

Sáng ngày 29 tháng 8, giờ Bắc Kinh, OpenAI đã phát hành GPT-Realtime, mô hình giọng nói đầu cuối tiên tiến nhất từ trước đến nay, trong một buổi phát trực tiếp, đồng thời công bố việc ra mắt toàn diện API Realtime trong hoàn cảnh. So với các sản phẩm AI giọng nói trước đây, GPT-Realtime mang lại hiệu suất vượt trội và mức giá thấp hơn, được thiết kế để giúp các nhà phát triển dễ dàng xây dựng các tác nhân giọng nói hiệu quả và đáng tin cậy hơn.
Cùng với những cải tiến về hiệu suất, giá của GPT-Realtime đã được tối ưu hóa đáng kể, giảm 20% so với phiên bản tiền nhiệm GPT-4o-Realtime-Preview. Trước đây, GPT-4o-Realtime-Preview có giá 40 đô la cho mỗi triệu token đầu vào âm thanh và 80 đô la cho mỗi triệu token đầu ra âm thanh. Giá điều chỉnh của GPT-Realtime hiện là 32 đô la cho mỗi triệu token đầu vào âm thanh (0,40 đô la cho token đầu vào được lưu trong bộ nhớ đệm) và 64 đô la cho mỗi triệu token đầu ra âm thanh. Mức giá được tối ưu hóa này cho phép các nhà phát triển xây dựng các tác nhân giọng nói hiệu quả với chi phí thấp hơn mà vẫn tận hưởng hiệu suất vượt trội.
OpenAI cũng đã tối ưu hóa việc quản lý ngữ cảnh hội thoại, cho phép các nhà phát triển linh hoạt đặt giới hạn mã thông báo và cắt bỏ nhiều vòng hội thoại cùng một lúc, giúp giảm đáng kể chi phí cho các cuộc hội thoại dài.
01. Phân tích chuyên sâu: mô hình giọng nói thông minh hơn và biểu cảm hơn
Mô hình GPT-Realtime mới thể hiện một bước nhảy vọt đáng kể về hiệu suất. OpenAI tuyên bố đây là mô hình giọng nói tiên tiến nhất của họ cho đến nay, đạt được những cải tiến đáng kể trong việc tuân theo các hướng dẫn phức tạp, sử dụng công cụ một cách chính xác và tạo ra giọng nói tự nhiên và biểu cảm hơn.
OpenAI tuyên bố rằng GPT-Realtime có thể thực hiện các lệnh phức tạp chính xác hơn, tạo ra giọng nói tự nhiên và biểu cảm hơn, đồng thời hỗ trợ chuyển đổi liền mạch giữa nhiều ngôn ngữ trong một câu. Trong các bài kiểm tra chuẩn nội bộ, mô hình đã chứng minh được mức độ thông minh cao hơn. So với các mô hình AI giọng nói trước đây, GPT-Realtime cải thiện đáng kể ở các khía cạnh sau:
Chất lượng âm thanh và khả năng biểu cảm: Có thể mô phỏng ngữ điệu, cảm xúc và tốc độ nói của con người, đồng thời hỗ trợ nhà phát triển tùy chỉnh giọng nói, chẳng hạn như "nhanh và chuyên nghiệp" hoặc "nhẹ nhàng và chu đáo" để nâng cao trải nghiệm của người dùng.
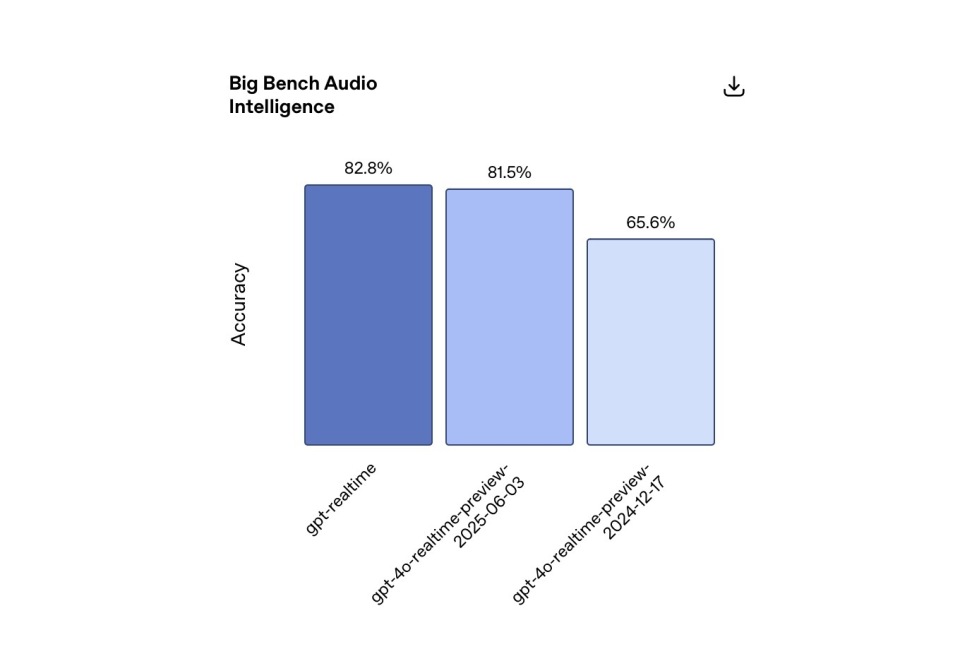
Trí tuệ và Khả năng hiểu: Không chỉ xử lý văn bản và lời nói, GPT-Realtime còn nhận dạng các tín hiệu phi ngôn ngữ (như tiếng cười), chuyển đổi linh hoạt giữa các ngôn ngữ trong câu và xử lý chính xác các chuỗi ký tự chữ và số. Thử nghiệm nội bộ cho thấy GPT-Realtime đạt độ chính xác 82,8% trong bài kiểm tra suy luận Big Bench Audio, vượt xa mức 65,6% của phiên bản tiền nhiệm GPT-4o-Realtime-Preview vào tháng 12 năm 2024 và 81,5% tính đến ngày 3 tháng 6 năm nay.
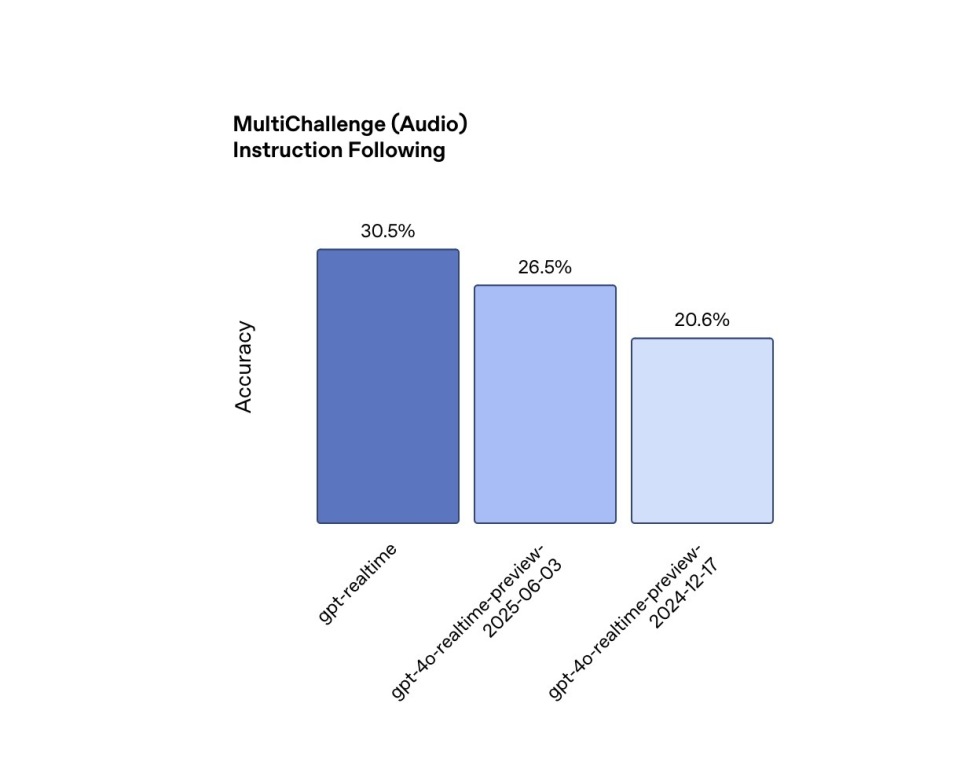
Theo dõi lệnh: Theo dõi lệnh là một khả năng quan trọng đối với các tác nhân đáng tin cậy, và GPT-Realtime cũng đã được cải thiện trong lĩnh vực này. Trong thử nghiệm MultiChallenge Audio, GPT-Realtime đạt độ chính xác thực thi lệnh 30,5%, cho phép nó tuân thủ các lời nhắc do nhà phát triển chỉ định một cách đáng tin cậy hơn, chẳng hạn như đọc nguyên văn các tuyên bố miễn trừ trách nhiệm pháp lý trong các cuộc gọi hỗ trợ. Hiệu suất này vượt qua mức 20,6% đạt được của thế hệ trước, GPT-4o-Realtime-Preview, vào tháng 12 năm 2024 và 26,5% vào ngày 3 tháng 6 năm nay.
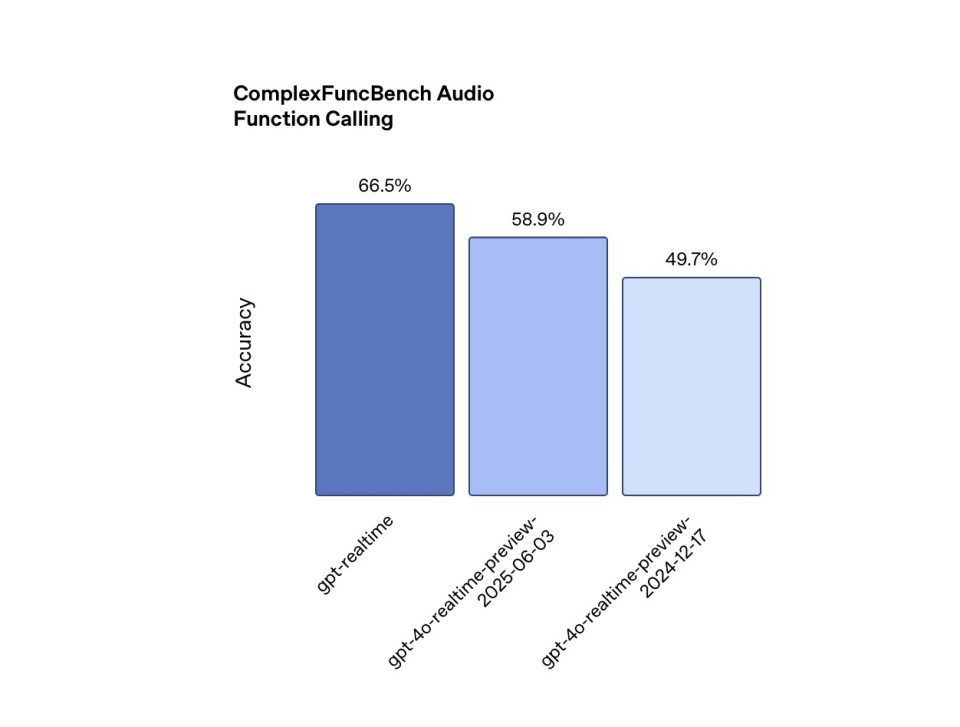
Gọi hàm: Để hoạt động hiệu quả trong thế giới thực, các tác nhân giọng nói phải sử dụng hiệu quả các công cụ bên ngoài. Trong bài kiểm tra ComplexFuncBench Audio, GPT-Realtime đạt tỷ lệ chính xác 66,5% cho các lệnh gọi hàm và hỗ trợ các lệnh gọi không đồng bộ, đảm bảo các cuộc trò chuyện diễn ra suôn sẻ mà không bị gián đoạn trong khi chờ kết quả. Để so sánh, GPT-4o-Realtime-Preview đạt tỷ lệ chính xác 49,7% vào tháng 12 năm 2024 và tỷ lệ chính xác 58,9% vào ngày 3 tháng 6 năm nay.
Ngoài trí thông minh được cải tiến, mô hình đã được huấn luyện để tạo ra giọng nói chất lượng cao hơn với ngữ điệu, cảm xúc và tốc độ giống con người hơn. Nó có thể tuân theo các hướng dẫn chi tiết, chẳng hạn như "nói nhanh và chuyên nghiệp" hoặc "nói nhỏ nhẹ với giọng Pháp", mang lại trải nghiệm cá nhân hóa hơn cho người dùng. Hơn nữa, GPT-Realtime hỗ trợ nhập hình ảnh và có thể nhận dạng nội dung của ảnh hoặc ảnh chụp màn hình. Ví dụ: người dùng có thể tải lên ảnh chụp màn hình và yêu cầu mô hình "đọc văn bản trong đó", mở rộng hơn nữa các kịch bản ứng dụng của nó.
Để chứng minh những tiến bộ này, OpenAI đã phát hành hai giọng nói mới, Cedar và Marin, chỉ có sẵn trong API, thể hiện những cải tiến đáng kể nhất trong giọng nói tự nhiên. Sự chú trọng đến từng chi tiết này được thiết kế để giải quyết những thách thức chính của ngành: Nâng cấp của OpenAI hướng trực tiếp đến việc tạo ra trải nghiệm người dùng hấp dẫn hơn và ít mang tính robot hơn.
02. Trao quyền cho các nhà phát triển: Nâng cấp API cho các tác nhân thông minh cấp sản xuất
Ngoài các mô hình mới, bản thân API thời gian thực hiện nay đã đạt đến cấp độ sản xuất. Kể từ phiên bản beta công khai vào tháng 10 năm 2024, OpenAI đã thu thập phản hồi từ hàng ngàn nhà phát triển và thực hiện các cải tiến tương ứng. Kiến trúc của API xử lý âm thanh trực tiếp thông qua một mô hình duy nhất, được thiết kế để giảm độ trễ và bảo toàn chi tiết giọng nói. Điều này mang lại những lợi thế đáng kể so với các quy trình đa mô hình truyền thống cho chuyển đổi giọng nói thành văn bản và văn bản thành giọng nói.

Một tính năng mới quan trọng là hỗ trợ máy chủ Giao thức Bối cảnh Mô hình (MCP) từ xa. Tiêu chuẩn mở này đơn giản hóa cách các mô hình AI kết nối với dữ liệu bên ngoài. Các nhà phát triển giờ đây có thể truyền URL của máy chủ MCP từ xa thông qua cấu hình phiên, cho phép API thời gian thực tự động xử lý các lệnh gọi công cụ, loại bỏ nhu cầu tích hợp thủ công. Điều này giúp đơn giản hóa việc kết nối các mô hình AI với các nguồn dữ liệu độc quyền, một bước quan trọng trong việc xây dựng hệ thống thông tin kinh doanh mạnh mẽ đồng thời ưu tiên dữ liệu người dùng và quyền riêng tư.
API thời gian thực hiện nay cũng hỗ trợ nhập hình ảnh, cho phép các cuộc trò chuyện đa phương thức, nơi các tác nhân có thể phân tích và thảo luận về những gì người dùng đang thấy. Hình ảnh được xử lý như ảnh chụp nhanh trong cuộc trò chuyện thay vì luồng video trực tiếp, đảm bảo nhà phát triển kiểm soát được những gì mô hình nhìn thấy. Điều này mở ra các trường hợp sử dụng như cho phép các tác nhân mô tả ảnh hoặc đọc văn bản từ ảnh chụp màn hình.
Ngoài ra, hỗ trợ Giao thức khởi tạo phiên (SIP) mới cho phép tích hợp trực tiếp với mạng điện thoại công cộng, hệ thống PBX và các điểm cuối điện thoại doanh nghiệp khác, tạo điều kiện triển khai các tác nhân thoại trong hoàn cảnh kinh doanh như trung tâm cuộc gọi.
Những người dùng đầu tiên đã thấy được kết quả. Nền tảng bất động sản Zillow đã được tiếp cận sớm với Realtime API, nền tảng này sẽ được sử dụng để hỗ trợ tìm kiếm nhà thế hệ tiếp theo. "Nó thể hiện khả năng lập luận nâng cao và giọng nói tự nhiên hơn, cho phép xử lý các yêu cầu phức tạp, nhiều bước như lọc danh sách dựa trên nhu cầu lối sống", Josh Weisberg, giám đốc AI của công ty, cho biết.
03. Đấu trường AI giọng nói cạnh tranh khốc liệt
Lần OpenAI phát hành mô hình GPT-Realtime diễn ra trong bối cảnh cạnh tranh khốc liệt trên thị trường AI giọng nói, với các đối thủ lớn đang tích cực thúc đẩy phát triển và triển khai công nghệ giọng nói của riêng họ. Vào tháng 5 năm nay, Anthropic đã ra mắt mô hình giọng nói cho Claude AI của mình, đánh dấu một bước tiến mạnh mẽ vào lĩnh vực này. Vào tháng 7, Meta đã mua lại công ty khởi nghiệp giọng nói PlayAI với giá 45 triệu đô la, nhằm mục đích củng cố công nghệ trợ lý AI và kính thông minh. Động thái này càng làm gia tăng sự cạnh tranh về nhân tài trong ngành.
Cộng đồng mã nguồn mở cũng là một lực lượng cạnh tranh mạnh mẽ không thể bỏ qua. Vào tháng 7, công ty khởi nghiệp Mistral của Pháp đã phát hành mô hình Voxtral, được cấp phép theo giấy phép Apache 2.0. Chính thức cam kết rằng giá dịch vụ của nó sẽ thấp hơn một nửa so với các API tương tự trong khi vẫn mang lại hiệu suất vượt trội. Tháng này, Xiaomi đã phát hành mô hình hiểu âm thanh quy mô lớn do chính mình phát triển, MiDashengLM-7B. Mô hình này sử dụng phương pháp đào tạo dựa trên phụ đề một cách sáng tạo để đạt được sự hiểu biết toàn diện về giọng nói, âm nhạc và âm thanh hoàn cảnh, đồng thời sử dụng giấy phép thân thiện với doanh nghiệp.
Các công ty công nghệ truyền thống cũng đang tiếp tục đầu tư vào AI giọng nói. Vào tháng 4 năm nay, Amazon đã ra mắt Nova Sonic, một mô hình biểu cảm theo thời gian thực, và tích hợp nó vào trợ lý ảo Alexa+. Sự đổi mới trong AI giọng nói cũng đã lan tỏa đến các công ty khởi nghiệp chuyên biệt. Ví dụ, Stability AI tập trung vào phát triển công nghệ xử lý giọng nói trên thiết bị, trong khi các công ty như Sesame AI đang tạo ra các trợ lý AI được mô tả là "giống người đến kinh ngạc" bằng cách tích hợp các tính năng giống con người như ngắt quãng tự nhiên và hơi lắp bắp trong giọng nói.
OpenAI lần tối ưu hóa các mô hình giọng nói tiên tiến của mình để chúng dễ sử dụng hơn, mạnh mẽ hơn và tiết kiệm chi phí hơn. Động thái này thể hiện một bước đi chiến lược trong bối cảnh cạnh tranh ngày càng khốc liệt giữa các nền tảng. OpenAI hy vọng sẽ tận dụng trải nghiệm phát triển vượt trội của mình để giành lợi thế trong cuộc chiến AI giọng nói, trở thành yếu tố then chốt quyết định kết quả.
Bài viết này được trích từ " Tencent Technology ", tác giả: Wu Ji, được 36Kr xuất bản với sự cho phép.





