

Bài viết này được dịch máy
Xem bản gốc
Lấy cảm hứng từ quá trình tự nghiên cứu của Karpathy, tôi đã dạy VibeHQ cách tự phát triển – không phải bằng cách phát triển một tác nhân đơn lẻ, mà bằng cách phát triển cách thức hợp tác của toàn bộ hệ thống Đa tác nhân.
lần chu trình hoàn toàn tự động, không cần sự can thiệp của con người:
• Lượng sử dụng token: 7,2 triệu → 5,7 triệu (mức giảm cao nhất là 62%)
• Giảm thiểu các vấn đề liên quan đến phối hợp (như công việc trùng lặp): 4 → 0
• Lãng phí token PM: -91%
Chu trình: đánh giá chuẩn → định lượng hợp tác và phân tích LLM, lỗi xảy ra → viết lại mã phối hợp /optimize-protocol → xây dựng lại → lặp lại.
Trí tuệ nhân tạo (AI) quan sát sự thiếu hợp tác giữa các thành viên trong đội ngũ, phân tích nguyên nhân và sau đó sửa đổi mã nguồn của chính nó để điều phối logic hợp tác. Toàn bộ quá trình được thực hiện mà không cần sự can thiệp của con người, cho phép AI tự tổ chức đội ngũ của mình để làm việc cùng nhau một cách liền mạch.
Dựa trên các tài liệu liên quan, AutoResearch đang tự động tối ưu hóa quá trình huấn luyện mô hình. Trước đây, Ralph sử dụng một tác nhân duy nhất cho vòng lặp tự động, trong khi Gastown chạy đồng thời 20-30 mã Claude.
Khả năng điều phối, nhưng nó không có khả năng tiến hóa. Tất cả đều rất mạnh mẽ, nhưng cuối cùng chúng đều làm suy yếu khả năng của một tác nhân duy nhất.
Không ai tự mình phát triển đội ngũ– cách phân chia nhiệm vụ, cách tránh xung đột, cách chia sẻ thông tin, cách hỗ trợ lẫn nhau. Giống như trong thế giới thực, các nhóm AI cũng cần phải tự rèn luyện kỹ năng này.
Hãy tưởng tượng điều gì sẽ xảy ra nếu thứ này bị hỏng:
• Các nhân viên xây dựng văn hóa đội ngũ và sự phối hợp làm việc hiệu quả.
• Thích ứng với các dự án và phân bổ các nhóm từ 3 đến 7 người tùy thuộc vào tiến độ phát triển dự án.
Càng cùng nhau thực hiện nhiều dự án, đội ngũ càng trở nên mạnh mẽ hơn.
• Các nhân viên có thể tự động phân công lại nhiệm vụ bằng cách thêm các thành viên mới vào nhóm trong suốt dự án.
Thành thật mà nói, cuối cùng nó sẽ phát triển thành cái gì? Tôi không biết, nhưng đó mới là điều thú vị nhất.

Andrej Karpathy
@karpathy
03-10
Three days ago I left autoresearch tuning nanochat for ~2 days on depth=12 model. It found ~20 changes that improved the validation loss. I tested these changes yesterday and all of them were additive and transferred to larger (depth=24) models. Stacking up all of these changes,
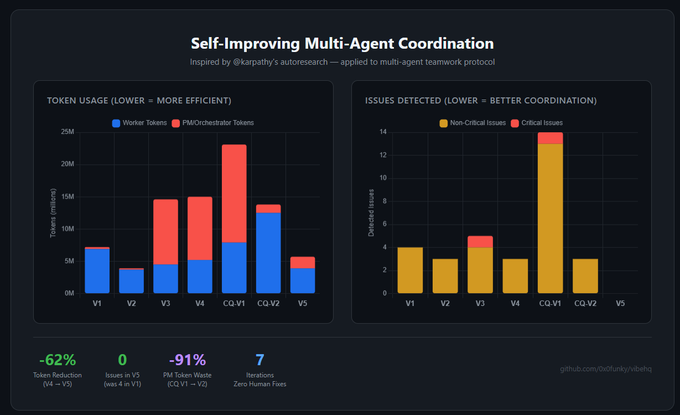

Bạn có thể tìm thấy dữ liệu thực nghiệm chi tiết trong bài báo này.
Từ Twitter
Tuyên bố từ chối trách nhiệm: Nội dung trên chỉ là ý kiến của tác giả, không đại diện cho bất kỳ lập trường nào của Followin, không nhằm mục đích và sẽ không được hiểu hay hiểu là lời khuyên đầu tư từ Followin.
Thích
Thêm vào Yêu thích
Bình luận
Chia sẻ
Nội dung liên quan





