

Biên soạn bởi: Moonshot
Nguồn: Geek Park
Năm 2025 là năm mà Agent nhấn chân ga.
Từ sự ngạc nhiên do DeepSeek gây ra vào đầu năm cho đến sự xuất hiện liên tiếp của GPT-4o và Claude 3.5, ranh giới của các mô hình lớn đã được viết lại nhiều lần. Tuy nhiên, điều thực sự khiến Chuỗi ngành công nghiệp AI lo lắng không phải là hiệu suất lặp lại của mô hình, mà là sự xuất hiện của Agent.
Sự phổ biến của các sản phẩm như Manus và Devin khẳng định lại một sự đồng thuận: các mô hình lớn sẽ không còn chỉ là công cụ nữa mà sẽ trở thành các thực thể thông minh có khả năng tự lên lịch.
Do đó, Agent đã trở thành chủ đề nóng thứ hai mà cộng đồng công nghệ toàn cầu đạt được sự đồng thuận nhanh nhất sau các mô hình lớn.
Từ việc tái thiết chiến lược của những gã khổng lồ cho đến việc theo dõi nhanh chóng con đường khởi nghiệp, Agent đang trở thành hướng đi tiếp theo để mọi người đặt cược. Tuy nhiên, trong khi các sản phẩm C-end đang nổi lên mạnh mẽ và các nhà phát triển rất hào hứng với chúng, thì các dự án thực sự chạy qua vòng khép kín giá trị người dùng lại rất hiếm, và ngày càng có nhiều sản phẩm bị mắc kẹt trong nỗi lo "sử dụng nhu cầu cũ để phù hợp với công nghệ mới".
Sau đợt nắng nóng, thị trường đã trở lại bình tĩnh: Agent là sự tái thiết mô hình hay là một bao bì mới? Cái gọi là sự phân chia theo con đường "phổ quát" và "dọc" có thực sự mang lại không gian thị trường bền vững không? Và đằng sau "lối vào mới", liệu đó có phải là sự phát triển của phương pháp tương tác hay sự phản ánh của thế giới cũ?
Sau những câu hỏi này, chúng ta sẽ thấy rằng ngưỡng thực sự của Agent có thể không nằm ở khả năng của mô hình, mà nằm ở cơ sở hạ tầng cơ bản mà nó phụ thuộc vào. Từ hoàn cảnh hoạt động có thể kiểm soát đến hệ thống bộ nhớ, nhận thức ngữ cảnh và gọi công cụ, việc thiếu từng mô-đun cơ bản là trở ngại lớn nhất đối với Agent khi chuyển từ trình diễn sang sử dụng thực tế.
Những vấn đề kỹ thuật cơ bản này chính là rào cản lớn nhất khiến Agent không thể chuyển từ "đồ chơi thời thượng" thành "công cụ năng suất" và cũng chính là đại dương xanh khởi nghiệp chắc chắn và có giá trị cao nhất hiện nay.
Ở giai đoạn cung vượt cầu và cầu chưa rõ ràng, chúng tôi muốn sử dụng cuộc trò chuyện này để trả lời một câu hỏi ngày càng cấp bách: Những vấn đề và cơ hội thực sự cho các Đại lý đang ẩn giấu ở đâu?
Trong cuộc trò chuyện độ sâu lần , chúng tôi đã mời Li Guangmi, người sáng lập Shixiang Technology và Zhong Kaiqi, Trưởng nhóm nghiên cứu AI của Shixiang Technology, cả hai đều ở tuyến đầu. Hai người hành nghề sẽ phân tích các vấn đề thực tế và cơ hội của các tác nhân hiện tại từ nhiều khía cạnh như hình thức sản phẩm, lộ trình kỹ thuật, mô hình kinh doanh, trải nghiệm người dùng và thậm chí là xây dựng Cơ sở hạ tầng.
Chúng ta sẽ theo dõi suy nghĩ của họ và khám phá nơi ẩn chứa những cơ hội thực sự cho các công ty khởi nghiệp trên bàn poker được bao quanh bởi những gã khổng lồ; cách xác minh từng bước một lộ trình tăng trưởng thực dụng chuyển đổi suôn sẻ từ "Copilot" sang "Agent"; và tại sao lập trình, một lĩnh vực có vẻ như theo chiều dọc, lại được coi là "giá trị cao nhất" và "chỉ báo quan trọng" dẫn đến AGI.
Cuối cùng, cuộc trò chuyện này sẽ mở rộng sang tương lai, cung cấp cái nhìn sâu sắc về mối quan hệ hợp tác mới giữa con người và tác nhân, cũng như những thách thức cốt lõi và cơ hội không giới hạn trong việc xây dựng cơ sở hạ tầng thông minh thế hệ tiếp theo.
Điểm nổi bật
Cách tiếp cận tốt nhất trong lĩnh vực đại lý chung là “Làm mẫu cho đại lý”.
Khi phát triển một tác nhân, bạn không cần phải "bắt đầu với mục tiêu trong đầu" và hướng đến một tác nhân hoàn toàn tự động ngay từ đầu. Bạn có thể bắt đầu với Copilot. Trong quá trình này, bạn có thể thu thập dữ liệu người dùng, cải thiện trải nghiệm người dùng, chiếm giữ tâm trí người dùng và sau đó từ từ chuyển đổi.
AGI có thể được hiện thực hóa đầu tiên trong hoàn cảnh mã hóa, vì hoàn cảnh này là đơn giản nhất và có thể thực hiện các khả năng cốt lõi của AI. Mã hóa là "cỗ máy vạn năng" trong thế giới này. Với nó, AI có thể xây dựng và sáng tạo. Mã hóa có thể lấy đi 90% giá trị của toàn bộ ngành công nghiệp mô hình lớn ở một giai đoạn nhất định.
Các sản phẩm AI Native không chỉ dành cho con người mà còn phải phục vụ AI. Một sản phẩm AI Native thực sự phải có cơ chế hai chiều tích hợp phục vụ cả AI và con người.
Các sản phẩm AI ngày nay đang chuyển từ “công cụ” sang “mối quan hệ”. Con người không xây dựng mối quan hệ bằng công cụ, nhưng họ sẽ xây dựng mối quan hệ với AI có trí nhớ, hiểu bạn và có thể “đồng điệu” với bạn.
Sau đây là lắng đọng chương trình phát sóng trực tiếp "Tech Talk Tonight" ngày hôm đó, do Geek Park biên soạn.
01 Sản phẩm Agent nào đã xuất hiện trong cơn sốt này?
Zhang Peng : Trong thời gian qua, mọi người đều thảo luận về Agent, cho rằng đây có thể là một chủ đề quan trọng ở giai đoạn này và là cơ hội phát triển hiếm có cho các công ty khởi nghiệp.
Tôi thấy Shixiang Technology đã tiến hành nghiên cứu chuyên sâu về hệ thống Agent và cũng đã trải nghiệm và phân tích nhiều sản phẩm liên quan. Trước tiên, tôi muốn nghe hai bạn chia sẻ, gần đây có sản phẩm liên quan đến Agent nào để lại ấn tượng sâu sắc với bạn? Tại sao?
Li Guangmi : Hai điều khiến tôi ấn tượng nhất là: một là khả năng lập trình của Claude của Anthropic và hai là chức năng Nghiên cứu sâu của OpenAI ChatGPT.
Về Claude, điều quan trọng nhất là khả năng lập trình của nó. Tôi quan điểm rằng lập trình (Lập trình) là chỉ báo tiên nghiệm quan trọng nhất để đo lường AGI. Nếu AI không thể phát triển các ứng dụng phần mềm trên quy mô lớn và toàn diện, thì tiến trình trong các lĩnh vực khác sẽ chậm. Trước tiên, chúng ta phải đạt được ASI (Trí tuệ siêu nhân tạo) mạnh mẽ trong hoàn cảnh lập trình trước khi các lĩnh vực khác có thể được đẩy nhanh. Nói cách khác, trước tiên chúng ta hiện thực hóa AGI trong hoàn cảnh kỹ thuật số và sau đó mở rộng sang các lĩnh vực khác.

Devin, lập trình viên AI đầu tiên trên thế giới | Nguồn: Cognition Labs
Về Deep Research, nó rất hữu ích với tôi và tôi sử dụng nó hầu như mỗi ngày. Trên thực tế, nó là một tác nhân tìm kiếm giúp tôi tìm lại lượng lớn các trang web và tài liệu. Trải nghiệm rất tốt và nó đã mở rộng đáng kể không gian nghiên cứu của tôi.
Zhang Peng : Kaiqi, theo quan điểm của bạn, sản phẩm nào đã để lại ấn tượng sâu sắc với bạn?
Cage : Tôi có thể giới thiệu mô hình tư duy mà tôi thường áp dụng khi quan sát và sử dụng các tác nhân, sau đó giới thiệu một hoặc hai sản phẩm tiêu biểu trong mỗi danh mục.
Trước hết, mọi người thường hỏi: tác nhân chung hay tác nhân dọc? Chúng tôi cho rằng tác nhân chung tốt nhất là "Mô hình như tác nhân". Ví dụ, Nghiên cứu sâu về OpenAI mà Guangmi vừa đề cập và mô hình o3 mới phát hành của OpenAI, thực chất là một ví dụ tiêu chuẩn của "Mô hình như tác nhân". Nó ghép tất cả các thành phần của tác nhân - mô hình ngôn ngữ lớn (LLM), ngữ cảnh, sử dụng công cụ và hoàn cảnh- lại với nhau và thực hiện đào tạo học tăng cường đầu cuối. Kết quả sau khi đào tạo là nó có thể hoàn thành nhiệm vụ truy xuất thông tin do nhiều tác nhân khác nhau thực hiện.
Vì vậy, "lý thuyết táo bạo" của tôi là: nhu cầu về tổng đại lý về cơ bản là tìm kiếm thông tin và viết mã nhẹ, và GPT-4o đã hoàn thành rất tốt hai loại này. Do đó, thị trường tổng đại lý về cơ bản là chiến trường chính của các công ty mô hình lớn và các công ty khởi nghiệp khó có thể phát triển chỉ bằng cách phục vụ nhu cầu chung.
Các công ty khởi nghiệp gây ấn tượng nhất với tôi về cơ bản đều tập trung vào các lĩnh vực theo chiều dọc.
Nếu chúng ta nói về lĩnh vực dọc của ToB trước, chúng ta có thể chia công việc của mọi người thành công việc front-end và công việc back-end.
Đặc điểm của công việc nền là tính lặp lại mạnh mẽ và yêu cầu đồng thời cao. Thường có một SOP (Quy trình vận hành chuẩn) dài. Nhiều trong số nhiệm vụ trong đó rất phù hợp để các tác nhân AI thực hiện một-một và phù hợp với việc học tăng cường trong không gian khám phá tương đối lớn. Những tác vụ tiêu biểu hơn mà tôi muốn chia sẻ ở đây là một số công ty khởi nghiệp về AI cho Khoa học, tham gia vào các hệ thống Đa tác nhân.
Trong hệ thống này, nhiều nhiệm vụ nghiên cứu khoa học được đưa vào, chẳng hạn như tìm kiếm tài liệu, lập kế hoạch thử nghiệm, dự đoán tiến trình biên giới và phân tích dữ liệu. Đặc điểm của nó là không còn là một tác nhân đơn lẻ như Nghiên cứu sâu, mà là một hệ thống rất phức tạp có thể đạt được độ phân giải cao hơn cho các hệ thống nghiên cứu khoa học. Nó có một chức năng rất thú vị được gọi là "Tìm mâu thuẫn", có thể xử lý nhiệm vụ đối nghịch, chẳng hạn như tìm mâu thuẫn giữa hai bài báo trên tạp chí hàng đầu. Điều này thể hiện một mô hình rất thú vị trong các tác nhân nghiên cứu.
Công việc lễ tân thường liên quan đến việc giao tiếp với mọi người và thực hiện các liên lạc bên ngoài. Hiện nay, các tác nhân giọng nói phù hợp hơn, chẳng hạn như các cuộc gọi theo dõi y tá, tuyển dụng, giao tiếp hậu cần, v.v. trong lĩnh vực y tế.
Ở đây tôi muốn chia sẻ một công ty có tên là HappyRobot. Họ đã tìm ra một kịch bản nghe có vẻ nhỏ, chuyên về giao tiếp qua điện thoại trong lĩnh vực hậu cần và Chuỗi cung ứng. Ví dụ, khi một tài xế xe tải gặp sự cố hoặc hàng hóa đến, đại lý có thể nhanh chóng gọi cho anh ta. Đây là một khả năng rất đặc biệt của AI Agent: phản hồi và phản ứng nhanh 24 giờ một ngày, 7 ngày một tuần. Điều này là đủ cho hầu hết các nhu cầu hậu cần.
Ngoài hai loại trên, còn có một số loại đặc biệt, chẳng hạn như Đại lý mã hóa.
02 Từ Copilot đến Agent, có con đường phát triển thực tế hơn không?
Zhong Kaiqi: Trong lĩnh vực phát triển mã, gần đây có rất nhiều sự nhiệt tình cho tinh thần khởi nghiệp. Một ví dụ điển hình là Cursor. Việc phát hành Cursor 1.0 về cơ bản đã biến một sản phẩm ban đầu trông giống như Copilot (lái xe hỗ trợ) thành một sản phẩm Agent hoàn chỉnh. Nó có thể hoạt động không đồng bộ ở chế độ nền và có chức năng bộ nhớ, chính xác là những gì chúng tôi hình dung về một Agent.
Sự so sánh giữa nó và Devin rất thú vị. Nó cho chúng ta cảm hứng rằng khi phát triển một tác nhân, bạn không cần phải "bắt đầu với mục tiêu trong đầu" và hướng đến một tác nhân hoàn toàn tự động ngay từ đầu. Bạn có thể bắt đầu với Copilot. Trong quá trình này, bạn có thể thu thập dữ liệu người dùng, cải thiện trải nghiệm người dùng, chiếm giữ tâm trí người dùng và sau đó từ từ chuyển đổi. Minus AI, đã hoạt động tốt ở Trung Quốc, cũng bắt đầu với Copilot là sản phẩm đầu tiên của họ.
Cuối cùng, tôi sẽ sử dụng mô hình tư duy "hoàn cảnh" để phân biệt các tác nhân khác nhau. Ví dụ, hoàn cảnh của Manus là máy ảo, hoàn cảnh của Devin là trình duyệt, hoàn cảnh trường của Flowith là sổ ghi chép, hoàn cảnh của SheetZero là bảng, hoàn cảnh của Lovart là canvas, v.v. "Hoàn cảnh" này tương ứng với định nghĩa về hoàn cảnh trong học tăng cường, đây cũng là một phương pháp phân loại đáng tham khảo.

Flowith, được tạo ra bởi một đội ngũ khởi nghiệp trong nước | Nguồn: Flowith
Zhang Peng : Chúng ta hãy nói sâu hơn về ví dụ Cursor. Công nghệ và lộ trình phát triển đằng sau nó là gì?
Cage: Ví dụ về xe tự lái rất thú vị. Cho đến ngày nay, Tesla vẫn không dám tháo bỏ vô lăng, phanh và chân ga. Điều này cho thấy AI không thể hoàn toàn vượt qua con người trong nhiều quyết định quan trọng. Miễn là khả năng của AI tương tự như con người, một số quyết định quan trọng chắc chắn sẽ cần đến sự can thiệp của con người. Đây chính xác là điều mà Cursor đã nghĩ rõ ràng ngay từ đầu.
Vì vậy, tính năng đầu tiên mà họ áp dụng là tính năng mà con người cần nhất: tự động hoàn thành. Họ đã biến tính năng này thành tính năng kích hoạt bằng tab. Với việc phát hành các mô hình như Claude 3.5, Cursor đã tăng độ chính xác của Tab lên hơn 90%. Với độ chính xác này, tôi có thể sử dụng nó từ 5 đến 10 lần trong luồng nhiệm vụ và trải nghiệm luồng sẽ xuất hiện. Đây là giai đoạn đầu tiên của Cursor dưới dạng Copilot.
Trong giai đoạn thứ hai, họ làm việc trên tính năng tái cấu trúc mã. Cả Devin và Cursor đều muốn làm điều này, nhưng Cursor đã làm điều đó khéo léo hơn. Nó sẽ bật lên một hộp thoại và khi tôi nhập yêu cầu, nó sẽ bắt đầu chế độ sửa đổi song song bên ngoài tệp để tái cấu trúc mã.
Khi tính năng này mới ra mắt, độ chính xác không cao, nhưng vì người dùng mong đợi nó là một Copilot nên mọi người đều chấp nhận. Và họ đã dự đoán chính xác rằng khả năng mã hóa của mô hình sẽ được cải thiện nhanh chóng. Vì vậy, trong khi họ đang hoàn thiện các tính năng sản phẩm và chờ khả năng của mô hình được cải thiện, khả năng của Agent đã xuất hiện một cách suôn sẻ.
Bước thứ ba là trạng thái Con trỏ mà chúng ta thấy ngày nay, một Agent tương đối toàn diện chạy ở chế độ nền. Nó có một hoàn cảnh giống như hộp cát đằng sau nó, và tôi thậm chí có thể chỉ định nhiệm vụ mà tôi không muốn làm cho nó trong khi làm việc, và nó có thể sử dụng tài nguyên máy tính của tôi ở chế độ nền để hoàn thành chúng. Đồng thời, tôi có thể tập trung vào nhiệm vụ cốt lõi mà tôi muốn làm nhất.
Cuối cùng, nó cho tôi biết kết quả dưới dạng tương tác không đồng bộ, giống như gửi email hoặc tin nhắn Feishu. Quá trình này thực hiện chuyển đổi trơn tru từ Copilot sang Autopilot (hoặc Agent).
Điều quan trọng là nắm bắt được tâm lý tương tác của mọi người và khiến người dùng sẵn sàng chấp nhận tương tác đồng bộ ngay từ đầu, để có thể thu thập được lượng lớn dữ liệu và phản hồi của người dùng.
03 Tại sao lập trình lại là “nền tảng thử nghiệm quan trọng” trên con đường hướng tới AGI?
Trương Bằng : Quang Mật vừa nói, "Lập trình là chìa khóa của AGI. Nếu chúng ta không thể đạt được ASI (siêu trí tuệ) trong lĩnh vực này, thì cũng sẽ khó đạt được trong các lĩnh vực khác." Tại sao?
Li Guangmi: Có một số logic. Đầu tiên, dữ liệu của Code là sạch nhất và dễ đóng vòng lặp nhất, và kết quả có thể xác minh được. Tôi đoán rằng Chatbot có thể không có bánh đà dữ liệu(một cơ chế vòng phản hồi liên tục tối ưu hóa các mô hình AI bằng cách thu thập dữ liệu từ các tương tác hoặc quy trình, do đó tạo ra kết quả tốt hơn và dữ liệu có giá trị hơn). Nhưng trường Code có cơ hội chạy bánh đà dữ liệu vì nó có thể thực hiện nhiều vòng học tăng cường và Code là hoàn cảnh chính để chạy nhiều vòng học tăng cường.
Một mặt, tôi hiểu Code là một công cụ lập trình, nhưng tôi thích nghĩ về nó như một hoàn cảnh để hiện thực hóa AGI. AGI có thể được hiện thực hóa đầu tiên trong hoàn cảnh này vì hoàn cảnh này là đơn giản nhất và nó có thể thực hiện các khả năng cốt lõi của AI. Nếu AI thậm chí không thể phát triển một phần mềm ứng dụng đầu cuối, thì nó sẽ còn khó khăn hơn trong các lĩnh vực khác. Nếu nó không thể thay thế công việc phát triển phần mềm cơ bản trên quy mô lớn trong tương lai, thì nó cũng sẽ khó khăn trong các lĩnh vực khác.
Hơn nữa, khi khả năng mã hóa được cải thiện, khả năng làm theo hướng dẫn của mô hình cũng sẽ được cải thiện. Ví dụ, khi xử lý các lời nhắc rất dài, Claude rõ ràng là tốt hơn. Chúng tôi đoán điều này có liên quan hợp lý đến khả năng mã hóa của nó.
Một điểm nữa là tôi nghĩ AGI tương lai sẽ được hiện thực hóa trước tiên trong thế giới số. Trong hai năm tới, các Agent sẽ có thể làm hầu hết mọi thứ mà mọi người làm trên điện thoại và máy tính của họ. Một mặt, nó có thể được thực hiện thông qua mã hóa đơn giản và nếu điều đó không hiệu quả, nó cũng có thể gọi các công cụ ảo khác. Do đó, việc hiện thực hóa AGI trong thế giới số trước tiên và làm cho nó chạy nhanh hơn là một logic lớn.
04 Làm thế nào để đánh giá một Agent tốt?
Trương Bằng : Lập trình là "cỗ máy vạn năng" trên thế giới này, AI có thể xây dựng và sáng tạo nhờ nó. Hơn nữa, lĩnh vực lập trình có cấu trúc tương đối, phù hợp để AI phát huy. Khi đánh giá chất lượng của một tác nhân, ngoài trải nghiệm của người dùng, bạn đánh giá tiềm năng của một tác nhân theo góc độ nào?
Cage Zhong : Một tác nhân giỏi trước tiên phải có hoàn cảnh giúp xây dựng bánh đà dữ liệu và bản thân dữ liệu phải có thể xác minh được.
Gần đây, các nhà nghiên cứu Anthropic đã đề cập đến một thuật ngữ gọi là RLVR (Học tăng cường từ phần thưởng có thể xác minh), trong đó"V" ám chỉ phần thưởng có thể xác minh. Mã và toán học là các lĩnh vực có thể xác minh rất chuẩn. Sau khi hoàn thành nhiệm vụ, bạn có thể xác minh ngay lập tức xem nó đúng hay sai và bánh đà dữ liệu được thiết lập một cách tự nhiên.
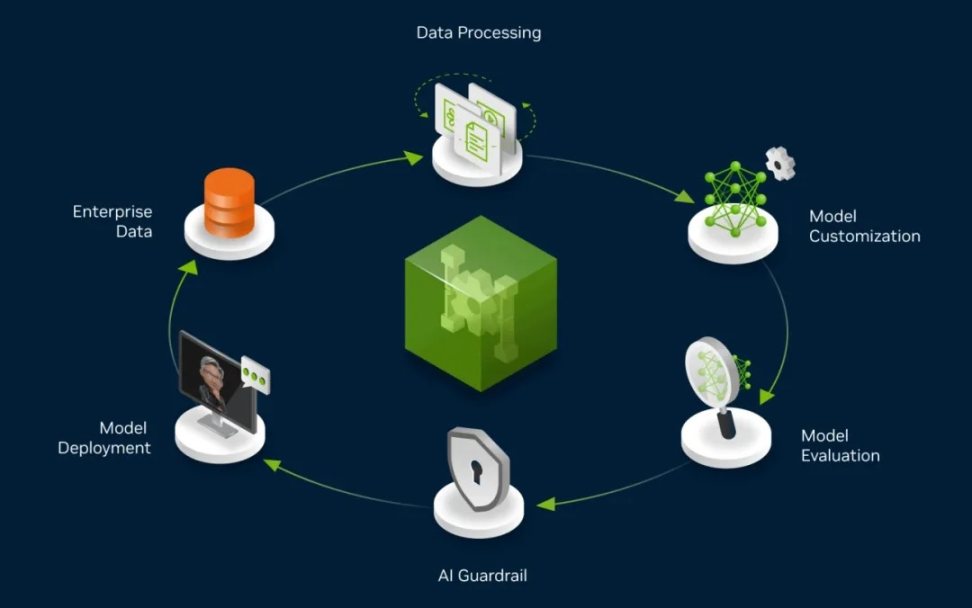
Cơ chế hoạt động của bánh đà dữ liệu |Nguồn: NVIDIA
Do đó, xây dựng một sản phẩm đại lý là xây dựng một hoàn cảnh như vậy. Trong hoàn cảnh này, thành công hay thất bại của nhiệm vụ của người dùng không quan trọng, vì đại lý hiện tại chắc chắn sẽ thất bại. Điều quan trọng là khi nó thất bại, nó có thể thu thập dữ liệu bằng tín hiệu, thay vì dữ liệu nhiễu, để hướng dẫn tối ưu hóa chính sản phẩm. Dữ liệu này thậm chí có thể được sử dụng làm dữ liệu khởi động lạnh cho hoàn cảnh học tăng cường.
Thứ hai, sản phẩm có đủ "Agent Native" không. Nghĩa là khi thiết kế sản phẩm, chúng ta phải cân nhắc đến nhu cầu của cả con người và tác nhân. Một ví dụ điển hình là The Browser Company. Tại sao họ lại tạo ra một trình duyệt mới? Bởi vì Arc trước đây được thiết kế hoàn toàn để cải thiện hiệu quả của người dùng. Khi thiết kế trình duyệt mới của họ, nhiều tính năng mới sẽ được chính các tác nhân AI sử dụng trong tương lai. Điều này rất quan trọng khi logic thiết kế cơ bản của sản phẩm thay đổi.
Về mặt kết quả, đánh giá khách quan cũng rất quan trọng.
1. Tỷ lệ hoàn thành nhiệm vụ+ tỷ lệ thành công: Đầu tiên, nhiệm vụ phải được hoàn thành, để người dùng ít nhất có thể nhận được phản hồi. Thứ hai là tỷ lệ thành công. Đối với nhiệm vụ 10 bước, nếu tỷ lệ chính xác của mỗi bước là 90%, thì tỷ lệ thành công cuối cùng chỉ là 35%. Do đó, kết nối giữa mỗi bước phải được tối ưu hóa. Hiện tại, một dòng vượt qua trong ngành có thể có tỷ lệ thành công hơn 50%.
2. Chi phí và hiệu quả: bao gồm chi phí tính toán (chi phí token) và chi phí thời gian của người dùng. Nếu GPT-4o chạy một nhiệm vụ trong 3 phút, trong khi một tác nhân khác mất 30 phút, thì sẽ là sự lãng phí rất lớn đối với người dùng. Hơn nữa, mức tiêu thụ tỷ lệ băm trong 30 phút này là rất lớn, điều này sẽ ảnh hưởng đến hiệu ứng quy mô.
3. Chỉ báo người dùng: Chỉ số điển hình nhất là độ trung thành của người dùng. Người dùng có sẵn sàng sử dụng sản phẩm nhiều lần sau khi dùng thử không? Ví dụ, tỷ lệ người dùng hoạt động hàng ngày/người dùng hoạt động hàng tháng (DAU/MAU), tỷ lệ duy trì tháng lần, tỷ lệ thanh toán, v.v. Đây là chỉ báo cơ bản để ngăn công ty chỉ có "thịnh vượng giả tạo" (năm phút nổi tiếng).
Li Guangmi : Tôi xin bổ sung thêm một góc nhìn nữa: mức độ phù hợp giữa Agent và khả năng của mô hình hiện tại. Ngày nay, 80% khả năng của Agent phụ thuộc vào công cụ mô hình. Ví dụ, khi GPT đạt đến 3.5, mô hình chung về đối thoại nhiều vòng đã xuất hiện và hình thức sản phẩm Chatbot trở nên khả thi. Sự trỗi dậy của Cursor cũng là do sự phát triển của mô hình lên đến mức Claude 3.5, cho phép khả năng hoàn thành mã của nó được thiết lập.
Devin thực sự đã ra mắt khá sớm, vì vậy điều rất quan trọng đối với đội ngũ sáng lập là phải hiểu được ranh giới khả năng của mô hình. Họ cần biết mô hình có thể đi đến đâu vào hôm nay và trong sáu tháng tới, điều này liên quan chặt chẽ đến các mục tiêu mà Agent có thể đạt được.
Zhang Peng : Sản phẩm "AI Native" là gì? Tôi nghĩ sản phẩm AI Native không chỉ để mọi người sử dụng mà còn phải phục vụ AI.
Nói cách khác, nếu một sản phẩm không có dữ liệu hợp lý để gỡ lỗi và không được xây dựng cho hoàn cảnh làm việc AI trong tương lai, thì nó chỉ sử dụng AI như một công cụ để giảm chi phí và tăng hiệu quả. Một sản phẩm như vậy có sức sống hạn chế và dễ bị choáng ngợp bởi làn sóng công nghệ. Một sản phẩm AI Native thực sự phải có cơ chế hai chiều tích hợp sẵn để phục vụ AI và con người. Nói một cách đơn giản, khi AI phục vụ người dùng, thì người dùng cũng phục vụ AI chứ?
Cage : Tôi rất thích khái niệm này. Dữ liệu Agent không tồn tại trong thế giới thực. Không ai có thể chia nhỏ quy trình suy nghĩ từng bước khi hoàn thành nhiệm vụ. Vậy chúng ta có thể làm gì? Một phương pháp là tìm một công ty chú thích chuyên nghiệp. Một phương pháp khác là tận dụng người dùng và nắm bắt cách sử dụng thực tế của người dùng và quy trình hoạt động của Agent.
Trương Bằng : Nếu chúng ta muốn con người "cung cấp"dữ liệu cho AI thông qua các tác nhân, thì loại nhiệm vụ nào sẽ có giá trị nhất?
Cage : Thay vì nghĩ về việc sử dụng dữ liệu để phục vụ AI, tốt hơn là hãy nghĩ về những điểm mạnh mà AI có mà cần được khuếch đại. Ví dụ, trong nghiên cứu khoa học, trước AlphaGo, con người nghĩ rằng Cờ vây và toán học là khó nhất. Nhưng sau khi sử dụng học tăng cường, người ta thấy rằng đây là những điều dễ nhất đối với AI. Điều tương tự cũng đúng trong lĩnh vực khoa học. Đã lâu rồi kể từ khi một học giả trong lịch sử loài người có thể hiểu được những ngóc ngách của mọi ngành học, nhưng AI có thể. Vì vậy, tôi cho rằng rằng nhiệm vụ như nghiên cứu khoa học là khó đối với con người, nhưng không nhất thiết là khó đối với AI. Đó là lý do tại sao chúng ta cần tìm thêm dữ liệu và dịch vụ để hỗ trợ nó. Phần thưởng của loại nhiệm vụ này có thể xác minh được nhiều hơn hầu hết nhiệm vụ. Trong tương lai, thậm chí con người có thể giúp AI "lắc ống nghiệm", sau đó cho AI biết kết quả là đúng hay sai, giúp AI cùng nhau thắp sáng cây công nghệ.
Li Guangmi : Khởi động lạnh dữ liệu ban đầu là cần thiết. Xây dựng một tác nhân giống như xây dựng một công ty khởi nghiệp. Người sáng lập phải khởi động lạnh và tự mình thực hiện. Tiếp theo, thiết lập hoàn cảnh rất quan trọng, điều này quyết định hướng đi của tác nhân. Sau đó, điều quan trọng hơn là xây dựng hệ thống phần thưởng. Tôi nghĩ rằng hai yếu tố hoàn cảnh và phần thưởng rất quan trọng. Trên cơ sở này, doanh nhân của tác nhân chỉ cần là "CEO" của tác nhân. Ngày nay, AI đã có thể viết mã mà con người không thể hiểu nhưng có thể chạy. Chúng ta không nhất thiết phải hiểu logic đầu cuối của học tăng cường. Chúng ta chỉ cần xây dựng hoàn cảnh và thiết lập phần thưởng.
05 Mô hình kinh doanh của Agent sẽ đi về đâu?
Zhang Peng : Gần đây, chúng tôi thấy rất nhiều đại lý ToB, đặc biệt là ở Hoa Kỳ. Mô hình kinh doanh và mô hình tăng trưởng của họ có thay đổi không? Hay có những mô hình mới đang nổi lên?
Cage : Tính năng lớn nhất hiện nay là ngày càng có nhiều sản phẩm được sử dụng từ dưới lên trong các tổ chức doanh nghiệp. Điển hình nhất là Cursor. Ngoài ra, còn có nhiều sản phẩm AI Agent hoặc Copilot mà mọi người sẵn sàng sử dụng trước. Đây không còn là mô hình SaaS truyền thống đòi hỏi phải có CIO và ký hợp đồng một-một, ít nhất là không phải là bước đầu tiên.
Một sản phẩm thú vị khác là OpenEvidence, nhắm đến các bác sĩ. Đầu tiên, họ chinh phục nhóm bác sĩ, sau đó dần dần đưa quảng cáo về thiết bị y tế và thuốc men vào. Việc kinh doanh này không cần phải đàm phán với bệnh viện ngay từ đầu, vì đàm phán với bệnh viện rất chậm. Điều quan trọng nhất đối với các công ty khởi nghiệp AI là tốc độ. Chỉ dựa vào hệ thống bảo vệ kỹ thuật là vô ích. Tăng trưởng cần đạt được thông qua cách tiếp cận từ dưới lên này.

Kỳ lân y tế AI OpenEvidence|Nguồn: OpenEvidence
Về mô hình kinh doanh, hiện nay có xu hướng chuyển dần từ định giá dựa trên chi phí sang định giá dựa trên giá trị.
1. Dựa trên chi phí: Giống như các dịch vụ đám mây truyền thống, thêm một lớp giá trị phần mềm vào chi phí CPU/GPU.
2. Trả tiền lần: Về phía Đại lý, một cách là tính phí theo “hành động”. Ví dụ, đại lý hậu cần mà tôi đã đề cập trước đó tính phí một vài xu cho một cuộc gọi điện thoại cho tài xế xe tải.
3. Tính phí theo quy trình công việc: Một mức độ trừu tượng cao hơn là tính phí theo "quy trình công việc", chẳng hạn như hoàn thành toàn bộ đơn hàng hậu cần. Điều này xa hơn về mặt chi phí và gần hơn về mặt giá trị, vì nó thực sự liên quan đến công việc. Nhưng điều này đòi hỏi một kịch bản tương đối hội tụ.
4. Trả theo kết quả: Lên một cấp, đó là trả theo kết quả. Vì tỷ lệ thành công của các đại lý không cao nên người dùng muốn trả tiền cho kết quả thành công. Điều này đòi hỏi công ty đại lý phải có khả năng đánh bóng sản phẩm ở mức cao.
5. Trả tiền theo Agent: Trong tương lai, chúng ta có thể thực sự trả tiền theo “Agent”. Ví dụ, có một công ty tên là Hippocratic AI chuyên sản xuất y tá AI. Ở Hoa Kỳ, chi phí thuê một y tá là con người là khoảng 40 đô la một giờ, trong khi y tá AI của họ chỉ tốn 9 đến 10 đô la một giờ, tức là bằng ba phần tư chi phí. Ở một thị trường như Hoa Kỳ, nơi mà lao động đắt đỏ, thì điều này rất hợp lý. Nếu Agent có thể làm tốt hơn trong tương lai, tôi thậm chí có thể thưởng cho họ và thưởng cuối năm. Đây đều là những cải tiến trong mô hình kinh doanh.
Li Guangmi : Điều chúng tôi mong đợi nhất là phương pháp định giá dựa trên giá trị. Ví dụ, nếu Manus AI xây dựng một trang web, thì nó có đáng giá 300 đô la không? Nếu nó xây dựng một ứng dụng, thì nó có đáng giá 50.000 đô la không? Nhưng giá trị của nhiệm vụ ngày nay vẫn khó định giá. Làm thế nào để thiết lập một phương pháp đo lường và định giá tốt là điều đáng để các doanh nhân khám phá.
Ngoài ra, Kaiqi vừa đề cập rằng thanh toán dựa trên đại lý, giống như một công ty ký hợp đồng với nhân viên của mình. Trong tương lai, khi chúng ta thuê một đại lý, chúng ta có cần cấp cho họ một "thẻ căn cước" không? Chúng ta có cần ký "hợp đồng lao động" không? Đây thực chất là một hợp đồng thông minh. Tôi rất mong chờ cách các hợp đồng thông minh trong lĩnh vực Crypto sẽ được áp dụng cho các đại lý trong thế giới kỹ thuật số trong tương lai. Khi nhiệm vụ hoàn thành, các lợi ích kinh tế sẽ được phân phối thông qua một phương pháp đo lường và định giá tốt. Đây có thể là cơ hội để kết hợp các đại lý với hợp đồng thông minh Crypto.
06 Mối quan hệ hợp tác giữa con người và tác nhân sẽ như thế nào?
Zhang Peng : Gần đây trong lĩnh vực Coding Agent, có hai thuật ngữ được thảo luận rất nhiều: "Con người trong vòng lặp" và "Con người trong vòng lặp". Họ đang thảo luận về điều gì?
Cage Zhong : "Con người trong vòng lặp" có nghĩa là con người nên giảm thiểu số lượng quyết định trong vòng lặp và chỉ tham gia vào những thời điểm quan trọng. Nó hơi giống với FSD của Tesla, khi hệ thống gặp phải một quyết định nguy hiểm, nó sẽ cảnh báo con người tiếp quản chân ga và phanh. Trong thế giới ảo, điều này thường đề cập đến sự hợp tác giữa con người và máy tính không đồng bộ, không tức thời. Con người có thể can thiệp vào các quyết định quan trọng mà AI không chắc chắn.
"Con người trong vòng lặp" giống như AI sẽ "ping" bạn theo thời gian để xác nhận điều gì đó. Ví dụ, Minus AI có một máy ảo ở bên phải và tôi có thể thấy nó làm gì trong trình duyệt theo thời gian thực. Nó giống như một hộp trắng mở và tôi có thể biết sơ bộ tác nhân muốn làm gì.
Hai khái niệm này không phải là đen và trắng, mà là một quang phổ. Bây giờ nó "trong vòng lặp" hơn, và mọi người vẫn cần phải xem xét và phê duyệt ở nhiều điểm chính. Lý do rất đơn giản, phần mềm vẫn chưa đạt đến giai đoạn đó và ai đó phải chịu trách nhiệm nếu có vấn đề. Không được tháo chân ga và phanh.
Có thể thấy trước rằng trong tương lai, đối với nhiệm vụ có tính lặp lại cao, kết quả cuối cùng sẽ là mọi người chỉ đọc tóm tắt và mức độ tự động hóa sẽ rất cao. Đối với một số vấn đề khó, chẳng hạn như để AI đọc báo cáo bệnh lý, chúng ta có thể tăng "tỷ lệ dương tính giả" của Agent lên một chút, giúp nó dễ dàng nghĩ rằng "có vấn đề", sau đó "trên vòng lặp" gửi những trường hợp này dưới dạng email cho bác sĩ con người. Theo cách này, mặc dù bác sĩ con người cần xem xét nhiều trường hợp hơn, nhưng tất cả các trường hợp được Agent đánh giá là "âm tính" đều có thể được chấp thuận suôn sẻ. Nếu chỉ có 20% báo cáo bệnh lý thực sự khó, thì băng thông công việc của bác sĩ con người đã được phóng đại gấp 5 lần. Vì vậy, đừng quá lo lắng về "trong" hoặc "trên", miễn là bạn tìm thấy một điểm kết hợp tốt, bạn có thể thực hiện tốt công tác cộng tác giữa người và máy.
Lý Quang Mễ : Thực ra có một cơ hội rất lớn đằng sau câu hỏi mà anh Bành đặt ra, đó là "tương tác mới" và "cách mọi người và các đại lý làm việc cùng nhau". Điều này có thể hiểu đơn giản là trực tuyến (đồng bộ) và ngoại tuyến (không đồng bộ). Ví dụ, khi chúng tôi phát trực tiếp một cuộc họp, chúng tôi phải trực tuyến theo thời gian thực. Nhưng nếu tôi, với tư cách là một CEO, phân công nhiệm vụ cho các đồng nghiệp của mình, tiến độ dự án sẽ không đồng bộ.
Ý nghĩa lớn hơn của điều này là khi các tác nhân được đưa vào sử dụng trên quy mô lớn, thì việc khám phá cách mọi người và các tác nhân có thể tương tác với nhau và cách các tác nhân có thể tương tác với nhau là điều đáng giá. Ngày nay, chúng ta vẫn tương tác với AI thông qua văn bản, nhưng trong tương lai, sẽ có nhiều cách để tương tác với các tác nhân. Một số có thể chạy tự động ở chế độ nền, trong khi những cách khác yêu cầu mọi người phải xem ở phía trước. Khám phá các tương tác mới là một cơ hội lớn.
07 Công suất dư thừa, cầu không đủ, khi nào “ứng dụng sát thủ” của Agent xuất hiện?
Trương Bằng : Coding Agent vẫn là phần mở rộng của IDE. Liệu có thay đổi gì trong tương lai không? Nếu mọi người đều chen chúc trên con đường này, những người đến sau làm sao có thể đuổi kịp Cursor?
Cage Zhong : IDE chỉ là một hoàn cảnh. Việc sao chép một IDE không có nhiều giá trị. Nhưng việc tạo ra một tác nhân trong một IDE hoặc một hoàn cảnh tốt khác là có giá trị. Tôi sẽ cân nhắc xem người dùng của nó chỉ là các nhà phát triển chuyên nghiệp hay liệu nó có thể được mở rộng cho "các nhà phát triển dân sự" ngoài các nhà phát triển chuyên nghiệp - những nhân viên văn phòng có nhiều nhu cầu tự động hóa.
Cái gì còn thiếu bây giờ? Không phải là năng lực cung ứng, vì các sản phẩm như Cursor đã phóng đại năng lực cung ứng mã hóa của AI lên 10 lần hoặc thậm chí 100 lần. Trước đây, nếu tôi muốn tạo ra một sản phẩm, tôi cần thuê ngoài một đội ngũ CNTT và chi phí thử nghiệm và sai sót rất cao. Bây giờ, về mặt lý thuyết, tôi có thể thử nghiệm và sai sót chỉ bằng cách nói một từ và trả phí hàng tháng là 20 đô la.
Cái còn thiếu hiện nay là nhu cầu. Mọi người đều đang sử dụng nhu cầu cũ để phù hợp với công nghệ mới, điều này hơi giống như "tìm đinh bằng búa". Hầu hết các nhu cầu hiện tại là dành cho các trang đích hoặc các trang web đồ chơi cơ bản. Trong tương lai, chúng ta cần tìm một hình thức sản phẩm hội tụ. Điều này hơi giống như khi công cụ đề xuất ra đời, đó là một công nghệ rất tốt. Sau đó, một hình thức sản phẩm có tên là "dòng thông tin" đã xuất hiện, thực sự đưa công cụ đề xuất đến với công chúng. Nhưng lĩnh vực Mã hóa AI vẫn chưa tìm thấy một sản phẩm sát thủ như "dòng thông tin".
Li Guangmi : Tôi nghĩ rằng mã hóa có thể lấy đi 90% giá trị của toàn bộ ngành công nghiệp người mẫu lớn ở một giai đoạn nhất định. Làm thế nào để giá trị này có thể tăng trưởng? Ngày nay, hành động đầu tiên vẫn là phục vụ 30 triệu lập trình viên trên toàn thế giới. Để tôi đưa ra cho bạn một ví dụ. Photoshop phục vụ 20 đến 30 triệu nhà thiết kế chuyên nghiệp trên toàn thế giới và ngưỡng rất cao. Nhưng khi Jianying, Canva và Meitu Xiuxiu ra mắt, có thể có 500 triệu hoặc thậm chí nhiều người dùng hơn có thể sử dụng các công cụ này và tạo ra nội dung phổ biến hơn.
Code có một lợi thế, đó là nền tảng thể hiện sáng tạo. Hơn 90% nhiệm vụ trong xã hội này có thể được thể hiện thông qua Code, vì vậy nó có tiềm năng trở thành nền tảng sáng tạo. Trước đây, ngưỡng phát triển ứng dụng rất cao và lượng lớn các nhu cầu đuôi dài không được đáp ứng. Khi ngưỡng giảm đáng kể, những nhu cầu này sẽ được kích thích. Điều tôi mong đợi là "sự bùng nổ của các ứng dụng". Dữ liệu lớn nhất do Internet di động tạo ra là nội dung và nội dung lớn nhất do làn sóng AI này tạo ra có thể là phần mềm ứng dụng mới. Điều này giống như sự khác biệt giữa các nền tảng video dài như Youku và iQiyi và Douyin. Bạn có thể so sánh mô hình lớn với một chiếc máy ảnh và trên đó, bạn có thể tạo ra các ứng dụng tuyệt vời như Douyin và Jianying. Đây có thể là bản chất của cái gọi là "Vibe Coding", một nền tảng sáng tạo mới.
Trương Bằng : Để nâng cao giá trị đầu ra của Agent, đầu vào cũng trở nên rất quan trọng. Nhưng xét về sản phẩm và công nghệ, có thể sử dụng phương pháp nào để nâng cao chất lượng đầu vào để đảm bảo đầu ra tốt hơn?
Cage : Khi nói đến sản phẩm, chúng ta không thể cho rằng lỗi là ở người dùng nếu họ không sử dụng sản phẩm tốt. Từ quan trọng nhất cần tập trung vào là “bối cảnh”. Một tác nhân có thể thiết lập “nhận thức về bối cảnh” không?
Ví dụ, nếu tôi viết mã trong một công ty Internet lớn, Agent sẽ không chỉ xem mã tôi có trong tay mà còn xem toàn bộ cơ sở mã của công ty, thậm chí cả các cuộc trò chuyện của tôi với các nhà quản lý sản phẩm và đồng nghiệp tại Feishu, cũng như thói quen giao tiếp và mã hóa trước đây của tôi. Việc cung cấp tất cả các bối cảnh này cho Agent sẽ giúp đầu vào của tôi hiệu quả hơn.
Do đó, đối với các nhà phát triển Agent, điều quan trọng nhất là phải tạo ra mối liên hệ đủ tốt giữa cơ chế bộ nhớ và ngữ cảnh, đây cũng là một thách thức lớn đối với cơ sở hạ tầng Agent.
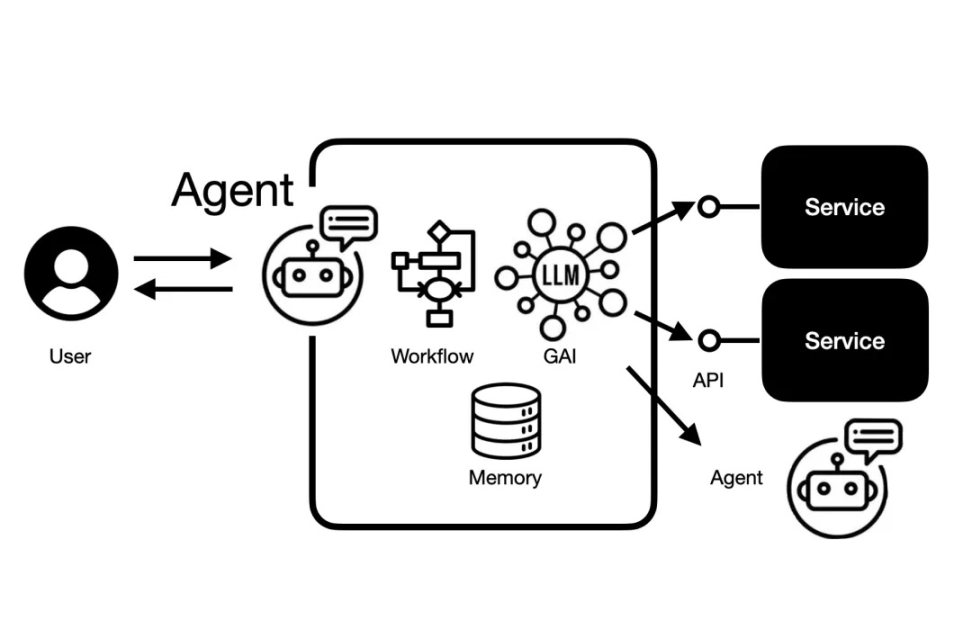
Thách thức của tác nhân: cơ chế trí nhớ tốt và kết nối ngữ cảnh | Nguồn hình ảnh: Retail Science
Ngoài ra, điều quan trọng đối với các nhà phát triển là chuẩn bị dữ liệu khởi động lạnh cho việc học tăng cường và xác định phần thưởng rõ ràng. Ý nghĩa đằng sau phần thưởng này là cách phân tích nhu cầu của người dùng khi họ không diễn đạt rõ ràng. Ví dụ, khi tôi hỏi những câu hỏi không rõ ràng, Nghiên cứu sâu của OpenAI sẽ đưa ra bốn câu hỏi hướng dẫn trước. Trong quá trình tương tác với nó, tôi thực sự đã suy nghĩ rõ ràng về nhu cầu của mình.
Đối với người dùng ngày nay, điều quan trọng nhất là phải suy nghĩ về cách diễn đạt rõ ràng nhu cầu của họ và cách chấp nhận chúng. Mặc dù bạn không cần phải "bắt đầu với mục tiêu cuối cùng trong đầu", bạn nên có kỳ vọng sơ bộ về điều tốt và điều xấu. Khi chúng ta viết lời nhắc, chúng ta cũng nên viết giống như mã, với hướng dẫn và logic rõ ràng, để tránh nhiều đầu ra không hợp lệ.
Lý Quang Mễ : Tôi muốn nói thêm hai điểm. Thứ nhất, tầm quan trọng của bối cảnh. Chúng tôi thường thảo luận nội bộ rằng nếu bối cảnh được thực hiện tốt, sẽ có những cơ hội mới ở cấp độ Alipay và PayPal.
Trước đây, các công ty thương mại điện tử xem xét GMV, nhưng trong tương lai, họ sẽ xem xét tỷ lệ hoàn thành nhiệm vụ. Hoàn thành nhiệm vụ liên quan đến trí thông minh ở một mặt và ngữ cảnh ở mặt khác. Ví dụ, nếu tôi muốn xây dựng một trang web cá nhân, nếu tôi cung cấp ghi chú Notion, dữ liệu WeChat và dữ liệu email cho AI, thì nội dung trang web cá nhân của tôi chắc chắn sẽ rất phong phú.
Thứ hai, học tự động. Sau khi thiết lập hoàn cảnh, tác nhân phải có khả năng lặp lại, điều này rất quan trọng. Nếu không thể tiếp tục học và lặp lại, kết quả sẽ là nó sẽ bị chính mô hình nuốt chửng, vì mô hình là một hệ thống học. Trong làn sóng Internet di động cuối cùng, các công ty không thực hiện học máy và đề xuất đã không phát triển lớn mạnh. Trong làn sóng này, nếu tác nhân không thể thực hiện tốt việc học và lặp lại tự động từ đầu đến cuối, tôi nghĩ rằng nó sẽ không thể thành công.
08 Có những thay đổi và cơ hội nào khác trong cuộc cạnh tranh giữa những người khổng lồ?
Trương Bằng : Làm sao chúng ta xác định được khả năng của các tác nhân trong tương lai sẽ xuất hiện dưới dạng siêu giao diện hay được phân bổ rời rạc trong nhiều tình huống khác nhau?
Cage : Tôi thấy một xu hướng lớn. Đầu tiên, chắc chắn là đa tác nhân. Ngay cả khi để hoàn thành một nhiệm vụ, trong các sản phẩm như Cursor, tác nhân thực hiện hoàn thiện mã và kiểm thử đơn vị có thể khác nhau, vì chúng cần các "tính cách" và thế mạnh khác nhau.
Thứ hai, lối vào có thay đổi không? Tôi nghĩ lối vào là vấn đề bậc hai. Điều đầu tiên cần xảy ra là mọi người đều có nhiều tác nhân và hợp tác với họ. Đằng sau những tác nhân này sẽ là một mạng lưới mà tôi gọi là "Botnet". Ví dụ, trong tương lai, hơn 60% lượng tiêu thụ cố định có thể được hoàn thành bởi các tác nhân.
Tương tự như vậy trong kịch bản năng suất. Trong tương lai, các cuộc họp hàng ngày của lập trình viên có thể được thay thế bằng sự hợp tác giữa các tác nhân, điều này sẽ thúc đẩy chỉ báo bất thường và tiến độ phát triển sản phẩm. Khi những điều này xảy ra, những thay đổi trong điểm vào có thể xuất hiện. Vào thời điểm đó, các cuộc gọi API sẽ không còn chủ yếu là các cuộc gọi của con người nữa mà là các cuộc gọi giữa các tác nhân.
Zhang Peng : Quyết định và trạng thái hành động của các công ty lớn có năng lực như OpenAI, Anthropic, Google và Microsoft trên Agent là gì?
Lý Quang Mật : Từ khóa trong đầu tôi là "phân biệt". Năm ngoái, mọi người đều theo đuổi GPT-4, nhưng bây giờ có nhiều thứ có thể làm được hơn, và mỗi công ty đã bắt đầu phân biệt.
Người đầu tiên tách ra là Anthropic. Vì nó ra đời sau OpenAI và khả năng toàn diện của nó không mạnh bằng, nên nó tập trung vào mã hóa. Tôi cảm thấy rằng nó đã chạm đến lá bài lớn đầu tiên trên con đường đến AGI, đó là Coding Agent. Họ có thể cho rằng AGI có thể đạt được thông qua mã hóa, có thể mang lại khả năng làm theo hướng dẫn và khả năng của Agent, là một vòng khép kín tự nhất quán về mặt logic.
Nhưng OpenAI còn có nhiều cái tên lớn hơn trong tay. Đầu tiên là ChatGPT, mà Sam Altman có thể muốn biến thành một sản phẩm có 1 tỷ người dùng hoạt động hàng ngày. Thứ hai là các mô hình sê-ri"o" (GPT-4o, v.v.), dự kiến sẽ mang lại nhiều khả năng khái quát hơn. Thứ ba là đa phương thức, và khả năng suy luận đa phương thức của nó đã được cải thiện, điều này cũng sẽ được phản ánh trong thế hệ trong tương lai. Vì vậy, Anthropic đã chạm vào một quân bài lớn, và OpenAI đã chạm vào ba quân bài.
Một công ty lớn khác là Google. Tôi nghĩ rằng vào cuối năm nay, Google có thể bắt kịp về mọi mặt. Bởi vì họ có TPU, Google Cloud, mô hình Gemini hàng đầu, Android và Chrome. Bạn không thể tìm thấy một công ty nào khác trên thế giới có tất cả các yếu tố này và gần như độc lập với các bên bên ngoài. Khả năng đầu cuối của Google rất mạnh. Nhiều người lo ngại rằng việc kinh doanh quảng cáo của họ sẽ bị Sự lật đổ, nhưng tôi cảm thấy rằng họ có thể tìm ra những cách mới để kết hợp các sản phẩm trong tương lai và chuyển đổi từ một công cụ thông tin thành một công cụ nhiệm vụ.
Hãy nhìn Apple. Vì nó không có khả năng AI riêng, nên nó rất thụ động trong quá trình lặp lại. Microsoft nổi tiếng với các nhà phát triển của mình, nhưng Cursor và Claude thực sự đã thu hút được rất nhiều sự chú ý của các nhà phát triển. Tất nhiên, mảng của Microsoft rất ổn định, với GitHub và VS Code, nhưng nó cũng phải có khả năng AGI và mô hình rất mạnh. Vì vậy, bạn có thể thấy rằng nó cũng đã công bố rằng một trong những mô hình được GitHub ưa thích đã trở thành Claude và nó đã lặp lại các sản phẩm dành cho nhà phát triển của riêng mình. Microsoft phải giữ vững phía nhà phát triển, nếu không nền tảng sẽ không còn nữa.
Vì vậy, mọi người bắt đầu chia rẽ. Có thể OpenAI muốn trở thành Google tiếp theo và Anthropic muốn trở thành Windows tiếp theo (sống trên API).
Zhang Peng : Cơ sở hạ tầng liên quan đến Agent có những thay đổi và cơ hội nào?
Cage : Các tác nhân có một số thành phần chính. Ngoài mô hình, thành phần đầu tiên là hoàn cảnh. Trong giai đoạn đầu phát triển tác nhân, 80% các vấn đề liên quan đến hoàn cảnh. Ví dụ, AutoGPT ban đầu được khởi động bằng Docker, rất chậm hoặc được triển khai trực tiếp trên máy tính cục bộ, rất không an toàn. Nếu một tác nhân muốn "làm việc" với tôi, tôi phải trang bị cho nó một "máy tính", vì vậy cơ hội cho hoàn cảnh đã xuất hiện.
Có hai yêu cầu chính khi cấu hình máy tính:
1. Máy ảo/Sandbox: Cung cấp hoàn cảnh thực thi an toàn. Nếu nhiệm vụ được thực hiện sai, nó có thể được khôi phục. Quá trình thực thi không thể gây hại cho hoàn cảnh thực tế. Nó phải có thể khởi động nhanh và chạy ổn định. Các công ty như E2B và Modal Labs đang cung cấp các sản phẩm như vậy.
2. Trình duyệt: Truy xuất thông tin là nhu cầu lớn nhất và các tác nhân cần thu thập thông tin từ nhiều trang web khác nhau. Các trình thu thập thông tin truyền thống dễ bị chặn, vì vậy các tác nhân cần được trang bị trình duyệt chuyên dụng có thể hiểu thông tin. Điều này đã dẫn đến sự ra đời của các công ty như Browserbase và Browser Use.
Thành phần thứ hai là bối cảnh. Bao gồm:
Truy xuất thông tin: Các công ty RAG truyền thống vẫn còn đó, nhưng cũng có những công ty mới, chẳng hạn như MemGPT, chuyên phát triển các công cụ quản lý bộ nhớ và ngữ cảnh nhẹ cho các tác nhân AI.
Khám phá công cụ: Sẽ có rất nhiều công cụ trong tương lai và chúng ta sẽ cần một nền tảng như Dianping để giúp các tác nhân khám phá và lựa chọn các công cụ hữu ích.
Bộ nhớ: Tác nhân cần có Infra có thể mô phỏng khả năng kết hợp trí nhớ dài hạn và ngắn hạn phức tạp của con người.
Thành phần thứ ba là các công cụ, bao gồm tìm kiếm đơn giản, thanh toán phức tạp, phát triển phần phụ trợ tự động, v.v.
Cuối cùng, khi tác nhân trở nên mạnh hơn, một cơ hội quan trọng chính là bảo mật tác nhân.
Lý Quang Mễ : Agent Infra rất quan trọng. Chúng ta có thể suy nghĩ từ đầu đến cuối. Ba năm nữa, khi hàng nghìn tỷ tác nhân đang thực hiện nhiệm vụ trong thế giới số, nhu cầu về Infra sẽ rất lớn, điều này sẽ định hình lại toàn bộ điện toán đám mây và thế giới số.
Nhưng ngày nay chúng ta vẫn chưa biết loại Agent nào có thể phát triển lớn mạnh và loại Infra nào cần thiết. Vì vậy, bây giờ là thời điểm rất tốt để các doanh nhân cùng thiết kế và cùng sáng tạo các công cụ Infra với các công ty Agent đang hoạt động tốt.
Tôi nghĩ những điều quan trọng nhất hiện nay là, thứ nhất, máy ảo, và thứ hai, công cụ. Ví dụ, tìm kiếm tác nhân trong tương lai chắc chắn sẽ khác với tìm kiếm của con người và sẽ có nhu cầu rất lớn về tìm kiếm máy. Hiện tại, tìm kiếm của con người trên toàn bộ mạng có thể là 20 tỷ lần một ngày và trong tương lai, tìm kiếm máy có thể là hàng trăm tỷ hoặc thậm chí hàng nghìn lần. Loại tìm kiếm này không yêu cầu tối ưu hóa sắp xếp của con người và một cơ sở dữ liệu lớn có thể là đủ. Có những cơ hội tuyệt vời để tối ưu hóa chi phí và tinh thần kinh doanh.
09 Khi AI không còn chỉ là một mô hình lớn, nó sẽ phát triển theo hướng nào?
Zhang Peng : Các tác nhân không thể tránh khỏi các mô hình. Nhìn lại ngày hôm nay, theo ông, công nghệ mô hình đã có những bước tiến quan trọng nào trong hai năm qua?
Li Guangmi : Tôi nghĩ có lẽ có hai cột mốc quan trọng. Một là mô hình luật mở rộng được GPT-4 thể hiện, có nghĩa là trong giai đoạn tiền đào tạo, việc mở rộng vẫn có hiệu quả và có thể mang lại khả năng khái quát hóa phổ quát.
Cột mốc quan trọng thứ hai là mô hình "tư duy mô hình" được thể hiện bằng sê-ri mô hình "o". Nó cải thiện đáng kể khả năng lý luận thông qua thời gian suy nghĩ dài hơn (Chuỗi suy nghĩ).
Tôi cho rằng hai mô hình này là cánh tay trái và phải của AGI ngày nay. Trên cơ sở này, Luật mở rộng quy mô không dừng lại, và chế độ tư duy sẽ tiếp tục. Ví dụ, Mở rộng quy mô có thể tiếp tục trong đa phương thức, và khả năng tư duy của sê-ri "o" có thể được thêm vào đa phương thức, do đó đa phương thức có thể có khả năng suy luận dài hơn, và khả năng kiểm soát và tính nhất quán của thế hệ sẽ trở nên rất tốt.
Cảm giác của tôi là hai năm tới có thể chứng kiến sự tiến triển nhanh hơn hai năm qua. Ngày nay, chúng ta có thể đang ở trong trạng thái mà hàng ngàn nhà khoa học AI hàng đầu trên thế giới đang cùng nhau thúc đẩy Phục hưng công nghệ của con người. Với đủ nguồn lực và nền tảng, những đột phá có thể xảy ra trong nhiều lĩnh vực.
Zhang Peng : Ông mong đợi những tiến bộ và bước nhảy vọt về công nghệ nào trong lĩnh vực AI trong một hoặc hai năm tới?
Cage : Đầu tiên là đa phương thức. Hiện tại, sự hiểu biết và tạo ra đa phương thức vẫn còn tương đối phân tán. Trong tương lai, chắc chắn sẽ tiến tới "sự thống nhất lớn", tức là sự tích hợp của sự hiểu biết và tạo ra. Điều này sẽ mở rộng rất nhiều trí tưởng tượng của sản phẩm.
Thứ hai là học tự chủ. Tôi thực sự thích khái niệm "thời đại trải nghiệm" do Richard Sutton (cha đẻ của học tăng cường) đề xuất, tức là AI cải thiện khả năng của mình thông qua trải nghiệm thực hiện nhiệm vụ trực tuyến. Điều này chưa từng thấy trước đây vì không có nền tảng kiến thức thế giới. Nhưng bắt đầu từ năm nay, đây sẽ là một điều liên tục.

Người đoạt giải Turing năm 2024 Richard Sutton |Nguồn: Amii
Thứ ba là bộ nhớ. Nếu mô hình thực sự có thể làm tốt bộ nhớ Agent ở cấp độ sản phẩm và kỹ thuật, thì sự đột phá sẽ rất lớn. Độ bám dính của sản phẩm sẽ thực sự xuất hiện. Tôi cảm thấy rằng ngay khi GPT-4o bắt đầu có bộ nhớ, tôi thực sự đã trở nên bám dính vào ứng dụng ChatGPT.
Cuối cùng, có những tương tác mới. Liệu có những tương tác mới không còn là hộp nhập văn bản nữa không? Bởi vì việc nhập thực sự là một ngưỡng rất cao. Liệu có nhiều tương tác trực quan và bản năng hơn trong tương lai không? Ví dụ, tôi có một sản phẩm AI "luôn bật" liên tục lắng nghe tôi và suy nghĩ không đồng bộ ở chế độ nền, và có thể nắm bắt bối cảnh chính tại thời điểm tôi có cảm hứng. Tôi nghĩ đây là những gì tôi đang mong đợi.
Zhang Peng : Thật vậy, ngày nay chúng ta phải đối mặt với cả thách thức và cơ hội. Một mặt, chúng ta không thể bị choáng ngợp bởi tốc độ phát triển công nghệ và phải duy trì sự chú ý liên tục. Mặt khác, các sản phẩm AI ngày nay đang chuyển từ "công cụ" sang "mối quan hệ". Con người sẽ không thiết lập mối quan hệ với các công cụ, mà sẽ thiết lập mối quan hệ với AI có trí nhớ, hiểu bạn và có thể "đồng điệu" với bạn. Loại mối quan hệ này về cơ bản là thói quen và quán tính, đây cũng là rào cản quan trọng trong tương lai.
Buổi thảo luận hôm nay rất sâu sắc. Cảm ơn Guangmi và Kaiqi đã chia sẻ rất tuyệt vời. Cảm ơn khán giả trong phòng phát sóng trực tiếp vì sự đồng hành của họ. Hẹn gặp lại các bạn trong số tiếp theo của "Tonight's Technology Talk".
Lý Quang Mễ : Cảm ơn.
Cage : Cảm ơn bạn.





