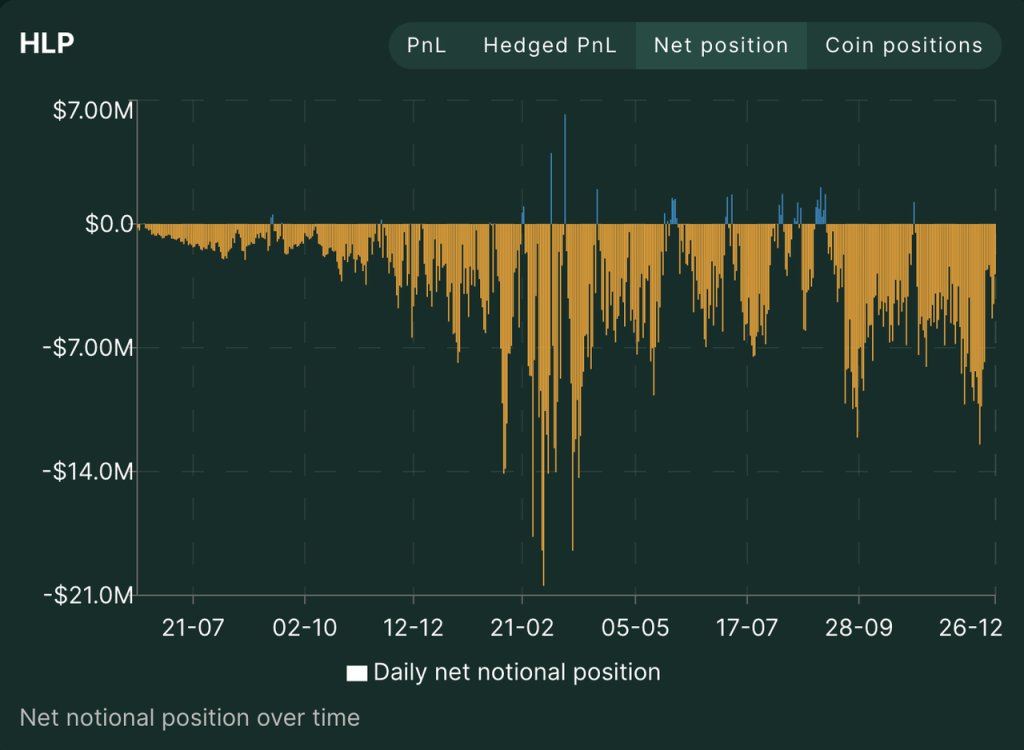
Since its launch in July 2023, HLP has almost always held a net short position, providing liquidity for retail transactions and maintaining profitability with a net short position in the long-term bull market. The current TVL is $350 million and the PNL is $50 million. Judging from the overall PNL curve of HLP and the PNL of the three strategic addresses, the Hyperliquid team is using fees to maintain a relatively positive APR for its HLP.
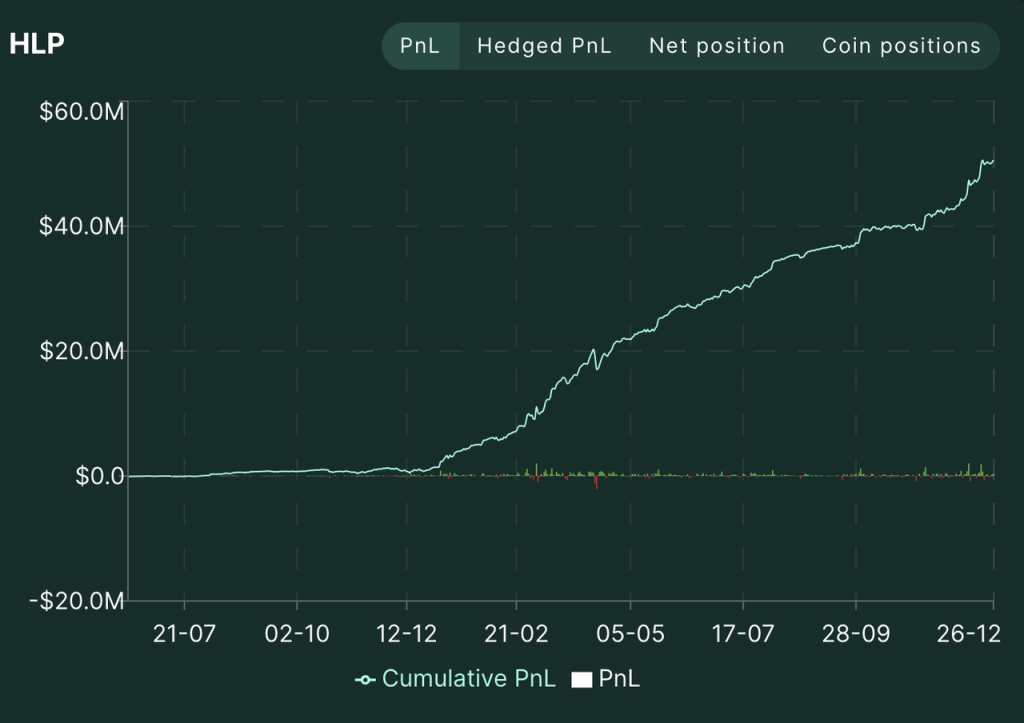
Source: Hyperliquid official website
Hyperliquid has been growing rapidly in terms of trading volume and open interest, especially in the last two months. With the $HYPE airdrop and continued price increases, the platform's data also reached a high point between December 17-20.
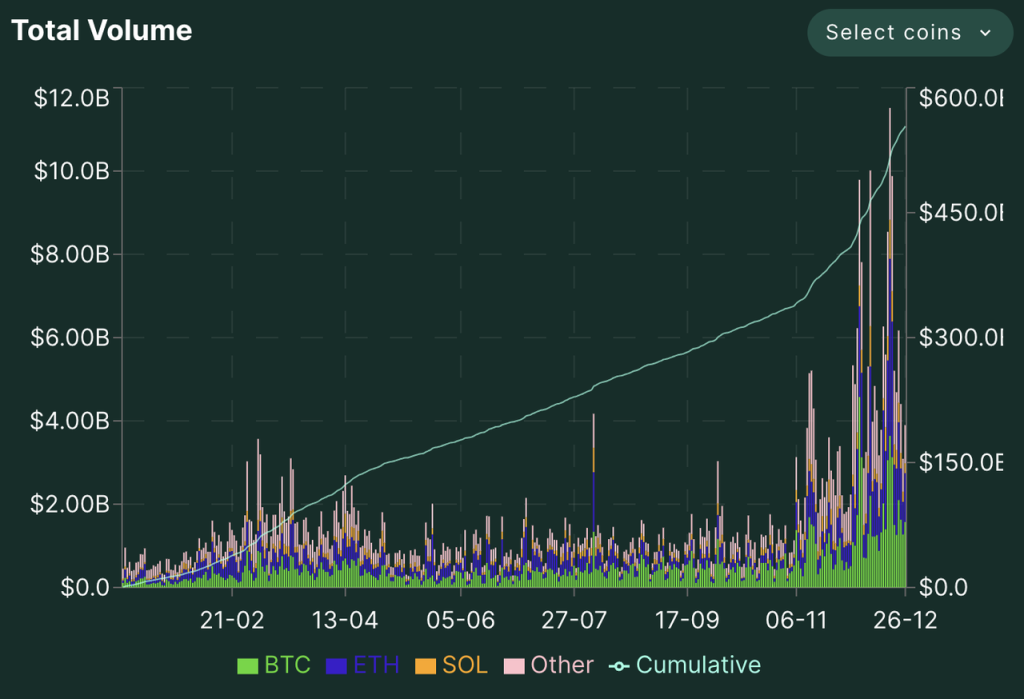
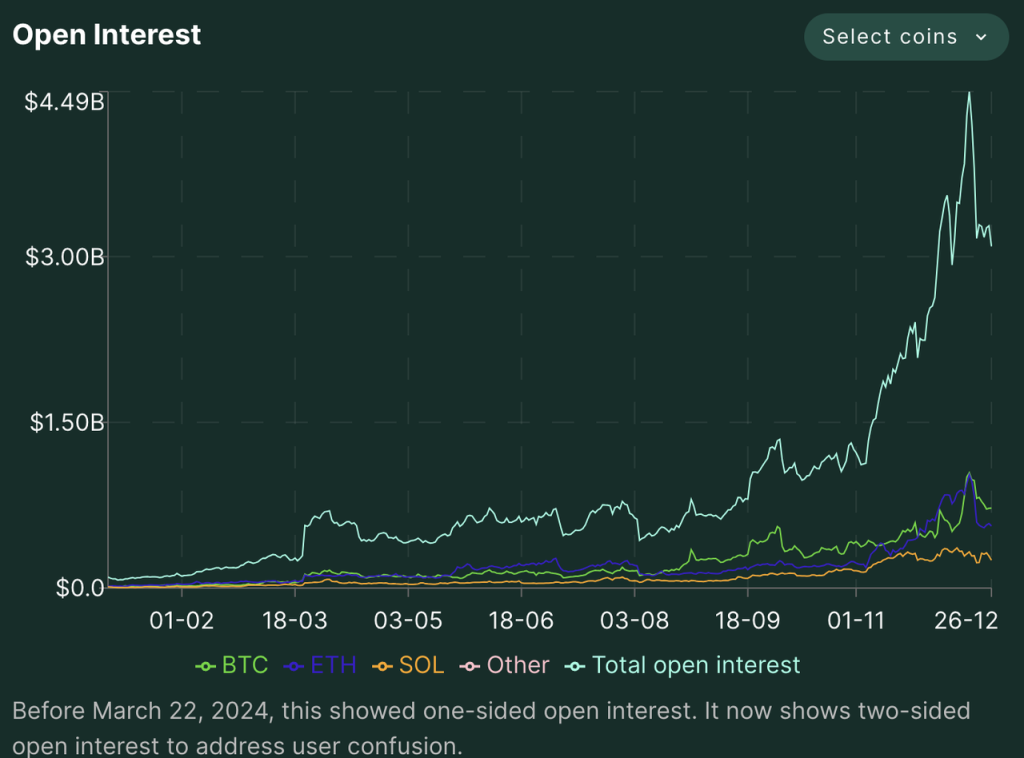
Hyperliuqid's trading volume, holdings, and number of traders since 2024 Source: Hyperliquid official website
In the decentralized derivatives market, in terms of trading volume, Hyperliquid has taken the lead since June this year. In the past two months, the gap between other decentralized derivatives exchanges and Hyperliquid has further widened, and now there is an order of magnitude gap.
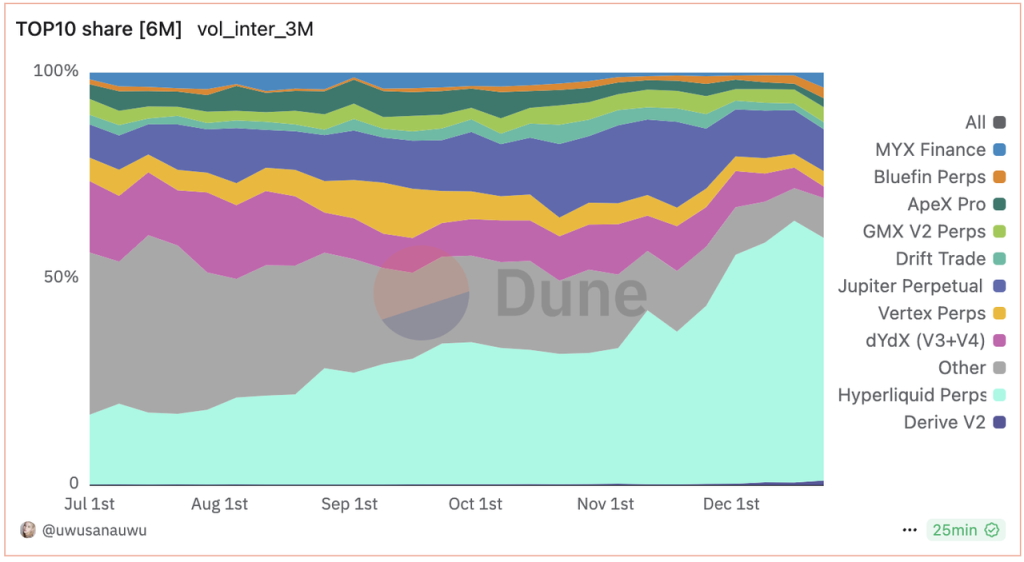
Decentralized derivatives exchange trading volume share Source: Dune
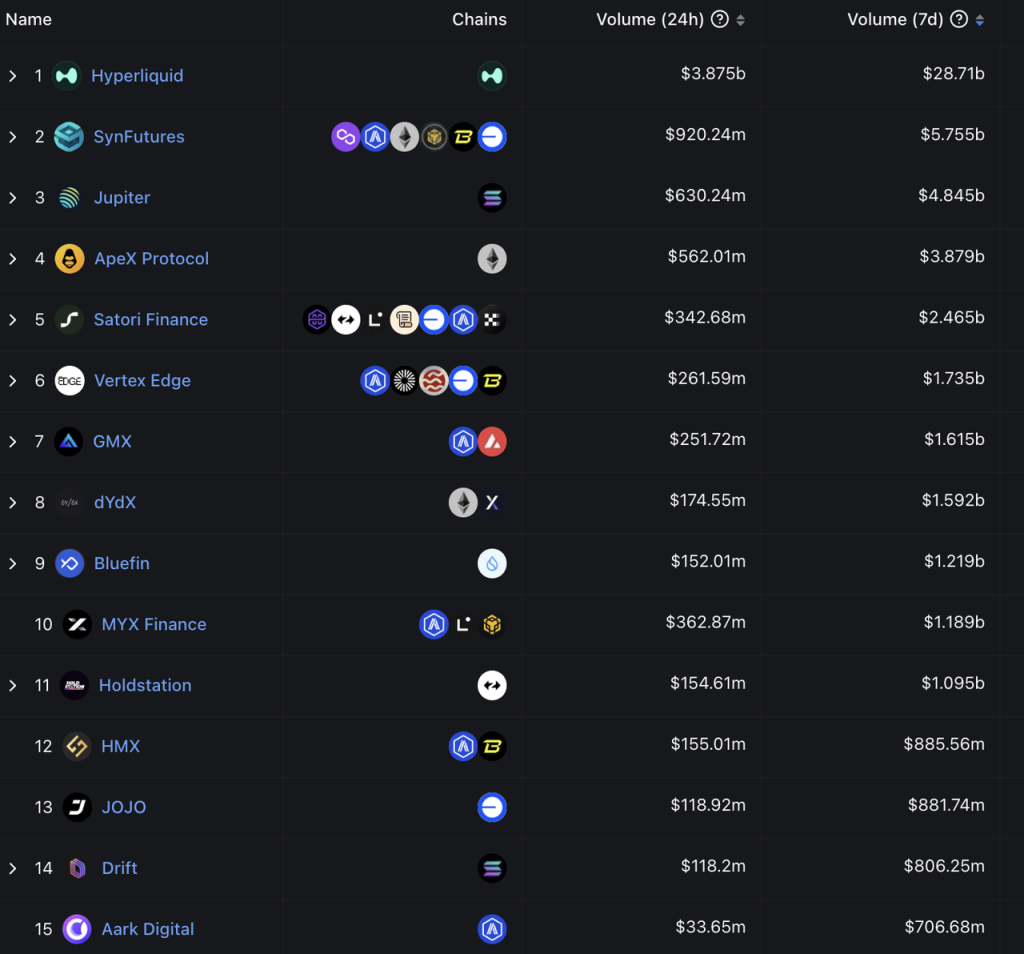
Decentralized derivatives exchanges 7-day trading volume ranking Source: DeFiLlama
Judging from valuation and trading volume, the more appropriate comparable object for Hyperliquid at present is the centralized exchange.
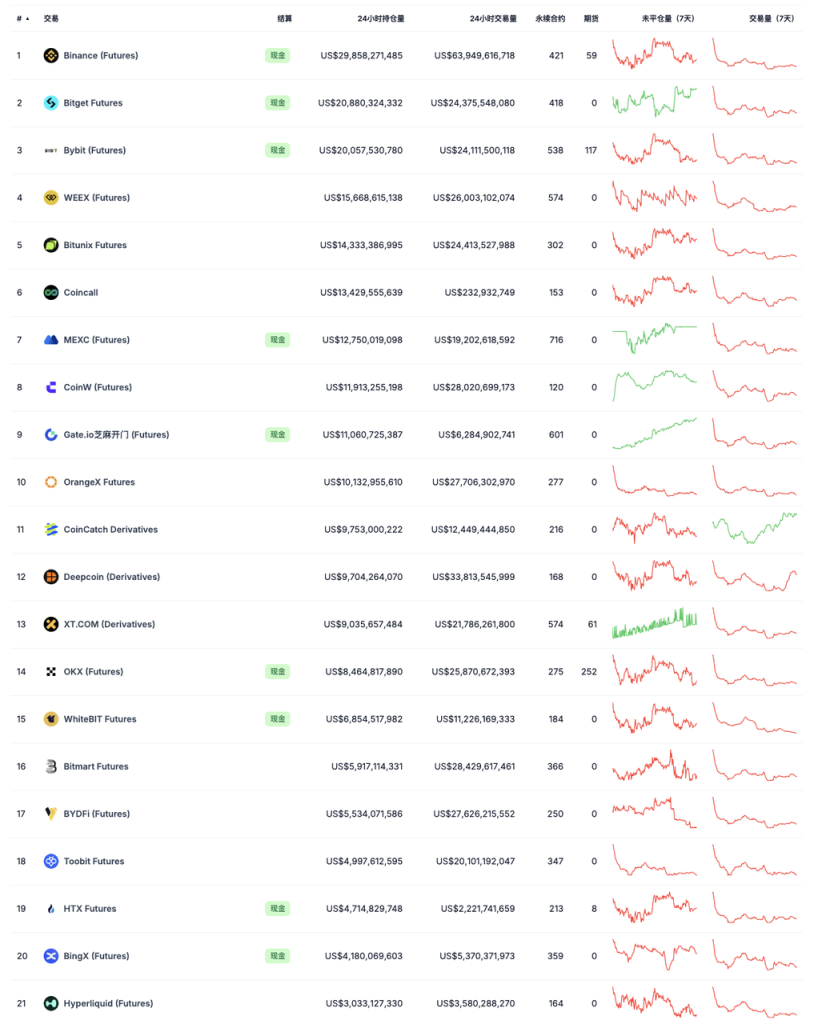
Screenshot time: 2024-12-28 Source: Coingecko
Hyperliquid's recent data has dropped significantly (the highest daily trading volume was 10.4 billion US dollars, and the trading volume in recent days was less than 5 billion US dollars), but its holdings are still 10% of Binance, and its trading volume is 6% of Binance; its holdings and trading volume are also roughly equivalent to 15% of Bitget and Bybit. When it was at its peak (December 17-20), Hyperliquid's holdings reached 12% of Binance, and its trading volume reached 9% of Binance; its holdings and trading volume data were close to 20% of Bybit and Bitget.
Overall, Hyperliquid's derivatives exchange has developed rapidly and has already established a relatively solid leading advantage in the field of decentralized derivatives exchanges. Compared with the leading centralized exchanges, the gap has narrowed to less than 10 times.
2.2 Spot Exchange
Hyperliquid's spot exchange is also in the form of an order book, and is consistent with derivatives exchanges in terms of product structure and fee standards.
Currently, Hyperliquid’s spot exchange only lists Hyperliquid’s native assets that comply with the HIP-1 standard, and does not list tokens from other chains.
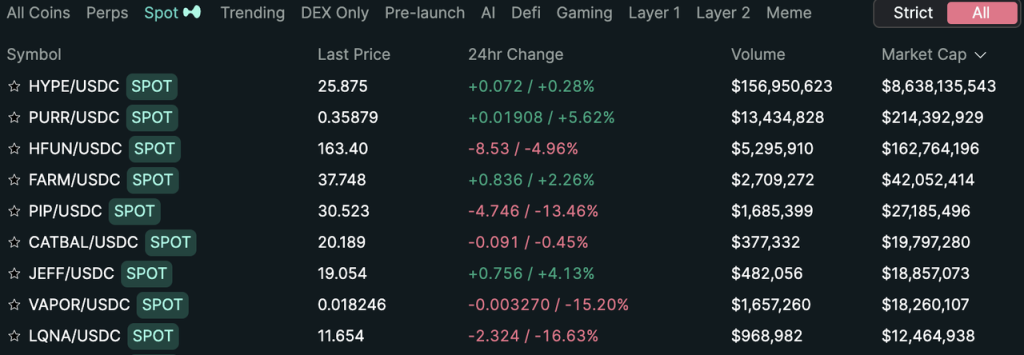
Hyperliquid is currently the top spot token by market capitalization
HIP-1 (decentralized coin listing)
HIP-1 is similar to ERC-20 or SPL-20, and is the token standard of the Hyperliquid network. However, unlike ERC-20 and SPL-20, the cost of creating a HIP-1 token is quite high, because the successful creation of a HIP-1 token also means that it can be listed on Hyperliquid's spot exchange.
Hyperliquid's HIP-1 is conducted in the form of a Dutch auction. Specifically:
Everyone can participate in the auction. The initial price is twice the transaction price of the previous auction and will continue to drop linearly to 10,000U within 31 hours (this value is adjustable, it was lower before, and was recently adjusted to 10,000U). The first developer who successfully bids will be eligible to create a TICKER, which can be listed on Hyperliquid's spot exchange. The auction amount is paid in USDC.
Recent auctions and prices:
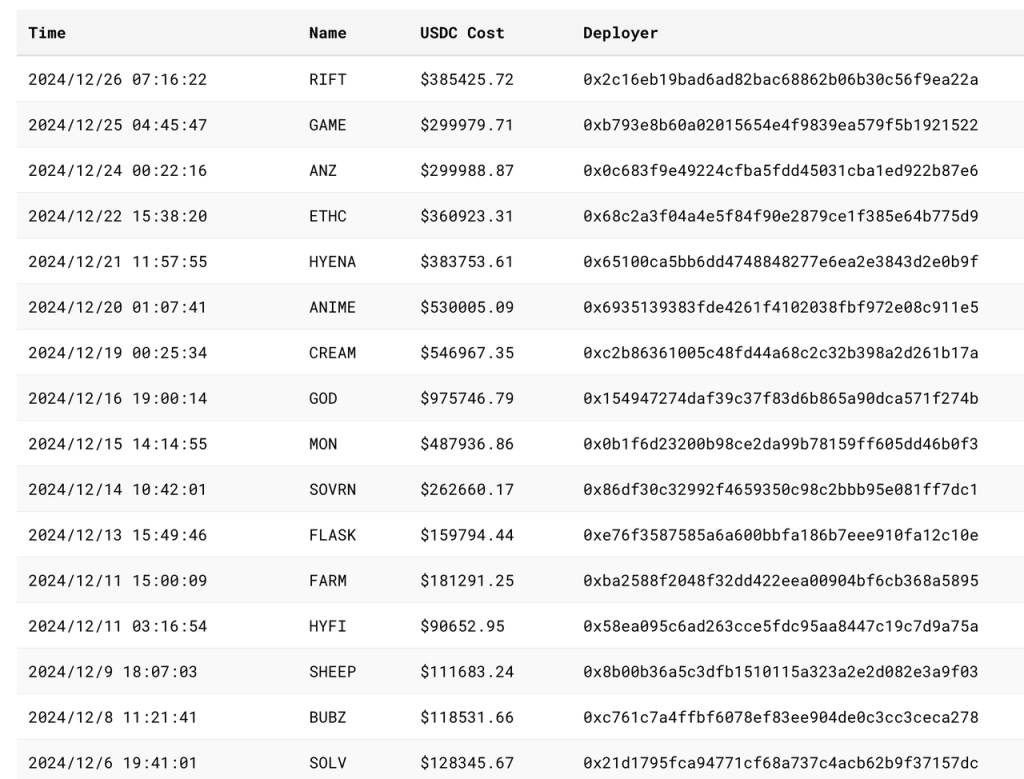
Source: asxn
The created Tickers worth noting are (in descending order of auction amount):
GOD: Pantera's investment game
CREAM: Cream, a long-established lending project that has been plagued by hackers, and a Machibigbrother-related project
ANIME: It is Azuki's token ticker. Rumor has it that it was filmed by the AZUKI team, but it has not been officially confirmed yet.
MON: Game Pixelmoon Publisher
SWELL: Staking & Restaking Protocol for the Ethereum Ecosystem
RIFT: Game protocol based on Virtual J3ff
GAME: Rumor has it that it was filmed based on Virtual's GAME, but it has not been officially confirmed yet
ANZ: Stablecoin protocol for base chain
SOVRN: formerly BreederDAO (a gaming asset platform invested by a16z and Delphi in the previous cycle), will soon release games on Hyperliquid
FARM: Hyperliquid's native AI pet game, launched via Hyperfun platform
ETHC: Machibigbrother associated mining project
SOLV: Bitcoin ecosystem pledge agreement, invested by BN labs, and no tokens have been issued yet.
SOLV can be roughly seen as a dividing point of the HIP-1 auction. Before that, it was mostly meme and domain name logic, tickers were mostly symbolic, and the focus of hype was uniqueness within the ecosystem.
After SOLV, most of the projects came to grab the ecological niche and the qualification to list the token, and the price gradually increased. The highest price of GOD was nearly 1 million US dollars. The project direction is mainly pan-entertainment, with games and NFT accounting for the majority, but there are also DeFi projects such as Solv, Swell and Cream.
In addition, it can be seen that as an exchange, Hyperliquid's spot "listing fee" has remained stable at more than 100,000 US dollars in the past month, which is close to the listing fees of some second-tier centralized exchanges.
Through HIP1, Hyperliquid has an open "decentralized listing" mechanism. The listing fees paid are decided by market participants themselves, and there will be no listing problems on centralized exchanges. On the other hand, the listing fees collected will be used for HYPE repurchase and destruction, which is also beneficial to HYPE's price performance and valuation indicators.
HIP-2 (Hyperliquid’s AMM)
Since Hyperliquid’s spot trading operates in the form of an order book, it is difficult to guarantee liquidity for new coins. Hyperliquid proposed HIP-2 to solve the initial liquidity problem of tokens created through HIP1.
In simple terms, HIP2 provides an automatic market-making system that allows developers to automatically make markets for tokens generated by HIP-1. The market-making logic is linear market-making within a range. Developers specify the upper and lower price limits of the market-making range, as well as the buying and selling points. The system automatically makes markets within the range with every 0.3% price change as one grid.
The following figure shows an order book using HIP-2 and its parameter settings:
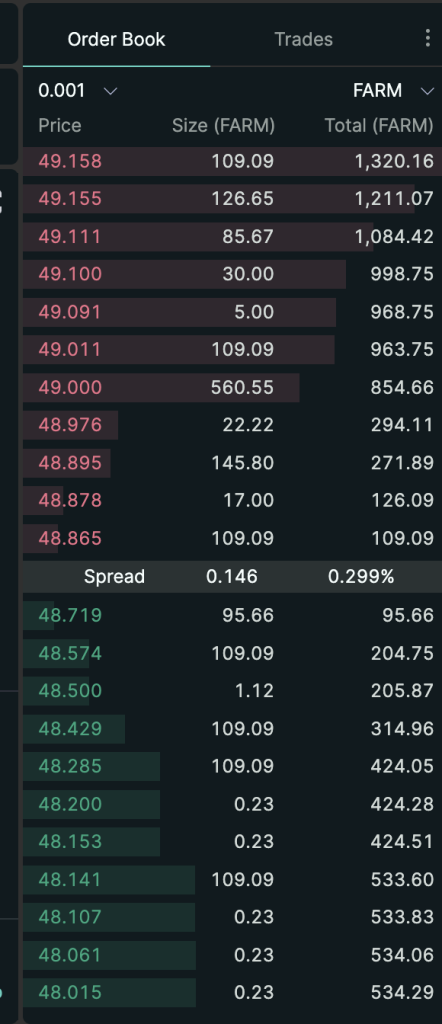
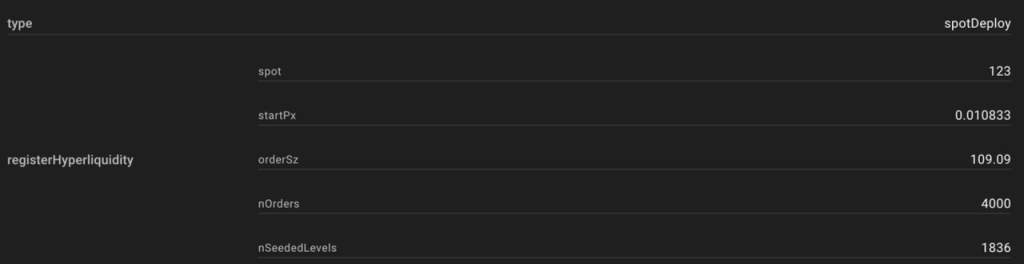
After the launch of HIP-2, many newly created Hyperliquid ecological tokens have chosen to use this Hyperliquid AMM mechanism. Currently, the total USDC volume of HIP-2 has exceeded 25 million US dollars.
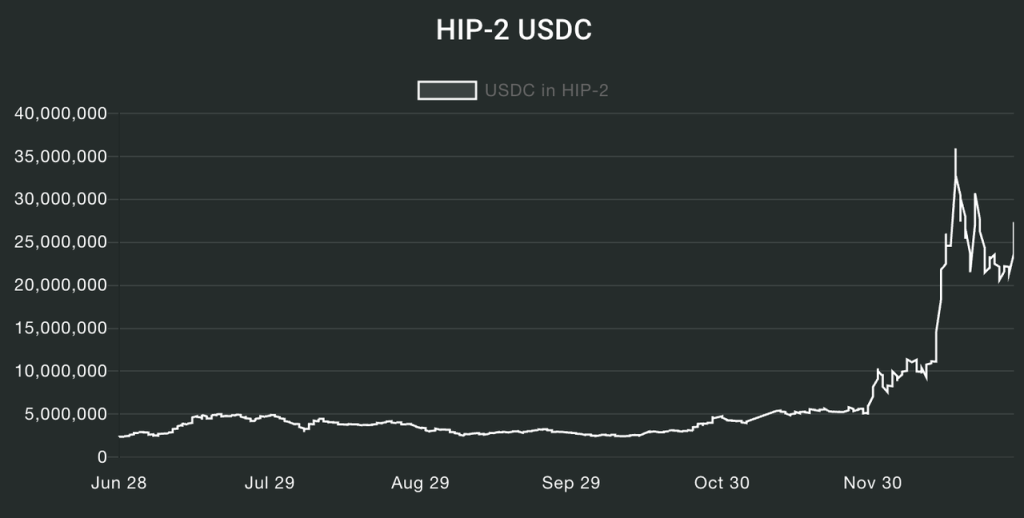
Hyperliquid's average daily spot trading volume in the past 30 days is about 400 million US dollars, ranking among the top ten DEXs, and is similar to the trading volume of Curve, Lifinity and Orca.
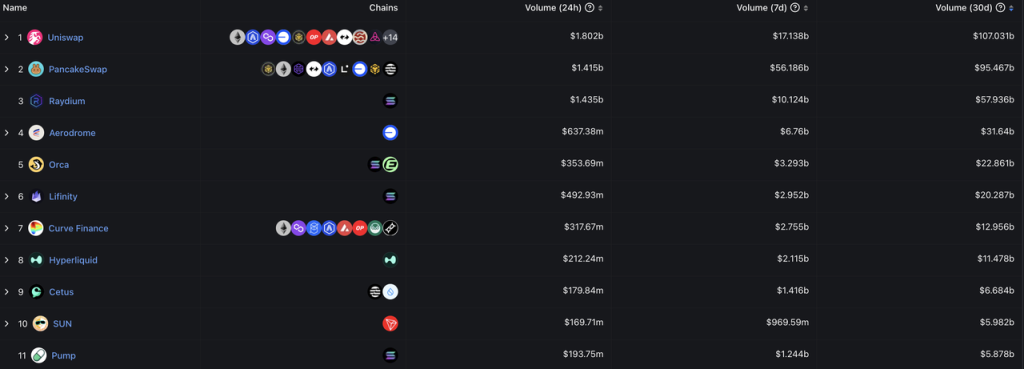
Source: DeFillama
2.3 HyperEVM
HyperEVM is not yet online. In Hyperliquid's official documentation, the RustVM currently running on derivatives and spot exchanges is called Hyperliquid L1, and HyperEVM is called EVM. According to the definition in its official documentation, HyperEVM is not an independent chain:
Hyperliquid L1 has a generalized EVM as part of the blockchain state. Importantly, the HyperEVM is not a separate chain, but is secured by the same HyperBFT consensus mechanism as the rest of L1. This enables the EVM to interact directly with native components of L1, such as spot and perpetual order books.
The ASXN report describes Hyperliquid's architecture with the following diagram:
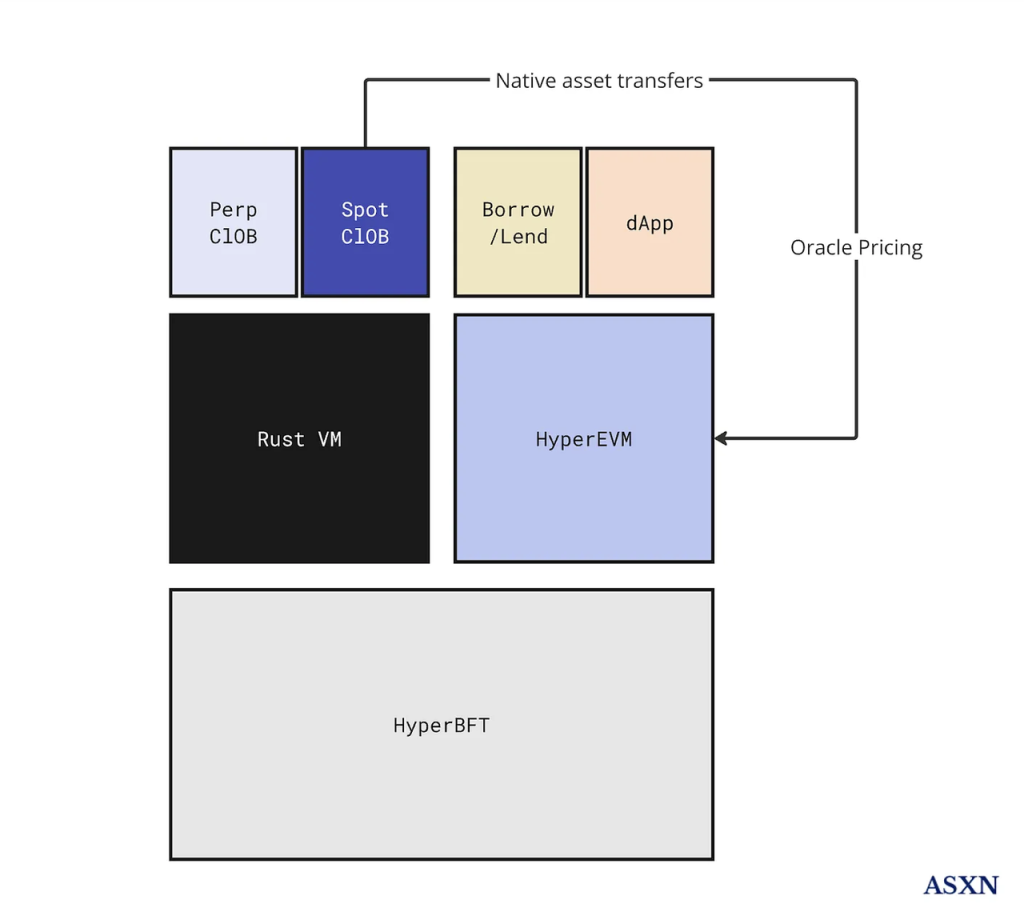
Hyperliquid has two execution layers (RustVM and HyperEVM) on a consensus layer (HyperBFT). Its core functions of contracts and spot are carried on RustVM, and RustVM will also focus on these two core dAPPs, while the rest of the dAPPs will be carried on HyperEVM.
As for HyperEVM, according to the team's documentation, we know:
Unlike RustVM, where Hyperliquid's current spot and exchange are located, HyperEVM is permissionless, which means that any developer can develop applications and issue assets (FT or NFT) on it.
HyperEVM and Hyperliquid's L1 are interoperable, such as L1's oracle can be used by HyperEVM, and some currency transfers can also be interoperable between the two VMs. (Not all interoperable, because the assets on L1 are "permitted", only including USDC and assets generated through HIP-1, while HyperEVM has much more assets)
HyperEVM will use Hyperliquid's native token $HYPE as Gas, while Hyperliquid's current L1 does not require users to pay Gas.
I have never seen a similar product architecture in the crypto world before, and we are not sure how to implement a typical case of DeFi composability on the Ethereum network, "deposit ETH into Lido to get stETH, deposit stETH into Aave to borrow USDC, and then use USDC to buy Meme token PEPE" on HyperEVM and Hyperliquid L1 under the current architecture (this may be the standard for defining whether it is one chain or two chains). However, in my current understanding, the relationship between HyperEVM and Hyperliquid L1 may be more similar to the relationship between "L2 and L1 with certain interoperability", or the relationship between centralized exchanges and their exchange EVM chains (such as Binance and BNB Chain or Coinbase and Base Chain)
Currently, the HyperEVM testnet is operating normally, and many validators have begun to participate in the HyperEVM testnet verification. The more famous ones include Chorus One, Figment, B Harvest, Nansen, etc.
HyperEVM test network verification node list source: ASXN
Since RustVM is not open to all developers, there are currently few applications developed based on RustVM based on Hyperliquid, most of which are trading auxiliary tools:
Such as Telegram trading robot Hyperfun (token HFUN), Telegram social trading robot pvp.trade, trading terminals tealstreet and Insilico, and derivatives trading aggregator Ragetrade.
HyperEVM is open to all developers, and there are many projects planned to be released on HyperEVM. In addition to the projects that have successfully obtained HIP-1 tokens mentioned above, the figure below and the Hypurr.co website list a considerable number of them.

We still need to wait for the official launch of HyperEVM to find out the specific mechanism and its relationship with Hyperliquid L1. Currently, the official has not given a planned launch date for HyperEVM.
Summary: Hyperliquid's current overall business positioning is similar to that of the top trading groups. Its core business is trading + L1 operations, and it has become a direct competitor to major trading groups. Although the business model is the same, compared with the existing top trading groups, Hyperliquid is different in that it chooses to build its trading business on the chain. Compared with CEX, which requires permission and has opaque data, the advantages of Hyperliquid's trading platform are permissionless access (no KYC required), transparent and verifiable business data, better composability, and lower overall operating costs, which also enables it to transfer more revenue and profits to its token HYPE.
3. Hyperliquid Team, Token Economics and Valuation
3.1 Team
Hyperliquid has two co-founders, Jeff Yan and iliensinc, who are Harvard alumni. Before entering the crypto industry, Jeff worked at Google and Hudson River Trading. The Hyperliquid team is quite lean. According to the ASXN September report, the team has 10 members, 5 of whom are engineers, which is especially true for a derivatives exchange with a daily trading volume of over 10 billion.
Judging from the entire product process currently built by the Hyperliquid team, especially their insistence on self-funded research and development, self-built high-performance chain to achieve a complete on-chain order book, and the highly innovative HIP-1, although the team is lean, its ability to always solve problems based on first principles is impressive.
3.2 $HYPE Economic Model
The total amount of $HYPE is 1 billion, which will be officially released on November 29, 2024. Since there is no financing, there is no investor share. The specific distribution is as follows:
31.0% Genesis allocation, airdropped to early users of Hyperliquid according to the number of points, fully circulated.
38.888% for future emissions and community rewards
23.8% is allocated to the team and will be released after 1 year of lock-up. Most of it will be released between 2027 and 2028, and some will continue to be released after 2028.
6.0% Hyper Foundation
0.3% community grants
0.012% HIP-2
The team and the community are generally allocated in a ratio of 3:7. The current currency holding addresses are as follows:
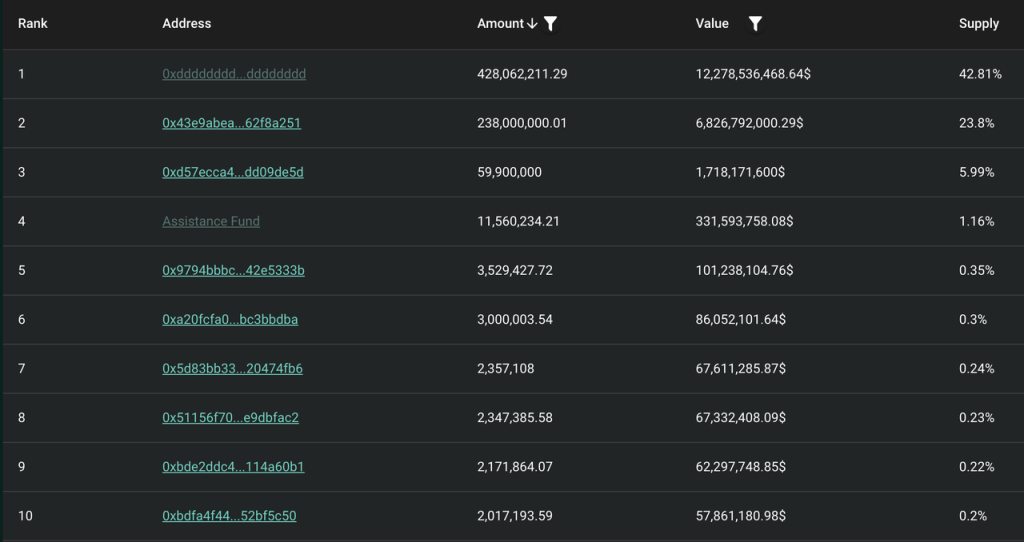
Excluding the community address, team address and foundation address, the address currently holding the most coins is the Assistance Fund (hereinafter referred to as AF), which holds a total of 1.16% of the total HYPE and 3.74% of the circulation.
Currently, there are two parts of the Hyperliquid ecosystem that involve fees: transaction fees and HIP-1 auction fees. Transaction fees include spot and contract transaction fees, contract funding fees, and contract liquidation fees. Since Hyperliquid L1 does not charge users for gas fees and HyperEVM has not yet been launched, Hyperliquid's current revenue does not include transaction gas fees.
According to the team in the documentation:
On most other protocols, the team or insiders are the main beneficiaries of fees. On Hyperliquid, fees are entirely directed to the community (HLP and the assistance fund). For security, the assistance fund holds a majority of its assets in HYPE, which is the most liquid native asset on the Hyperliquid L1.
In most other protocols, the team or insiders are the primary beneficiaries of fees. On Hyperliquid, fees go entirely to the community (HLP and the Assistance Fund). The Assistance Fund holds most of its assets in HYPE, as this is the most liquid native asset on Hyperliquid L.
All the fees belong to HLP and AF. However, the team did not clearly inform the proportion of the fees between HLP and AF.
Fortunately, the data of Hyperliquid L1 is publicly available. According to @stevenyuntcap's speculation logic, as of early December, Hyperliquid has subsidized HLP for a total of 44 million US dollars since its launch, and the initial AF funds used to purchase HYPE are 52 million US dollars. It can be concluded that Hyperliquid's cumulative revenue from its launch to early December is 96 million US dollars, that is, the distribution ratio of the total revenue of the agreement in HLP and AF is 46%:54%. (In addition, we can also use Hyperliquid's cumulative transaction volume of 428 billion US dollars during this period to convert the average contract rate of the Hyperliquid agreement to about 0.0225%).
Since all of AF's USDC has been used to repurchase HPYE, we can simplify it to the following: 46% of Hyperliquid's perpetual contract trading revenue during this period was allocated to the supply side (HLP holders), and 54% was used to repurchase $HYPE tokens.
Of course, in addition to the perpetual contract transaction fees, Hyperliquid will have two other sources of income that will benefit HYPE holders: the auction fees from HIP-1 and the USDC portion of spot transaction fees. Currently, both of these revenues also go to AF to repurchase HYPE (it also includes the HYPE portion of the HYPE-USDC spot transaction fees, which is currently directly destroyed, with a total of 110,000 HYPEs destroyed).
At present, AF's strategy is still to regularly purchase all accumulated USDC for HYPE, so we can simply track Hyperliquid's profits and the repurchase of HYPE based on AF's USDC inflow data. According to data from hyperdata.info, AF's cumulative USDC inflow currently exceeds US$77 million, and more than US$25 million in the past month, with an average daily repurchase of about US$1 million in HYPE.
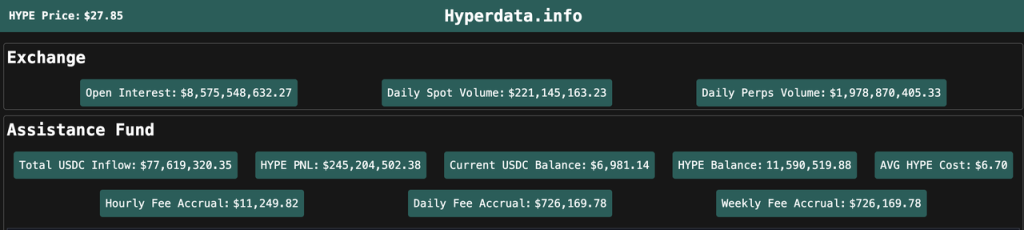
On December 30, 2024, Hyperliquid officially launched the HYPE staking function. The current yield of HYPE staking is about 2.5%. This part of the income only includes the fixed PoS consensus layer income. Its yield consensus refers to the yield consensus of the Ethereum consensus layer (the yield is inversely proportional to the square of the number of staked HYPE). In addition to the 300 million tokens of the team and the foundation, there are also nearly 30 million user tokens involved in the staking.
Looking ahead, there are still many possibilities for adjustments to HYPE's economic model, such as:
HyperEVM is online.
$HYPE is used as gas for HyperEVM
The execution layer income is distributed to HYPE stakers (the current HYPE pledge income only includes)
The handling fee is redistributed to the holders of $HYPE
$HYPE staking fee discount
3.3 Valuation
Below we will explore the following two valuation frameworks for Hyperliquid. Before we begin, it is important to point out that:
Hyperliquid's data has changed greatly - its market value, TVL, revenue, user data, etc. have increased several times or even dozens of times in the past month, and then retreated by 50%. The drastic changes in its own indicators are far greater than the comparison shown by the valuation indicators listed below. The following valuation framework is more suitable for long-term valuation reference.
HYPE price is currently the biggest fundamental of Hyperliquid. The surge in its various data is more the result of rising HYPE prices, rather than "because Hyperliquid has such good data, it has such a price."
Framework 1: Comparison with BNB
The main thesis of Hyperliquid is "Binance on the chain" proposed by messari:
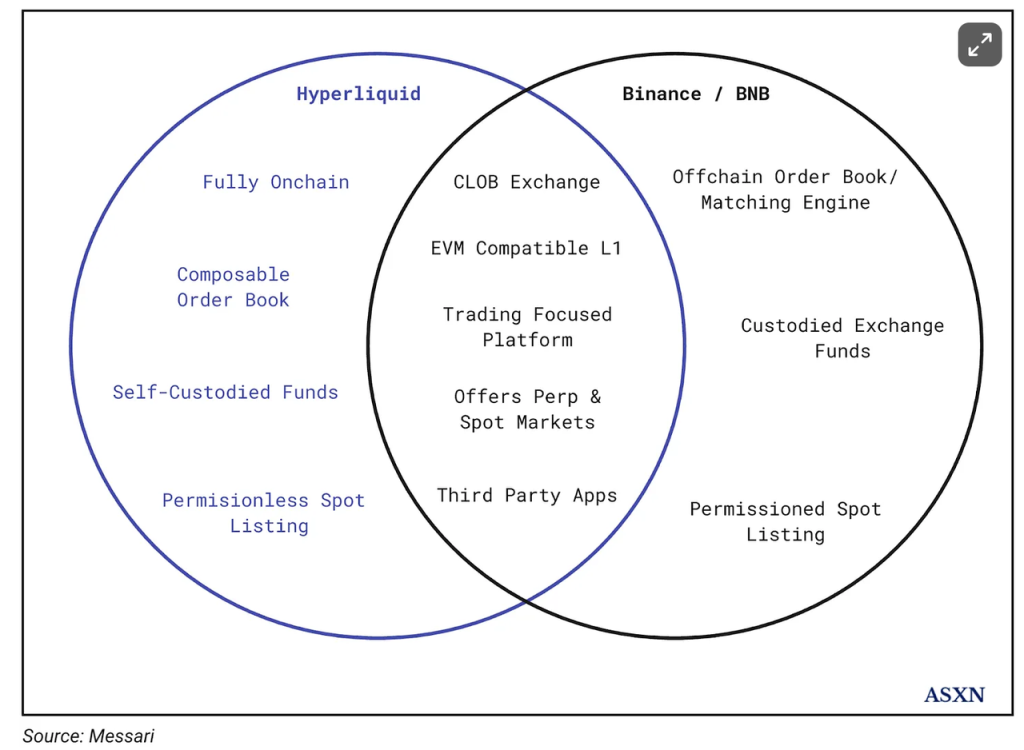
This analogy is generally reasonable and may indeed be a good framework. Binance/BNB may indeed be the most suitable comparison object for Hyperliquid/HYPE.
Hyperliquid’s core business is derivatives and spot exchanges, which is consistent with Binance’s corresponding main business;
HyperEVM can be compared with BNBChain. Although HyperEVM has not yet been launched, according to the current design, both HYPE and BNB can be used as Gas for the EVM chain and can be staked to earn income.
Both HYPE and BNB can directly benefit from platform transaction fees;
Next, we will divide Hyperliquid architecture into derivatives exchanges, spot exchanges, and EVM for comparison with Binance.
Derivatives Exchanges:
As mentioned above, Hyperliquid’s recent holdings and trading volume data are around 10% of Binance’s corresponding data. Therefore, we roughly believe that in the derivatives exchange module, HYPE = 10% BNB.
Spot Exchanges:
Hyperliquid's average daily spot trading volume in the past thirty days is around US$400 million, while Binance's average daily spot trading volume is around US$26 billion after excluding the FDUSD trading pair with no transaction fees. HYPE = 1.5% BNB.
EVM:
According to the above logic, we believe that the relationship between HyperEVM and Hyperliquid L1 is more similar to the relationship between Binance Exchange and BNBChain.
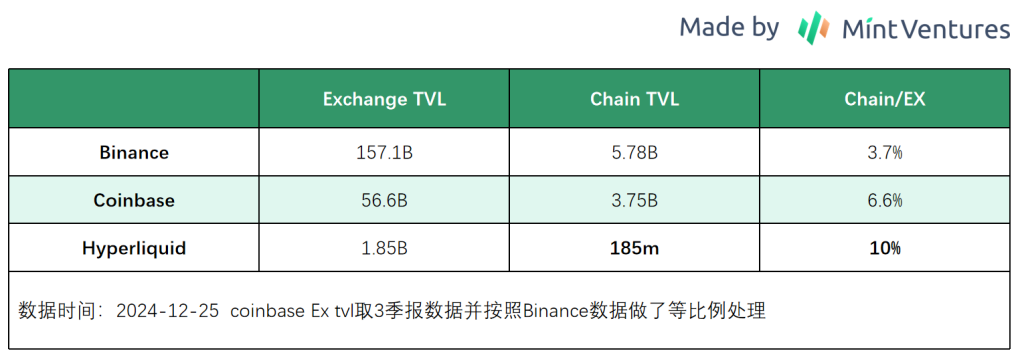
HyperEVM is not online yet, so we cannot confirm how much TVL will be migrated from RustVM to HyperEVM. However, from the perspective of product architecture and corresponding experience, the overall logic is still based on the migration of existing users of the exchange. We list the data of Binance and Coinbase, and considering the market sentiment towards Hyperpe, we assume that 10% of the Exchange TVL will be migrated to the chain (still optimistic, but most of the articles using TVL valuation currently assume that 100% of Hyperliquid TVL will be migrated to HyperEVM). According to this calculation, HYPE = 3%BNB.
Economic Model
In addition, we also need to consider the differences between the economic models of HYPE and BNB.
From the above analysis of the HYPE economic model, it can be seen that HYPE currently converts 54% of the platform's gross profit and 100% of its net profit into repurchase or destruction of HYPE.
Previously, BNB used 20% of Binance Exchange's net profit to repurchase BNB in accordance with the white paper. After the repurchase and destruction were decoupled from the platform's net profit in 2021, we have no way of knowing the proportion of Binance's net profit empowerment for BNB. However, judging from the changing trend of the destruction data and Binance's market position in the same period of time, the proportion of net profit destruction is probably maintained at a similar level.
From the perspective of the economic model (for coin holders), HYPE is significantly better than BNB.
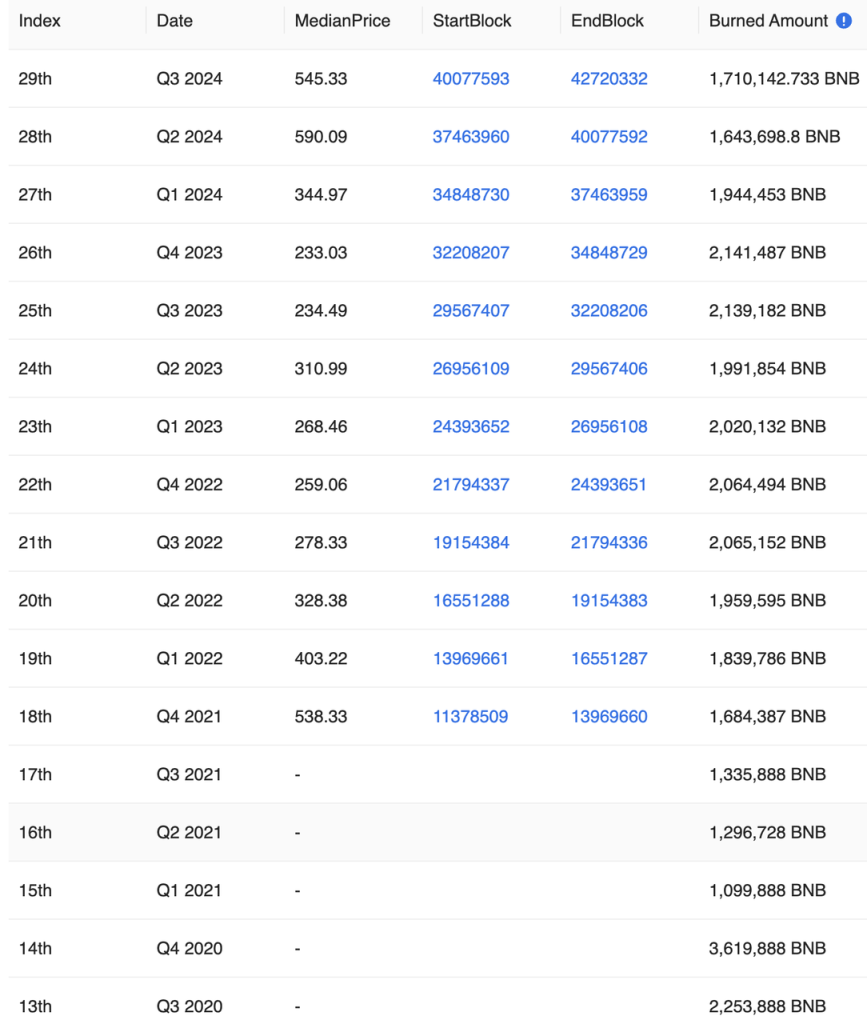
BNB historical destruction data
It is also worth mentioning that the proportion of Hyperliquid's current revenue flowing into HYPE tokens is 54%, and this value still has room to rise further. Due to mechanism reasons, HLP has been holding a large number of cryptocurrency short positions with USDC as collateral in the bull market when BTC has risen by more than 200% since July 2023. Although HLP's own strategy is appropriate and it has rarely maintained a break-even, it still needs to pay an annualized APR of more than 30% to retain funds in HLP.
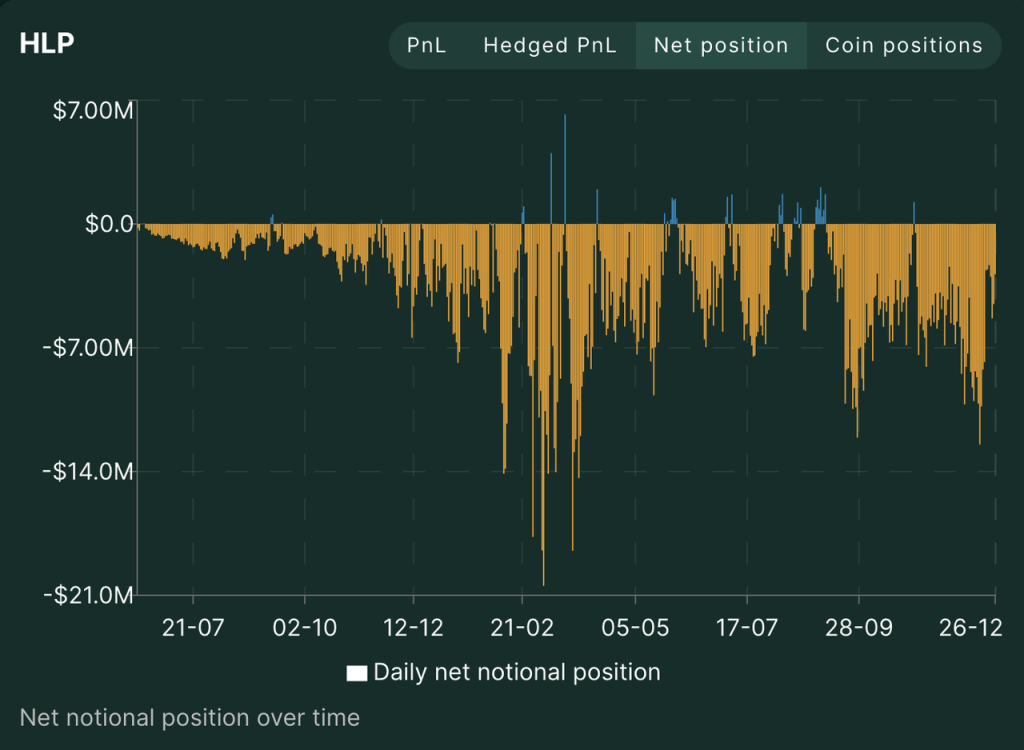
HLP historical net position Source: Hyperliquid official website
In the future, as the market gradually peaks, the overall trend of crypto users as net longs in derivatives will not change, and the probability of HLP's own strategic returns increasing in volatile and bear markets will increase (we can see the same trend from the historical returns of GMX's GLP and GNS's Vault). Hyperliquid may not need to pay such a large proportion of its income as rent to HLP, and Hyperliquid's net profit margin is still expected to increase further.
When it comes to net profit margin, we have no way of knowing what Binance's net profit margin is, but we can get a glimpse of the operating costs of centralized exchanges from the reports of listed company Coinbase.
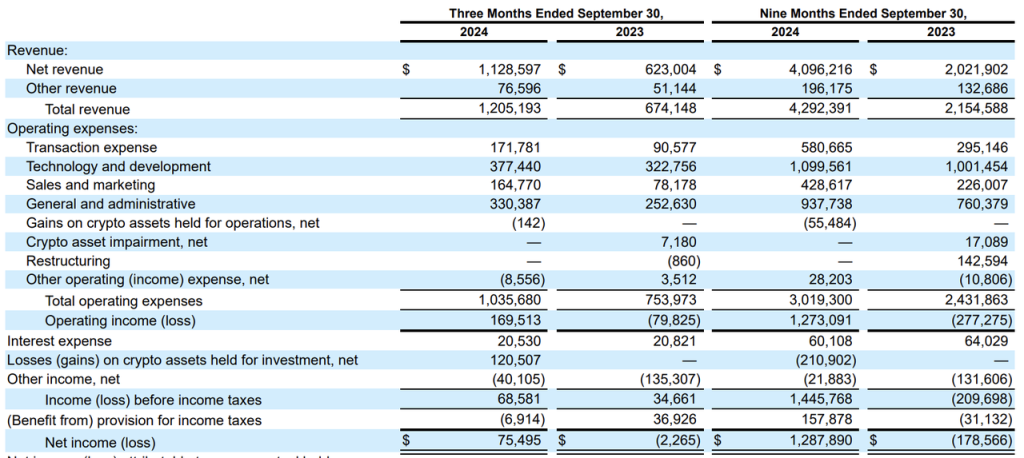
Coinbase quarterly report 24Q3
It can be seen that in 2023, Coinbase's operating expenses (research and development, management, sales expenses and transfer fees) averaged more than 600 million US dollars per quarter, which is basically equivalent to all revenue, and the net profit margin is close to 0; in 2024, with the outbreak of the market, its net profit margin has improved a lot, but the net profit margin is still less than 30%.
From the above numerical comparison, we can clearly see the advantage of Hyperliquid's net profit margin (economic model) over centralized trading. We can also look at this advantage from a specific event: the handling of the coin listing issue.
Centralized exchanges usually have a dedicated listing team to take charge of listing coins. They need to track market hot spots and negotiate with various project teams to collect listing fees and/or project tokens. Centralized exchanges need to pay the listing team a considerable salary and commission, and also need to pay the salary of the internal control team that monitors and handles possible interest transfer issues during the listing process.
As mentioned earlier, Hyperliquid's coin listing process HIP-1 runs automatically based on pre-determined code, and the operating cost of new coin listings is infinitely close to 0, so that its "coin listing fees" can be fully allocated to HYPE holders.
To sum up, at the end of December 2024, we have the following comparison:
Derivatives trading: HYPE = 10% BNB
Spot trading: HYPE = 1.5% BNB
EVM(estimate): HYPE = 3% BNB
Economic model: HYPE is significantly better than BNB
Circulating market value: HYPE = 9% BNB
Total circulating market value: HYPE = 27% BNB
Derivatives trading is Hyperliquid's main business at present, and should have a relatively high weight in valuation comparisons. In my opinion, although HYPE's current market value is not cheap, it is not expensive either.
Frame 2: PS
HYPE has a token repurchase and destruction mechanism, which directly affects the HYPE token. The PS indicator can be used for valuation, as follows:
Contract transaction fees:
We make our estimates based on an average contract transaction fee of 0.0225% and a 46:54 split of profits between HLP and AF.
Hyperliquid's contract revenue in the most recent month = $154.7 billion*0.0225% = $34.8 million, of which about 54% went to AF for repurchase of HYPE, and the amount of HYPE repurchase = $18.79 million, corresponding to an annualized net profit of $225.5 million.
HIP-1 Auction Fee:
The revenue in the most recent month was US$6.1 million. Based on the distribution ratio of HLP and AF46:54, the corresponding annualized net profit was US$39.5 million.
Spot transaction fee:
Hyperliquid's spot trading fee standard is the same as that of contract trading, and the distribution method of the USDC part of the fee is also the same as that of contract trading, that is, the profit is distributed between HLP and AF at a ratio of 46:54; the fees of other tokens in spot trading (such as HYPE-USDC transactions, HYPE buyers pay USDC fees, and HYPE sellers pay HYPE fees) are directly destroyed.
Therefore, we need to calculate the net profit of HYPE from spot transaction fees in two parts:
HYPE part: You can check it directly through the block browser. The TGE of HYPE token is exactly 30 days. The number of HYPE destroyed is 110,490, corresponding to an annualized destruction of 1,325,880, which is about 37 million US dollars at the current price.
USDC part: Hyperliquid's spot trading volume in the last 30 days was US$11.5 billion. The portion of spot trading used to repurchase HYPE = US$11.5 billion*0.0225*54%=US$1.397 million, corresponding to an annualized net profit of US$16.77 million.
Combining the above three parts of expenses, we made an annualized calculation based on the data of the most recent month and found that the amount used to repurchase HYPE was US$318,770,000.
Calculated based on the market capitalization, HYPE's P/S is 29.4, and calculated based on the full market capitalization, HYPE's P/S is 88.
We have listed some crypto projects with comparable circulation P/S indicators to Hyperliquid:
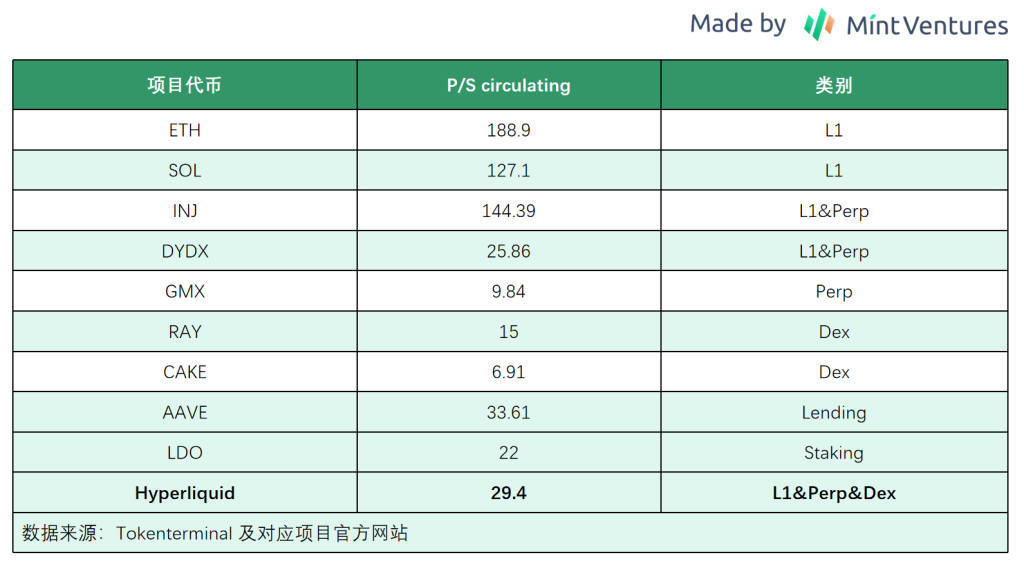
It can be seen that the P/S valuation of L1 is significantly higher than that of applications, and the P/S valuation of Hyperliquid is significantly lower than that of other comparable L1s.
The above are two frameworks for HYPE valuation. It is important to remind you again that:
Hyperliquid's own data changes greatly - its market value, TVL, revenue, user data, etc. have increased several times or even dozens of times in the past month, and then retreated by 50%. The drastic degree of change in its own indicators is far greater than the comparison shown by the valuation indicators listed below. The above valuation framework is more suitable for long-term valuation reference.
HYPE price is currently the biggest fundamental of Hyperliquid. The surge in its various data is more the result of rising HYPE prices, rather than "because Hyperliquid has such good data, it has such a price."
4. Risks
The risks faced by Hyperliquid are as follows:
Financial risk: Currently, all of Hyperliquid’s funds are stored in the bridge of its Arbitrum network. The security of this smart contract and the multi-signature of the 3/4 team that manages all funds are crucial.
Code risks include the current L1 risks and HyperEVM risks. Hyperliquid uses an innovative architecture and consensus. The current closed-source status of its L1 reduces the possibility of being attacked. However, as Hyperliquid grows in size and influence, and HyperEVM goes online, the possibility of potential attacks/code vulnerabilities is gradually increasing.
Oracle risk, which is an inherent risk in all derivatives exchanges.
Regulation leads to loss of comparative advantages. The lack of KYC is currently Hyperliquid’s main comparative advantage over centralized exchanges. As Hyperliquid continues to grow in size, there may be regulatory requirements such as anti-money laundering from regulators.





